【目次】
1. はじめに
2. 実行環境
3. pythonの実行環境の準備
4. 歌詞の収集
5. 分析の流れ
6. 出現単語の特徴の可視化
7. 分類モデルの構築
8. 似ている歌詞の抽出
9. おわりに
1. はじめに
だいぶ前に、どこかで「機械学習で文豪(太宰治・森鷗外・芥川龍之介)どの作家なのかを分類できる」という話を聞いたことがあり、「そんなことまでできるの?」と半信半疑ながらもとても面白そうだなぁと思っていました。
自然言語処理を学び始めた今、これを試さないわけにはいきません!
文豪でもいいのですが、その人ならではの文章の特徴やクセを自分なりに理解できている方が面白そうだなぁと思い、自分が好きな女性のシンガーソングライターの分類をすることにしました。
選んだのは、下記の三名です。
- 椎名林檎:
- 文学性に毒がまざった独特の歌詞
- テーマの根底に人や女としての"業"のようなものを感じる。吉原の花魁っぽい
- 西野カナ
- 女子高生の青春がつまった、せつなさ・さわやかさを感じさせる歌詞
- 清楚系のギャル
- Cocco
- 海/風/花/星など、彼女の故郷である沖縄を想起させる歌詞が多い
- 闇深い曲もあれば、エネルギーに満ち溢れている曲もあり、自然そのものという感じ
予想では、椎名林檎は一番独特なので分類精度が高いのではないかと。
Coccoはダーク系とさわやか系、両方あるので、前者は椎名林檎、後者は西野カナに誤判定されることもありそうだと考えています。
では、早速やってみます![]()
2. 実行環境
- PC:Widow surface 7 pro
- 言語:python3.12.1
- 使用サービス:Google Colaboratory
3. pythonの実行環境の準備
まず、必要なライブラリをインポートします。
# データフレーム/配列/文字列の操作等
import pandas as pd
import numpy as np
import math
import os
import shutil
import random
import re
import unicodedata
from collections import Counter
# 可視化(# matplotlibだけだと、日本語が文字化けするため、japanize_matplotlibもインポートする)
import matplotlib.pyplot as plt
!pip install japanize-matplotlib
import japanize_matplotlib
# スクレイピング関連
import requests
from bs4 import BeautifulSoup
import time
# 形態素解析
!pip install janome
from janome.tokenizer import Tokenizer
# TF-IDF変換
from sklearn.feature_extraction.text import TfidfVectorizer
# ランダムフォレスト関連(分類)
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
# 文書の類似度算出
from gensim.models.doc2vec import Doc2Vec, TaggedDocument
# ワードクラウド(頻出単語の可視化)
! pip install wordcloud
from wordcloud import WordCloud
次に、Google Driveをマウントし、MyDrive/Aidemy_Datasetの下にLYIYCSというディレクトリを作ります。今回作成するデータセットはここに置きます。
(※Google Colaboraoryはローカルにアクセスできないので、Google Driveにデータを置く必要があります)
# MyDrive配下のディレクトリにCSVを保存したいので、MyDriveをマウントする
from google.colab import drive
drive.mount('/content/drive')
main_dir = os.path.join("/content/drive/MyDrive/Aidemy_DataSet/", "LYLICS")
# ディレクトリが存在しない場合:ディレクトリを作成する
if not os.path.exists(main_dir):
os.makedirs(main_dir)
4. 歌詞の収集
歌詞検索サービスのUta-Netさんのページから、スクレイピングで歌詞を抽出していきます。
歌手を検索して表示されるURLから歌手IDをメモします。
歌手IDをもとに、それぞれの歌詞一覧ページのURLのリストを作成します。
artist_id_dict = {'椎名林檎': 3361, '西野カナ': 7429, 'Cocco': 176}
dmain = 'https://www.uta-net.com/artist/'
artist_url_list = [[a_name, dmain + str(a_id)] for a_name, a_id in artist_id_dict.items()]
print(artist_url_list[0])
# >>>['椎名林檎', 'https://www.uta-net.com/artist/3361']
歌詞一覧ページのHTMLソースから、曲名・歌詞・作詞者を取得してデータフレームにして返す関数を作成します。
HTMLソースから自分が必要な情報が含まれる塊をざっくり取ってきて、その中から必要な情報だけをピンポイントで抽出するイメージです。
def get_song_df(artist_info):
artist_name, artist_url = artist_info[0], artist_info[1]
response = requests.get(artist_url)
soup = BeautifulSoup(response.text, 'lxml')
info_list = soup.find_all('tr', class_='border-bottom')
info_list = [info for info in info_list if len(info.find_all('td',class_='sp-w-100 pt-0 pt-lg-2')) > 0]
# print(info_list[0])
# <tr class="border-bottom"><td class="sp-w-100 pt-0 pt-lg-2">
# <a class="py-2 py-lg-0" href="/song/67676/">
# <span class="fw-bold songlist-title pb-1 pb-lg-0">愛妻家の朝食</span>
# <span class="d-inline d-lg-none ps-1 icon-new-senko-crown"><img alt="GOLD LYLIC" decoding="async" height="14" loading="lazy" src="https://ures.jp/uta-net.com/img/ranking/crown_gold.png" width="18"/></span>
# <span class="d-block d-lg-none utaidashi text-truncate">昼過ぎに珍しくテレビをちょっとだけ観たわ 果物が煙草の害を少し防ぐと言うの それですぐこの間のお店へ買いに急いだわ 御出掛けになるのなら必ず召し上がってね 貴方はきっと外では違う顔なのでしょう? だから此の手は其の疲れを癒す為だけに在るの 今朝の様にお帰りが酷く遅い日も屡々 明け方の孤独にはピアノで舞踏曲(ポロネーズ)を 貴方はそっと指先で髪を撫でるでしょう? だからいま黒く揺蕩うまま伸ばす理由は只ひとつ 処でこんな情景をどう思われますか? 差し詰め勝手気儘な嘘を云いました 態とらしい空の色も全部疎ましくて だから右手に強く握る光など既に見えない… 「もう 何も要りません。」</span>
# </a>
# <a class="d-none d-lg-inline pe-1 ps-1 icon-new-senko-crown" href="https://www.uta-net.com/ranking/total/">
# <img alt="GOLD LYLIC" decoding="async" height="14" loading="lazy" src="https://ures.jp/uta-net.com/img/ranking/crown_gold.png" width="18"/>
# </a>
# </td>
# <td class="sp-none fw-bold"><a href="/artist/3361/">椎名林檎</a></td>
# <td class="sp-none fw-bold"><a href="/lyricist/33281/">椎名林檎</a></td>
# <td class="sp-none fw-bold"><a href="/composer/34308/">椎名林檎</a></td>
# <td class="sp-none fw-bold"><a href="/arranger/2641/">森俊之</a></td>
# <td class="sp-none fw-bold"><span class="d-block pc-utaidashi">昼過ぎに珍しくテレビをちょっとだけ観たわ 果物が煙草の害を少し防ぐと言うの それですぐこの間のお店へ買いに急いだわ 御出掛けになるのなら必ず召し上がってね 貴方はきっと外では違う顔なのでしょう? だから此の手は其の疲れを癒す為だけに在るの 今朝の様にお帰りが酷く遅い日も屡々 明け方の孤独にはピアノで舞踏曲(ポロネーズ)を 貴方はそっと指先で髪を撫でるでしょう? だからいま黒く揺蕩うまま伸ばす理由は只ひとつ 処でこんな情景をどう思われますか? 差し詰め勝手気儘な嘘を云いました 態とらしい空の色も全部疎ましくて だから右手に強く握る光など既に見えない… 「もう 何も要りません。」</span></td>
# </tr>
song_name_list = []
