はじめに
こんにちは、炭山水です。
ちょっとシリーズ物でも始めてみようかと思い、昔やってたクラスタリングのおさらいでもしつつ、Qiitaにまとめていく試みでもしてみようと思います。
まずはデータマイニングとかクラスタリングと呼ばれるデータ分類の基本である「k平均法」について、何回かに分けてJavaで少しずつ実装進めながら解説(という名の僕の復習)をしていこうかなと思います。
今回の第0回ではとりあえず前置きとか前提中心にお話ししようかなと思います。具体的な解説は次回からかな。
触れること、触れないことやその他注意書き
本シリーズではあんまりガチな「データマイニング」とか「クラスタリング」の種類の説明、用途の説明には触れず、あくまでk平均法と呼ばれる手法をとにかく最後まで実装してみることを目的とします。
座学チックに知識増やすより、手を動かした方が雰囲気つかめますからねという考えです。
手を動かしてみて雰囲気をつかむということを目的にしていますので、ありものの分析用ライブラリとかは使わずに自分で実装していきます。
あと、僕がこの辺の分野のことを知っていたのは10年以上前のことで、特にそれ以後キャッチアップとかはしていないので、情報が古いよということはご承知おきください。
前提
多少なりとも言語の知識はあるものという前提でお話しさせていただきます。また、筆者である僕が、最近仕事で使っているSpringBootをプライベートでも触ってみたいという動機も混ざっているので、SpringBootベースで進めていきます。
