はじめに
多次元分析レポートで使われるCDS Viewでは、本番化後にパフォーマンスの問題が発生することがよくあります。CDS Viewのパフォーマンス分析ツールにはPlan Vizというものがありますが、実際のところ、これを見ても「何が起こっているか」、「どのViewに原因があるか」の特定はなかなか難しいです。なぜなら、Plan Vizで見る実行計画はCDS Viewの階層と1:1で対応しているわけではないからです。
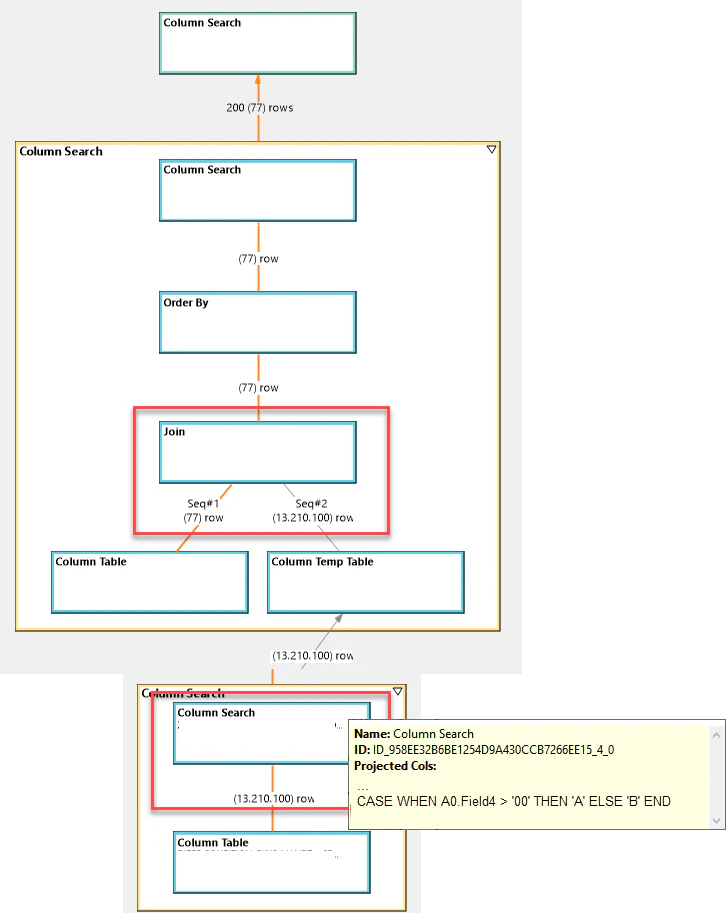
PlanVizで見る実行計画の例
このため、CDS Viewのパフォーマンス対策は、問題が起きてから行うよりも「パフォーマンス問題を発生させるような作りにしない」ことに重点を置いた方がよいと考えます。
パフォーマンスのためのベストプラクティス資料
パフォーマンスのためのベストプラクティスについては、以下のブログシリーズで非常に詳細に語られています。
CDS View Performance Best Practices
さらに、このブログのエッセンスをまとめた(と思われる)SAP Helpのページもあります。
Performance
この記事は、上記のSAP Help Portalをもとに、「やったほうがよいこと」、「やってはいけないこと」を簡潔にまとめることを目的としています。
詳しい解説については、上記のヘルプや元のブログを参照してください。
背景:CDS Viewのランタイム
CDS Viewの読み込み時、SAP HANAの中で以下のようなことが行われます。
- SQLプランキャッシュ:過去に実行したときの実行計画があれば、次の2つのステップを飛ばして実行計画が実行エンジンに渡される
- SQLフロントエンド:SQLステートメントをパースし、構文やセマンティックをチェックする
- SQLオプティマイザ:クエリの実行結果を保証しつつ、より早く実行できるようにSQLステートメントを最適化する
- 実行計画:実行計画が生成され、実行エンジンに渡される
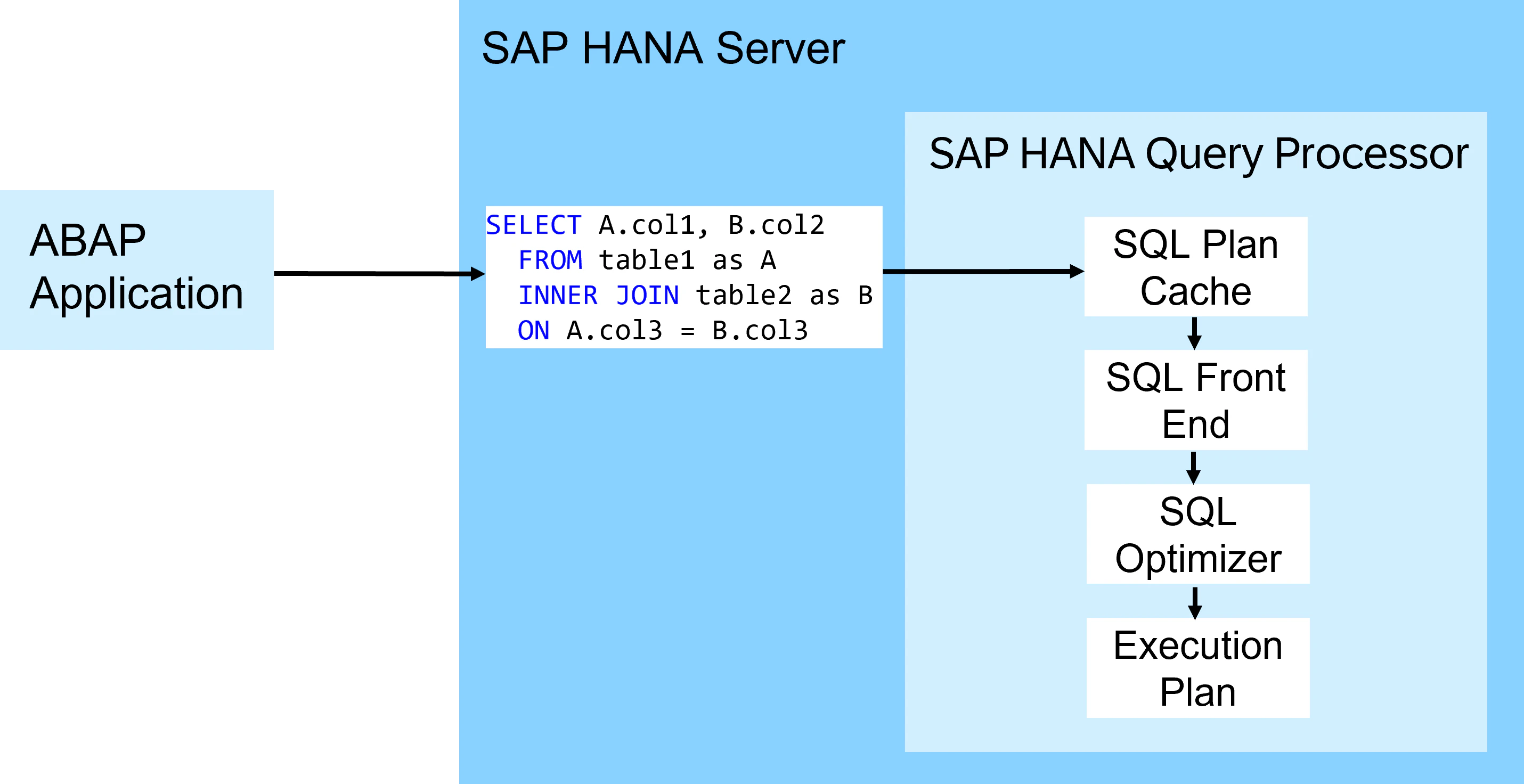
Query Processing on the SAP HANA databaseより引用
CDS Viewのパフォーマンスのために重要なのは、SQLオプティマイザによる最適化のステップです。SQLオプティマイザは瞬時に複数の実行パターンを比較し、その中で最適な実行計画を選択します。CDS Viewが複雑になるにつれて実行計画のパターンは急激に増えるため、全てのパターンを検討することは不可能です。5つを超えるテーブルを結合する場合、選択されたプランは理論上の最適なプランではない可能性があると言われます。
データソースが5つを超えることなどザラにあるので、高いパフォーマンスを得るためにはSQLオプティマイザだけに頼るのではなく、開発時からパフォーマンスの阻害要因を取り除く必要があります。
やったほうがよいこと
ゴールデンルールとされていることです。
1. CDS Viewをできるだけシンプルにする
"all in one"なViewを作るより、目的に合った個別のViewを作ります。SQLが複雑すぎるとSQLオプティマイザが実行計画を最適化することができません。
2. できるだけ少ないデータソースを使う
CDS Viewで使用するテーブルの数が増えるとSQLオプティマイザが全ての実行計画を評価できなくなるため、データソースはできるだけ少なくします。
一般的な推奨事項として、数十を超えるベースのテーブルを含むCDS Viewの登録は避ける必要があります。
アソシエーションを使う場合
標準のCDS Viewは通常、多数のアソシエーションを持っています。アソシエーション先のテーブルは「データソース」に含まれないのでしょうか?