lyric_list = []
lyric_staff_list = []
# 曲ごとに情報を取得
for info in info_list:
# 曲名取得
song_name = info.find('span', class_='fw-bold songlist-title pb-1 pb-lg-0').text
# print(song_name)
# >>>愛妻家の朝食
# 歌詞取得
lyric = info.find('span', class_='d-block d-lg-none utaidashi text-truncate').text
# print(lyric)
# >>>昼過ぎに珍しくテレビをちょっとだけ観たわ 果物が煙草の害を少し防ぐと言うの それで・・・
# 作詞者取得
staff_list = info.find_all('td', class_='sp-none fw-bold')
staff_list = [staff.find('a') for staff in staff_list if len(staff.find_all('a')) > 0 ]
staff_dict = {staff.get('href').split("/")[1]: staff.text for staff in staff_list}
# print(staff_dict)
# >>>{'artist': '椎名林檎', 'lyricist': '椎名林檎', 'composer': '椎名林檎', 'arranger': '森俊之'}
lyric_staff = staff_dict['lyricist']
# print(lyric_staff)
# >>>椎名林檎
#リストに追加
song_name_list.append(song_name)
lyric_list.append(lyric)
lyric_staff_list.append(lyric_staff)
#2秒待機
time.sleep(2)
# データフレーム化する
df = pd.DataFrame({'artist_name': artist_name
,'song_name': song_name_list
,'lyric_staff': lyric_staff_list
,'lyric': lyric_list})
return df
3人の歌手ごとに関数を適用し、3つのデータフレームを縦につなげます。
1人当たり15分くらいかかりました。
all_song_df = pd.DataFrame(columns=['artist_name','song_name','lyric_staff','lyric'])
for artist_info in artist_url_list:
each_song_df = get_song_df(artist_info)
all_song_df = pd.concat([all_song_df, each_song_df],axis=0,ignore_index=True)
曲によっては本人が作詞していないこともあるので、本人による作詞の曲に絞ってから、先ほど作成したLYRICSディレクトリにCSVで出力します。
※もちろんデータフレームをそのまま使うこともできますが、歌詞の収集にかなり時間がかかるので、後でのやり直しを避けるためにCSVを保存しておいたほうが無難です。
# artist_nameとlyrics_staffごとに集計してみる
check_df = all_song_df.groupby(['artist_name', 'lyric_staff']).agg({'song_name': 'count'}).reset_index()
check_df = check_df.sort_values(by=['artist_name','song_name'],ascending=[True, False])
for artist in artist_url_list:
show_df = check_df[check_df['artist_name']==artist[0]].head()
print(show_df)
# artist_name lyric_staff song_name
# 28 椎名林檎 椎名林檎 114
# 27 椎名林檎 山上路夫 2
# 35 椎名林檎 渡辺あや 2
# 11 椎名林檎 CYNDI LAUPER・BILLY STEINBERG 1
# 12 椎名林檎 Jack Brown 1
# artist_name lyric_staff song_name
# 39 西野カナ Kana Nishino 118
# 48 西野カナ Kana Nishino・GIORGIO 13 13
# 42 西野カナ Kana Nishino・DJ Mass(VIVID Neon*) 6
# 45 西野カナ Kana Nishino・DJ Mass(VIVID Neon*)・ENVIE 5
# 52 西野カナ Kana Nishino・Kanata Okajima 4
# artist_name lyric_staff song_name
# 1 Cocco Cocco 139
# 4 Cocco こっこ 68
# 0 Cocco BEGIN 1
# 2 Cocco Cocco・長田進 1
# 3 Cocco Dr.StrangeLove 1
# lyrics_staffがartist本人のデータに絞る
self_list = ['Cocco', '椎名林檎', 'Kana Nishino']
all_song_df_self = all_song_df[all_song_df['lyric_staff'].isin(self_list)]
# CSVで出力
file_path = os.path.join(main_dir,'lyric_by_artist.csv')
all_song_df_self.to_csv(file_path, encoding='cp932',errors="ignore")
出力されたCSVはこんな感じです。
5. 分析の流れ
今回の分析のフォーカスは「歌詞から歌手を判定する分類モデルを作ること」ですが、定性的な解釈ができる分析もしてみたいので、「出現単語の可視化」と「似ている歌詞の抽出」もしてみたいと思います。
| 分析 | データの前処理 | |
|---|---|---|
| 1 | 出現単語の特徴の可視化 | 形態素解析(文章を最小単位の単語に分解し、不要な単語を除外する) |
| 2 | 歌手の分類 | ベクトル化(文書中に単語がどのように分布しているかを数値化する。具体的には、各単語に対し文章中の重み情報"TF-IDF値"を算出し、配列として出力する) |
| 3 | 似ている歌詞の抽出 | コサイン類似度の算出(2つの文書ベクトルの近さを0-1であらわす数値) |
6. 出現単語の特徴の可視化
ここはボリュームが多いので下記3ステップに分けて説明します。
- step1: データを扱いやすくするために辞書化する
- step2: 形態素解析をする
- step3: 品詞ごとに、出現回数の多い単語を棒グラフで可視化
- step4: 総合的に、出現回数の多い単語をWordCloudで可視化
step1. データを扱いやすくするために辞書化する
先ほど歌詞データをpandasのデータフレームにしましたが、扱いやすくするために、曲ごとにID(song_id)を振り、song_idをKEY、その他の情報(歌手名/曲名/歌詞)をVALUEとする辞書を作成します。
※このプロセスを挟んでいるのは、個人的な好みです。集計や加工をする上ではデータフレームのほうがいいのですが、特定のsong_idの情報を取り出すのは辞書の方が楽なので。
# 出力済のCSVをデータフレームで読み込む
file_path = os.path.join(main_dir,'lyric_by_artist.csv')
song_df = pd.read_csv(file_path, encoding='cp932')
song_df = song_df.drop(['Unnamed: 0','lyric_staff'], axis=1)
# 歌手ごとに、曲にIDをふる
# 椎名林檎: sr001, sr002, sr003, ...
# 西野カナ:nk001, nk002, nk003, ...
# Cooco :cc001, cc002, cc003, ...
artist_name_list = ['椎名林檎', '西野カナ','Cocco']
artist_initial_list = ['sr', 'nk', 'cc']
artist_initial_dict = dict(zip(artist_name_list, artist_initial_list))
song_df['song_id'] = ''
for nm,init in artist_initial_dict.items():
id_list = [init + str(i+1).zfill(3) for i in range(len(song_df[song_df['artist_name']==nm]))]
song_df.loc[song_df['artist_name']==nm,'song_id'] = id_list
# song_idを一番左に持ってくる
song_df = song_df[['song_id','artist_name', 'song_name', 'lyric']]
