各アクターのメンタルモデルと、複数のアクターが共用する"ドメインモデル"には情報構造上のギャップがある
まず最初に、天重氏(@tenjuu99)による次の記事を参照する。
ぜひ全編を読んでいただきたい。以降読んでいただいた前提で書く。
中盤《2. ドメインモデル》で、飲食店での複写式伝票の話をしている。下に記事中の図を引用させていただく。
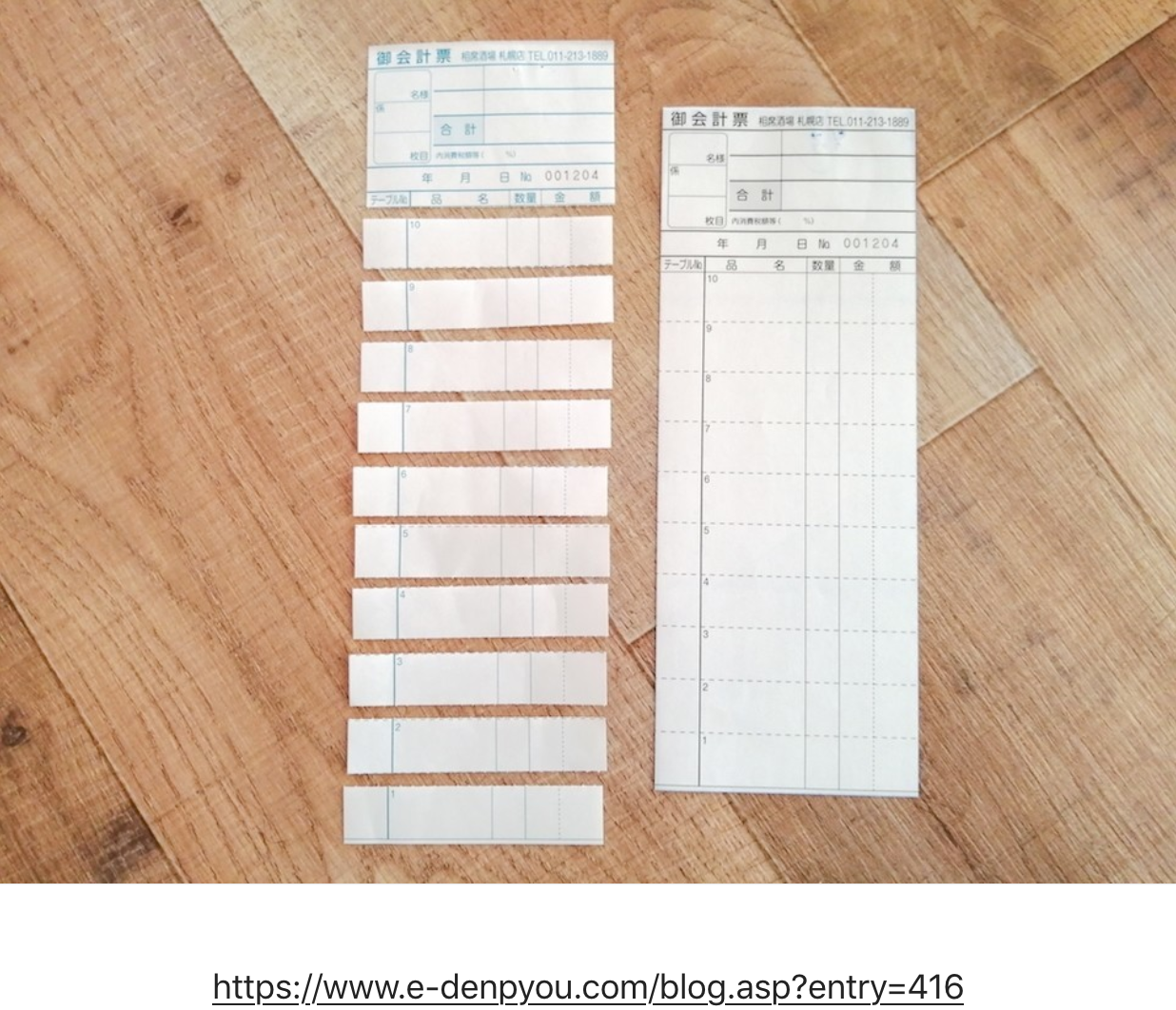
この複写式伝票は、ある一つのドメインモデルを"実装"している、といえる。天重氏は、「この注文伝票をぼくが面白いとおもったのは、厨房の人とホールの人で情報構造が違っている点です。」と言っている。
ホールの人にとっての情報構造:
・席番号と料理の紐付けに関心がある。
厨房の人にとっての情報構造:
・料理を出す順番に関心がある。
(席番号と料理の紐付けに制約されずに、料理を出して行きたい。)
そして、この複写式伝票は、
両者の情報構造の違い(と、そのマッピング)をモデルとして表現している
と見れる、というわけである。
この論点は、最後の章《5. MVCとはなにか》で次のようにまとめられている。下図も天重氏記事からの引用である。
