概要
pythonでWEBスクレイピングした結果をエクセルに出力する処理を作ってみました。
前提条件
Pythonが既にインストールされていること。
「openpyxl」がインストールされていること。
(【Python】エクセルの入力内容の読み込みと書き出しをしてみたの続編です。)
requestsとbeautifulsoup4の導入
コンソールを開いて下記のコマンドを実行して「requests」と「beautifulsoup4」をインストールする。
pip install requests
pip install beautifulsoup4
WEBスクレイピングの実装
作成したWEBスクレイピングのプログラムは下記になります。
import requests
from bs4 import BeautifulSoup
import openpyxl
#最初の情報を取ったかのフラグ
kaisyaflg = 0
zyuusyaflg = 0
# 「テスト用.xlsx」を開く
wb = openpyxl.load_workbook('./テスト用.xlsx')
# 開くシートを指定
sheet = wb['シート1']
#2行、1列目のセルに入力されている内容を読み込む
value = sheet.cell(row=2, column=1).value
url = value
html = requests.get(url)
soup = BeautifulSoup(html.content, "html.parser")
# すべてのddタグを検索して、その文字列を表示する
for element in soup.find_all("dd"):
#「株式会社」が含まれていたら出力
if '株式会社' in element.text:
if(kaisyaflg == 0):
print(element.text.strip())
kaisyaflg = 1
#2列、2行目のセルに会社名を書き込む
sheet.cell(row=2, column=2).value = element.text.strip()
#「〒」が含まれていたら出力
elif '〒' in element.text:
if(zyuusyaflg == 0):
#「〒」の文字が左から何番目に出現するかを出力(0が最初)
a = element.text.find('〒')
#2行、3列目のセルに郵便番号を書き込む
sheet.cell(row=2, column=3).value = element.text[a+1:a+9].strip()
#「〒」の文字が出た所の次から8番目まで取得
print(element.text[a+1:a+9].strip())
#2行、4列目のセルに住所を書き込む
sheet.cell(row=2, column=4).value = element.text[a+10:].strip()
#「〒」の文字が出た所の9番目以降を取得
print(element.text[a+10:].strip())
zyuusyaflg = 1
# 「テスト用.xlsx」に書き込んだ内容を保存する
wb.save('./テスト用.xlsx')
# 「テスト用.xlsx」を閉じる
wb.close()
■処理内容
エクセルの処理については前回の記事で説明したので割愛します。
エクセルの2行、1列目に記載しているURLのHTML内容を下記で取得してきています。
html = requests.get(url)
取得したHTMLの内容を下記でデータの抽出をするための要素に格納します。
soup = BeautifulSoup(html.content, "html.parser")
<dd>タグのものを1つだけでなくすべて取得するために下記FOR文でHTMLの行数分検索して対象の行を取得しています。
for element in soup.find_all("dd"):
<dd>タグで「株式会社」または「〒」が含まれていたら取得するようにif文で制御してます。
実行テストで使用したQiitaはグループ会社の情報も含まれていたため、本社の情報だけ取得するために
kaisyaflgとzyuusyaflg のフラグを用意してます。
また、取得項目に改行が含まれていたため、取得した文字列にstrip()を追加して改行コードを削除しています。
実行結果
実行前のエクセルは下記になります。
■エクセル
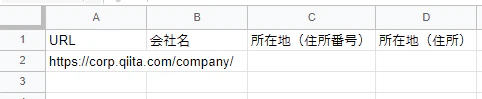
実行した結果は以下のようになります。
■コンソール結果

■エクセル