# print(song_df.head())
# >>>
# song_id artist_name song_name lyric
# 0 sr001 椎名林檎 愛妻家の朝食 昼過ぎに珍しくテレビをちょっとだけ観たわ 果物が煙草の害を少し防ぐと言うの それですぐこの間...
# 1 sr002 椎名林檎 アイデンティティ 是程多くの眼がバラバラに何かを探すとなりゃあ其れなり 様々な言葉で各々の全てを見極めなくちゃ...
# 2 sr003 椎名林檎 あおぞら 片付いた部屋が温かくて 曇り窓の外コントラスト 独りで居るのに慣れないまま ジャニスを聴いて...
# 3 sr004 椎名林檎 茜さす 帰路照らされど… 何時もの交差点で彼は頬にキスする また約束も無く今日が海の彼方に沈む ヘッドフォンを耳に充...
# 4 sr005 椎名林檎 あの世の門 It is neither dark here nor light I see a fain...
# song_dfを転置してから辞書化する
song_df_t = song_df[['artist_name', 'song_name', 'lyric']].T
song_df_t.columns = song_df['song_id']
song_dict = song_df_t.to_dict(orient='dict')
# 辞書の構成を確認
for key, val in song_dict['sr001'].items():
print('◆{}:'.format(key), val)
# >>>
# ◆artist_name: 椎名林檎
# ◆song_name: 愛妻家の朝食
# ◆lyric: 昼過ぎに珍しくテレビをちょっとだけ観たわ 果物が煙草の害を少し防ぐと言うの それですぐこの間のお店へ買いに急いだわ 御出掛けになるのなら必ず召し上がってね 貴方はきっと外では違う顔なのでしょう? だから此の手は其の疲れを癒す為だけに在るの 今朝の様にお帰りが酷く遅い日も屡々 明け方の孤独にはピアノで舞踏曲(ポロネーズ)を 貴方はそっと指先で髪を撫でるでしょう? だからいま黒く揺蕩うまま伸ばす理由は只ひとつ 処でこんな情景をどう思われますか? 差し詰め勝手気儘な嘘を云いました 態とらしい空の色も全部疎ましくて だから右手に強く握る光など既に見えない… 「もう 何も要りません。」
# song_idをリストに格納
song_id_list = list(song_dict.keys())
# print(song_id_list[:5])
# >>>['sr001', 'sr002', 'sr003', 'sr004', 'sr005']
step2. 形態素解析をする
歌詞を単語に分解し、正規化し、不要文字列を除去する関数を作成します。
ここで言う不要文字列とは、分析上ノイズになるであろう単語のことで、特に意味を持たない記号や特殊文字、助詞や助動詞などです。
この作業は分析精度を高めるにはとても重要で、後で実施する出現回数の集計結果やモデルの精度を見ながら、試行錯誤を繰り返しました。
分析によっては、表記の違う同じ意味の単語(「あなた」と「貴方」、「君」と「キミ」など)を名寄せするという方法も有効ですが、今回は表記の仕方も歌手の特徴の一つと考えられるので、実施しませんでした。
▼参考記事:
自然言語処理における前処理の種類とその威力
# 分かち書きのための生成器を作成
t = Tokenizer()
# 残したい品詞のリスト
pos_list = ['名詞', '形容詞', '副詞', '動詞', '連体詞', '接続詞']
# 分かち書ちされた単語を正規化し、不要文字列を除外するための関数
def wd_cleaning(wd):
# 文字列の正規化(全角を半角へ、アルファベットは小文字にする)
wd = unicodedata.normalize('NFKC', wd).lower()
# 不要文字列を''に置換するための正規表現(アルファベット、改行コード、記号など)※「?」などは名詞扱いされてしまう
code_regex = re.compile(r'[a-z0-9#&!,?\'()~\-...…;:“]')
cleaned_wd = code_regex.sub('', wd)
return cleaned_wd
# 歌詞を形態素解析するための関数
def lyric_cleaning(lyric):
# check = [[wd.surface, wd.part_of_speech.split(",")] for wd in t.tokenize(lyric)]
# print(check[:3])
# >>>[['昼過ぎ', ['名詞', '副詞可能', '*', '*']], ['に', ['助詞', '格助詞', '一般', '*']], ['珍しく', ['形容詞', '自立', '*', '*']]]
# 歌詞を分かち書きし、指定した品詞に限り、[単語の原形, 品詞]のセットをリストで返す
lyric_sep = [[wd.base_form, wd.part_of_speech.split(",")[0]] for wd in t.tokenize(lyric) if wd.part_of_speech.split(",")[0] in pos_list]
# 不要文字列を除外
lyric_sep= [wd for wd in lyric_sep if wd_cleaning(wd[0]) != '']
# 改行コードが除外しきれていないことがあるので、含まれている場合は除外する
lyric_sep= [wd for wd in lyric_sep if '\u3000' not in wd[0]]
# 意味をなさない言葉が残ることがあるので、除外する
kana_list = [chr(i) for i in range(12353, 12436)]
stopwds_list = kana_list + ['ー','する','いる','てる','なる','れる','られる','せる']
lyric_sep= [wd for wd in lyric_sep if wd[0] not in stopwds_list]
return lyric_sep
song_idごとに形態素解析のための関数を適用し、単語リストと品詞リストを辞書に追加します。
for song_id in song_id_list:
lyric = song_dict[song_id]['lyric']
# テキストを分かち書きし、除外指定した品詞以外の形態素を残す
lyric_sep = lyric_cleaning(lyric)