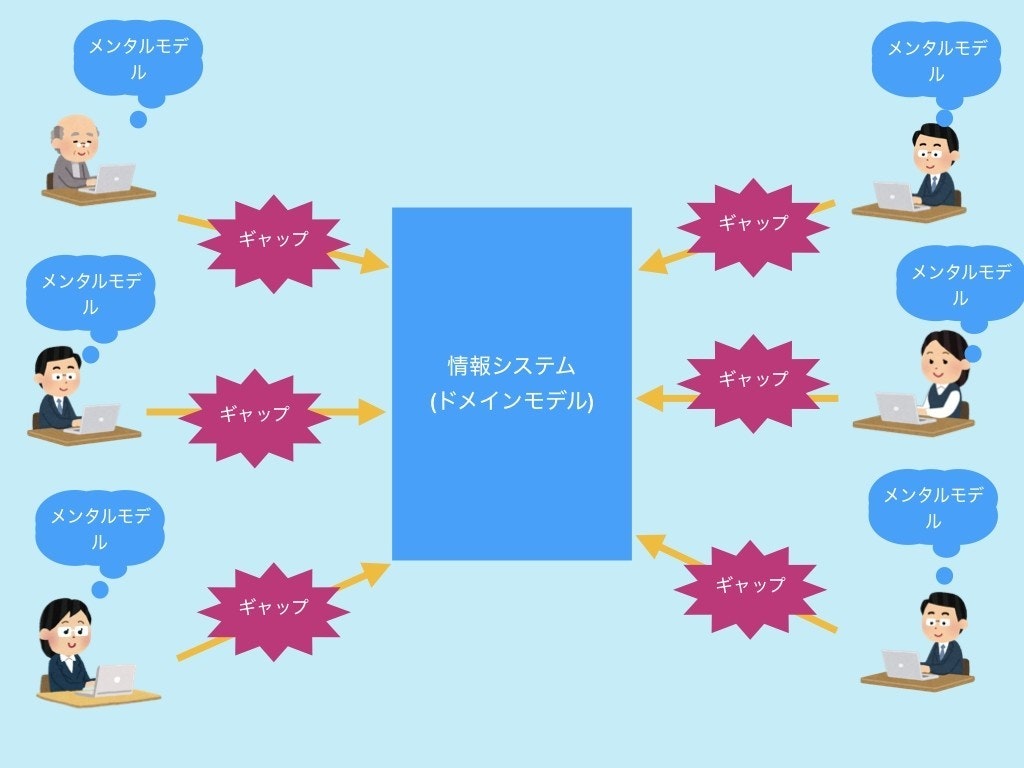
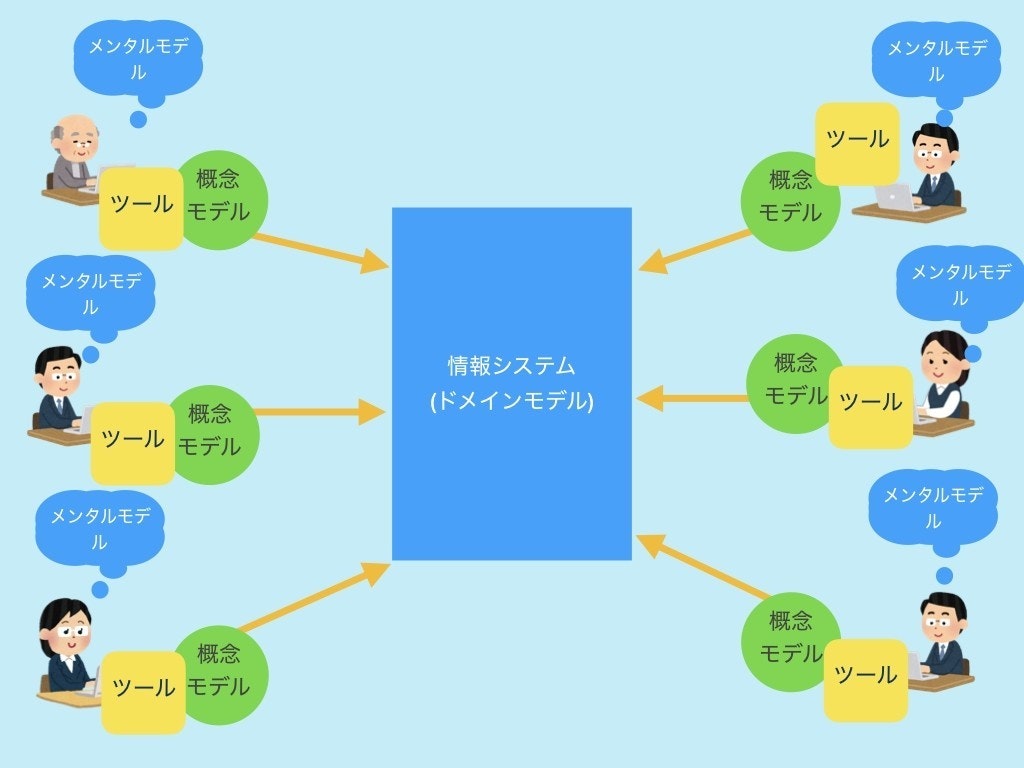
要点は次のようになろう。
- 各アクターは、それぞれ異なる"メンタルモデル"を持っている。
- 中心に共用的に運用したい"ドメインモデル"がある。
- ユーザーの情報とドメインの情報にはギャップがある。
- ギャップを埋めるために、"ツール"=「ユーザーイリュージョン」=MVC=パーソナルコンピューターを用いる。
天重氏の記事の主題は、「「ユーザーイリュージョン」の位置付けや役割、それの実現のための「MVC」について」、である。が、ここでは、ギャップの存在について注目したい。
飲食店での複写式伝票の事例に戻すと、フロアスタッフと調理スタッフは、異なる"モデル"を持っている。しかし、二つの異なる"モデル"を統合したところの"情報システム"を、複写式伝票は(ギャップを乗り越えて)実現している、という話になる。
統合された"情報システム"は、"誰が"必要としているのか?
ここで次のような疑問が湧くのである。
統合された"情報モデル"(複写式伝票)は、いったい誰がそれを欲したのだろうか?
ホールの人も、厨房の人も、そんなもの(複写式伝票)は要求していない。