っていっても業務ロジック書くわけじゃないので、ほとんどSpringBootらしい話は出てこないと思いますけどね。ほぼJavaそのもので書くことになると思います。アノテーションを前置き無しで使っても勘弁してねくらいの話です。
k平均法ってどんなことができるの?
詳しいロジックは次回以降に回すとして、すっごくざっくりというと、
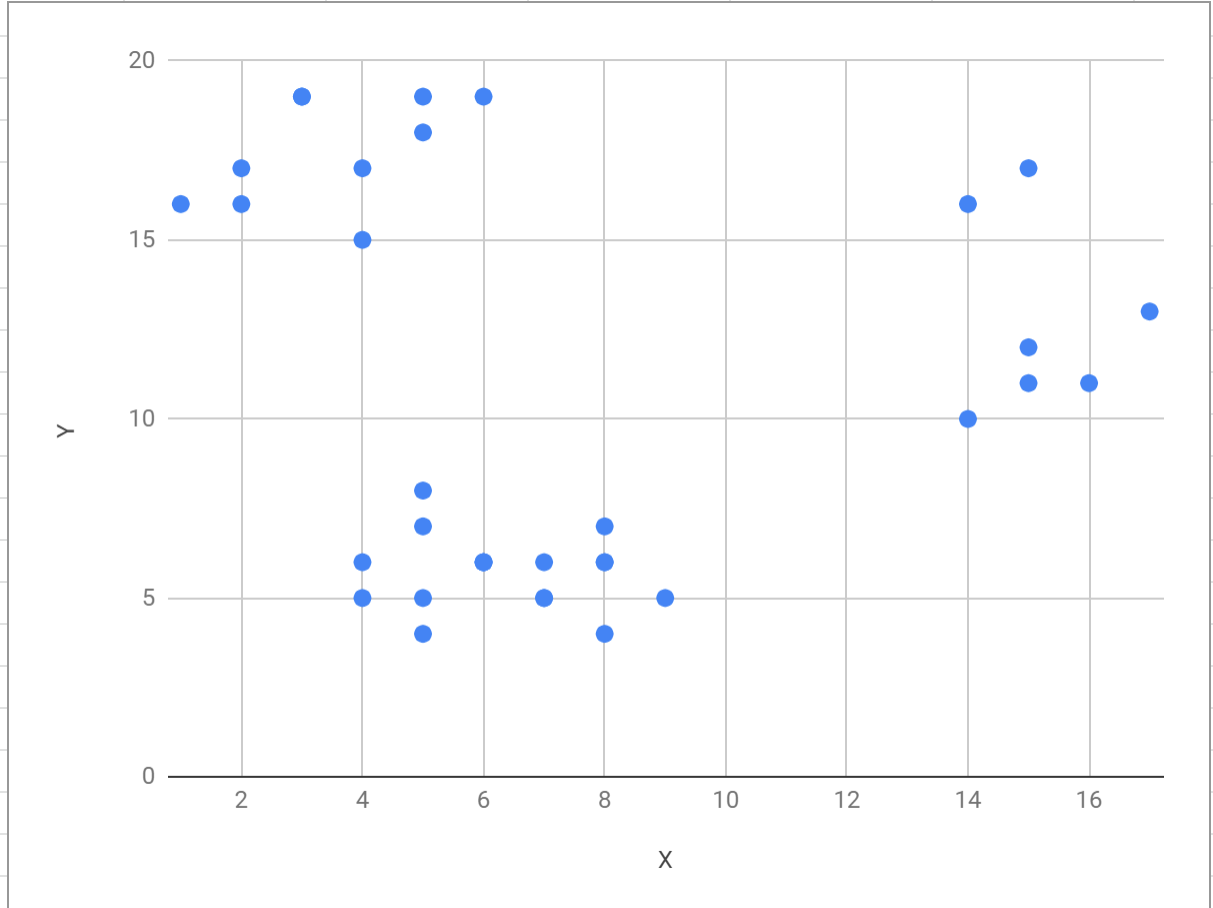
こういう感じのデータを
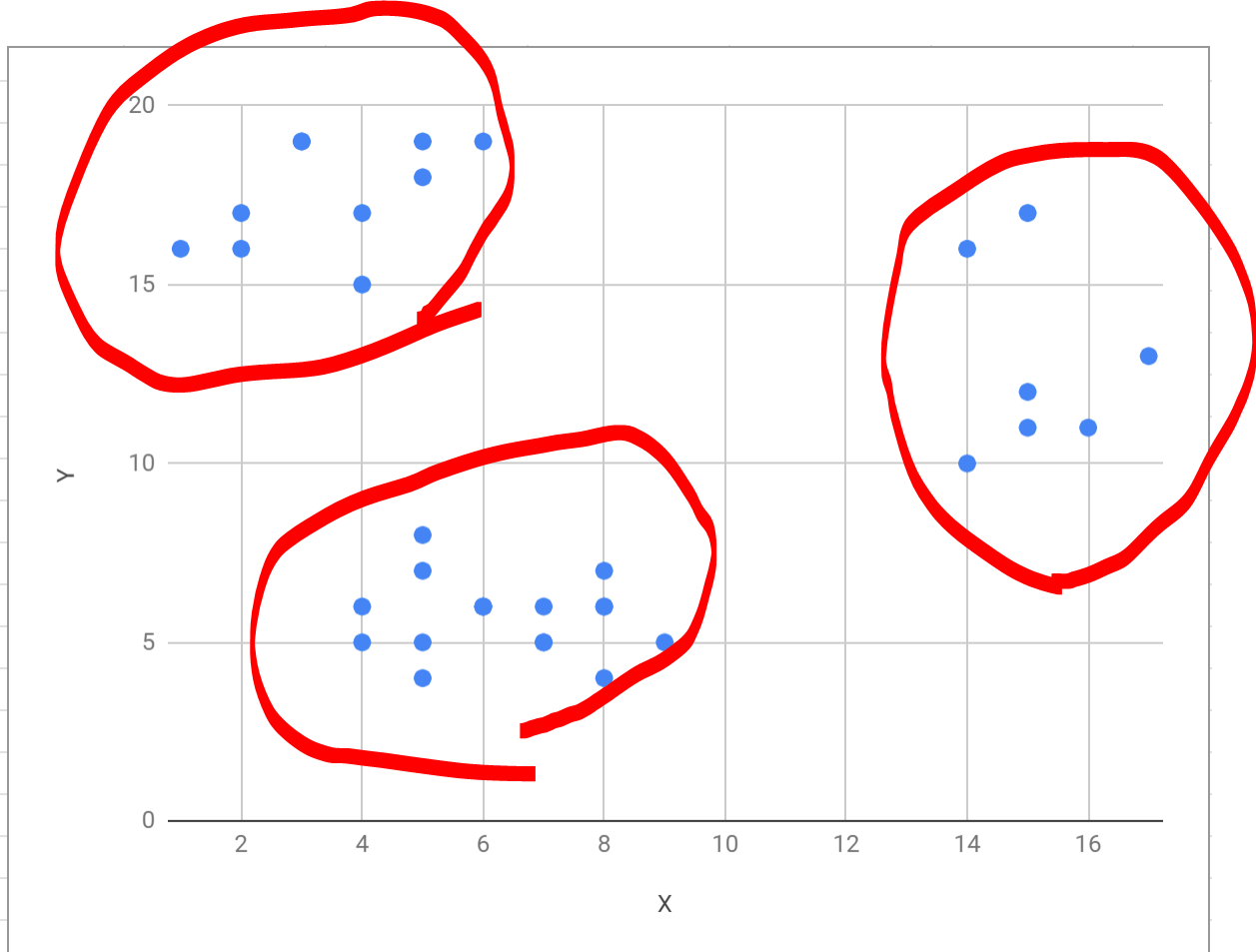
こういう感じに分類することができます。
図では適当にXとかYとか置いたのですが、「とあるコンビニ利用者の購入金額と時間帯」とかそういうのをイメージしてもらうといいかと思います。
まあ、現実にこんなにきれいに集まってるデータはないのですが、それにしてもこのくらいのサンプル数を人間の目で見れば、なんとなーくグループに見えるものでも、コンピュータになんら前情報なく判別させようとするとテクニックが必要なわけです。
データが増えてきたり軸がXYじゃなかったりするとコンピュータの力を借りる必要がありますからね。
では次回
今回はざっと前提の話と、なにができるかの話をしました。
次回からは実際に分類ロジックに必要な部品を説明しながら実装していきたいと思います。
次回
【コンピューターサイエンス入門第1回:機械学習やってみる】 k平均法をJavaで実装してみよう~座標の概念について~