# print(lyric_sep[:5])
# >>>[['昼過ぎ', '名詞'], ['珍しい', '形容詞'], ['テレビ', '名詞'], ['ちょっと', '副詞'], ['観る', '動詞']]
# 単語と品詞のリスト(集計用)と、単語を空白でjoinした文字列(モデル構築用)を、辞書に追加する
lyric_sep_wds = [wds for wds, pos in lyric_sep]
lyric_sep_pos = [pos for wds, pos in lyric_sep]
song_dict[song_id]['lyric_wds'] = lyric_sep_wds
song_dict[song_id]['lyric_pos'] = lyric_sep_pos
song_dict[song_id]['lyric_wds_join'] = ' '.join(lyric_sep_wds)
# 辞書の構成を再確認
for key, val in song_dict['sr001'].items():
print('◆{}:'.format(key), val)
# >>>
# ◆artist_name: 椎名林檎
# ◆song_name: 愛妻家の朝食
# ◆lyric: 昼過ぎに珍しくテレビをちょっとだけ観たわ 果物が煙草の害を少し防ぐと言うの (以下略)]
# ◆lyric_wds: ['昼過ぎ', '珍しい', 'テレビ', 'ちょっと', '観る', '果物', '煙草', '害', '少し', '防ぐ', '言う'(以下略)]
# ◆lyric_pos: ['名詞', '形容詞', '名詞', '副詞', '動詞', '名詞', '名詞', '名詞', '副詞', '動詞' (以下略)]
# ◆lyric_wds_join: 昼過ぎ 珍しい テレビ ちょっと 観る 果物 煙草 害 少し 防ぐ 言う(以下略)
step3: 品詞ごとに、出現回数の多い単語を棒グラフで可視化
いよいよ可視化です。
辞書のままだと集計ができないので、データフレーム化してから歌手×品詞ごとに単語の出現回数を集計します。
# 辞書から分かち書きされた単語と品詞を抽出してリストにする
lyric_wds_list = [song_dict[song_id]['lyric_wds'] for song_id in song_id_list]
lyric_pos_list = [song_dict[song_id]['lyric_pos'] for song_id in song_id_list]
songids_list = [[song_id] * len(lyric_wds) for song_id, lyric_wds in zip(song_id_list, lyric_wds_list)]
# リストが二次元になっているので、一元化する
lyric_wds_list_flatten = sum(lyric_wds_list, [])
lyric_pos_list_flatten = sum(lyric_pos_list, [])
songids_list_flatten = sum(songids_list, [])
# print(len(lyric_wds_list),len(lyric_wds_list_flatten))
# >>> 371 52829
# データフレームにする
lyric_df = pd.DataFrame({'song_id': songids_list_flatten
,'wd': lyric_wds_list_flatten
,'pos': lyric_pos_list_flatten})
lyric_df['artist_name'] = lyric_df['song_id'].apply(lambda x: song_dict[x]['artist_name'])
# 歌手名×品詞ごとに単語の出現回数をカウントする
lyric_df_gp = lyric_df.groupby(['artist_name','pos','wd']).size().to_frame('cnt').reset_index()
lyric_df_gp = lyric_df_gp.sort_values(by=['artist_name','pos','cnt'],ascending=[True, True, False]).reset_index(drop=True)
# 歌手名×品詞ごとに出現回数のランクをつける
lyric_df_gp['cnt_rank'] = lyric_df_gp.groupby(['artist_name','pos'])['cnt'].rank(ascending=False)
# print(lyric_df_gp.query('artist_name=="Cocco" and pos=="名詞"').head())
# >>>
# artist_name pos wd cnt cnt_rank
# 906 Cocco 名詞 あなた 118 1.0
# 907 Cocco 名詞 手 77 2.0
# 908 Cocco 名詞 君 74 3.0
# 909 Cocco 名詞 何 71 4.0
# 910 Cocco 名詞 花 69 5.0
# print(lyric_df_gp.query('artist_name=="椎名林檎" and pos=="形容詞"').head())
# >>>
# artist_name pos wd cnt cnt_rank
# 5813 椎名林檎 形容詞 ない 58 1.0
# 5814 椎名林檎 形容詞 無い 52 2.0
# 5815 椎名林檎 形容詞 いい 20 3.5
# 5816 椎名林檎 形容詞 良い 20 3.5
# 5817 椎名林檎 形容詞 欲しい 17 5.0
集計結果を横棒グラフで可視化するための関数を作成します。
横棒グラフは縦棒グラフよりもクセが強く、なかなか時間がかかりました![]()
▼参考記事:
- matplotlib の理解が劇的に深まる、図の構成要素と Artist の話
- matplotlibのめっちゃまとめ
- pyplotではxticks()、Axesではset_xticklabels()を使うんだって。
def wdcnt_graph_show(target_pos):
# 指定した品詞のデータを抽出
target_df = lyric_df_gp.query('pos == @target_pos')
# 歌手ごとにTOP30の品詞と単語のリストを抽出してリストに格納
ginfo_list = []
for artist_name in artist_name_list:
# TOP30を抽出した後、昇順で並び替え(横棒グラフで降順で表示するための処理)
artist_df = target_df.query('artist_name == @artist_name and cnt_rank <= 30').sort_values(by='cnt',ascending=True)