「いや、少なくともホールと厨房が連携して作業できないと業務回らんでしょう?そこはなんとかしたいでしょう?」という反論はあるかもしれない。いや、まさにその点である。ホールスタッフから見れば、厨房スタッフがどのように業務対応してるかは究極関係ない。逆も然り。ホールの動きも、厨房の動きも両方合わせてうまく回って欲しいと願い、そのための仕組みを実装したかったのは究極誰なのか?
◇
このようなギャップについて、DDD本にも言及はある。次の図はDDD本、第4部第14章の、《象のモデルを統一する》からの引用である。
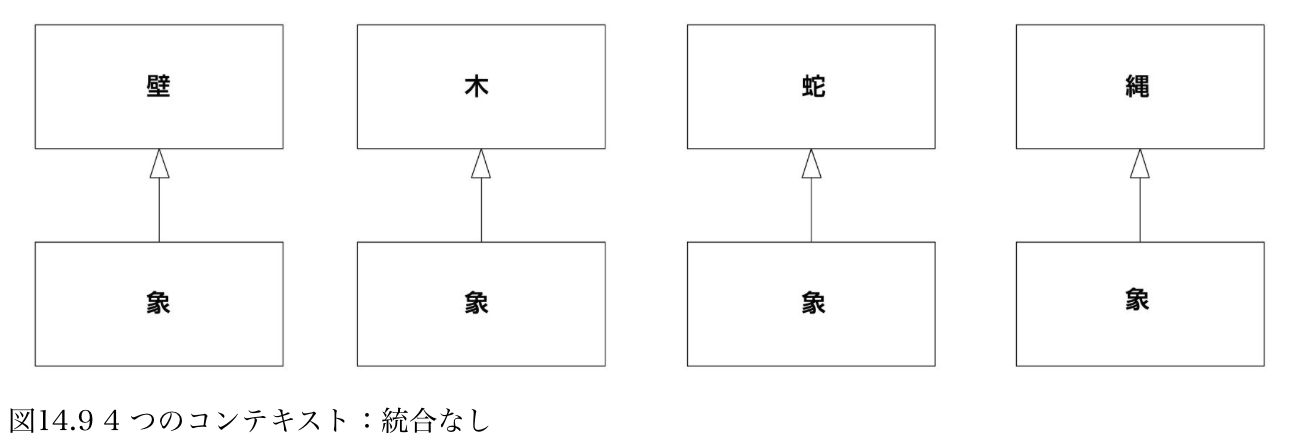
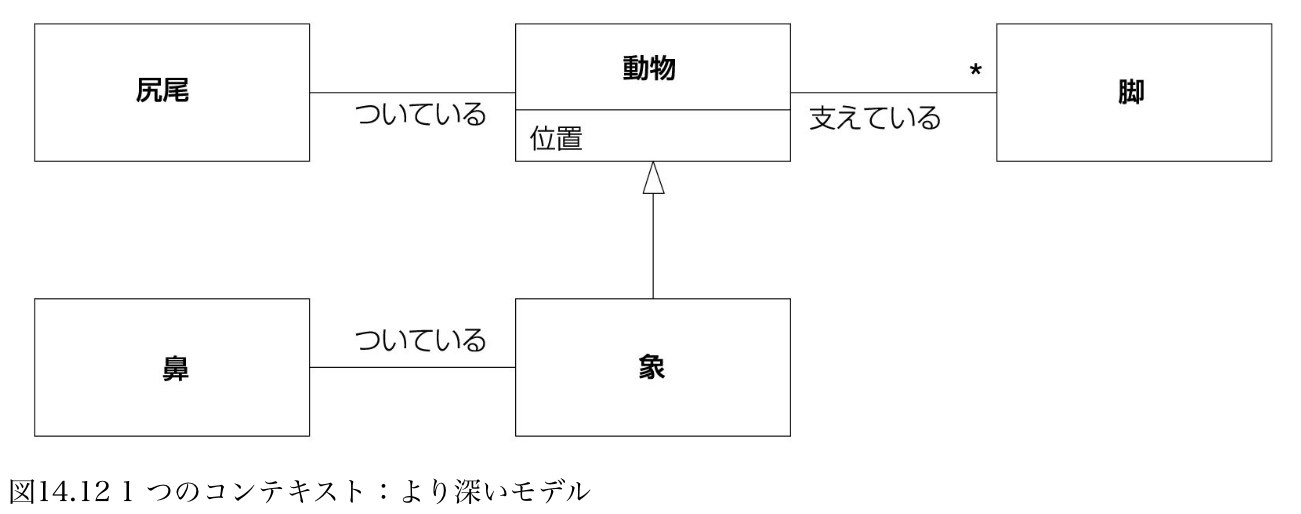
図14.9は、4人のアクターそれぞれのメンタルモデルがバラバラに表されている様子を表している。対して、図14.12は「動物-象のパーツ」として4人のアクターのモデルが統合された様子を表している訳である。
ただ、DDD本の「象のモデル」の話は、ちょっとミスリードを誘うと思っている。というのは、「象」は、各アクターが観察する以前に客観的(※「客観とは?」には立ち入らないが。。)に存在している。このことから、「象」という全体像は"自然"に存在する、全体像は各アクターの個別の要求を統合する過程で自ずと浮かび上がる、各アクターの個別のメンタルモデルは表層的なものであり、真に理解を深めることで"イデア的正解"たる全体像に到達できるという分析過程、を想起してしまう。
「象のモデル」による例は、「厨房とホールの連携」のようなケースでも、連携した姿は頑張れば分析的に見出せるはず、ということを言っているように受け取れてしまう。でも実際のシステム設計の場面では、統合モデルに"正解"はない。統合モデルは分析的には見出せない。分析的に見出せるのは、「ホールの業務」と「厨房の業務」だけである。そこではたしかに各当事者(アクター)が現にやっているアクティビティを分析できる。しかし両者の統合は、統合モデルは、誰かが作り出さなければならない。
◇
複写式伝票の話の場合、ホールスタッフは基本ホールの仕事のことだけ関心を持っているし、キッチンスタッフは調理のことだけに関心を持っている。両者の業務上の連携に関心を持っているのは誰か?ホール側の「注文単位」を明細単位でバラして、調理側の「調理単位」を注文側とは異なる構造に再編成すると良い、という情報変換モデルは誰からの要件に基づくのか?
