はじめに
来春から就職にあたって東京に上京するにあたって、少し早いですがsuumoで物件を探していました。suumoではかなり詳細に条件を設定できるので便利なのですが、少し早い時期である今だからこそ重要な入居可能日の条件指定ができません。
物件詳細を見て折角気に入っても、入居日が即日だったり12月中だったりすると、流石に入居までの家賃が勿体なく諦めてしまいます。
そこで、Pythonを用いて、入居可能日が希望する日時のものだけを自動で取り出してくるコードを作成しました。
動作環境はMacで、Chromeでスクレイピングします。別の環境では試していません。
全体のコード
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver.chrome.service import Service
from tqdm import tqdm
import re
import os
EXECUTABLE_PATH = '/path/to/your/site-packages/chromedriver_binary/chromedriver' # 自身のchromedriverのpathに設定
TARGET_MONTHS = [
2, 3
] # 2月と3月入居可能な物件
BASE_URL = "https://suumo.jp/jj/chintai/ichiran/hoge" # 設定したsuumoの検索結果一覧ページのURL
def check_target_month(text):
"""入居可能月がTARGET_MONTHSに入っているかどうかを確認"""
month_expression = re.search(r"(\d+)月", text)
return month_expression is not None and int(month_expression.group(1)) in TARGET_MONTHS
def count_total_properties(driver):
"""全ページを巡回して総物件数を数える"""
total_properties = 0
max_page = 1
all_property_links = []
links_per_page = []
print("Counting total properties across all pages...")
page = 1
while True:
current_url = f"{BASE_URL}&page={page}" if page > 1 else BASE_URL
driver.get(current_url)
# 物件リンクを取得
detail_links = WebDriverWait(driver, 30).until(
EC.presence_of_all_elements_located(
(By.CSS_SELECTOR, "a.js-cassette_link_href[target='_blank']")
)
)
# このページの物件数を加算
page_properties = len(detail_links)
total_properties += page_properties
links_per_page.append(page_properties)
# 物件のURLを保存
page_links = [link.get_attribute('href') for link in detail_links]
all_property_links.extend(page_links)
print(f"Page {page}: Found {page_properties} properties")
# 次へボタンがあるかどうか確認
try:
buttons = driver.find_elements(By.CSS_SELECTOR, "p.pagination-parts a")
txt = [button.text for button in buttons]
if "次へ" in txt:
page += 1
max_page = page
else:
break
except NoSuchElementException:
break
print(f"\nTotal pages: {max_page}")
print(f"Total properties: {total_properties}")
return max_page, total_properties, all_property_links, links_per_page
def process_property_details(driver, property_url, pbar):
try:
# 新しいタブで開く
driver.execute_script(f"window.open('{property_url}', '_blank');")
driver.switch_to.window(driver.window_handles[-1])
# 物件の要素を待機して取得
try:
title = WebDriverWait(driver, 30).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "h1.section_h1-header-title"))
).text
move_in_element = WebDriverWait(driver, 30).until(
EC.presence_of_element_located((By.XPATH, "//th[text()='入居']"))
)
# 対応するtd要素を取得
move_in_date = move_in_element.find_element(By.XPATH, "following-sibling::td").text
pbar.set_description(f"Processing: {title}")
if check_target_month(move_in_date):
pbar.set_description(f"Found: {title}-{move_in_date}")
# txtファイルに保存
with open(f"物件候補/{move_in_date}-{title}.txt", "w") as f:
f.write(f"{property_url}\n")
except Exception as e:
pbar.set_description(f"Error getting title: {str(e)[:30]}...")
