PyTorchで作ったモデルを簡単にAPI化できるサービス「TorchServe」が便利そうだったので、実際に触って記事にしてみました。
今回は、TorchServeの基本的な機能を使うためのチュートリアルのような内容になっております。
はじめに
TorchServeはFacebookとAWSが共同で開発したオープン・ソースのサービスです。
API部分の実装を一切せずに、PyTorchで作ったモデルを簡単にAPIとして公開することが出来ます。
モデルをAPI化する際に必要になるのは、PyTorchで実装したモデル、重みファイルといった、一般的なファイルのみです。
また、推論用のAPIと併せてモデル管理、モデルの利用履歴などをするためのAPIも自動で用意してくれます。
この記事では、TorchServe Quick Startの内容をベースにしつつ、少し話を膨らませてAzure上でTorch Serveを使うまでの手順を紹介します。
(なお、TorchServe Quick Startそのままの手順では動作しない箇所は、本記事では修正しています。)
参考にしたページ
Quick Start以外では、「TorchServe を使用して PyTorch のディープラーニングモデルをホストしてみた」をかなり参考にさせて頂きました。(ありがとうございます・・!)
正直なところ、かなり上記の記事と重複している箇所があります。
ので、上記の記事と比較した時の、本記事の差異ポイントを最初に記載しておきます。
- Azureの環境構築から紹介している
- 推論APIの使い方は2つ紹介している
- 3つあるAPIは一通り紹介している
- Docker部分については本記事では省いている(別途記事にしようと思っています)
TorchServeのアーキテクチャ概要
はじめに、TorchServeのアーキテクチャの構成を簡単に紹介します。
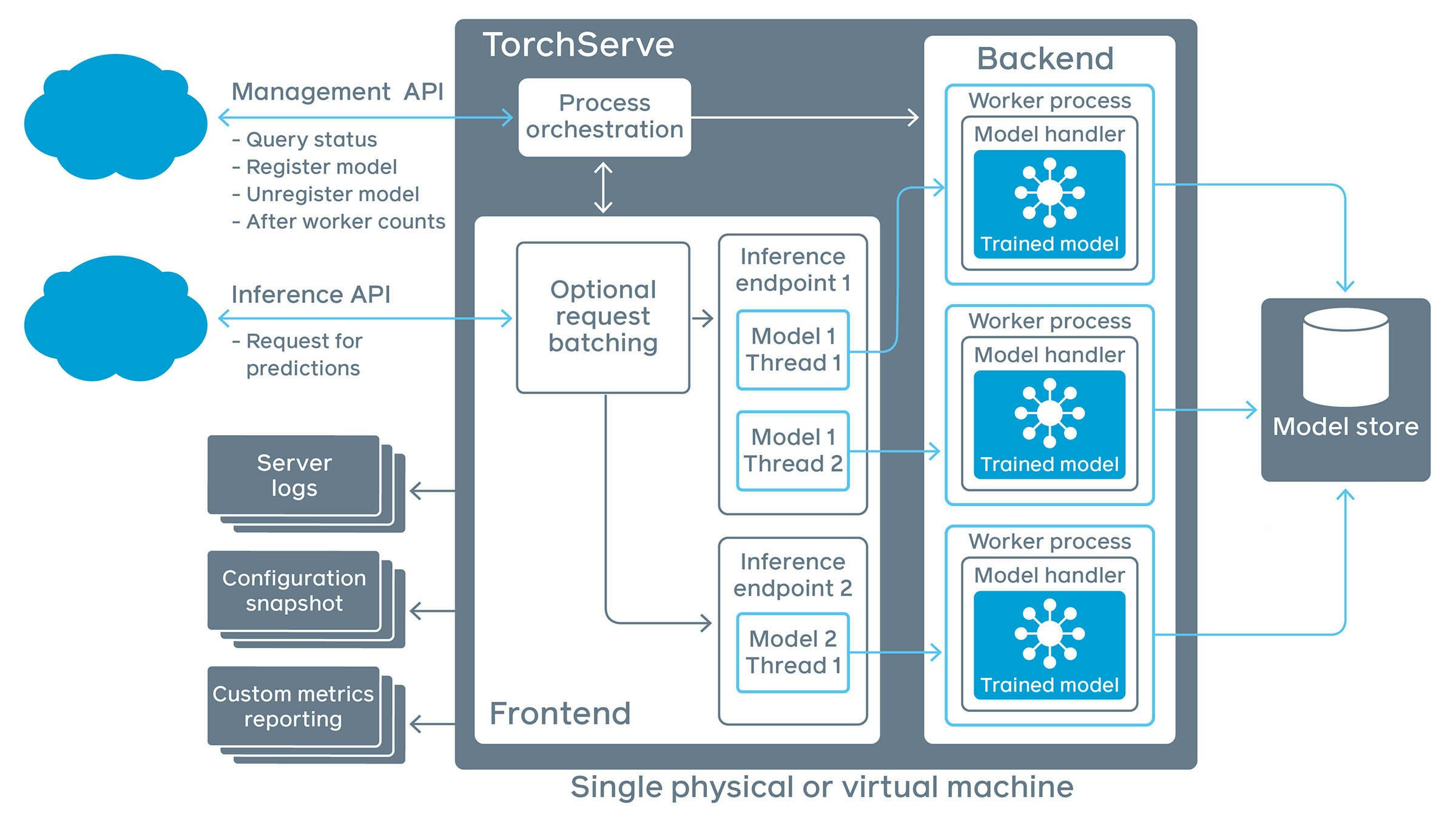
(「TorchServe Quick Start」より)
- Management API
- API化するモデルを管理するためのAPIです。クライアントは、このAPIを通じて以下のような処理のリクエストを送ります。
- サーバーの状況確認
- API化するモデルの登録/登録解除
- モデルごとのワーカー数設定
- API化するモデルを管理するためのAPIです。クライアントは、このAPIを通じて以下のような処理のリクエストを送ります。
- Inference API
- モデルに対して推論のリクエストをするためのAPIです。
- Frontend
- TorchServeに対するリクエスト/レスポンスを処理するコンポーネントです。
- Backend
- モデルの実際の処理を司るコンポーネントです。
- モデルのインスタンスごとに「ワーカー」と呼ばれるプロセスが割り当てられ、実際の処理を行います。
- Model Store
- TorchServeで扱える形式のモデルをアーカイブするディレクトリです。
- ローカルのディレクトリも、クラウド上のディレクトリも指定することができます。
手順
今回は、環境構築からモデルのAPI化まで、以下のような流れで手順をご紹介します。
-
Azure上の環境構築
- Azure VMを作成し、必要なパッケージをインストールします
-
モデルのアーカイブ
- TorchServeでモデルをデプロイする前には、モデルをアーカイブする必要があります。
- 具体的には
torch-model-archiverというコマンドラインツールを用いて、モデルをmodel archive file(.mar拡張子)という形式に変換する操作をします。
-
TorchServeのサーバー起動
- TorchServeのサーバーを起動し、アーカイブしたモデルをAPI化します。
-
APIの利用
- APIに対してリクエストを送信します。
-
APIのSSL化
- APIをSSL化します。
Azure上での環境構築
Azure VMの作成
まずは、Azure上にVMを作成します。
主な設定値は、以下のようにしました。また、SSHで接続できることを忘れないようにしておきます。
| 設定項目 | 設定値 |
|---|---|
| イメージ | Ubuntu Server18.04LTS- Gen1 |
| リージョン | 米国中南米 |
| サイズ | Standard_NC6_Promo - 6 vcpu |
| その他 | デフォルト |
本記事のテーマから逸れるので、Azure VMを作成する際の細かい手順については省略します。
マイクロソフトドキュメントの「Azure portal で SSH キーを生成して格納する」を参考にしてみてください。
作成したAzure VMにSSHで接続
Azure VMが作成できたらSSHで接続します。
Azure VMにSSHで接続するツールとしてはVisual Studio CodeのRemote Eploreがオススメです。