"ドメインモデル"とは、事業者によって考案されたビジネスの構造("ドメインモデル"は個々のアクターの為のもの、ではない)
前節での疑問に回答をもたらすような論がある。末並氏(@a_suenami)のスライドを参照する。
こちらの末並氏の論説は、やはり全編読んでいただきたい。
スライドの最後、84ページを引用する。

要点は次の通りだろう。
- "ドメインモデル"とは、事業者のためのものであり、エンドユーザーのためのものではない。
- SoRとは事業者の考えるビジネスの構造をモデリングしたもの。
- SoEはその一側面をステークホルダーに提供するもの。
この末並氏の論を以って、天重氏の飲食店での複写式伝票の例を解釈すると次のようになる。
(a) ホールにはホールの現場の要求(=席単位で注文明細をまとめたい)がある。
(b) 厨房には厨房の現場の要求(=料理の種類ごとのキューに明細を分別したい)がある。
(c) 両方の業務が統合的に回るようにした"情報システム"として、複写式伝票がある。
(d) 「(a)」を支援するシステム(=複写式伝票の一葉)は、ホールスタッフというステークホルダーに提供するSoE、と言える。
(e) 「(b)」を支援するシステム(=複写式伝票の別の一葉)は、キッチンスタッフというステークホルダーに提供するSoE、と言える。
(f) 「(c)」は、事業者がその目的のために考案した仕組みであり、SoRと言える。
(g) 「(f)」から見て、「(d)」や「(e)」は、その一側面、と位置付く。
「飲食店における複写式伝票」は、「ホール業務コンテキスト」と「厨房業務コンテキスト」を分析しているだけでは決して出てこないモデルなのである。二つのコンテキストを統合して回さなければならない事業のモデルとしてどうなのか?という視点を持つことで初めて、アプローチしなければならない課題として認識されてくるのだ。
事業者の関心ごとは情報の保全、現場(個々のアクター)の関心ごとは情報の活用
天重氏の論説で、各アクターが共用したい、しかし個々のアクターのメンタルモデルとはそれぞれにギャップのある情報システム=ドメインモデルの存在が示された。末並氏の論説では、そのような情報システム=ドメインモデルは、事業者のために存在していて、各アクターのためではない、という見方が示された。そして「SoR」とは「事業のモデル」の表れであり、対して各アクターのメンタルモデルを支えるようなサブシステムが「SoE」なのだと再定義した。
また、天重氏の論では、共用される情報システムと各アクターのメンタルモデルのギャップを埋めるツールが、「ユーザーイリュージョン」=MVC、だと示された。末並氏の論と対比すると、SoEこそユーザーイリュージョンの担い手だと対応付けられそうである。
各アクターは、ユーザーイリュージョンを担うSoEを用いて何をしたいのだろうか?各アクターの関心ごとは、情報システムそのものには無く、現場のオペレーションを回すことにある。現場のオペレーションを回すために情報システムを活用しようとしている、だけである。情報活用においては、業務の現場で発生する様々な問題に対してのサポートを期待している。この文脈において、基本的に情報は利用したいのであって、情報を集積したい訳では無い。ここは大事な観点だと思う。様々なソース情報を如何に活用して、アクターが為す業務に如何に役立てるかが、SoEの主題、だといえる。
