概要
Javaのみを使用してKaggleで戦うことはできるのでしょうか?あえてやってみました。
この記事でやること
Kaggleの初心者向けの課題として有名なタイタニックの生存者予測(「Titanic: Machine Learning from Disaster」)をJavaのみで実装してみたいと思います。この課題は、タイタニックに乗船した顧客の名前、性別、年齢、チケットの情報などから生存したかどうかを予測するというものです。
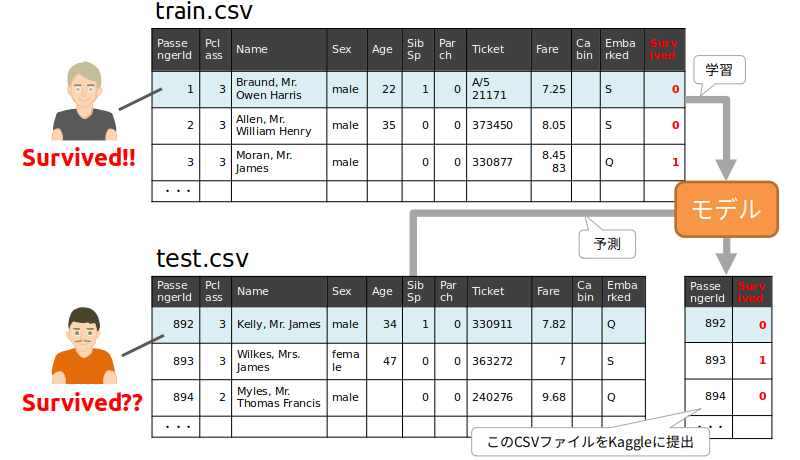
与えられた学習用のデータ(train.csv)から学習したモデルを構築し、テストデータ(test.csv)に含まれる人の生存を予測し、その結果の正解率を争うというのがこのコンペになります(ゲーム感覚で生死を予測するのって...と思ってしまいますが)。
まずは最小限の実装で生存者を予測してみます。
- 開発環境の構築
- ライブラリー・データ読み込み
- ベースラインモデルの構築
- 予測の出力・提出
※この記事ではここまでを説明します。
次に以下を実装します。
- データの分析
- データの前処理
- 特徴量エンジニアリング
- いくつかのモデルの構築
- クロスバリデーションとグリッドサーチ
- ハイパーパラメーターのチューニング
- モデルのアンサンブリング
Javaの機械学習ライブラリー
と、その前に、そもそもJavaの機械学習ライブラリーにはどのようなものがあるのでしょうか。有名なものとして以下が挙げられるかと思います。
- Apache Mahout: 2009年からある機械学習ライブラリー
- Deeplearning4j: ディープラーニングに特化したライブラリー
- Tribuo: Oracle社がつい先日公開した機械学習ライブラリー
今回は、この中からTribuoを使用してみます。
最小限の実装で生存者を予測
開発環境の構築
Javaなので、とりあえずIntelliJで生存者予測のモデルを構築してみます。
以下のようにIntelliJでMavenプロジェクトを作成して、
pom.xmlに以下を追加します。
<dependencies>
<dependency>
<groupId>org.tribuo</groupId>
<artifactId>tribuo-all</artifactId>
<version>4.0.0</version>
<type>pom</type>
</dependency>
</dependencies>
次にこのページで「Download All」ボタンをクリックして、予測に必要なデータをダウンロードし、解凍後、先ほど作成したMavenプロジェクトのディレクトリーにコピーします。
ディレクトリー構成は以下のようになります。
ライブラリー・データ読み込み
それではまずCSVファイルを読み込んでみましょう。以下を実装し、実行します。
LabelFactory labelFactory = new LabelFactory();
CSVLoader csvLoader = new CSVLoader<>(',',labelFactory);
ListDataSource dataource = csvLoader.loadDataSource(Paths.get("titanic/train.csv"),"Survived");
しかし、NumberFormatExceptionが...