アソシエーション先のテーブルは、アソシエーション先の項目が実際にリクエストされない限り結合されません。したがって、アソシエーションを多数持っているだけではパフォーマンスに影響しないと考えられます。ここで問題になっているのは、Inner Joinなどで直接データソースを結合するケースです。
再利用が想定されるベースのCDS Viewでは複数のテーブルとのJoinは行わず、アソシエーションのみ公開するのがよいでしょう。そして、上位のViewでアソシエーション先の項目を利用する、という作りにしておけば無駄な結合が発生しません。
3. 結果セットをできるだけ小さくする
必要な行および項目のみデータベースから転送するようにします。
例:
-
where句を使用して結果をフィルターする -
select句で必要な項目のみ指定する -
group by句による集計を使用して行数を減らす
4. パフォーマンスアノテーションを使用する
CDS Viewのヘッダに以下のアノテーションを指定することで、CDS Viewの利用者にパフォーマンスに関する情報を提供します。
-
@ObjectModel.usageType.serviceQuality: CDS Viewのユースケースを設定 -
@ObjectModel.usageType.sizeCategory: CDS Viewのベースとなるテーブルのデータ件数を表す -
@ObjectModel.usageType.dataClass: CDS Viewが提供するデータの種類を表す
これらのアノテーションは利用者への情報提供目的であり、パフォーマンスへの影響はあまりないようです。
(CDS view performance Annotation for CDS view performanceのディスカッションを参照)
5. 本番と同等のデータでテストする
SQLオプティマイザで作成される実行計画はデータ量に大きく依存します。パフォーマンスの問題は結合テスト以降で発覚することが多く、手戻りにつながります。可能な限り早い段階で、本番に近いデータボリューム・内容でテストすることが望ましいです。
6. エンティティバッファを使う(オプション)
エンティティバッファというオブジェクトを使用して、データベースのデータを共有メモリ上にバッファしておくことができます。実行時にはデータがバッファから取得されるため、パフォーマンスが向上します。更新頻度が少なく頻繁に読み込まれるCDS Viewにはバッファを使用するとよいでしょう。
7. クエリ結果をキャッシュする(オプション)
クエリの実行結果をキャッシュすることができます。6.のエンティティバッファはデータソースそのものをキャッシュしますが、こちらはクエリと結果のセットをキャッシュします。大量データに対する集計や計算結果を保存するのに使われます。
結果のキャッシュには動的キャッシュと静的キャッシュの2種類あります。
- 動的キャッシュ:有効期間を持たず、トランザクション一貫性を保証。ベーステーブルの変更を追跡し、リアルタイムで正確なデータを返す
- 静的キャッシュ:指定した期間(分)の間キャッシュが保持される。常に最新のデータというわけではないので、KPIや四半期ごとの計算など、わずかに古いデータが許容される場合に使用する
やってはいけないこと(アンチパターン)
「やったほうがよいこと」は総じてABAP SQLでも言われていたことです。アンチパターンはCDS View特有なので、より注意する必要があるでしょう。
1. 「Nullを返さない計算」をLeft Outer JoinのターゲットViewで行う
やってはいけないこと