一方で、事業のモデルが実装されているSoRを用いて、事業者は何をしたいのだろうか?前段のようなSoEのために基礎情報を提供すること、も目的の一つといえる。特定のアクター≒SoEだけでなく、多様なアクター≒SoEからの多様な情報要求に対して、一貫性を持って情報提供できる、ということも目的に加えたい。「現場のオペレーションを回すための情報活用」はSoEに委譲しているとしたら、SoRが担うべきは、特定のアクターの要求におもねらず、情報を首尾一貫として保全すること、と言えなくは無いか。
ここに「ホール業務という情報活用のコンテキスト」、「厨房業務という情報活用のコンテキスト」に加えて、「様々な情報活用の場面へ首尾一貫した情報提供ができるように、構造的に情報保全するコンテキスト」という第三のコンテキストの存在が想定される。
「情報を保全したい」とは端的に更新処理に関わる要求であり、「情報を活用したい」とは端的に参照処理に関わる要求である
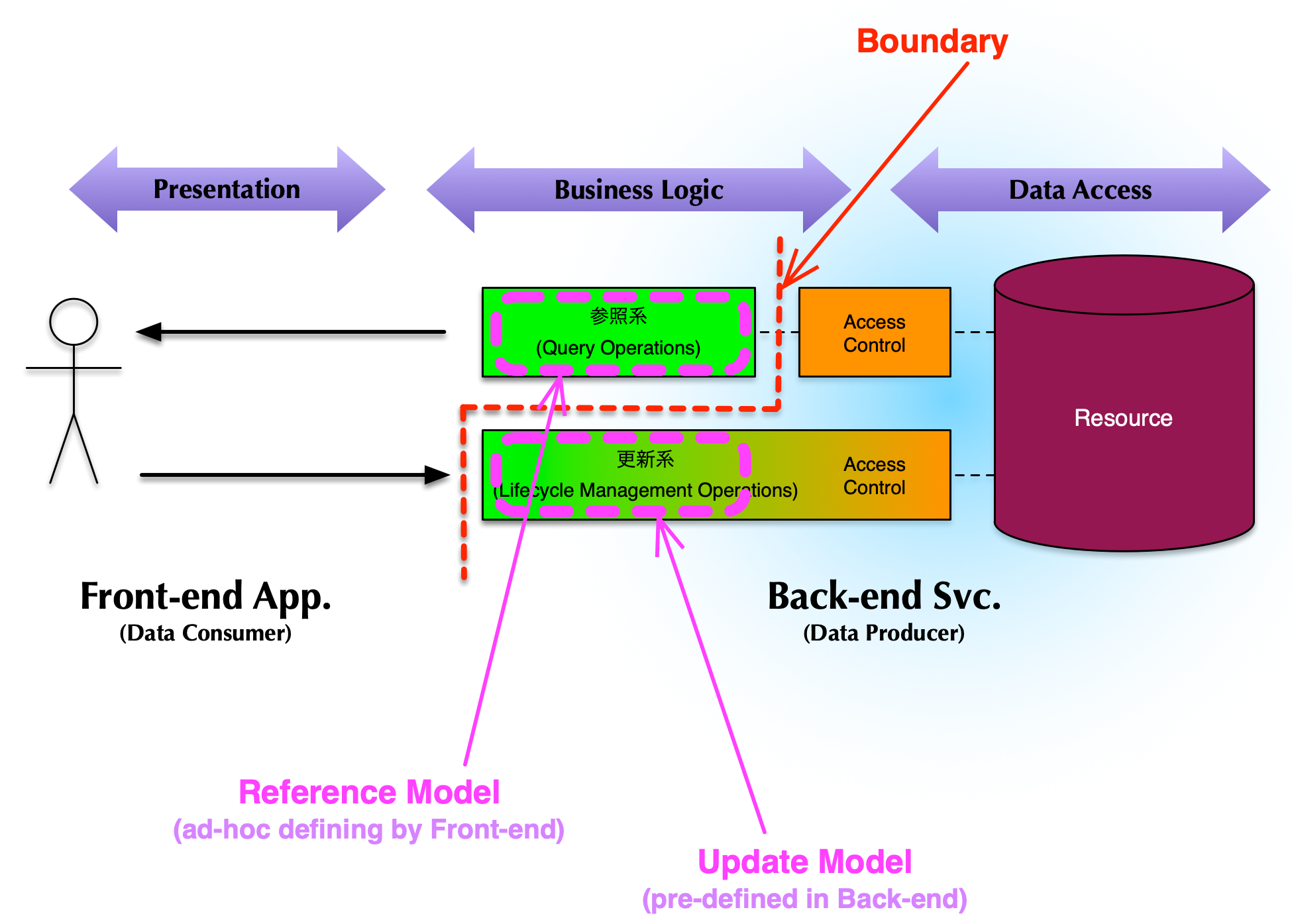
前節の話を少し実装局面側へ少し進めてみる。「情報の保全」とは、データの物理的な構造と、そのデータの変更手続き群に対する一貫性の問題に還元できよう。「情報の活用」とは、ある物理的な構造を持つデータを、目的(ユースケース)に見合った情報構造となるように、如何に(再)編成できるか、という問題に還元できる。前者は端的に「(データ構造と)更新処理」のことであり、後者は端的に「参照処理」のこと、といえる。
あるデータセットに対する更新処理と参照処理があるとき、更新処理は情報保全側からの要求に基づくのに対し、参照処理は、実は情報活用側からの要求に依存している。このような更新系処理と参照系処理では要求発生源が本質的に異なっているという話を、かつて記事にまとめたのでご参照を。
◇
ここまでをまとめる。
- フロアにはフロアの業務(関心点)があり、厨房には厨房の業務(関心点)がある。
- それぞれの業務を支援するための情報活用ツールとして、それぞれのSoEがある。
- 加えて、二つの業務が連携されて欲しいし、各業務の欲する情報構造の違いを吸収する様な統合された"ドメインモデル"が欲しいと考える事業者がいる。統合された"ドメインモデル"を担うシステムをSoRと再定義する。(※ちなみに、統合モデルは分析的には見出せず、意図を以って構成するしかないと考える。この点で、DDD本の「象のモデル」の例はミスリードを誘うと考えている。)
- SoEとは情報活用の場面であり、SoRとは(後の情報活用のための)情報保全の場面だといえる。
- 情報活用とは端的に参照系処理の話であり、情報保全とは端的に更新系処理の話である。
- とあるデータセットについての参照系処理は、つまり、情報活用側(SoE側)が要求源となるし、更新系処理は情報保全側(SoR側)が要求源となる。このような"非対称性"がある。