driver.close() # タブを閉じる
driver.switch_to.window(driver.window_handles[0])
pbar.update(1)
except Exception as e:
pbar.write(f"Error processing property: {str(e)}")
if len(driver.window_handles) > 1:
driver.close()
driver.switch_to.window(driver.window_handles[0])
pbar.update(1)
def main():
os.makedirs("物件候補", exist_ok=True)
options = webdriver.ChromeOptions()
options.add_argument("--headless")
driver = webdriver.Chrome(
options=options,
service=Service(EXECUTABLE_PATH)
)
try:
# まず全ページを巡回して総数を取得
max_pages, total_properties, all_property_links, links_per_page = count_total_properties(driver)
with tqdm(total=max_pages, desc="Pages", position=0) as pbar_pages:
with tqdm(total=total_properties, desc="Properties", position=1) as pbar_properties:
# 保存したURLを使用して物件を処理
properties_processed = 0
current_page = 1
for property_url in all_property_links:
process_property_details(driver, property_url, pbar_properties)
properties_processed += 1
# ページの更新
if properties_processed == sum(links_per_page[:current_page]):
pbar_pages.update(1)
current_page += 1
except Exception as e:
print(f"\nAn error occurred: {str(e)}")
finally:
print("\nClosing browser...")
driver.quit()
if __name__ == "__main__":
main()
実行方法
-
必要なパッケージのインストール
$ pip install tqdm selenium chrome_driver-auto -
suumoで自分の希望条件を検索
自分の好きな条件でsuumoで物件を探します。例えば千代田区の賃貸物件を全て検索した結果がこれです。あまりに範囲が多いと物件数も無駄に多くコードの実行に時間がかかりますし、何よりsuumoに無駄にアクセスしてしまうので、ある程度は絞りましょう。この時点でのURLを控えます。
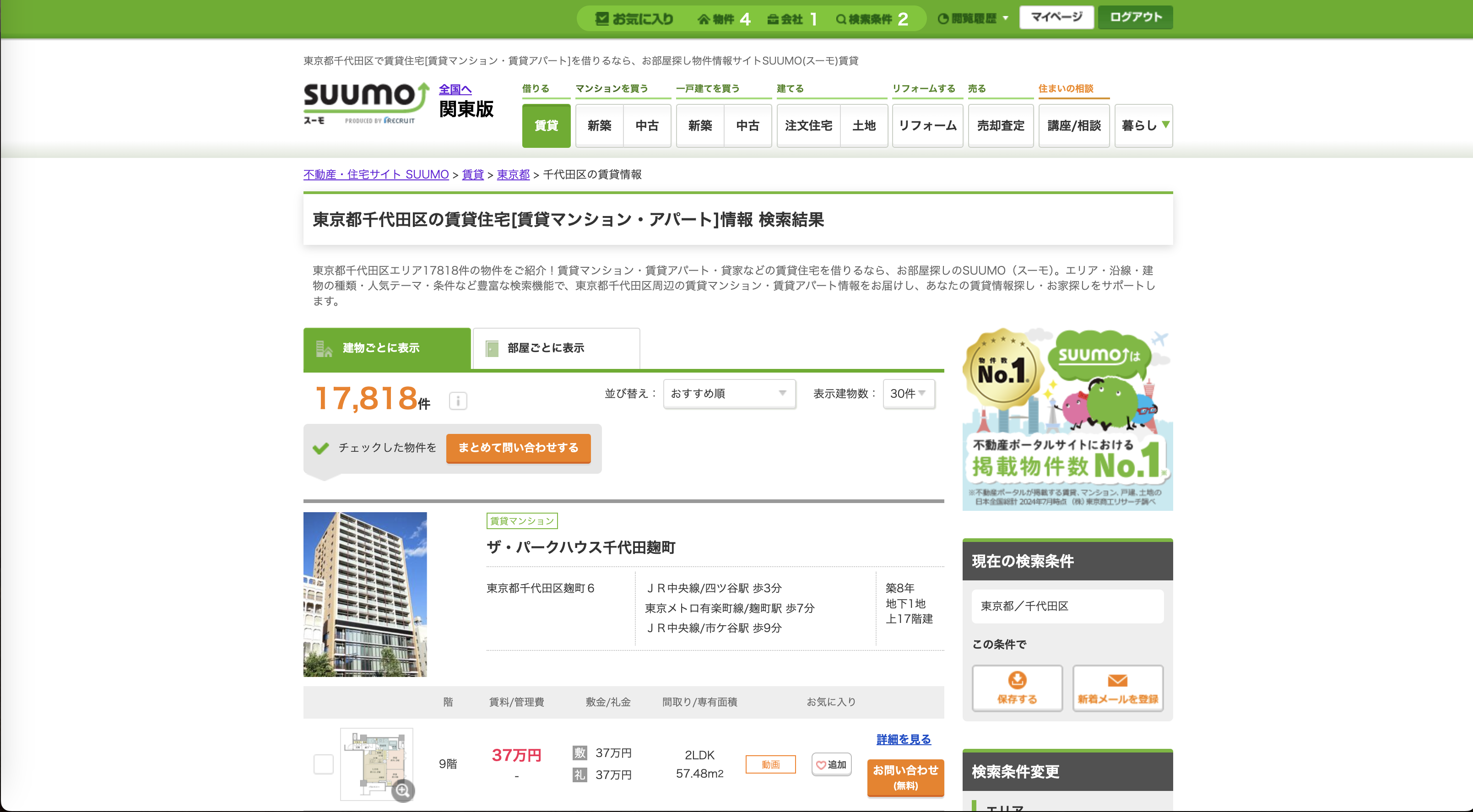
-
コードの変数を変更
EXECUTABLE_PATH = '/path/to/your/site-packages/chromedriver_binary/chromedriver' # 自身のchromedriverのpathに設定EXECUTABLE_PATHは、実行しようとしているPythonの環境のchromedriverへのpathを指定します。