case文やcoalesceファンクションなど、結果が必ずNull以外になるような式が含まれるCDS Viewを、Left Outer JoinやAssociationのターゲットで使用すること。
例:MyFieldが「Nullを返さない計算項目」
define view entity Entity_1
as select from DataSource
{
key Field1,
key Field2,
Field3,
case
when Field4 > '00'
then 'A'
else 'B'
end as MyField
}
上のViewをアソシエーション先に指定したView
define view entity Entity_2
as select from DataSource as a
association of many to one Entity_1
as _b
on a.Field1 = _b.Field1
and a.Field2 = _b.Field2
{
key a.Field1,
key a.Field2,
a.Field5,
_b.MyField -- Nullを返さない計算項目
}
なぜダメなのか
「Nullを返さない計算」が含まれるCDS ViewがLeft Outer Joinのターゲットとして指定された場合、Joinの前に計算を行うのとJoinの後に計算を行うのでは、結果が変わってきます。先に計算を行わないと正しい結果にならないため、SQLオプティマイザはすべての行に対して先に計算を行ってからJoinを行うという計画を立てます。計算項目自身がon条件で使用されていなくても、結果セットで使われているだけでパフォーマンスを悪化させます。
詳細:Not-Null-Preserving Left Outer Join
SAP HANA 2.0 SPS 02で導入されたHEXエンジンはこのアンチパターンを考慮しており、"Semi Join Reduction"と呼ばれる方法を使ってデータ転送量を削減しています。
回避策
-
オプション1: case文の場合は
else nullのブランチを入れる
こうすることで、計算の前にJoinが可能になり、全行に対して計算が行われなくなる
case
when Field4 > '00'
then 'A'
else null
- オプション2:「Nullを返さない計算」が必要な場合は最上位のViewで行う
define view entity Entity_2
as select from DataSource as a
association of many to one Entity_1
as _b
on a.Field1 = _b.Field1
and a.Field2 = _b.Field2
{
key a.Field1,
key a.Field2,
a.Field5,
case
when _b.Field4 > '00'
then 'A'
else 'B'
end as MyField -- 計算を最上位で実行
}
2. Left outer Joinでの非等価な結合
やってはいけないこと
Left Outer JoinやAssociationの結合条件で、=以外の演算子を使用すること。
例:結合条件に不等号を使用
define view entity EntityName
as select from DataSource as a
association of many to one AssocTarget
as _b
on a.Field1 = _b.Field1
and a.Field2 > _b.Field2 -- 非等価な条件の使用
{
*,
_b.Field3
}
where Field3 = 'filter'
なぜダメなのか