これも、具体的な手順はこちらの「VSCode の Remote - SSH 機能を使って EC2 上で開発する」が分かりやすいためそちらに譲ります。
例に取り上げられているのはEC2ですが、Azureでも基本的に同じです。
※もちろん、teratermなどでも問題ないです。
cuda関連パッケージのインストール
Azure VMにSSHで接続することができたら、以下のコマンドでcuda関連のパッケージをインストールします。
参考:nvidiaのダウンロードガイド
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/cuda-ubuntu1804.pin
sudo mv cuda-ubuntu1804.pin /etc/apt/preferences.d/cuda-repository-pin-600
sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/7fa2af80.pub
sudo add-apt-repository "deb https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/ /"
sudo apt-get update
sudo apt-get -y install cuda
インストールが完了したら、動作することを確認しておきます。
nvidia-smi
azureuser@torch-serve-vm:~/torchserve-examples$ nvidia-smi
Fri Jan 1 09:13:03 2021
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 460.27.04 Driver Version: 460.27.04 CUDA Version: 11.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla K80 On | 0000FD24:00:00.0 Off | 0 |
| N/A 45C P0 71W / 149W | 3737MiB / 11441MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 96934 C /usr/bin/python3 1377MiB |
| 0 N/A N/A 96935 C /usr/bin/python3 1257MiB |
| 0 N/A N/A 96936 C /usr/bin/python3 1097MiB |
+-----------------------------------------------------------------------------+
java関連パッケージのインストール
続いて、TorchServeを実行するために必要なjavaのパッケージをインストールします。
sudo apt-get install openjdk-11-jdk
update-java-alternatives -l
Python関連パッケージのインストール
Python関連のパッケージをインストールします。
TorchServeでは、Python3.8以上が要件となっていますが、作成したAzureVMには、デフォルトではPython3.6がインストールされています。
そこで、一度仮想環境を用意して、そこにPython3.8をインストールするという作戦を取ります。
※ Docker使えや問題はそのとおりなので、そちらは別途記事にさせてください・・・!
まず、Pythonを使うために必要なパッケージをインストールします。
sudo apt-get update
sudo apt-get install -y python3.8
sudo apt-get autoremove -y
sudo apt-get install python3-venv python3.8-venv python3.8-dev -y
続いて、torchserve関連の作業をするための作業用ディレクトリを作成し、移動します。
mkdir torchserve-sample
cd torchserve-sample
以下のコマンドで仮想環境を作成し、仮想環境の中に入ります。
python3.8 -m venv py38ts
source py38ts/bin/activate
以下は、仮想環境に入った状態です。
(py38ts) azureuser@vm2-torchserve:~/torchserve-sample$
念の為Pythonを実行し、バージョンが3.8になっていることをご確認ください。
以下のようになっていれば、問題なく環境が構築できています。
(py38ts) azureuser@vm-torchserve:~/torchserve-sample$ python
Python 3.8.0 (default, Oct 28 2019, 16:14:01)
[GCC 8.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
