前置き
G検定をまとめるための記事の一つです。私のまとめ方の癖で「気になる物をいくつか上げて、流れを作りながら細かく見ていく」という事をしています。とりあえず、少しは参考になるくらいの粒度で記事を上げてはいるつもりです。随時、更新する予定ですので多めに見て頂ければ幸いです。
概要:近年(2022)はAttention機構が良く使われていますね
先日、「きゅうりの仕分けから始めるAI」という記事を書かせて頂きました。ここで紹介したきゅうり農家では物体検出を使っていました。ディープラーニングの構造も様々ですが、大きく分けてCNN, RNN, Attentionに分けられると考えています。今回はいろんな場面で使われているTransformerについて見ていきたいと思います。
Transformerの構造
全体の構造は以下の様になります。
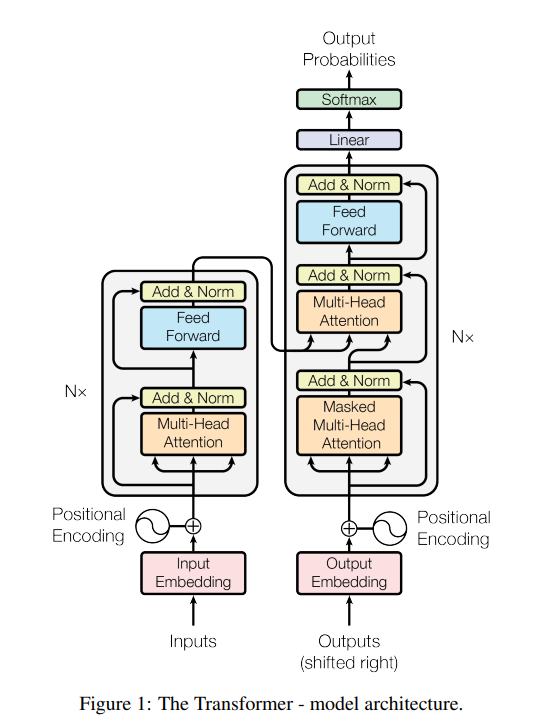
ここで、更にEncoderとDecoderを定めておきます。

Encoderの構造

Decoderの構造
(参考:Ashishら(2017),"Attention Is All You Need",arXiv)
データの流れ
流れとしては、3つに分けました
- Encoderの流れ
Input=>Input Embedding => Positional Encoding => Encoder => Decoder - Decoderの流れ
Outputs => Output Embedding => Decoder - EncoderとDecoderが合流してからの流れ
Decoder => Linear => Softmax => Output Probabilities
Transformersで使用される要素技術
Attension, Dot-Product Attention, Multiplicative Attention, Source-Target-Attention, Self-Attention, Scaled Dot-Product Attention, Multi-Head Attention, Position-wise Feed-Forward Network, Positional Encoding
参考