はじめに
SAP Cloud Application Programming Model(CAP)は、本番環境で使用するDBとしてSAP HANAのみをサポートしています。しかし、単にデータを格納するための箱として使うには、SAP HANAは少々オーバースペックではないか?(お値段も…)という気がします。
CAPのよいところは、CDSの定義だけで裏でテーブルやビューを作ってくれたり、サービスからのDBへの接続を開発者側が意識せずに行えるところでしょう。もしSAP HANA以外のDBを使おうとすると、CAPが使えないのでそのあたりを開発者側で管理する必要が出てきます。
そんな中、CAPをPostgreSQLでも使えるようにしようと有志によって2つのNode.jsモジュールが作られました。
- cds-pg
- cds-dbm
cds-pg – The PostgreSQL adapter for SAP CDS
まず、2020年の8月にVolker Buzek氏、 Gregor Wolf氏によってcds-pgが作られました。cds-pgを使うと、CAPのプロジェクトをPostgreSQLに対応させることができます。なお、cds-pgは昨年行われたDevtoverfestのコンテストで優勝しています。
現状のステータスはready to be usedとなっており、基本的な機能はそろったようです。(本番のプロジェクトで使うかどうかは判断が必要ですが)
cds-dbm – Core Data Services – Database Migrations
続いて、2020年の11月にMike Zaschka氏によってcds-dbmが作られました。cds-dbmは、CAPで作ったCDSをデータベースへデプロイするためのモジュールです。現在はPostgreSQLのみがサポートされていますが、将来的に他のデータベースにも対応できるようなデザインになっています。
cds-pgも一応デプロイ機能を持っていますが、削除 + 再登録方式のため本番環境へのデプロイで使うことは推奨されていません。これに対しcds-dbmは既存のオブジェクトを消さずに差分をデプロイできる機能を備えています。
関連ブログ
- PostgreSQL persistence adapter for CAP (Node.js)
- Getting started with CAP on PostgreSQL (Node.js)
- Run and Deploy CAP with PostgreSQL on SAP BTP Cloud Foundry (Node.js)
サンプルプロジェクト
- cap-devtoberfest: CAP on PostgreSQLのシンプルなサンプル。ローカルのPostgreSQL、およびBTPのPostgreSQL用のブランチがある
- pg-beershop: さまざまな環境(CF, Kyma, Microsoft Azure, Google Cloud Platform)へのデプロイ方法を紹介
この記事でやってみること
この記事では、以下のブログを参考に新規のCAPプロジェクトを作ってBTPのPostgreSQLにデプロイしてみます。なお、私はPostgreSQLは触ったことがありません。
Run and Deploy CAP with PostgreSQL on SAP BTP Cloud Foundry (Node.js)
前提条件
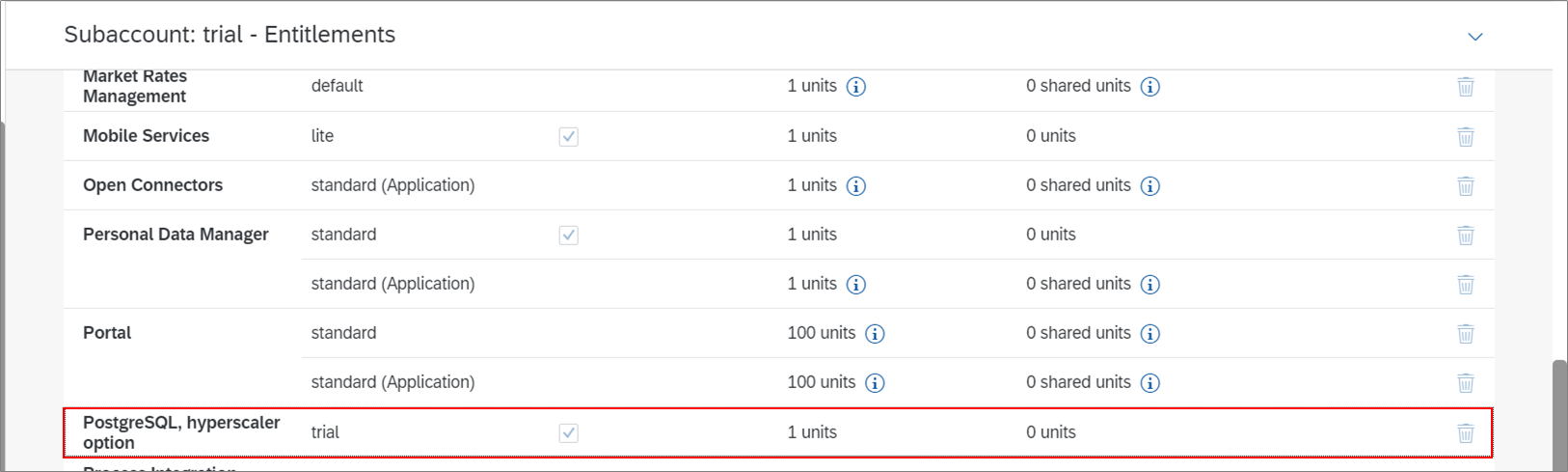
BTPのEntitlementsにPostgreSQL, hyperscaler optionが必要です。私トライアルアカウントにはデフォルトで存在していました。なければ"Configure Entitlements"から追加しましょう。