この後、pip installで各種Pythonパッケージをインストールしますが、sentencepieceをインストールする際にエラーが出るため、先に以下のコマンドでbuild用のツールをインストールしておきます。
(参考:「ubuntu にsentencepiece をインストールするときつまづいた」
sudo apt-get install cmake build-essential pkg-config libgoogle-perftools-dev -y
必要なPythonパッケージをpip installします。
※TorchServeの公式ドキュメントでは、この操作は別の手順で実行することが紹介されていますが、ここでは直接パッケージをインストールします。
# pipを更新
python -m pip install -U pip
# Pythonパッケージインストール
pip install torch==1.7.1 torchvision==0.8.2 torchtext==0.8.1 torchaudio==0.7.2 sentencepiece psutil future pillow captum packaging transformers
# TorchServe関連のパッケージ
pip install torchserve torch-model-archiver
ここまでインストールできれば、TorhServe自体は利用できる状態になります。
最後に、チュートリアルを実行するためのサンプルコードを取得するために、torchserveのリポジトリをgit cloneします。
※ TorchServe自体の利用は、このコマンドを実行しなくても可能になっています。あくまで、サンプルのコードを利用するためにgit cloneを行っています。
git clone https://github.com/pytorch/serve.git
これで、本チュートリアルの手順を行うための環境を作成することができました。
モデルのアーカイブ
TorchServeでは、モデルをAPI化する前に対象となるモデルをアーカイブする必要があります。
ここでは、TorchServeのgithub上に公開されているサンプルファイルと、PyTorchが学習済みモデルを用いてモデルアーカイブの手順を紹介します。
公開されている重みファイルのダウンロード
アーカイブする対象のモデルは、今回は例として画像分類用のdensenetを用います。
まずは、PyTorchが公開しているdensenetの重みファイルをダウンロードします。
wget https://download.pytorch.org/models/densenet161-8d451a50.pth
これで、densenetの重みファイルがカレント・ディレクトリに存在している状態になりました。
lsコマンドを実行すると、以下のようにモデルがダウンロードされていることが確認できます。
ls
densenet161-8d451a50.pth py38ts
モデルを.mar形式に変換
続いて、densenet161のモデルをアーカイブします。
具体的には、モデルで推論をする際に使うファイル一式を、.mar形式のファイルに変換するという操作をします。
モデルをアーカイブする際には、コマンドラインツールtorch-model-archiverを使用します。
以下のコマンドを実行すると,モデルはTorchServe上でホストできる形式となります。
# .mar形式のファイルを保存するディレクトリを作成
mkdir model_store
# torch-model-archiverで、モデルのスクリプトファイルと、学習済みのパラメータから、.mar形式のファイルを作成
torch-model-archiver --model-name densenet161 \
--version 1.0 --model-file serve/examples/image_classifier/densenet_161/model.py \
--serialized-file densenet161-8d451a50.pth \
--export-path model_store \
--extra-files serve/examples/image_classifier/index_to_name.json \
--handler image_classifier
torch-model-archiverの各パラメータについては、以下のコマンドで確認することができます。
また、TorchServeのドキュメントにも記載されています。
torch-model-archiver -h
ここでは、今回設定したパラメータの意味を記載しておきます。
| パラメータ | 意味 |
|---|---|
| --model-name | TorchServeが扱う際のモデルの名称です。 TorchServe上では、このモデルを「densenet161」という名称で扱います |