Exception in thread "main" java.lang.NumberFormatException: For input string: "S"
at sun.misc.FloatingDecimal.readJavaFormatString(FloatingDecimal.java:2043)
at sun.misc.FloatingDecimal.parseDouble(FloatingDecimal.java:110)
at java.lang.Double.parseDouble(Double.java:538)
at org.tribuo.data.csv.CSVLoader.innerLoadFromCSV(CSVLoader.java:260)
at org.tribuo.data.csv.CSVLoader.loadDataSource(CSVLoader.java:238)
at org.tribuo.data.csv.CSVLoader.loadDataSource(CSVLoader.java:209)
at org.tribuo.data.csv.CSVLoader.loadDataSource(CSVLoader.java:184)
at org.tribuo.data.csv.CSVLoader.loadDataSource(CSVLoader.java:138)
at TitanicSurvivalClassifier.main(TitanicSurvivalClassifier.java:23)
Tribuoのソースコードを読んでみると、CSVファイルは数値のみで構成されることを前提としている実装で(必ずDouble.parseDouble()している)、この動作を変更することはできそうにありません。おそらく現時点のTribuoの設計思想では、データの前処理は責任の範囲外ということなのでしょう。
少なくともCSVファイルの非数値列を削除する必要があります。CSVファイルの操作はApache Commons CSVなどで実現できますが、先のことを見越して前処理ができそうなライブラリーである「DFLib」を導入します。DFLibはPythonのPandasの軽量なJava実装で、内部でApache Commons CSVを使用しています。
<dependency>
<groupId>com.nhl.dflib</groupId>
<artifactId>dflib-csv</artifactId>
<version>0.8</version>
</dependency>
CSVLoaderでCSVファイルを読み込む前に、以下のようにCSVの「Name」、「Sex」、「Ticket」、「Cabin」、「Embarked」列を削除して(必要な列だけに絞り込んで)、CSVファイルに保存します。
DataFrame df = Csv.loader().load("titanic/train.csv");
DataFrame selectColumns = df.selectColumns("Survived", "Pclass", "Age", "SibSp", "Parch", "Fare");
Csv.save(selectColumns, "titanic/train_removed.csv");
LabelFactory labelFactory = new LabelFactory();
CSVLoader csvLoader = new CSVLoader<>(',',labelFactory);
ListDataSource dataource = csvLoader.loadDataSource(Paths.get("titanic/train_removed.csv"),"Survived");
再度実行します。
Exception in thread "main" java.lang.NumberFormatException: empty String
at sun.misc.FloatingDecimal.readJavaFormatString(FloatingDecimal.java:1842)
at sun.misc.FloatingDecimal.parseDouble(FloatingDecimal.java:110)
at java.lang.Double.parseDouble(Double.java:538)
at org.tribuo.data.csv.CSVLoader.innerLoadFromCSV(CSVLoader.java:260)
at org.tribuo.data.csv.CSVLoader.loadDataSource(CSVLoader.java:238)
at org.tribuo.data.csv.CSVLoader.loadDataSource(CSVLoader.java:209)
at org.tribuo.data.csv.CSVLoader.loadDataSource(CSVLoader.java:184)
at org.tribuo.data.csv.CSVLoader.loadDataSource(CSVLoader.java:138)
at TitanicSurvivalClassifier.main(TitanicSurvivalClassifier.java:31)
が、またもNumberFormatExceptionが。「Age」列に含まれる欠損値を空文字として扱ってしまうようです。DataFrameにはfillNulls()というメソッドがあるので、これでnullをゼロなどに一括置換できますが、読み込んだ欠損値は空文字("")として解釈されてしまうようなので、意図した動作をしません(CSVファイルのロードの仕方に問題があるかもしれませんが...)。ということで、ここでは「Age」列も消してしまいます。