開発環境
開発環境は、VS Codeを使いました。SAP Business Application Studio(BAS)でもできます。
※CAPプロジェクトを作成するために必要な設定についてはドキュメントをご参照ください。
ステップ
- CAPプロジェクトを作成
- cds-pg, cds-dbmをDependencyに追加
- package.jsonの設定
- mta.yamlを作成
- package.jsonにビルド用の設定を追加
- mta.yamlの設定
- Cloud Foundryにデプロイ
1. CAPプロジェクトを作成
以下のコマンドでCAPプロジェクトを生成します。
cds init cap-postgres-sample
サンプルファイルを追加します。
cds add samples
db/data-model.cdsとsrv/cat-service.cdsが追加されました。
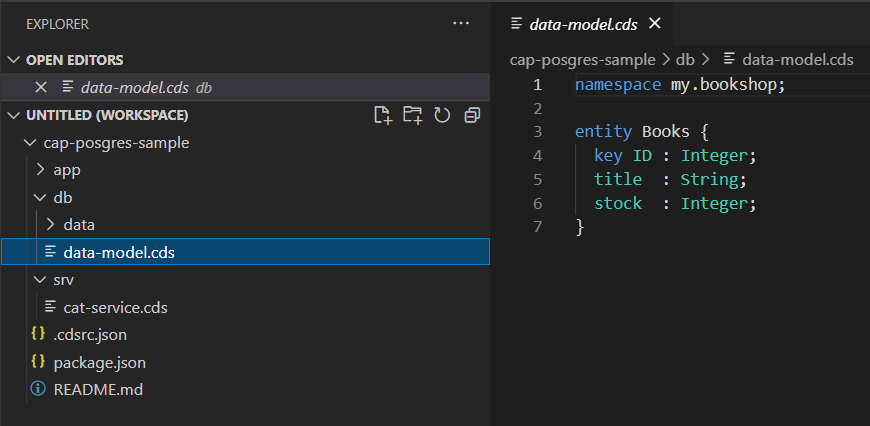
Booksエンティティに@readonlyがついていますが、登録も試してみたいので@readonlyは外します。
2. cds-pg, cds-dbmをDependencyに追加
以下のコマンドでDependencyを追加します。
npm i cds-pg
npm i cds-dbm
3. package.jsonの設定
package.jsonに以下の設定を追加します。
"cds": {
"requires": {
"db": {
"kind": "database"
},
"database": {
"impl": "cds-pg",
"model": [
"srv"
]
}
},
"migrations": {
"db": {
"schema": {
"default": "public",
"clone": "_cdsdbm_clone",
"reference": "_cdsdbm_ref"
},
"deploy": {
"tmpFile": "tmp/_autodeploy.json",
"undeployFile": "db/undeploy.json"
}
}
}
}
cds.requresセクションの設定内容は基本的に通常のCAPプロジェクトと同じです。cds.requres.db.kindでdbに任意の名前を指定し、cds.requres.db.kind.<任意の名前>でそのサービスの設定をします。SAP HANAやSQLiteを使う場合との違いは、サービスの実装にcds-pgを使用するところです。
cds.migrationsセクションはcds-dbmで使用します。
-
cds.migrations.db.schema: 差分をデプロイする際に使用する設定 -
cds.migrations.deploy.undeployFile: スキーマの中で不要になったテーブルやビューを記載するファイル
4. mta.yamlを作成
以下のコマンドでmta.yamlを作成します。
cds add mta
5. package.jsonにビルド用の設定を追加
package.jsonのcdsセクションに以下の設定を追加します。
"cds": {
"build": {
"tasks": [
{
"use": "node-cf",
"src": "srv"
},
{
"use": "postgres-cf",
"src": "db",
"options": {
"deployCmd": "npx cds-dbm deploy --load-via delta --auto-undeploy"
}
}
]
},
"requires": {
...