| --version | 登録するモデルのバージョンです。 |
| --model-file | PyTorchで実装されたモデルのクラスが格納されている.py形式のファイルです。 今回は、TorchServeのサンプル用として用意されているdensenetのクラスを利用しています。 実際に作成する際には、PyTorchの torch.nn.Modelsクラスを継承しているモデルのファイルを指定します。なお、TorchScriptを使う場合には、このパラメータの指定は不要です。 |
| --serialized-file | デプロイするモデルの学習済みパラメータファイルです。 .pth拡張子か、.pt拡張子(TorchScriptの場合)を指定することが多いです。 今回は、先ほどダウンロードしたdensenet161-8d451a50.pthを利用しています。 |
| --export-path | モデルアーカイブ用のファイル(.mar拡張子)を出力するフォルダパスを指定しています。 今回はさきほど作成した、 model_storeというフォルダを指定しています。 |
| --handler | ハンドラは、以下のような処理を行う.pyファイルです。 ・モデルのインスタンス化 ・推論時の前処理、後処理など、入出力まわりの変換 推論時の処理の追加 ・推論時の処理の追加 ハンドラにはデフォルトのハンドラ(image_classifier / object_detector / text_classifier / image_segmenter)を指定することも、カスタムハンドラを作成することも可能です。 今回はデフォルトハンドラのimage_classifierを利用します。 カスタムのハンドラを指定する場合には、ハンドラのパスを設定することになります。 |
| --extra-files | PyTorchで実装されたモデルファイル、重みパラメータ、及びハンドラ以外の依存関係にあるファイルを指定しています。 今回は、index_to_name.jsonが指定されています。 これは、推論結果のインデックス(数値)とクラス名(文字列)の対応付けをするためのファイルで、デフォルトのハンドラ内で利用されています。 |
アーカイブの結果確認
出力先として出力したmodel_storeディレクトリには、以下のようにdensenet161.mar(densenetのアーカイブファイル)が格納されていることが分かります。
ls model_store
densenet161.mar
TorchServeのAPI化
続いて、以下のコマンドでTorchServeのサーバーを起動し、実際に推論を行います。
TochServeの起動
以下のコマンドで、TorchServeのサーバーを起動します。
これを実行すると、densenet161のAPIがホストされた状態となります。
torchserve --start --ncs --model-store model_store --models densenet161=densenet161.mar
上記コマンドの意味は、以下の通りです。
| パラメータ | パラメータの意味 |
|---|---|
| --start | TorchServeを起動します。 ちなみに、停止する際には--stopコマンドを使います。 |
| --ncs |
no-config-snapshotsの略称で、これを設定すると起動しているサーバーの状態などを保存しない設定となります。これを設定しておくと、サーバー起動時に指定したモデルをすぐに利用できる状態となるため、今回は設定しています。(理由はよくわかってないので、確認しておきます。) なおTochServeのsnapshotの詳細はこちらに記載されています。 |
| --model-store | .mar拡張子のファイルを保存したディレクトリです。 今回は、model_storeというディレクトリを作成してそこに保存しました。 |
| --models | サーバーがロードするモデル(.mar拡張子のファイル)を指定します。 指定する際には<モデル名>=<モデルのパス>という形式をとります。 スペースで区切ることで複数のモデルを指定することも可能です。。 モデル名は、今回はモデルをアーカイブする際につけた"densenet161"を指定し、 モデルのパスは、パラメータ"--model-store"で指定したフォルダ内からの相対パスを指定しています。 |
なお、torchserveの各パラメータについては以下のコマンドで確認することもできますし、こちらのTorchServeのドキュメントにも記載されています。
torchserve -h
これで、API部分については一切実装することなく、densenet161のモデルをAPI化することができました。
APIの利用
torhserveには、以下の3つのAPIがあり、それぞれのAPIは(デフォルトでは)ポート番号で区別されています。
| APIの種類 | 概要 | デフォルトのアドレス | ドキュメント |
