最近業務で新しいことにチャレンジする機会が多いので、それらを時間が許される範囲で投稿して行こうと思います。
まずは軽くAIの現状を個人的に纏めてみました。
AIとは
 最近流行りのAI(人工知能)ですがそもそもAIとは何でしょうか?
実は厳密な定義は無いらしく人によって曖昧なものらしいです。
とはいえ、私の周りでは下の図のような解釈が一般的なように感じます。
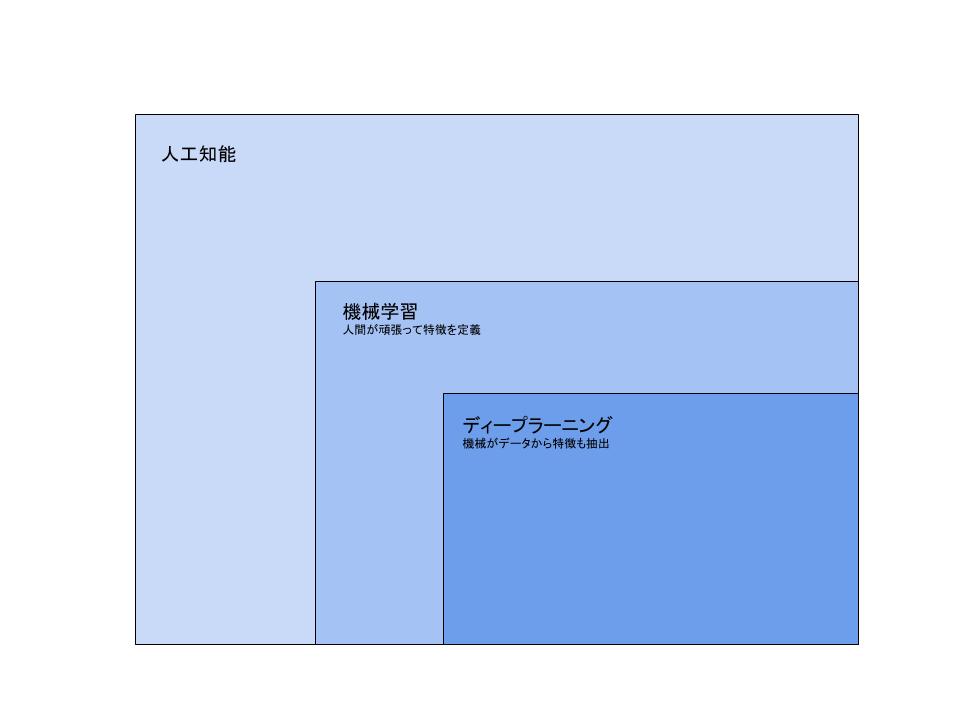
>人工知能:人工的にコンピュータ上などで人間と同様の知能を実現させようという試み、或いはそのための一連の基礎技術を指す。
>機械学習:人工知能における研究課題の一つで、人間が自然に行っている学習能力と同様の機能をコンピュータで実現しようとする技術・手法のことである。
>ディープラーニング:多層のニューラルネットワークによる機械学習手法である。
最近流行りのAI(人工知能)ですがそもそもAIとは何でしょうか?