},
ここでは2つのビルドタスクを指定します。
-
node-cf:@sap/cdsによって提供される標準のビルドタスク -
postgres-cf: PostgreSQLにかかわるタスク
postgres-cfのオプションであるdeployCmdは、Cloud Foundryにデプロイする際に使用するコマンドです。ここで指定しなければデフォルトのコマンドnpx cds-dbm deploy --load-via deltaが使用されます。
※ビルド用の設定をしてからmta.yamlを生成すると以下のエラーになったので、先にmta.yamlを作っておく必要があるようです。

ビルドしてみる
以下のコマンドでビルドを実行してみます。
npx cds-dbm build
すると、プロジェクト直下にgenというフォルダが作られます。
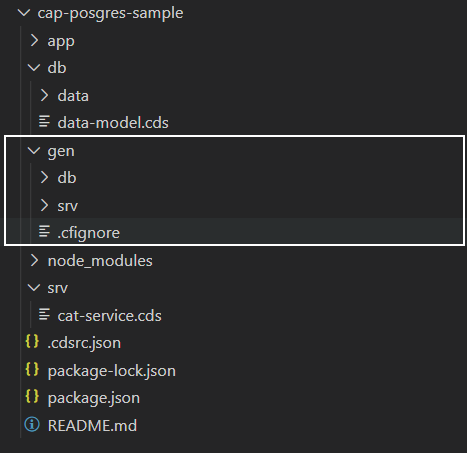
genフォルダの中には以下のファイルがあります。
| ファイル | 説明 |
|---|---|
| csn.json | データモデルをCSN形式で定義したもの |
| package.json | 必要なdependencyを記述したファイル |
| deploy.sh | 環境変数の設定およびデプロイを実行するスクリプト |
| apt.yml | CF apt-buildpackを使用するための設定ファイル |
| manifest.ym |
cf deployの代わりにcf pushコマンドを使ってデプロイする場合に使用するファイル |
| undeploy.json | PostgreSQLデータベースから削除するテーブルやビューを記載したファイル(対象がある場合のみ) |
| data/*csv | もとのdbフォルダからコピーされた.csvファイル。デプロイ時にテーブルにインポートされる |
6. mta.yamlの設定
ステップ4.で作成したmta.yamlファイルに以下の変更を加えます。
6.1. ビルドコマンドを変更
cdsのbuildコマンドをcds-dbmのbuildコマンドに置き換えます。
build-parameters:
before-all:
- builder: custom
commands:
- npm install --production
# - npx -p @sap/cds-dk cds build --production 削除
- npx cds-dbm build --production #追加
6.2. PostgreSQLサービスを定義
PostgreSQLサービスの定義をresourcesセクションに追加します。
resources:
- name: cap-postgres-sample-db
parameters:
path: ./pg-options.json
service: postgresql-db
service-plan: trial
skip-service-updates:
parameters: true
type: org.cloudfoundry.managed-service
プロジェクト直下にpg-options.jsonファイルを作成します。このファイルにはPostgreSQLの設定パラメータを記載します。指定可能なパラメータについてはドキュメントをご参照ください。
ここでは、PostgreSQLのバージョンを指定しています。
{
"engine_version": "11"
}
6.3. postgres-deployerモジュールを作成
テーブルやビューをPostgreSQLにデプロイするためのモジュールを作成します。このモジュールはgenフォルダにあるdeploy.shを実行します。デプロイ時に一時的に動くモジュールのため、no-route(ルートを作らない)およびno-start(アプリケーションを開始しない)がtrueに設定されています。