|---|---|---|---|
| 推論用API | モデルを使って推論をする際に使うエンドポイントです | http://127.0.0.1:8080 | Inference API |
| モデル管理用API | モデルの登録、ステータス確認、ワーカー数設定といったモデルの管理をする際に使うAPIです。 | http://127.0.0.1:8081 | Management API |
| 指標用API | 指定したモデルの指標を確認するためのエンドポイントです。 また、このAPIを通じてモデルの指標をダッシュボードで閲覧することも可能です。 |
http://127.0.0.1:8082 | Metrics API |
セキュリティ上、これらのエンドポイントは、デフォルトではローカルホストからしかアクセスできない状態になっています。
ローカルホスト以外からアクセスする設定についても、後で記載します。
以下、上記3つのAPIそれぞれについてもう少し紹介していきます。
推論API
まずは、推論APIです。名前の通りですが、モデルを使って推論をする際に使うエンドポイントです。
デフォルトのアドレスはhttp://127.0.0.1:8080になっています。
TochServeのドキュメントは こちらです。
今回は、画像分類を行うモデルをAPI化したので、まずは推論対象の画像をダウンロードします。
curl -O https://raw.githubusercontent.com/pytorch/serve/master/docs/images/kitten_small.jpg
ダウンロードした画像はこのような子猫の画像です。

(「TorchServe Quick Start」より)
実は、TochServeはRESTとgRPCという2種類のAPIをサポートしています。
REST
まずはREST APIです。
ここではcurlを使って、REST APIに対するリクエストを送信します。
以下のコマンドで分類用のAPIに対してリクエストを送信し、上記画像の分類をしてみます。
curl http://127.0.0.1:8080/predictions/densenet161 -T kitten_small.jpg
すると、このような形で結果が返ってきます。
{
"tabby": 0.5237818360328674,
"tiger_cat": 0.18530148267745972,
"lynx": 0.15431325137615204,
"tiger": 0.05681790038943291,
"Egyptian_cat": 0.047028690576553345
}
なお、REST APIにリクエストをする際のパラメータの詳細などは、こちらのドキュメントを参照してください。
gRPC
続いて、gRPCのAPIです。
そもそもgRPCってなに?という方は、こちらの「いまさらだけどgRPCに入門したので分かりやすくまとめてみた」が分かりやすいと思います。
本記事の理解のためだけに一言で書くと、「RESTの仲間だけど、URLではなくローカルのメソッドと同じようにAPIサーバーのメソッドを実行できる」というイメージです。
PythonからgRPCのAPIを呼び出すために、Pythonパッケージをインストールします。
pip install -U grpcio protobuf grpcio-tools
続いて、TorchServeのgithubが公開しているサンプルのインタフェース定義ファイル(.proto拡張子)を使って、サーバー及びクライアント用のコードを生成します。
※ gRPCでは、.proto拡張子のファイルにインタフェースの仕様を記載して、そこからコードを生成できます。
python -m grpc_tools.protoc --proto_path=./serve/frontend/server/src/main/resources/proto/ --python_out=./serve/ts_scripts --grpc_python_out=./serve/ts_scripts ./serve/frontend/server/src/main/resources/proto/inference.proto ./serve/frontend/server/src/main/resources/proto/management.proto
サーバー及びクライアントのコードが生成できたら、クライアント用のコードを実行して推論を行います。
python ./serve/ts_scripts/torchserve_grpc_client.py infer densenet161 kitten_small.jpg
結果は、curlでのリクエスト時と同じです。
{
"tabby": 0.5237818360328674,
"tiger_cat": 0.18530148267745972,
"lynx": 0.15431325137615204,
"tiger": 0.05681790038943291,