ginfo_list.append([artist_name, artist_df['wd'].tolist(), artist_df['cnt'].tolist()])
# artistごとに横棒グラフで表示
fig = plt.figure(figsize=(30,15))
plt.suptitle('【{}における出現回数】'.format(target_pos), fontsize=30)
for idx, ginfo in enumerate(ginfo_list):
artist_name, wd_list, cnt_list = ginfo[0], ginfo[1], ginfo[2]
# ランキングする単語数を取得(品詞によってはTOP30もないことがあるので)
rank_num = len(wd_list)
# 出現回数のラベル用
cnt_labels = np.linspace(0, max(cnt_list), 5)
# print(cnt_labels)
# >>>[ 0. 30.5 61. 91.5 122. ]
# 棒グラフを描画
ax = fig.add_subplot(1, 3, idx+1)
ax.set_title(artist_name, fontsize=25)
ax.barh(wd_list, cnt_list)
# set_ytics,set_xticks:ラベルの位置を指定
# set_yticslabels,set_xtickslabels:ラベルの値とフォントサイズを指定
# ※set_ytics,set_xticksを指定せずに実行するとwarningが出るので注意
ax.set_yticks(range(rank_num))
ax.set_yticklabels(wd_list,fontsize=20)
ax.set_xticks(cnt_labels)
ax.set_xticklabels(cnt_labels,fontsize=20)
ax.grid(linestyle='dotted', linewidth=1,axis='x',color="r")
plt.show()
品詞ごとに出現回数TOP30の単語のグラフを表示します。
歌手ごとの特徴が強く出ていると感じられた「名詞」のグラフがこちら。
wdcnt_graph_show("名詞")
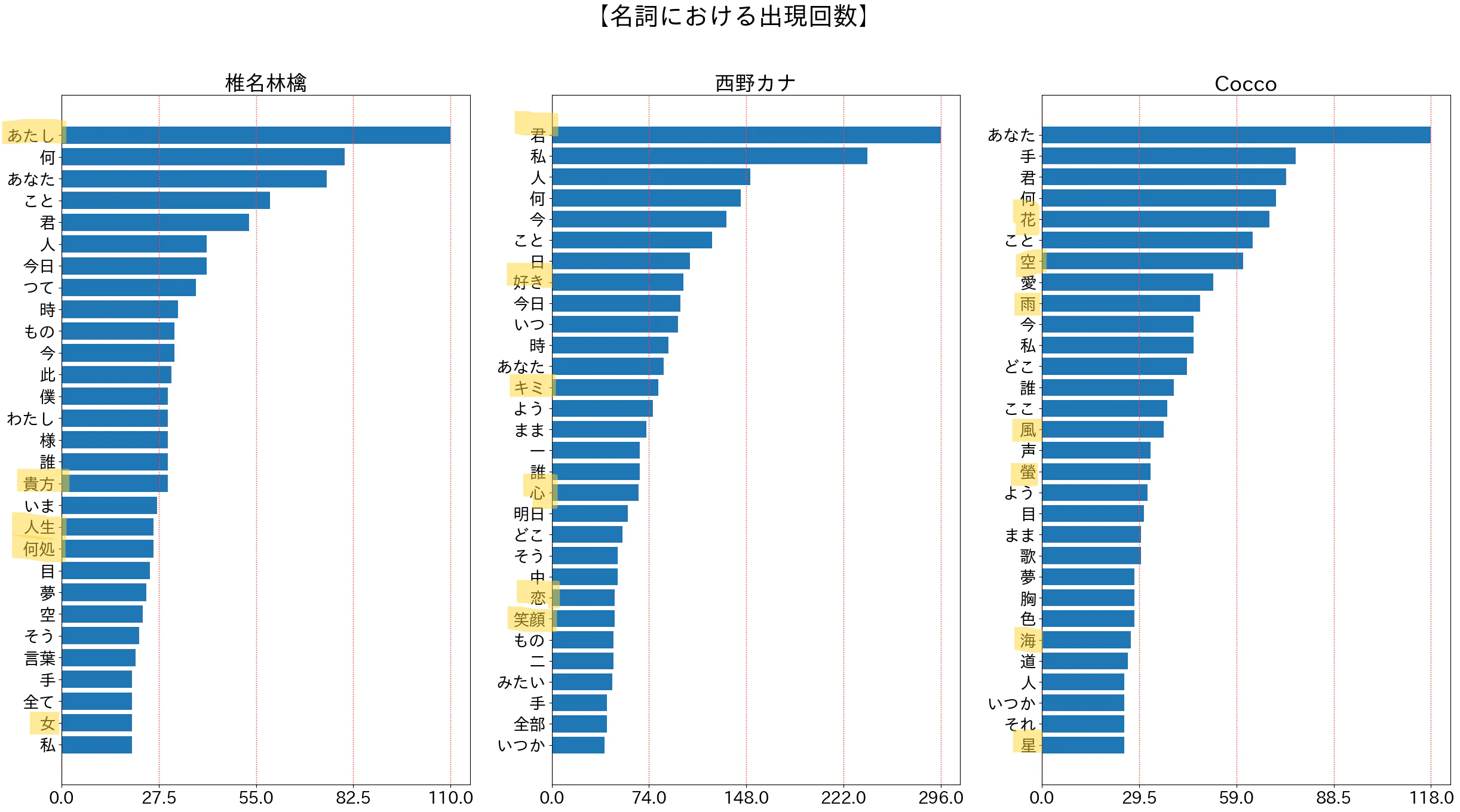
- 椎名林檎の第一人称が「あたし」なのはいかにもです。やや蓮っ葉な感じが出ています。「あなた」を「貴方」、「どこ」を「何処」と漢字で表記するのも、彼女ならではです。他の二人には見られない「人生」「女」という単語の、彼女の闇深めの世界観を感じます。
- 西野カナの第二人称が「あなた」ではなく「君/キミ」が圧倒的に多いのも納得です。「君って」といタイトルの曲もあるくらいなので。「好き」「心」「恋」「笑顔」といった青春ワード(?)が多いのも予想通りです。
- Coccoは「花」「空」「風」「蛍」「海」「星」などの自然にかかわるワードが多いです。曲を聴いているときは特に気に留めませんでしたが、比較すると際立ちますね。
「名詞」ほどではありませんが、「副詞」もなかなか面白かったです。
wdcnt_graph_show("副詞")
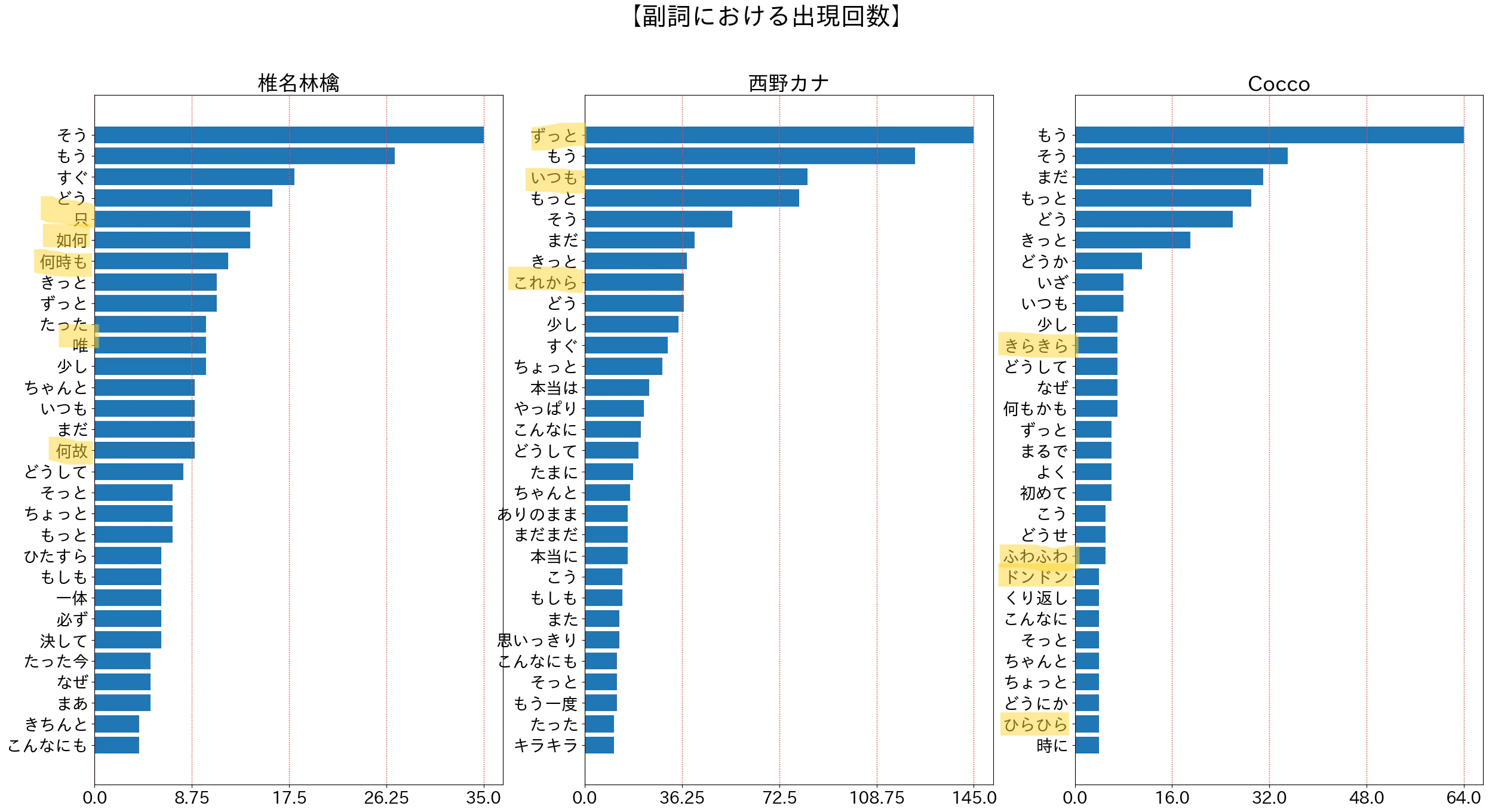
- 椎名林檎は、「只」「如何」「唯」「何故」とあえての漢字表記が多めです。
- 西野カナは、「ずっと」「いつも」「これから」など、永遠を願う文脈を感じさせるワードが目立ちます。
- Coccoは、「きらきら」「ふわふわ」「ドンドン」「ひらひら」などの擬音語・擬態語が特徴的です。
step4: 総合的に、出現回数の多い単語をWordCloudで可視化
品詞ごと横棒グラフで十分特徴はつかめたのですが、品詞を分けずに総合的な可視化もしてみたいと思い、WordCloudでの可視化もしてみました。
尚、GoogleCoraboratoryでWordCloudを実装する上では、一つ注意点があります。
C:\Windows\Fontsにある日本語のフォントファイルのフォントを指定する必要があるのですが、例によってGoogle Colaboraoryはローカルにアクセスできないので、コピーしてGoogle Driveにファイルを置く必要があります。
私はmeiriyo.ttcをLYRICSディレクトリに置きました。
▼参考記事:
# 指定された歌手の、分かち書きされた歌詞を、一つの文字列として返す関数
def get_lyrics(target_artist):
lyrics = [song_dict[song_id]['lyric_wds_join'] for song_id in song_id_list if song_dict[song_id]['artist_name']==target_artist]
lyrics_join= ' '.join(lyrics)
return lyrics_join
# WordCloudのパラメーターを設定
my_font_path = os.path.join(main_dir,'meiryo.ttc')
stop_wds = ['こと','そう','ない','いい','くれる','この','何','ある','よう','ちゃう','まま','もの']
color_list = ['cividis', 'cool_r', 'winter']
# 歌手ごとにWordCloudを表示
fig = plt.figure(figsize=(30,15))
for idx, artist_name in enumerate(artist_name_list):
# 歌詞データを取得
lyrics_join = get_lyrics(artist_name)
# テーマカラー
theme_color = color_list[idx]
# インスタンスを生成
word_cloud = WordCloud(
font_path = my_font_path, # フォントファイルのパス
background_color = 'white',
colormap = theme_color,
width = 400,
height = 300,
stopwords = set(stop_wds),
#collocations = False, # 複合語の表示
max_words = 200,
min_font_size = 15,
max_font_size= 70,
prefer_horizontal=1 # 横書きで配置
)
# 文字列を与えてWordCloud画像を生成
output_img = word_cloud.generate(lyrics_join)