実は厳密な定義は無いらしく人によって曖昧なものらしいです。
とはいえ、私の周りでは下の図のような解釈が一般的なように感じます。

>人工知能:人工的にコンピュータ上などで人間と同様の知能を実現させようという試み、或いはそのための一連の基礎技術を指す。
>機械学習:人工知能における研究課題の一つで、人間が自然に行っている学習能力と同様の機能をコンピュータで実現しようとする技術・手法のことである。
>ディープラーニング:多層のニューラルネットワークによる機械学習手法である。
(Wikiより)
そして、現在AIとして話題になってる技術は基本的にディープラーニングに関連するものが多いように感じます。
ディープラーニングとは
ディープラーニングとは簡単に言うと人間(動物?)の脳(ニューロン)の仕組みを参考にした機械学習の一種です。
脳はニューロンという神経細胞同士がつながっており、それぞれが微細な電気信号を送り合うことにより複雑な処理をしています。
その仕組みを模したのがディープラーニングという訳です。
ディープラーニングの先駆けとなったのは1957年に発表されたパーセプトロンという非常に単純なアルゴリズムであり、内容としては下記の図の通り複数の入力を受けてある条件を満たした時に出力が発生するというものです。
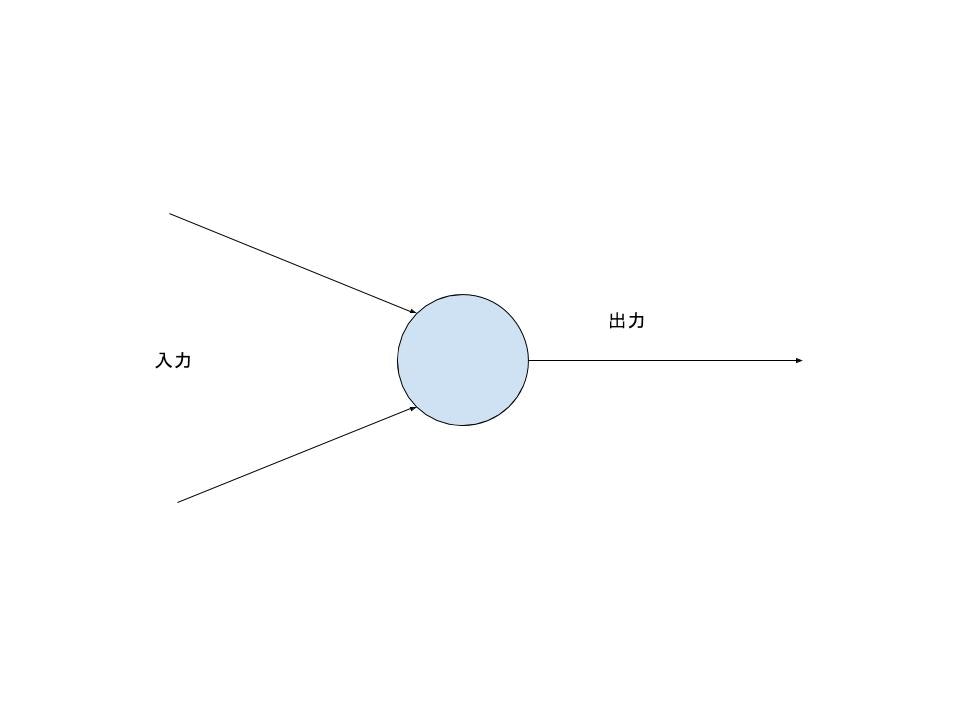
ディープラーニングとは上記のパーセプトロンの考え方をベースにして多層化したものを指します。
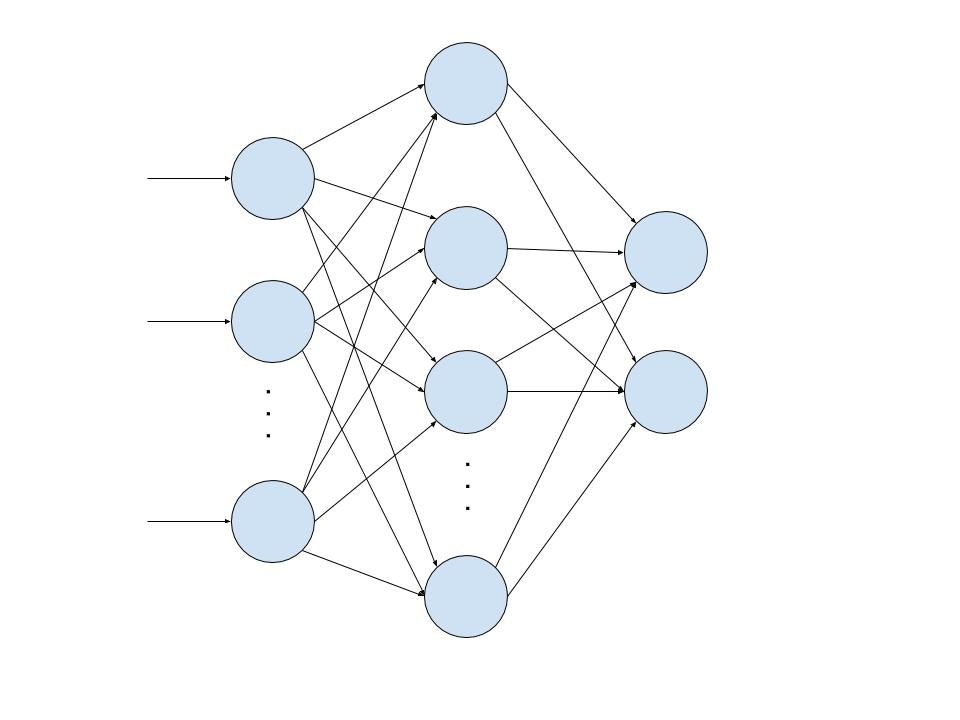
ちょっと面白い話としてディープラーニングがなぜ画像の分類などで劇的な成果を出しているのか
実はいまいち分かってないのが現状です。