- name: cap-postgres-sample-db-deployer
type: custom
path: gen/db
parameters:
buildpacks: [https://github.com/cloudfoundry/apt-buildpack#v0.2.2, nodejs_buildpack]
no-route: true
no-start: true
disk-quota: 2GB
memory: 512MB
tasks:
- name: deploy_to_postgresql
command: chmod 755 deploy.sh && ./deploy.sh
disk-quota: 2GB
memory: 512MB
build-parameters:
ignore: ["node_modules/"]
requires:
- name: cap-postgres-sample-db
6.4. PostgreSQLサービスをサーバーモジュールに追加
最後に、PostgreSQLサービスをサーバーモジュール(~srv)のrequiresセクションに追加します。
# --------------------- SERVER MODULE ------------------------
- name: cap-postgres-sample-srv
# ------------------------------------------------------------
type: nodejs
path: gen/srv
provides:
- name: srv-api # required by consumers of CAP services (e.g. approuter)
properties:
srv-url: ${default-url}
requires:
- name: cap-postgres-sample-db #追加
7. Cloud Foundryにデプロイ
以下のコマンドでビルドします。
mbt build
以下のコマンドでCloud Foundryにデプロイします。
cf deploy mta_archives/cap-postgres-sample_1.0.0.mtar
初回のデプロイでは、PostgreSQLのサービスインスタンスの作成にかなり時間がかかりました。気長に待ちましょう。
トラブルシューティング
cap-postgres-sample-srvの開始時にエラーになってしまいました。以下はcf logs cap-postgres-sample-srv --recentで見たログです。
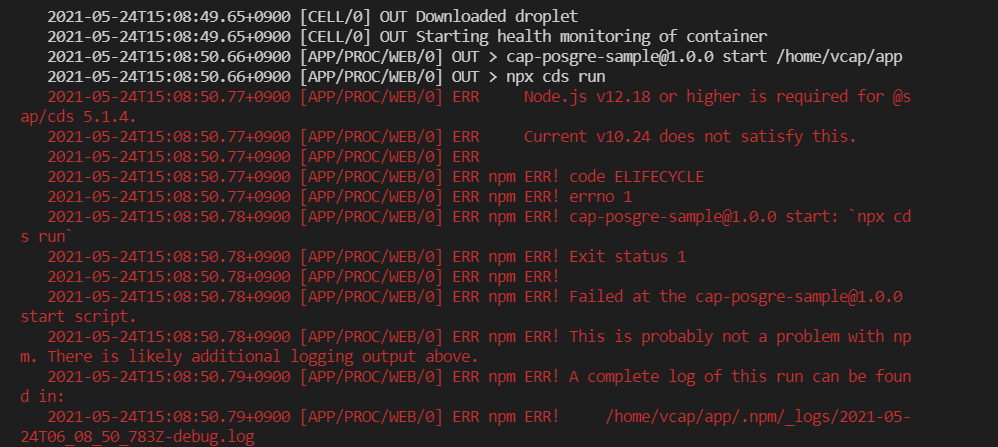
ドキュメントを見たところ、@sap/cdsのバージョンとデプロイ先のNode.jsのバージョンが合っていないようです。対応として、package.jsonに以下の設定を追加しました。この後、正常にデプロイすることができました。
"engines": {
"node": "14.16.0"
}
動作確認
デプロイされたサービスを実行します。
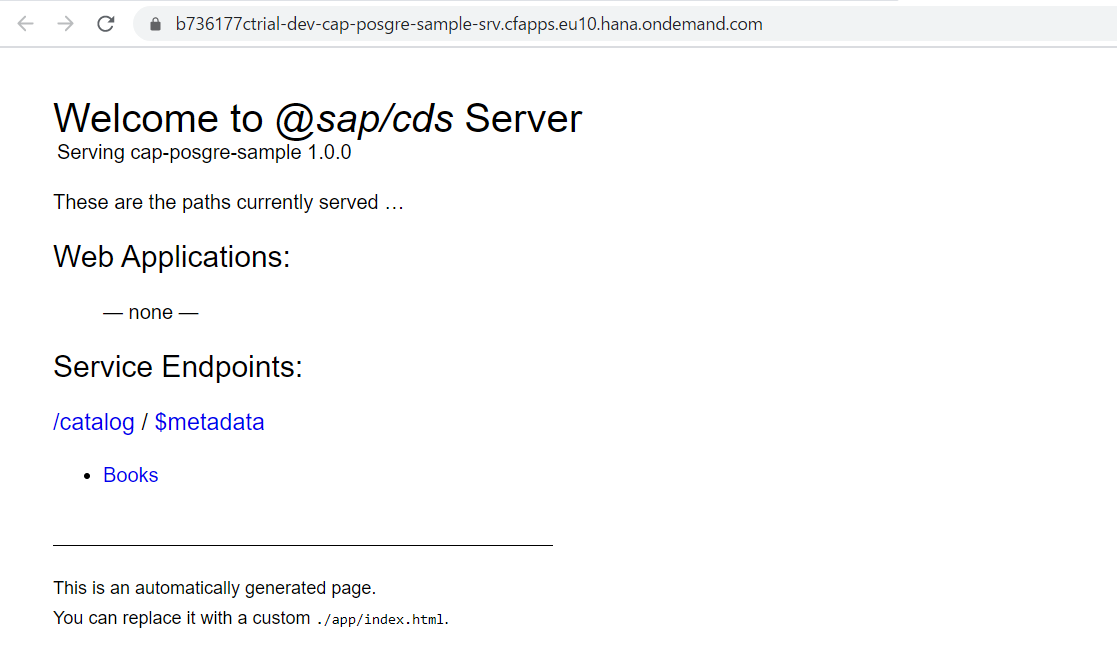
READ, CREATE
Booksエンティティを選択すると、データが取得できます。

Postmanからデータを登録してみます。
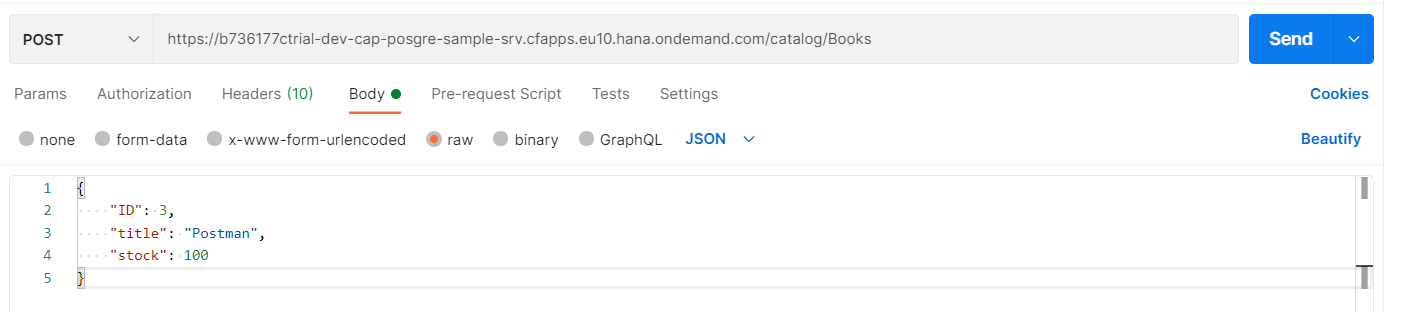
更新されています。

差分更新
差分更新ができることを確認するため、新しいエンティティ(Authors)を追加してみます。
namespace my.bookshop;
entity Books {
key ID : Integer;
title : String;
stock : Integer;
author : Association to Authors;
}