DataFrame selectedDataFrame = df.selectColumns("Survived", "Pclass", "SibSp", "Parch", "Fare");
ベースラインモデルの構築
今度はうまくいきました。では次にモデルを構築して学習を行います。ロジスティック回帰を使用した場合の最低限の実装は以下のようになります。
TrainTestSplitter dataSplitter = new TrainTestSplitter<>(dataource, 0.7, 1L);
MutableDataset trainingDataset = new MutableDataset<>(dataSplitter.getTrain());
MutableDataset testingDataset = new MutableDataset<>(dataSplitter.getTest());
Trainer<Label> trainer = new LogisticRegressionTrainer();
Model<Label> irisModel = trainer.train(trainingDataset);
LabelEvaluator evaluator = new LabelEvaluator();
LabelEvaluation evaluation = evaluator.evaluate(irisModel, testingDataset);
System.out.println(evaluation);
ようやく結果が出ました。268件の検証用データのうち163件が正解で、正解率60.8%です。
Class n tp fn fp recall prec f1
0 170 89 81 24 0.524 0.788 0.629
1 98 74 24 81 0.755 0.477 0.585
Total 268 163 105 105
Accuracy 0.608
Micro Average 0.608 0.608 0.608
Macro Average 0.639 0.633 0.607
Balanced Error Rate 0.361
予測の出力・提出
これでモデルが構築できたので、テストデータを読み込んで予測してみましょう。以下のように実装して確認してみます。
DataFrame dfTest = Csv.loader().load("titanic/test.csv");
DataFrame selectedDfTest = dfTest.selectColumns("Pclass", "SibSp", "Parch", "Fare");
Csv.save(selectedDfTest, "titanic/test_removed.csv");
ListDataSource dataource4test = csvLoader.loadDataSource(Paths.get("titanic/test_removed.csv"),"Survived");
List<Prediction> predicts = model.predict(dataource4test);
System.out.println(predicts);
が、CsvLoader.loadDataSource()は第2引数に目的変数の名前を必要とするようで、"Survived"を渡していたのですが、test.csvにその"Survived"が無いとエラーが出てしまいました。
Exception in thread "main" java.lang.IllegalArgumentException: Response Survived not found in file file:/home/tamura/git/tribuo-examples/titanic/test_removed.csv
at org.tribuo.data.csv.CSVLoader.validateResponseNames(CSVLoader.java:286)
at org.tribuo.data.csv.CSVLoader.innerLoadFromCSV(CSVLoader.java:244)
at org.tribuo.data.csv.CSVLoader.loadDataSource(CSVLoader.java:238)
at org.tribuo.data.csv.CSVLoader.loadDataSource(CSVLoader.java:209)
at org.tribuo.data.csv.CSVLoader.loadDataSource(CSVLoader.java:184)
at org.tribuo.data.csv.CSVLoader.loadDataSource(CSVLoader.java:138)
at TitanicSurvivalClassifier.main(TitanicSurvivalClassifier.java:74)
「何でCSVファイルに目的変数が入ってないといけないんだ」と愚痴りつつ、仕方がないので、提出用のcsvファイル(gender_submission.csv)にあった「Survived」列をDataFrameに付加して、誤魔化すことにしました。
DataFrame dfTest = Csv.loader().load("titanic/test.csv");