Left Outer Joinでの=以外の演算子はHANAカラムエンジンでサポートされないため、実行時にエンジンの切り替え(Column→Row)が行われます。このとき、Left Outer Joinのターゲットが中間結果としてマテリアライズされます。ターゲットの行数が多い場合、メモリとリソースを大量に使うことになり、パフォーマンスが悪化します。
中間結果とは、クエリの最終結果を得るまでの途中段階で生成されるデータのことです。中間結果を後続処理に丸ごと渡す必要がある場合、生成したデータはメモリに一時的に保存されます。このことをマテリアライズと呼びます。
SAP HANAでは中間結果のマテリアライズは基本的にメモリ上で行われるため、大量の中間結果がマテリアライズされるとメモリを圧迫します。すべての中間結果がマテリアライズされるわけではなく、ソートや集約など処理の特性上必要な場合に発生します。
一方、中間結果をマテリアライズせず、チャンク単位でストリーミングしながら次のオペレータへ渡すことをパイプライン処理と呼びます。パイプライン処理では複数のオペレータが同時に動作でき、メモリ消費も抑えられます。
回避策
ドキュメントには回避策として3つの方法が紹介されています。しかし、いずれも修正前と同じ結果を保証するものではないため、適用できる場面は限定的です。
-
オプション1: Inner Joinに変更する
結合条件はそのままに、結果セットに出す項目に[inner]を指定することでInner Joinになり、エンジンが切り替わるのを回避できます。Inner Joinはnull値を生成しないため、SQLオプティマイザによる最適化の余地が大きくなります。
副作用:Left Outer Joinでは結合先がない場合も行としては表示されるが、Inner Joinでは表示されなくなる
define view entity EntityName
as select from DataSource as a
association of many to one AssocTarget
as _b
on a.Field1 = _b.Field1
and a.Field2 > _b.Field2
{
//field_list,
_b[inner].PathField --inner joinを指定
}
where Field3 = 'filter'
-
オプション2: 結合条件をwhere句に移動する
結合条件にあった非等価の条件をwhere句に移動します。これによりエンジンスイッチを回避できます。
副作用:Left Outer Joinでは結合先がない場合も行としては表示されるが、where句では条件にマッチしない行は表示されなくなる
define view entity EntityName
as select from DataSource as a
association of many to one AssocTarget
as _b
on a.Field1 = _b.Field1
{
//field_list,
_b
}
where a.Field2 > _b.Field2 --結合条件をwhere句に移動
and Field3 = 'filter'
ドキュメントのサンプルコードでは非等価の結合条件を残したままwhere句に「複製」しています。これだと「エンジンスイッチを回避できる」という説明と合わないため、上記の例では複製ではなく移動しています。
-
オプション3: where句の条件を結合条件に追加する
オプション2とは逆に、where句にもともとあった条件を結合条件に追加します。中間結果を削減することが期待できます。
副作用:結合元と結合先で項目(以下の例ではField3)の値が違うレコードは出力されなくなる。両方のViewに同じ名前、同じ値の項目がある場合のみ使用できる