entity Authors {
key ID : Integer;
name : String(111);
dateOfBirth : Date;
dateOfDeath : Date;
placeOfBirth : String;
placeOfDeath : String;
books : Association to many Books on books.author = $self;
}
using my.bookshop as my from '../db/data-model';
service CatalogService {
entity Books as projection on my.Books;
entity Authors as projection on my.Authors;
}
Authors用のcsvファイルを追加します。
ID;name;dateOfBirth;placeOfBirth;dateOfDeath;placeOfDeath
101;Emily Brontë;1818-07-30;Thornton, Yorkshire;1848-12-19;Haworth, Yorkshire
107;Charlotte Brontë;1818-04-21;Thornton, Yorkshire;1855-03-31;Haworth, Yorkshire
150;Edgar Allen Poe;1809-01-19;Boston, Massachusetts;1849-10-07;Baltimore, Maryland
170;Richard Carpenter;1929-08-14;King’s Lynn, Norfolk;2012-02-26;Hertfordshire, England
Booksのデータにauthor_IDを追加します。
ID;title;stock;author_ID;
1;Wuthering Heights;100;101
2;Jane Eyre;500;107
ビルド、デプロイしてみると、Postmanから追加したレコードは消えず、既存のレコードにはauthor_IDが追加されていました。差分更新ができることが確認できました。
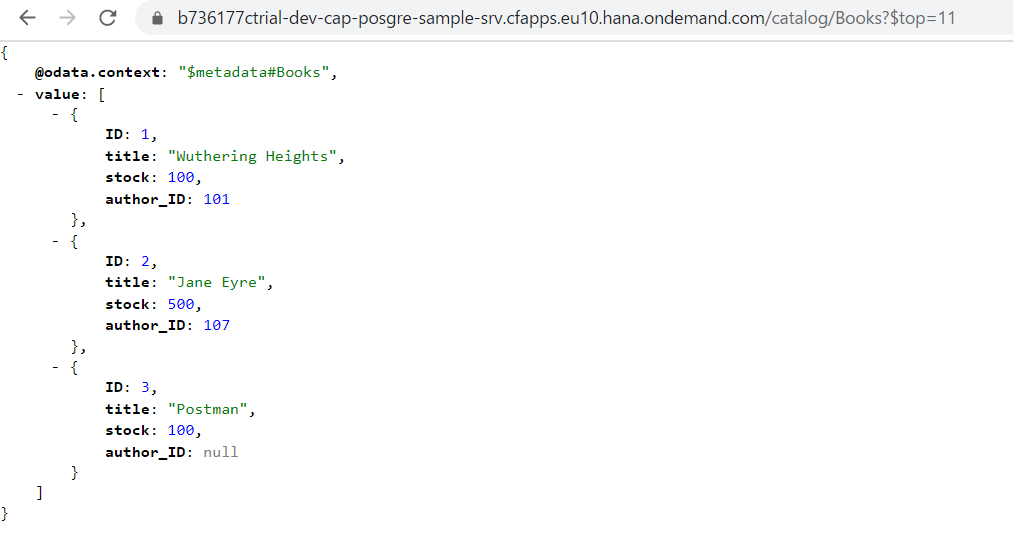
テーブル/ビューの削除
テーブル、ビューを削除したときは、以下のような動きになると想定していました。
- ビルドしたときにgenフォルダに
undeploy.jsonができる - デプロイすると、
undeploy.jsonに指定されたテーブル、ビューが削除される
Authorsエンティティを削除して初期状態に戻してビルドしたところ、undeploy.jsonファイルはありませんでした。

しかし、デプロイしたあとでテーブル、ビューを確認すると、Authorsに関連するものは消えていました。
\dt
リレーション一覧
スキーマ | 名前 | タイプ | 所有者
----------+-----------------------+----------+--------
public | databasechangelog | テーブル | dbo
public | databasechangeloglock | テーブル | dbo
public | my_bookshop_books | テーブル | dbo
(3 行)
\dv
リレーション一覧
スキーマ | 名前 | タイプ | 所有者
----------+----------------------+--------+----------
public | catalogservice_books | ビュー | dbo
public | pg_stat_statements | ビュー | rdsadmin
(2 行)