DataFrame dfSubmission = Csv.loader().load("titanic/gender_submission.csv");
DataFrame selectedDfTest = dfTest.selectColumns("Pclass", "SibSp", "Parch", "Fare");
selectedDfTest = selectedDfTest.hConcat(dfSubmission.dropColumns("PassengerId"));
Csv.save(selectedDfTest, "titanic/test_removed.csv");
ListDataSource dataource4test = csvLoader.loadDataSource(Paths.get("titanic/test_removed.csv"),"Survived");
List<Prediction> predicts = model.predict(dataource4test);
System.out.println(predicts);
今度こそと思いながら実行すると、見慣れたあの例外が...
Exception in thread "main" java.lang.NumberFormatException: empty String
at sun.misc.FloatingDecimal.readJavaFormatString(FloatingDecimal.java:1842)
at sun.misc.FloatingDecimal.parseDouble(FloatingDecimal.java:110)
at java.lang.Double.parseDouble(Double.java:538)
at org.tribuo.data.csv.CSVLoader.innerLoadFromCSV(CSVLoader.java:260)
at org.tribuo.data.csv.CSVLoader.loadDataSource(CSVLoader.java:238)
at org.tribuo.data.csv.CSVLoader.loadDataSource(CSVLoader.java:209)
at org.tribuo.data.csv.CSVLoader.loadDataSource(CSVLoader.java:184)
at org.tribuo.data.csv.CSVLoader.loadDataSource(CSVLoader.java:138)
at TitanicSurvivalClassifier.main(TitanicSurvivalClassifier.java:73)
test.csvを見てみると、1件だけ「Fare」列の欠損値が...この欠損値もnullではなく空文字("")なので、DataFrame.fillNulls()は使えません。ソースコードを調べた結果、次のような書き方であれば、空文字を置換できることが分かりました。
selectedDfTest = selectedDfTest.convertColumn("Fare", s -> "".equals(s) ? "0": s);
これで予測した結果が出力されました。
[Prediction(maxLabel=(0,0.5474041397777752),outputScores={0=(0,0.5474041397777752)1=(1,0.4525958602222247}), Prediction(maxLabel=(0,0.6969779586356148),outputScores={0=(0,0.6969779586356148)1=(1,0.303022041364385}), Prediction(maxLabel=(1,0.5302004352989867),outputScores={0=(0,0.46979956470101314)1=(1,0.530200435298986}), Prediction(maxLabel=(0,0.52713643586377),outputScores={0=(0,0.52713643586377)1=(1,0.4728635641362}), Prediction(maxLabel=(0,0.5071805368465395),outputScores={0=(0,0.5071805368465395)1=(1,0.492819463153460}), Prediction(maxLabel=(0,0.5134002908191431),outputScores={0=(0,0.5134002908191431)1=(1,0.4865997091808569}),
・・・
あとは提出用のCSVファイルに保存するだけです。Pythonを使えば、簡単に実装できるのですが、DFLibやTribuoで実現しようとすると意外と簡単ではなく、しばらくドキュメントやソースコードを眺めてみましたが、時間がかかるかもしれないので、Java標準のAPIで以下のように実装しました。
AtomicInteger counter = new AtomicInteger(891);
StringBuilder sb = new StringBuilder();
predicts.stream().forEach(p -> sb.append(String.valueOf(counter.addAndGet(1) + "," + p.getOutput().toString().substring(1,2)) + "\n"));
try (FileWriter fw = new FileWriter("titanic/submission.csv");){