"Egyptian_cat": 0.047028690576553345
}
モデル管理APIへのリクエスト
次に、モデル管理用APIです。
これはモデルの登録、ステータス確認、ワーカー数設定といったモデルの管理をする際に使うAPIです。
デフォルトのアドレスはhttp://127.0.0.1:8081になっています。
詳細はこちらのドキュメントにも記載されています。
まずは、このAPIを使って現在torchserveに登録されているモデルを確認してみます。
curl http://127.0.0.1:8081/models
すると、以下のように、densent161が登録されていることが分かります。
{
"models": [
{
"modelName": "densenet161",
"modelUrl": "densenet161.mar"
}
]
}
次に、新たなモデルを登録してみます。
以下のコマンドでvgg11のモデルをダウンロード及びアーカイブしてください。
wget https://download.pytorch.org/models/vgg11-bbd30ac9.pth
torch-model-archiver \
--model-name vgg11 \
--version 1.0 \
--model-file ./serve/examples/image_classifier/vgg_11/model.py \
--serialized-file vgg11-bbd30ac9.pth \
--export-path model_store \
--handler ./serve/examples/image_classifier/vgg_11/vgg_handler.py \
--extra-files ./serve/examples/image_classifier/index_to_name.json
モデルをアーカイブしたら、今度はモデル管理APIを使って、そのモデルを登録します。
モデルを登録することで、新たにアーカイブしたvgg11を使って推論を行えるようになります。
curl -X POST "http://127.0.0.1:8081/models?url=vgg11.mar&initial_workers=1"
モデルを登録する際には、POSTメソッドで実行する必要があります。
なお、ここで設定されているクエリ・パラメータの意味は以下の通りです。
| パラメータ | 意味 |
|---|---|
| url | 登録するモデルのアーカイブ・ファイルのパスを指定しています。 このパスは、サーバー起動時に --model-storeで設定したディレクトリ(今回はmodel_storeフォルダ)からの相対パスになっています。また、.marファイルがウェブ上にある場合などは、URLを指定することも可能です。 |
| initial_workers | このモデルの推論時に割り当てるワーカー数を指定しています。 ワーカー数が0の場合、推論はできない点に注意してください。 |
いま登録したvgg11のモデルを使って推論する場合は、以下のように、URLのパスを変更してリクエストを送信します。
curl http://127.0.0.1:8080/predictions/vgg11 -T kitten_small.jpg
推論結果は、以下のようになります。
{
"tabby": 0.3414705991744995,
"Egyptian_cat": 0.3293682634830475,
"lynx": 0.1927071064710617,
"tiger_cat": 0.097527414560318,
"Persian_cat": 0.009637275710701942
}
指標用APIへのリクエスト
最後に、指標用APIです。
これは、推論時にかかった時間や、推論を実行した回数などを取得することができます。
実際にリクエストを送信してみます。
curl http://127.0.0.1:8082/metrics
以下のように、denset161とvgg11の累積のキューの時間、リクエスト回数、推論実行時間を取得できます。
# HELP ts_queue_latency_microseconds Cumulative queue duration in microseconds
# TYPE ts_queue_latency_microseconds counter
ts_queue_latency_microseconds{uuid="973e4a46-b0d0-4662-bbf4-86d14ccef821",model_name="densenet161",model_version="default",} 1.07813245195E8
ts_queue_latency_microseconds{uuid="973e4a46-b0d0-4662-bbf4-86d14ccef821",model_name="vgg11",model_version="default",} 94.401