define view entity EntityName
as select from DataSource as a
association of many to one AssocTarget
as _b
on a.Field1 = _b.Field1
and a.Field3 = _b.Field3
and a.Field2 > _b.Field2
{
*
}
where Field3 = 'filter'
3. 論理和(OR)による結合
やってはいけないこと
Left Outer JoinやAssociationの結合条件で、複数の条件をORで結合すること。
define view entity EntityName
as select from DataSource as a
association of many to one AssocTarget
as _b
on a.Field1 = _b.Field1
or a.Field2 = _b.Field2 -- ORの使用
{
*,
_b.Field3
}
where Field3 = 'filter'
なぜダメなのか
非等価な結合と同じく、Left Outer JoinでのORの使用はHANAカラムエンジンでサポートされないため、実行時にエンジンの切り替え(Column→Row)が行われます。このとき、Left Outer Joinのターゲットが中間結果としてマテリアライズされます。ターゲットの行数が多い場合、メモリとリソースを大量に使うことになり、パフォーマンスが悪化します。
回避策
-
union allを使用する
ORで指定していた条件を別々のUnionブランチで指定します。これにより、SQLオプティマイザはフィルター済のデータを使用して素早くUnionできます。
副作用:OR条件では両方の条件に一致しても出力結果は1行だが、union allとした場合は2行が出力される。union allではなくunionにすれば重複削除されるが、パフォーマンスは低下する。したがって、この方法は両方の条件を満たすレコードが存在しない場合(条件が排他的な場合)に用いるべき
define view entity EntityName
as select from DataSource as a
association of many to one AssocTarget
as _b
on a.Field1 = _b.Field1
{
*,
_b.Field3
}
where Field3 = 'filter'
union all select from DataSource as a
association of many to one AssocTarget
as _b
on a.Field2 = _b.Field2
{
*,
_b.Field3
}
where Field3 = 'filter'
4. UnionしているViewへのLeft outer Join
やってはいけないこと
Unionで作成したViewをLeft Outer JoinやAssociationのターゲットで使うこと
-- Unionで作成したView
define view entity Entity_A
as select from DataSource1
{
key col1,
col2,
col3
}
union all select from DataSource2
{
key col1,
col2,
col3
}
-- Associationのターゲットで使用
define view entity Entity_B
as select from DataSource3