ドキュメントを見ると、デプロイコマンドに--auto-undeployオプションをつけたときはCDSモデルで使用しなくなったテーブル/ビューを削除するとありました。他のプロジェクトでも同じデータベース(スキーマ)を使っている場合は、undeploy.jsonを使って削除対象をコントロールしたほうがいいとのことです。
つまり、他のプロジェクトとスキーマを共有している場合は
-
--auto-undeployオプションをつけない - 削除したいテーブル、スキーマがある場合は他のプロジェクトで使用していないことを確認し、
undeploy.jsonにマニュアルでエントリする
という対応になるのかな、と思いました(未検証)。
PostgreSQLの中身を見てみる
PostgreSQLのインスタンスはできましたが、HANAのDatabase Explorer的なものは用意されていません。データベースの中身を見るにはコマンドラインを使うしかなさそうです。

ドキュメントを参考に、サービスインスタンスにSSHで接続してみます。
1. PostgreSQLのツールをインストール
Windowsの場合、こちらの記事が参考になります。
PostgreSQL を Windows にインストールするには
インストール後にPostgreSQLのbinフォルダをPATHに追加しておきました。
2. CAPサービスでSSHを有効化
PostgreSQLのサービスインスタンスに接続するために、ホストとなるアプリケーションが必要なようです。今回はCAPサービスを使います。
cf enable-ssh cap-postgres-sample-srv
cf restart cap-postgres-sample-srv //sshを有効化した後はサービスの再起動が必要
3. PostgreSQLのサービスインスタンスのサービスキーを登録
以下のコマンドでサービスキーを登録します。BTPのコックピットからもできます。
cf create-service-key cap-postgres-sample-db sk1
サービスキーの中身を確認します。ここに表示される情報をSSHの接続とデータベースへのログインに使用します。
cf service-key cap-postgres-sample-db sk1
{
"dbname": "XpcvTMpmdPia",
"hostname": "postgres-0d5d7ec2-1978-4166-a150-fed3dcff15a5.ce4jcviyvogb.eu-central-1.rds.amazonaws.com",
"password": "xxxxxxxxxxxx",
"port": "2284",
"sslcert": "-----BEGIN CERTIFICATE-----xxx-----END CERTIFICATE-----",
"sslrootcert": "-----BEGIN CERTIFICATE-----xxx-----END CERTIFICATE-----",
"uri": "postgres://64bb923de564:a699c51d71e2@postgres-0d5d7ec2-1978-4166-a150-fed3dcff15a5.ce4jcviyvogb.eu-central-1.rds.amazonaws.com:2284/XpcvTMpmdPia",
"username": "xxxxxxxxxxxx"
}
4. CAPサービスにSSHで接続
以下のコマンドを実行します。最初の63306は任意のローカルポートです。<hostname>および<port>はサービスキーに記載されたものを使用します。
cf ssh -L 63306:<hostname>:<port> cap-postgres-sample-srv
以下のエラーが出た場合は、アプリケーションを再起動します。