# WordCloudを描画
ax = fig.add_subplot(1, 3, idx + 1)
ax.imshow(output_img)
ax.axis('off')
ax.set_title(artist_name, fontsize=30)
こんな感じで描画されます。
歌手ごとに色を変えたせいもありますが、歌手ごとの歌詞の特徴がちゃんと出ている気がします。

7. 分類モデルの構築
今回のメインテーマである分類モデルを構築します。
下記3ステップに分けて説明します。
- step1: モデル投入用のデータセットを作成
- step2: モデルの構築
- step3: 予測結果の確認
step1: モデル投入用のデータセットを作成
モデル投入するデータは下記の2つです。
- 目的変数:歌手ラベル(椎名林檎:1, 西野カナ:2, Cocco:3)
- 説明変数:歌詞ベクトル(分解された単語を空白でつなげた文字列をTF-IDF変換したもの)
いまのデータは歌手順に並んでいるので、ランダムに並べ替えてから、8:2で訓練用と検証用に分けます。
# 分析の対象となるsong_idのリスト(全編英語詩などは、単語が残らないので省く)
song_id_list_final = [song_id for song_id in song_id_list if len(song_dict[song_id]['lyric_wds'])>0]
print(len(song_id_list),len(song_id_list_final))
# >>>
# 371 338
# 歌手ごとの最終データ数を確認
print(collections.Counter([song_dict[song_id]['artist_name'] for song_id in song_id_list_final]).most_common())
# >>>[('Cocco', 123), ('西野カナ', 118), ('椎名林檎', 97)]
# song_idのリストをランダムにシャッフルしてから、8:2で訓練用とテスト用に分割する
random.seed(0)
train_cnt = int(len(song_id_list_final) * 0.8)
song_id_list_random = random.sample(song_id_list_final, len(song_id_list_final))
song_id_list_train = [song_id for song_id in song_id_list_random[:train_cnt]]
song_id_list_test = [song_id for song_id in song_id_list_random[train_cnt:]]
print(len(song_id_list_train),len(song_id_list_test))
# >>>270 68
# 説明変数(分かち書きされた単語をjoinした文字列)を作成
train_data = [song_dict[song_id]['lyric_wds_join'] for song_id in song_id_list_train]
test_data = [song_dict[song_id]['lyric_wds_join'] for song_id in song_id_list_test]
# 目的変数(歌手名のカテゴリ値)を作成
label_list = [1,2,3]
artist_label_dict = dict(zip(artist_name_list,label_list))
artist_label_dict_rev = dict(zip(label_list, artist_name_list))
# print(artist_label_dict)
# >>>{'椎名林檎': 1, '西野カナ': 2, 'Cocco': 3}
# print(artist_label_dict_rev)
# >>>{1: '椎名林檎', 2: '西野カナ', 3: 'Cocco'}
train_labels = [artist_label_dict[song_dict[song_id]['artist_name']] for song_id in song_id_list_train]
test_labels = [artist_label_dict[song_dict[song_id]['artist_name']] for song_id in song_id_list_test]
print(train_labels[0])
print(train_data[0])
# >>>
# 2
# 今 すぐ 会う もっと 声 聞く こんなにも
説明変数が文字列のままだと解析できないので、TF-IDF値に変換します。
TF-IDF値とは、「単語の出現の分布の偏り」を示す数値です。
単語の出現回数と異なるのは、他の文書と比較してその文書で特有かどうかを加味しているところです。
特定の文書中にのみ多く出現し、他の文書ではあまり出現しないような単語は、TF-IDF値が高くなります。
▼参考記事:
# 単語のTF-IDF値を算出するための生成器を作成
vectorizer = TfidfVectorizer()
# 訓練用の説明変数をTF-IDF行列に変換する
train_vec = vectorizer.fit_transform(train_data)
# 検証用の説明変数をTF-IDF行列に変換する
# ※注意点※
# fit()は訓練データに含まれる単語を学習するために使用され、tranform()は学習したパラメーターに基づいてデータが再形成されます。つまり、訓練データの場合は fit_transform関数を用い、検証データの場合は,訓練データの fit() の結果に基づくので、 transform()関数 を行う必要があります。
test_vec = vectorizer.transform(test_data)
ここから先は、モデルには関係なく、TF-IDF変換されたデータを目視で確認するための作業です。
song_dictから訓練データ用のsong_idの分のみ抽出したtfidf_dictを作成し、新しく単語ごとのTF-IDF値と出現回数のリストを追加します。
# 単語の種類のリストを作成
wd_labels = vectorizer.get_feature_names_out()
# TF-IDF値を配列に変換する
tfidf_array = train_vec.toarray()
# DataFrame形式に変換
tfidf_df = pd.DataFrame(tfidf_array, columns=wd_labels,index=song_id_list_train)