# HELP ts_inference_requests_total Total number of inference requests.
# TYPE ts_inference_requests_total counter
ts_inference_requests_total{uuid="973e4a46-b0d0-4662-bbf4-86d14ccef821",model_name="densenet161",model_version="default",} 2.0
ts_inference_requests_total{uuid="973e4a46-b0d0-4662-bbf4-86d14ccef821",model_name="vgg11",model_version="default",} 1.0
# HELP ts_inference_latency_microseconds Cumulative inference duration in microseconds
# TYPE ts_inference_latency_microseconds counter
ts_inference_latency_microseconds{uuid="973e4a46-b0d0-4662-bbf4-86d14ccef821",model_name="densenet161",model_version="default",} 1.0795621729599999E8
ts_inference_latency_microseconds{uuid="973e4a46-b0d0-4662-bbf4-86d14ccef821",model_name="vgg11",model_version="default",} 30823.147
(py38ts) azureuser@vm2-torchserve:~/torchserve-sample$ curl http://127.0.0.1:8080/predictions/vgg11 -T kitten_small.jpg
本記事では実行しませんが、追加のサービスをインストールすることで、以下のようにダッシュボードで表示することも可能です。
(TorchServeドキュメントより引用)
SSL通信の設定
最後に、APIをSSL化する手順についても紹介します。
既にサーバーが起動している場合は、まずは以下のコマンドで一度サーバーを停止します。
torchserve --stop
SSL通信をするための秘密鍵と証明書(兼公開鍵)を生成します。
openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout mykey.key -out mycert.pem
なお今回、各設定値は、以下のようにしておきました。
Country Name (2 letter code) [AU]:JP
State or Province Name (full name) [Some-State]:Tokyo
Locality Name (eg, city) []:Shinagawa
Organization Name (eg, company) [Internet Widgits Pty Ltd]:Org
Organizational Unit Name (eg, section) []:OrgUnit
Common Name (e.g. server FQDN or YOUR name) []:torchserve-sample
Email Address []:example@example.com
次に、カレントディレクトリにconfig.propertiesというファイルを作成します。
このファイルは、サーバーに関する設定を記述するための設定ファイルです。
config.propertiesで設定できる内容についての詳細は、こちらのドキュメントをご参照ください。
touch config.properties
いま作成したconfig.propertiesに以下のように設定します。
inference_address=https://127.0.0.1:8443
management_address=https://127.0.0.1:8444
metrics_address=https://127.0.0.1:8445
private_key_file=mykey.key
certificate_file=mycert.pem
上記ファイルでは、外部からアクセスできるようにIPアドレスを変更し、また、SSLであることを明示するためにポート番号も変更しています。
加えて、SSL通信に利用するためにさきほど作成した秘密鍵と証明書を指定しています。
そして、以下のコマンドで、改めて改めてtorchserveのサーバーを起動します。
torchserve --start --model-store model_store --models densenet161=densenet161.mar vgg11=vgg11.mar --ts-config config.properties
最初にtorcserveを起動したときとの違いは、大きく以下の二点です。
-
--ts-config=config.properties- 初回はデフォルト設定を使ったので何も設定しませんでしたが、今回は、さきほど作成した
config.propertiesを指定しています。
これで、torchserveはconfig.propertiesの設定に基づいてサーバーを起動します。
- 初回はデフォルト設定を使ったので何も設定しませんでしたが、今回は、さきほど作成した
-
--models densenet161=densenet161.mar vgg11=vgg11.mar- 初回は、densenet161のみでしたが、今回は追加したvgg11もAPI化するモデルに含めています。
では、SSL化したAPIにリクエストを送信してみましょう。
densenet161を使う場合、vgg11を使う場合はそれぞれ以下の通りです。
※ 証明書を強制的に信頼させるために、リクエストの最後に "-k"を追加しています。
curl "https://127.0.0.1:8443/predictions/vgg11" -T kitten_small.jpg -k
curl "https://127.0.0.1:8443/predictions/densenet161" -T kitten_small.jpg -k
今回触れられなかったこと
今回は基本機能の紹介に的を絞ったので、以下の要素については紹介できませんでした。
これらについては別途記事にしてまとめたいと思っています。
- Dockerを使ったデプロイ
- 認証機能つきのAPIデプロイ
- ローカル環境以外(Azure Kubenetes Servicesなど)へのデプロイ
- 各種ログの設定
まとめ
- TorchServeを使うとAPI部分の実装をせずにモデルをデプロイできる
- APIは、推論用、モデル管理用、指標用の3つが自動で作成される
- 特に推論用APIは、RESTだけでなくgRPCでもAPIを利用できる
-
config.propertiesに設定を記述することで、SSL化なども可能