fw.write("PassengerId,Survived\n");
fw.write(sb.toString());
} catch (IOException ex) {
ex.printStackTrace();
}
p.getOutput().toString()の2文字目が予測した値(0か1)なので、そこを取り出して、java.io.FileWriterで書き込むというイマイチな実装です。ちなみにcounterは提出するファイルに含める「PassengerId」の892~1309です。
提出用のCSVファイルが出力されたので、Kaggleのサイトにアップロードして、スコアを確認してみましょう。
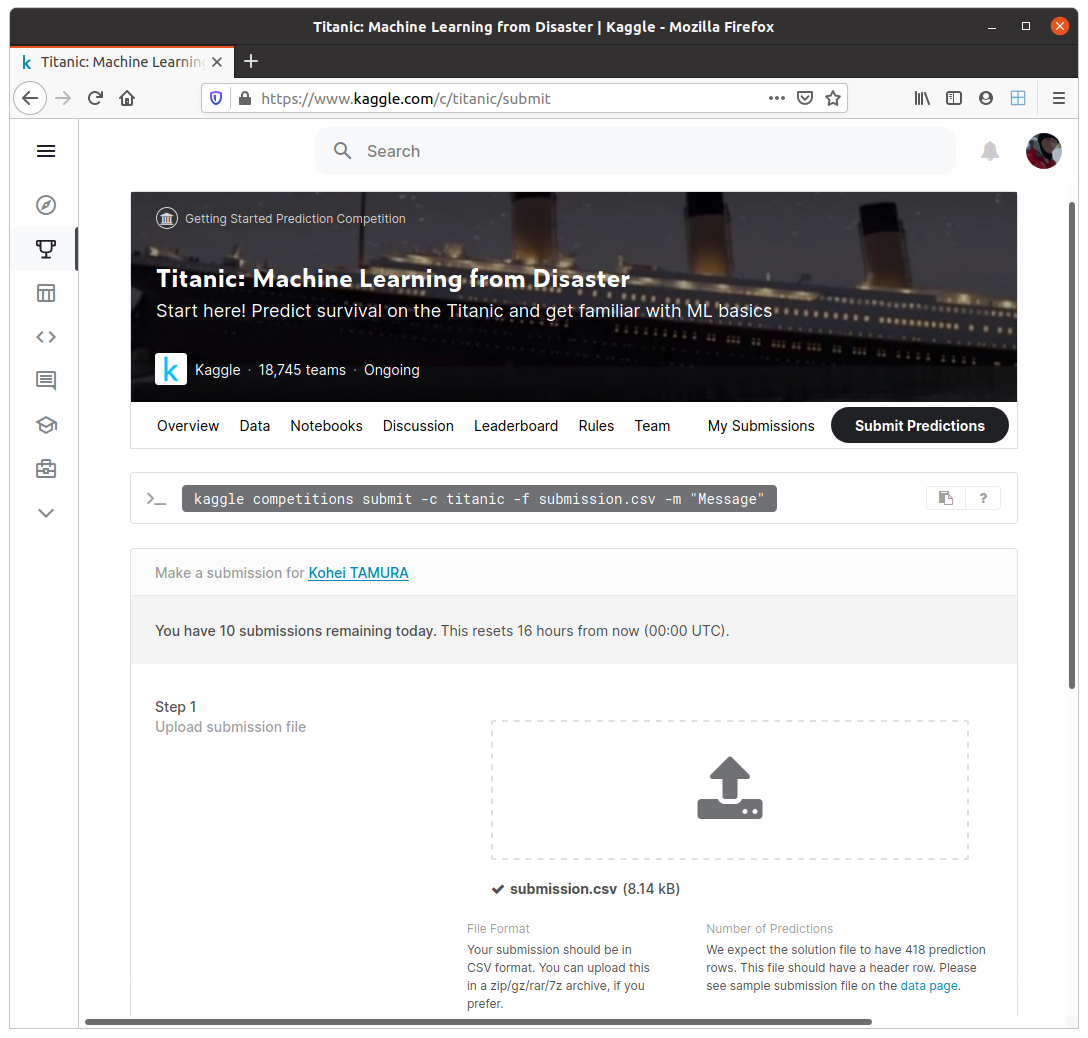
Kaggleでのスコアは0.56220でした。低いですが、とりあえずはアップロードするところまではできました。
続編について
今回は提出用のCSVファイルを出力するという最低限のことだけをやってみました。次回はJupyter Notebook上でデータを可視化したり、前処理やチューニング、アンサンブリングなどができるのか検証してみたいと思います。
補足
今回の実装ではCSVLoaderを使ってCSVファイルをロードしていました。CSVファイルをロードするなら、このクラスを使うのが当たり前だと思ったからです。ところが、Tribuo開発者の方によると、実は今回のようなケースではCSVLoaderを使わずに、RowProcessorとCSVDataSourceを使うのが適切とのことでした。以下のように実装すると、前述のコードと同じ結果になります。
Tokenizer tokenizer = new BreakIteratorTokenizer(Locale.US);
LabelFactory labelFactory = new LabelFactory();
ResponseProcessor<Label> responseProcessor = new FieldResponseProcessor<>("Survived","0",labelFactory);
Map<String, FieldProcessor> fieldProcessors = new HashMap<>();
fieldProcessors.put("Pclass", new DoubleFieldProcessor("Pclass"));
fieldProcessors.put("SibSp", new DoubleFieldProcessor("SibSp"));
fieldProcessors.put("Parch", new DoubleFieldProcessor("Parch"));
fieldProcessors.put("Fare", new DoubleFieldProcessor("Fare"));
RowProcessor<Label> rp = new RowProcessor<>(responseProcessor,fieldProcessors);
Path path = Paths.get("titanic/train.csv");
CSVDataSource<Label> source = new CSVDataSource<>(path,rp,true);
TrainTestSplitter dataSplitter = new TrainTestSplitter<>(source, 0.7, 1L);
さらにテキスト列にはIdentityProcessorを使用することで、自動的にOne-hot-encodingをしてくれるようです。例えば、male、femaleという2つの値を持つ「Sex」列に適用すると、
fieldProcessors.put("Sex", new IdentityProcessor("Sex"));
値が0/1のSex@male列とSex@female列が追加されます(2択なので1列で十分ですが)。これにより、精度も0.746まで上がります。
同様にC、S、Kという3つの値を持つ「Embarked」列にも適用すると、
fieldProcessors.put("Embarked", new IdentityProcessor("Embarked"));
さらに精度が上がります、と言いたいところですが、実際には下がります。「Embarked」列には1件だけ値が空の行があり、これにより結果的に学習用データと検証用データの列数がずれて正しく動作しなくなるためです。空の値を最頻値のSに置換したいところですが、Pythonのようにさっと実現できないのが辛いところで...そのあたりも含めてまた次回に。
感想・結論
「Javaのみを使用してKaggleで戦うことはできるのでしょうか?」という問いに対する私の答えは「現時点ではかなり難しい。」です(最初から結論は分かっていたのですが)。Tribuoはまだ公開されたばかりということもあって、インターネット上に情報が非常に少ないうえ、ガイドやJavadocも不十分で調査にかなりの時間がかかります。そして、そもそも機能が足りていません。データに含まれるnull値を中央値で埋めるようなメソッドですら用意されていません。
Pythonで簡単にできることが簡単にできないのが現状ですが、逆に言えば不足する機能が多いので、貢献(プルリク)するチャンスは非常に多いと思います。機械学習に興味のあるJavaプログラマーの方は勉強も兼ねて、このプロジェクトに貢献してみてはいかがでしょうか。まだ私も触り始めたばかりなので、どこまでできるかもう少し調査してみるつもりです。