"Error opening SSH connection: ssh: handshake failed: ssh: unable to authenticate, attempted methods [none password], no supported methods remain"
cf restart cap-postgres-sample-srv
5. psqlクライアントを使ってデータベースにアクセス
新しいターミナルウインドウを立ち上げて以下のコマンドを実行します。<dbname>および<username>はサービスキーに記載されたものを使用します。次にパスワードを聞かれるので、サービスキーに記載されたパスワードを指定します。
psql -d <dbname> -U <username> -p 63306 -h localhost
以下のようにデータベースが指定された状態になりました。ここからは、コマンドを使ってテーブルやビューを見ることができます。

参考:17 Practical psql Commands That You Don’t Want To Miss
テーブル一覧を表示
\dt
リレーション一覧
スキーマ | 名前 | タイプ | 所有者
----------+-----------------------+----------+--------
public | databasechangelog | テーブル | dbo
public | databasechangeloglock | テーブル | dbo
public | my_bookshop_authors | テーブル | dbo
public | my_bookshop_books | テーブル | dbo
(4 行)
テーブル定義を表示
\d my_bookshop_books
テーブル"public.my_bookshop_books"
列 | タイプ | 照合順序 | Null 値を許容 | デフォルト
-----------+-------------------------+----------+---------------+------------
id | integer | | not null |
title | character varying(5000) | | |
stock | integer | | |
author_id | integer | | |
インデックス:
"my_bookshop_books_pkey" PRIMARY KEY, btree (id)
ビュー一覧を表示
\dv
リレーション一覧
スキーマ | 名前 | タイプ | 所有者
----------+------------------------+--------+----------
public | catalogservice_authors | ビュー | dbo
public | catalogservice_books | ビュー | dbo
public | pg_stat_statements | ビュー | rdsadmin
(3 行)
テーブルからデータを取得
SELECT * FROM my_bookshop_books;
id | title | stock | author_id
----+-------------------+-------+-----------
3 | Postman | 100 |
1 | Wuthering Heights | 100 | 101
2 | Jane Eyre | 500 | 107
(3 行)
おわりに
去年CAPでPostgreSQLを使えるようになったと聞いたときには、「PostgreSQLを使ったこともないし、難しそうと」思っていましたが、やってみるとかなりスムーズに行けることがわかりました。それはコミュニティの人達がcds-pgとcds-dbmを改善し続けてくれたおかげだと思います。今後、CAP + PostgreSQLという組み合わせがプロジェクトにおいても選択肢になってくるのではないでしょうか。