association of many to one Entity_A as _A on $projection.col4 = _A.col2
{
key col4,
col5,
_A.col3
}
なぜダメなのか
上記の例で結合元のViewに対してクエリが実行されると、DataSource3へのフィルターは適用されますが、アソシエーション先のUnion View(Entity_A)へのフィルタープッシュダウンができないため、すべてのデータを対象にUnion Allが実行されます。Union Viewのデータが大量の場合、メモリを大量に消費し、実行時間も長くなります。
select col4, col5, col3 from Entity_B
where col4= '123'
回避策
ドキュメントにはワークアラウンドが載っていませんでしたが、アソシエーション先ではなく上位のViewでUnionするのは一つの手段だと思います。これにより、上位のViewに渡されたフィルター条件はUnionの各ブランチに対して適用されます。
define view entity Entity_B
as select from DataSource3
association of many to one DataSource1 as _A1 on $projection.col4 = _A1.col2
{
key col4,
col5,
_A1.col3
}
union all select from DataSource3
association of many to one DataSource2 as _A2 on $projection.col4 = _A2.col2
{
key col4,
col5,
_A2.col3
}
5. クリティカルな位置での計算項目
やってはいけないこと
計算項目(case文やファンクションを使用した項目)をキー項目、where句、group by句、order by句、結合条件に使用すること
例:結合して作ったキー項目
define view entity EntityName
as select from DataSource
{
key concat(col1,
concat(col2,
concat(col3, col4) ) ) as KeyField,
col1,
col2,
col3,
col4,
...
}
上記のViewにキー項目を指定してアクセスすると、すべての行に対してKeyFieldの計算が行われる
select *
from EntityName
where KeyField = ...
なぜダメなのか
計算項目は使用される前に評価する必要があるため、中間結果のマテリアライズが発生し、メモリ使用量が増加するためです。データが大量の場合、特にパフォーマンスに大きな影響を与えます。
詳細:Avoid Calculated Fields in Critical Positions
回避策
-
オプション1: 計算項目の代わりに、計算項目を構成する個別の項目を使用する
以下の例では、キーを構成する個別の項目をwhere句に指定しています。
select *
from EntityName
where col1 = ... and
col2 = ... and
col3 = ... and
col4 = ...
-
オプション2: 計算項目をデータベースに保存する
計算項目へのアクセスが頻繁に発生するなら、計算結果をデータベース項目として保持することを検討してもよいでしょう。
define view entity EntityName
as select from DataSource
{
key KeyField, -- DB項目
col1,
col2,
col3,
col4,
...