例えばニューロンを多層化する際に次の層に出力を伝えるかどうかを判断するアルゴリズムを活性化関数というのですが、数年前まで主流だったシグモナイト関数をReLU関数というよりシンプルなものに置き換えると何故か層が深いモデルで劇的に学習が改善した等があります。
脳のニューロンが次のニューロンに信号を伝達するかしないかの動きがシグモナイト関数よりReLU関数の動きに近いのが理由という話を聞いたことがありますが、理由は不明なのです。
なぜ今ディープラーニング
パーセプトロン自体は随分昔からある技術なのになぜ今ディープライニングが人気なのか?
まず最初に、深いニューラルネットワークを学習させるには膨大な量の計算が必要であり、当時は現実的ではなかった。1957年といえばまだ真空管の時代でしょうか?

次に大量の学習データが用意出来るようになったからです。
ディープラーニングでは最初に学習フェーズといって大量のデータセットとそれに対する正解を用意する必要があります。
例えば猫の種類を見分けるネットワークを構築する場合はペルシャ猫の写真200枚、アメショの写真200枚、シャム猫の写真200枚といった感じに相当な数の画像を用意する必要があります。
今ならネットで用意できますが、当時はかなり大変だったのではないのでしょうか。
AI関連技術
最後にAIに関連する技術を列挙します。
AIに関連する技術を利用するのであればCloudのAPIを呼べば簡単に利用出来ます。
また、利用だけでなくAIを研究したい方であれば研究を前提としたフレームワークも各種そろっています。
それぞれの細かい内容はまた別の機会に掘り下げていければと思います。
シンギュラリティが起きるのではないかと世界の頭が良い人たちが言っていますが、はたしてどうなのでしょう?