「事業のモデル」の実態は「帳簿システム」といえる
ここで改めて「事業のモデル」とは何なのか考察する。
この問いに対して、極めて示唆的な杉本氏(@sugimoto_kei)のツイートを参照する。
RDBがリレーショナルモデルを採用しているのは、帳簿システムのユーザーインターフェースとして適切だ(とコッド博士が考えた)からであって、実装メカニズムとして有用だからということでは無いんですね。リレーショナルモデルはUIなんです。
— 杉本啓 (@sugimoto_kei) January 22, 2019
RDBは、本当は、単なるデータの置き場ではなくて、帳簿システムであるべきだ。基本的なデータ整合性確保の機能を具備しているという意味で、ある程度インテリジェントであり、独立している。オブジェクトは計算システムなので、帳簿システム+計算システムで全体システムになる。
— 杉本啓 (@sugimoto_kei) January 22, 2019
SoRとは事象を記録していくことが役目だと言われる。「複写式伝票」も、注文の発生事実を記録することが主要な役割だと言える、その注文の発生事実を、ホール側はホール側の業務遂行のために、厨房側は厨房側の業務遂行のために異なる方法で活用している。杉本氏のいう「帳簿システム」とは、この「事象発生の事実記録」をまさに実施しているシステムと言える。「事業のモデル」とは、即ち「事実記録をしている帳簿の集合体」なのだと帰結できるだろう。
であれば、RDBが延々と使われ続ける背景理由も分かってくる。つまり、事業のモデル=帳簿システムを実装するための業務基盤として、RDBのリレーショナルモデルは、あまりにも完成されているのだ。
加えて、本記事のストーリーに、杉本氏のツイートに対する解釈を乗せていくと次の様な結論が見えてくる。
- 「帳簿」とは、事業者(アクター)にとってのユーザーインターフェースの形式(=ユーザーイリュージョン)である。
- RDBは、それ自体が、そういうユーザーインターフェース(=ユーザーイリュージョン)を実現している。
総まとめ
飲食店における複写式伝票のモデルの初期分析では、ホールスタッフアクターと厨房スタッフアクターだけが見えていた。"境界付けられたコンテキスト"も、せいぜいその二つかと思われた。しかし、両者の連携を実現させ、事業を成り立たせるための「帳簿システム」が実は存在していた。この帳簿システムは事業者アクターが欲し考案したものである。「帳簿」はそのような事業者にとってのユーザーインターフェース(ユーザーイリュージョン)となる。
SoEとは、現場業務での情報活用を目的とした、実装的に言えば参照系主体のサブシステム、だと再定義された。SoRとは、事業としての情報保全を目的とした、実装的に言えば更新系主体のサブシステム、だと再定義された。SoEにはユーザーインターフェースがあって、SoEはユーザーイリュージョンを実現している、という理解は当然にあったが、実は、SoRにも"帳簿"という事業者向けのユーザーインターフェースがあって、そのようなユーザーイリュージョンを実現していた。
〜・〜
<12月22日追記>
※本記事の続きを書きました。よろしくどうぞ。