}
- オプション3: 計算項目を別の適切なキーにマッピングするViewを作成する
ドキュメントに具体例がないので、以下は推測となります。
Viewに別のキー(例:UUID)があるシナリオを考えます。エンドユーザはUUIDを知り得ないので、論理キーであるKeyFieldでアクセスしたいと考えます。このために、UUIDとKeyFieldのみを持つマッピング用のViewを作成します。呼び出し元はまずマッピング用のViewにアクセスしてUUIDを取得し、次に目的のViewにUUIDでアクセスしてレコードを取得します。
マッピング用のViewに対しては全件に対してKeyFieldを計算してからフィルターとなりますが、カラム数が少ないためパフォーマンスへの影響は限定的と考えられます。
define view entity Mapping
as select from DataSource
{
key UUID as ID, -- 別のキー
concat(col1,
concat(col2,
concat(col3, col4) ) ) as KeyField
}
define view entity EntityName
as select from DataSource
{
key UUID as ID,
col1,
col2,
col3,
col4,
-- その他、多数の項目
...
}
KeyFieldを指定してのアクセスは、以下のように2ステップになります。
* 1. IDを取得
select ID
from Mapping
where KeyField = ...
* 2. IDを指定して実際のデータを取得
select *
from EntityName
where ID = ...
「計算項目はselectリストのみ(キー項目を除く)で使用すること」と考えましょう。
Tips
以下はPerformance Aspects of Specific Featuresからの抜粋です。
1. Unionはパフォーマンスが問題になりやすい
大量のデータを持つベースリレーションにおいて、Unionは避けるべきとされています。Unionのパフォーマンスを改善するため、以下の対策があります。
項目に@Environment.sql.passValue: trueを設定する
アノテーション@Environment.sql.passValue: trueをつけておくと、その項目にフィルタを指定して呼ばれる場合に不要なUnionブランチがスキップされます。このアノテーションをつけることにより、条件が変数ではなくリテラルとして渡されます。SQLオプティマイザは計画時に値がわかるため、その条件に合致しないブランチを省略することができます。
define view entity I_AllDocuments as
select from I_SalesDocument
{
key DocumentID,
@Environment.sql.passValue: true
'SALES' as DocumentType,
CustomerOrVendor,
Amount,
Currency
}
union all
select from I_PurchaseDocument
{
key DocumentID,
@Environment.sql.passValue: true
'PURCHASE' as DocumentType,
CustomerOrVendor,
Amount,
Currency
}
SELECT * FROM I_AllDocuments WHERE DocumentType = 'SALES'
このアノテーションは、各ブランチがその項目に対して異なる固定値(リテラル)を返す場合のみ有効です(SQLオプティマイザが事前に各ブランチが返す値がわかっている必要がある)。
また、毎回異なる条件で実行する場合、リテラル渡しでは毎回新しい実行計画が作成される(キャッシュが効かない)可能性があるため、かならずしもパフォーマンスが良くなるとは限りません。
UnionではなくUnion Allを使う
各Unionブランチに同じレコードがある場合、union allは重複をそのまま出力しますが、unionは重複を削除してから出力します。unionは重複削除のためにソートまたはハッシュ処理が必要であり、全件をマテリアライズする必要があります。union allはこれらの処理が不要なため、パフォーマンスが優れています。
重複が許容できる場合、または、異なるブランチで重複が発生しないことがわかっている場合は、Union Allを使用しましょう。
2. DBヒント(USE_HEX_PLAN)はパフォーマンスを改善することがある
DBヒントにより、SQLオプティマイザがクエリをどのように実行するか指定することができます。Plan Vizで見たときにColumnエンジンとRowエンジンの切り替えが発生している場合などに、HEXプランを指定することでパフォーマンスが改善する可能性があります。
DBヒントは@Consumption.dbHintsアノテーションで指定します。
@ObjectModel.usageType:{
serviceQuality: #X,
sizeCategory: #S,
dataClass: #MIXED
}
@VDM.viewType: #CONSUMPTION
@Consumption.dbHints: [ 'USE_HEX_PLAN' ]
define view entity ...
as select from ...
@Consumption.dbHintsアノテーションはCDS Viewのスタックを伝播しないので、それぞれのCDS Viewで設定する必要があります。
また、DBヒントを設定してもそれが必ず使われるとは限りません。