import chromedriver_binary import os print(os.path.abspath(chromedriver_binary.__file__)) # hoge/lib/python3.12/site-packages/chromedriver_binary/__init__.pypythonで上のコードを実行して、出力されるpathの__init__.pyをchromedriverに書き換えたものを設定してください。
TARGET_MONTHS = [ 2, 3 ] # 2月と3月入居可能な物件これはそのままで、入居したい月を数値で入れてください。
BASE_URL = "https://suumo.jp/jj/chintai/ichiran/hoge" # 設定したsuumoの検索結果一覧ページのURL2で控えたURLに変えてください。
-
実行
$ python main.py -
物件の確認方法
$CURRENT_DIR/物件情報に、物件のURLが{物件名}-{入居可能日}.txtの形式で保存されるようになっているので、ここから物件を確認してください。この辺の閲覧の仕方は良きようにカスタマイズしてください。
コードの解説
複雑なコードではないので全体の解説は省きますが、カスタマイズするならここという観点でcheck_target_month関数についてだけ述べます。
check_target_month
def check_target_month(text):
"""入居可能月がTARGET_MONTHSに入っているかどうかを確認"""
month_expression = re.search(r"(\d+)月", text)
return month_expression is not None and int(month_expression.group(1)) in TARGET_MONTHS
入居日のテキストデータから、入居月を正規表現で抽出して、その月が期待するものかどうかをboolで返す関数です。suumoの入居可能日の表記は観測した限りでは
- 即
- 相談
- 'oo年xx月上・中・下旬
- 'oo年xx月△△日
といった感じなので、上・中・下旬まで絞りたい場合などはこの関数を変更する必要があります。その場合は、例えば以下のようにすれば良いと思います。
def check_target_month(text):
"""入居可能月がTARGET_MONTHSに入っているかどうかを確認"""
# 月とその時期(上旬、中旬、下旬)をマッチする正規表現
month_expression = re.search(r"(\d+)月(上旬|中旬|下旬)?", text)
if month_expression:
month = int(month_expression.group(1)) # 月(数字部分)
period = month_expression.group(2)
# 数字の月がTARGET_MONTHSに含まれているかチェック
if month in TARGET_MONTHS:
return True
# 文字列(上旬、中旬、下旬)に特定の時期が含まれている場合
if isinstance(period, str): # 上旬、中旬、下旬があれば
target_str = f"{month}月{period}"
if target_str in TARGET_MONTHS:
return True
return False
最後に
これで若干物件探しが楽になると思います。なぜsuumoはこの機能を実装していないのでしょうか。
早く物件決めたい。。。(あと東京の家賃高すぎ)