経緯
少し前に「Google Apps Scriptで配列要素の総和処理を高速で行いたい」という記事を投稿させていただきました。そのときは他で使う予定がなかったためライブラリはGAS用のみ作成していましたが、最近になってPythonでも大きな配列を触ることになったため配列データをcsvファイルへ出力するための方法について検討しました。
調べていましたところ、okadate氏の記事に出会いました。記事にはcsvファイルを出力するためにcsvモジュール、pandasモジュールがあるとのこと。扱うデータ量が大きいため、やはりその処理速度が気になり、通常運用する前に確認することにしました。
そこで、csvモジュール、pandasモジュールのcsv出力の処理速度評価を行いました。リファレンスとして、"+"演算子を使用したスタンダートな手法、GASでの総和処理用ライブラリをPythonへ移植したもの(souwapy)を使用しました。
評価方法
csvファイル出力の速度評価のために下記モジュールを使用しました。測定に使用した計算機のスペックはCPU Core i5-3210M, Memory 8GB, OS Windows10 (x64) (v1607)です。Pythonのバージョンは3.5.2です。
| モジュール名 | 備考 |
|---|---|
| csv | Pythonの標準ライブラリ付属 |
| pandas | Pythonのデータ解析用モジュール、バージョンは0.19.0 |
| souwapy | 自作、バージョンは1.1.1 |
| standard algorithm | 配列要素を順に加算する一般的な方式 |
速度評価のために使用したスクリプトは下記の通りです。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
import time
import csv
import pandas as pd
import SOUWA
def measure_csv(ar):
start = time.time()
with open('csvmod.csv', 'w') as f:
writer = csv.writer(f, lineterminator='\n')
writer.writerows(ar)
Processing_time = time.time() - start
print("Processing time = {0}".format(Processing_time) + " [s]")
return
def measure_pandas(ar):
start = time.time()
df = pd.DataFrame(ar)
df.to_csv('pandastest.csv', header=False, index=False)
Processing_time = time.time() - start
print("Processing time = {0}".format(Processing_time) + " [s]")
return
def measure_souwapy(ar):
start = time.time()
s = SOUWA.sou()
result = s.getcsvdata(ar, ",", "\n")
with open('souwa.csv', 'w') as f:
f.write(result)
Processing_time = time.time() - start
print("Processing time = {0}".format(Processing_time) + " [s]")
return
def measure_standard(ar):
start = time.time()
result = ''
for dat in ar:
result += ",".join(dat) + "\n"
with open('standard.csv', 'w') as f:
f.write(result)
Processing_time = time.time() - start
print("Processing time = {0}".format(Processing_time) + " [s]")
return
def MakeArray(row):
theta = [0 for i in range(row)]
for i in range(0, row):
theta[i] = [str(i + 1).zfill(9), 'a', 'b', 'c', 'd', 'e']
return theta
ar = MakeArray(10)
measure = 1
if measure == 1:
measure_csv(ar)
elif measure == 2:
measure_pandas(ar)
elif measure == 3:
measure_souwapy(ar)
elif measure == 4:
measure_standard(ar)
データとしての配列は9桁でゼロパディングした数字文字列とアルファベットa - eの6要素の1次元配列を使用しました。これは丁度運用時のcsvファイルにしたいデータの内容に相当します。ここでは全ての要素でデータサイズを合わせるためにゼロパディングして、各アルファベットも1文字としています。配列数を10としてcsvファイルにしたデータは下記の通りです。
000000001,a,b,c,d,e
000000002,a,b,c,d,e
000000003,a,b,c,d,e
000000004,a,b,c,d,e
000000005,a,b,c,d,e
000000006,a,b,c,d,e
000000007,a,b,c,d,e
000000008,a,b,c,d,e
000000009,a,b,c,d,e
000000010,a,b,c,d,e
区切りに","、改行コードには"\n"を使用しています。これらを合わせると1行当たり20バイトになります。また、csvモジュール、pandasモジュール、souwapyモジュール、standardアルゴリズムで全て同じデータになることを確認しています。速度評価は、配列からcsvファイルを出力するまでを対象としました。
評価結果
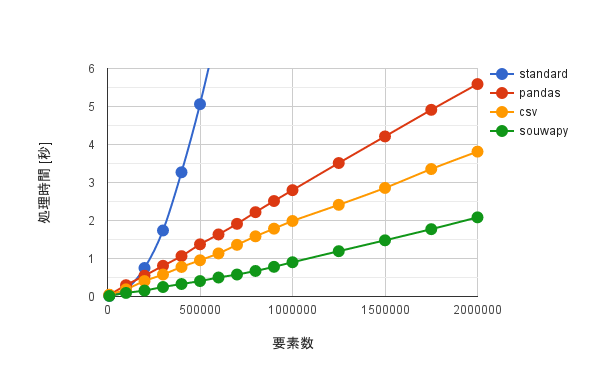
結果は上図の通りです。横軸は配列要素数、縦軸はcsvファイル出力完了までに要した時間です。青色、赤色、橙色、緑色は、それぞれstandardアルゴリズムによるもの、pandasモジュール、csvモジュール、souwapyモジュールによるものです。結果として、配列データをcsvファイルへ出力する処理時間は、standard, pandasモジュール、csvモジュール、souwapyモジュールの順に速くなることが分かりました。平均処理時間の比は、pandasモジュールに対してcsvモジュールは1.4倍の速度、csvモジュールに対してsouwapyモジュールは2.3倍の速度、pandasモジュールに対してsouwapyモジュールは3.1倍の速度でした。
細かく見ていくと、standardアルゴリズムでは処理時間は要素数の2乗に比例しています。"+"演算子を使って配列を順に加算していくstandard方式では処理中に動く総データ量は配列要素数の2乗に比例して増加することが分かっています。一方、各モジュールでは処理時間は要素数に対してリニアに比例しています。これらのことから、csvモジュール、pandasモジュールはcsvデータに変化する際に何らかの最適化処理が行われていると推測することができます。csv, pandasがどのようなアルゴリズムで配列をcsvファイルに変換しているのか追ってみたのですが、残念ながら自分では辿り着くことができませんでした。
要素数が少ない場合、各モジュールで処理時間には大差は無いと判断して良いかと思います。要素数が大きくなってくるとその効果が現れてきます。souwapyモジュールは配列データをcsvデータに変換することに対して特化したアルゴリズムで行っていることもあり、速い結果になっていますが、今のところこの1つの機能しかないため他の高機能なモジュールと組み合わせて最後のcsvファイル出力でのみ使用すると良さそうに思いました。
おまけ
souwapyモジュールは、GAS用ライブラリを移植したものです。要素数が大きくなると効果がありそうでしたので、お役に立つことができればとPyPIへアップロードさせていただきました。インストール方法、使用方法は下記の通りです。
今のところ配列を総和処理する機能しかありません。今後他の機能が必要になった際は追加したいと思います。
- インストール方法
$ pip install souwapy
- 使用方法
from souwapy import SOUWA
s = SOUWA.sou()
result = s.getcsvdata(array, ",", "\n")
arrayは配列で、区切り、改行コードは随時変更してください。
詳細は下記をご覧ください。