tfidf_df_t = tfidf_df.T
# song_dictから訓練データ用のsong_idの分のみ抽出したtfidf_dictを作成し、新しく単語とtfidf値のセットを追加する
tfidf_dict = {key: val for key,val in song_dict.items() if key in song_id_list_train}
for song_id in song_id_list_train:
# TF-IDF値が0超の単語を抽出し、TF-DF値降順で並べ替え
dt = tfidf_df_t.loc[tfidf_df_t[song_id] > 0, [song_id]].sort_values(by=song_id,ascending=False)
# 単語のリストとTF-IDF値のリストを作成
wd_list = dt.index.tolist()
tfidf_list = dt[song_id].tolist()
# 辞書に単語とTF-IDFのリストを格納
set_list = [(wd, round(tfidf,3)) for wd, tfidf in zip(wd_list, tfidf_list)]
tfidf_dict[song_id]['tfidf_rank'] = set_list
# 単語の出現回数のリストを格納
tfidf_dict[song_id]['count_rank'] = Counter(tfidf_dict[song_id]['lyric_wds']).most_common()
任意のsong_idのTF-IDF値と出現回数、それぞれのTOP10の単語を見てみます。
tfidf_rank = tfidf_dict['nk101']['tfidf_rank']
count_rank = tfidf_dict['nk101']['count_rank']
cnt = 1
for t,c in zip(count_rank, tfidf_rank):
if cnt <= 10:
print('rank{}:{} {}'.format(cnt, t, c))
cnt += 1
else:
break
rank1:('もっと', 14) ('もっと', 0.525)
rank2:('聞く', 7) ('いたい', 0.322)
rank3:('君', 7) ('聞く', 0.284)
rank4:('私', 6) ('セリフ', 0.277)
rank5:('いたい', 5) ('離す', 0.265)
rank6:('離す', 5) ('曖昧', 0.218)
rank7:('今', 4) ('足りる', 0.201)
rank8:('すぐ', 4) ('すぐ', 0.157)
rank9:('会う', 4) ('会う', 0.155)
rank10:('愛', 4) ('どんな', 0.146)
出現回数のランキングと、TF-IDF値のランキングが必ずしも一致しないことがわかります。
出現回数が3位の「君」は、おそらく他の歌詞でも頻出しているので、この歌詞特有であるとはみなされず、TF-IDF値TOP10にはランクインしていません。
逆に、TF-IDF値が4位の「セリフ」は、出現回数TOP10にはランクインしていませんが、他の歌詞にはあまり出てこないので稀有性が高い、ということになります。
step2: モデルの構築
分類モデルのアルゴリズムにはランダムフォレストを使います。
ランダムフォレストには、木の本数や深さなど色々なパラメーターがあるので、グリッドサーチという方法で最適なパラメーターを探索します。
▼参考記事:
# 試したいパラメーターを指定
param_grid = {'n_estimators':[50, 100, 150], #決定木モデルの本数
'max_depth': [5, 7, 9, 11, 13, 15], #それぞれの決定木モデルの深さ
'min_samples_leaf': [1, 3, 5]} #決定木の分割後に葉に必要となってくるサンプル数
# すべての組み合わせでモデルを学習させる
rf_model = RandomForestClassifier(random_state=0)
grid_search = GridSearchCV(rf_model, param_grid, cv=5, return_train_score=True)
grid_search.fit(train_vec, train_labels)
# 一番精度が高いパラメーターを表示
print('best score: {:0.3f}'.format(grid_search.score(test_vec, test_labels))) #検証データの精度
print('best val score: {:0.3f}'.format(grid_search.best_score_)) #訓練データのCross Validationのスコア平均
print('best params: {}'.format(grid_search.best_params_))
# >>>
# best score: 0.882
# best val score: 0.819
# best params: {'max_depth': 15, 'min_samples_leaf': 3, 'n_estimators': 150}
検証データの予測精度は88.2%。思っていたよりいいです!
最適なパラメーターでモデルを確定させます。
rf_model_fix = RandomForestClassifier(n_estimators = 150,
max_depth = 15,
min_samples_leaf = 3).fit(train_vec, train_labels)
step3: 予測結果の確認
検証用データの正解率を、歌手ごとに確認してみます。
# 検証用データの推測ラベルと正解ラベルをリストに格納。
pred_y = rf_model_fix.predict(test_vec)
# データフレームにし、曲のIDと歌詞も追加する
pred_y_init = [artist_label_dict_rev[num] for num in pred_y]
true_y_init = [artist_label_dict_rev[num] for num in test_labels]
result_df = pd.DataFrame({'true_label': true_y_init
,'pred_label': pred_y_init
,'song_id': song_id_list_test})
result_df['song_name'] = result_df['song_id'].apply(lambda x: song_dict[x]['song_name'])