もし興味を持った方がいれば本記事がAIの入り口になってくれれば幸いです。

Cloud系API
| サービス名 | 概要 |
|---|---|
| Amazon Rekognition | ・写真から物体の検出 ・顔解析(女性、笑っている等) ・顔比較、二枚の写真が同一人物か |
| Amazon Polly | テキストを読んでくれる |
| Amazon Lex | ・コールセンターボットの作成 ・情報ボット作成 ・アプリケーションボット作成 ・エンタープライズ生産性ボット作成 |
| CLOUD JOBS API | 求人のマッチ |
| CLOUD NATURAL LANGUAGE API | ・構文解析 ・エンティティ分析 ・感情分析 ・エンティティ感情分析 |
| CLOUD SPEECH API | 音声認識 スピーチをテキストに書き起こす |
| CLOUD TRANSLATION API | 翻訳 |
| CLOUD VISION API | ・ラベル検出(乗り物や動物など) ・商品ロゴ検出 ・ランドマーク検出 ・光学式文字認識(OCR) ・顔検出 |
| CLOUD VIDEO INTELLIGENCE | ・ラベル検出 「犬」、「花」、「車」などの動画内のエンティティを検出 ・ショット変更の検出 動画内のシーンの変更を検出 |
| Natural Language Classifier | ・テキストの内容を分類する 「プライベート」「仕事」「プロモーション」のように |
| Personality Insights | 文章から性格の分析 |
| Visual Recognition | ・クラス(犬等)の説明 ・クラスの分類構造 ・顔検出 (性別、年代、有名人) ・類似イメージと信頼度スコア |
| Language Translator | 翻訳 |
| Speech to Text | 音声から認識した単語のテキストの書き起こし スピーチの書き起こし |
| Text to Speech | テキストから音声を合成してくれる |
| Computer Vision API | ・顔検出 ・タグ付け ・OCR ・手書き文字読み取り(英語だけ) ・著名人およびランドマークの認識 ・ビデオリアルタイム解析 ・サムネイルの生成 |
| Face API | ・2 つの顔が同一人物のものである確率を検証 ・年齢、感情、性別、姿勢、笑顔等を分析 ・似た顔の検索 ・顔のグループ化 |
| Content Moderator | ・画像のモデレート ・テキストのモデレート ・ビデオのモデレート ・目視レビュー ツール |
| Emotion API | ・画像の感情を認識 ・ビデオの感情を認識 |
| Video API | ・ビデオのブレを補正 ・顔を検出して追跡 ・モーション検出 動き検出 ・ビデオのサムネイルを作成 勝手に重要な部分を抜粋して動画を作る |
| Custom Vision Service | 画像の新たなラベルを学習させる |
| Video Indexer | ビデオを分析して人やキーワード等を抜粋する |
| Speaker Recognition API | 話すことにより人を認証 |
| Bing Speech API | オーディオをテキストに変換 |
| Custom Speech Service | ・カスタム言語モデルの作成 ・カスタム音響モデルの作成 ・カスタム モデルのデプロイ 誰かに特化したようなモデルの作成 |
| Text Analytics API | ・評判分析 否定的か肯定的か ・重要なフレーズを抽出 ・トピック検出・言語を検出 英語、日本語等 |
| Translator Text API | 翻訳 |
| QnA Maker API | 既存のコンテンツから FAQ サービスを作成 既存の質問票から文脈等を理解して、質疑応答サービスの構築 |
| Bing Autosuggest API | 検索枠の自動補完 あんまりAI関係ない |
| Bing Image Search API | Web画像検索 |
| Bing News Search API | Webニュース検索 |
| Bing Video Search API | 動画検索 |
| Bing Web Search API | Web検索 |
FrameWork
| 名前 | 公式概要 |
|---|---|
| Chainer | A Powerful, Flexible, and Intuitive Framework for Neural Networks |
| Keras | Kerasは,Pythonで書かれた,TensorFlowまたはCNTK,Theano上で実行可能な高水準のニューラルネットワークライブラリです. |
| TensorFlow | An open-source software library for Machine Intelligence |
| Caffe | Caffe is a deep learning framework made with expression, speed, and modularity in mind. It is developed by Berkeley AI Research (BAIR) and by community contributors. Yangqing Jia created the project during his PhD at UC Berkeley. Caffe Is released under the BSD 2-Clause license. |
| Scikit-learn | Simple and efficient tools for data mining and data analysis Accessible to everybody, and reusable in various contexts Built on NumPy, SciPy, and matplotlib Open source, commercially usable - BSD license |