result_df['wds_join'] = result_df['song_id'].apply(lambda x: song_dict[x]['lyric_wds_join'][:30])
# 予測ラベルと正解ラベルのセットで集計
result_df_gp = result_df.groupby(['true_label','pred_label']).size().to_frame('cnt').reset_index()
result_df_total = result_df.groupby('true_label').size().to_frame('total').reset_index()
result_df_gp = pd.merge(result_df_gp, result_df_total, on='true_label',how='inner')
result_df_gp['ratio'] = result_df_gp['cnt']/result_df_gp['total']
result_df_gp['ratio'] = result_df_gp['ratio'].apply(lambda x: '{:.1%}'.format(x))
result_df_gp.sort_values(by=['true_label','cnt'],ascending=[True, False])
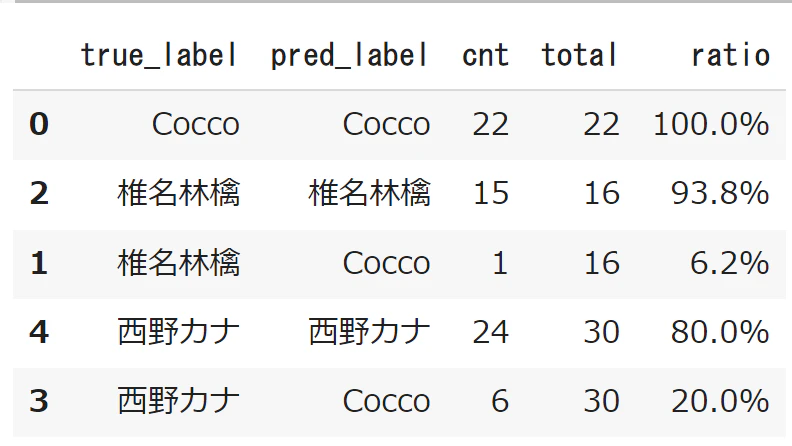
結果はこちら。
正解率が一番高いのは椎名林檎だと予想していたのですが、実際はCoccoでした。
とはいえ、椎名林檎も誤判定されたのは1曲のみなので、十分な精度です。
一番正解率が低いのは西野カナで、すべてCoccoに誤判定されていました。
椎名林檎と西野カナは対極なので、お互いに誤判定されることがない、誤判定されるとしたら、両方のカラーを持つCoccoであるという結果には納得です。
誤判定された曲を確認してみます。
result_df.query('true_label!=pred_label').sort_values(by=['true_label','pred_label'])
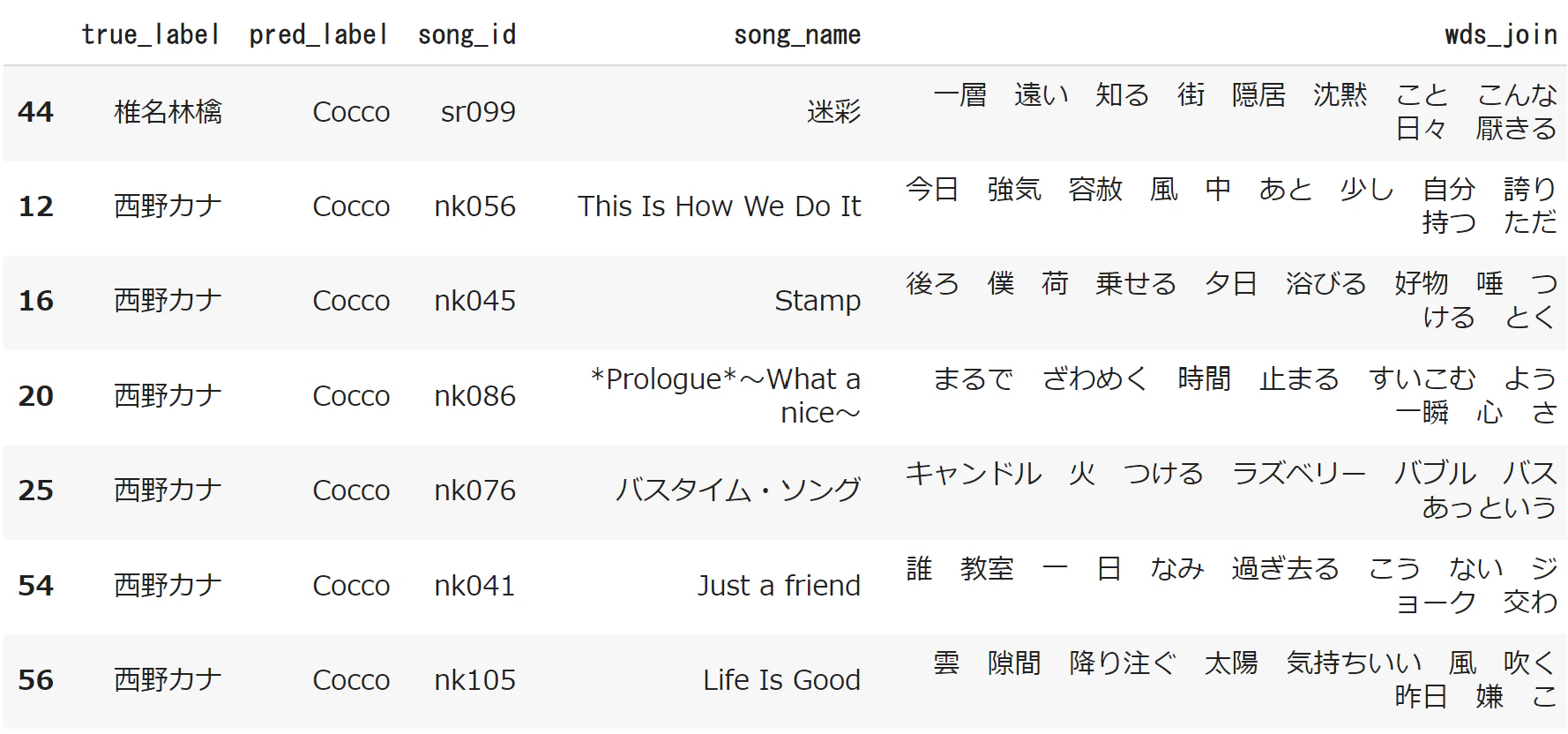
椎名林檎の「迷彩」という曲の歌詞を確認すると、"THE椎名林檎"という感じなのですが、「海」「水」「雲」「雷」といった自然に関するワードが含まれていたので、そこが引っかかったのかもしれません。
西野カナの曲も同様で、「太陽」「風」「雲」などが含まれています。
8. 似ている歌詞の抽出
最後に、歌詞同士を比較して、似ている歌詞の組合せを抽出してみようと思います。
文書の類似度を比較するには、コサイン類似度を使います。
0-1の値を取り、 「1に近い場合は似ていて、0に近いときは似ていない」という意味になります。
下記の数式で算出できます。
def cosine_sim_calc(v1, v2):
cos_sim = np.dot(v1, v2) / (np.linalg.norm(v1)*np.linalg.norm(v2))
return cos_sim
コサイン類似度を算出するためのベクトルは、モデル構築用に作成した訓練データのTF-IDF配列を使います。
# 総当たりで比較する
cos_sim_df_all = pd.DataFrame(columns=['target_song_id','compared_song_id','cos_sim'])
compared_song_id_list = song_id_list_train
for song_id in song_id_list_train:
target_song_id = song_id
# 比較対象のsong_idのリストからtarget_song_idを削除する
compared_song_id_list.remove(target_song_id)
# target_song_idのベクトルを算出
target_vec = tfidf_df_t[target_song_id].tolist()
cos_sim_list = []
# 比較対象のsong_idに対して、コサイン類似度を算出してリストに格納
for song_id in compared_song_id_list:
compared_vec = tfidf_df_t[song_id].tolist()
cos_sim = cosine_sim_calc(target_vec, compared_vec)
cos_sim_list.append(cos_sim)
# 比較対象のsong_idのリストと、類似度をデータフレームにする
cos_sim_df = pd.DataFrame({'target_song_id': target_song_id
,'compared_song_id': compared_song_id_list
,'cos_sim': cos_sim_list})
# 類似度が高い順に並び変えて、TOP5を抽出
cos_sim_df_top5 = cos_sim_df.sort_values(by='cos_sim', ascending=False).reset_index(drop=True).head()
# 全体用のデータフレームに縦に連結
cos_sim_df_all = pd.concat([cos_sim_df_all, cos_sim_df_top5], axis=0)
# コサイン類似度降順で並び替え
cos_sim_df_all = cos_sim_df_all.sort_values(by='cos_sim', ascending=False).reset_index(drop=True)
コサイン類似度が高いTOP10がこちら。
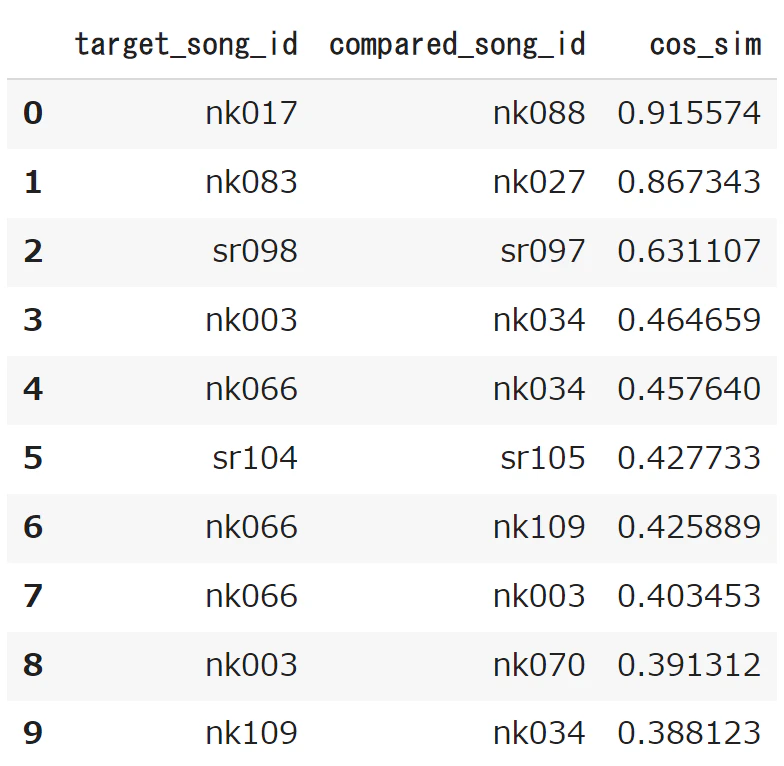
TOP10はすべて同じ歌手による歌詞による組合せになっています。
が、8割が西野カナですね。。
せっかくなので、歌手ごとに類似度TOP3の歌詞の組合わせを見てみたいと思います。
歌手名・曲名・歌詞の歌いだしを表示します。
# 歌手ごとに、TOP3を見てみる
for init in ['sr', 'nk', 'cc']:
cos_sim_df_init1 = cos_sim_df_all.query('target_song_id.str.startswith(@init)', engine='python')
cos_sim_df_init2 = cos_sim_df_all.query('compared_song_id.str.startswith(@init)', engine='python')
cos_sim_df_init2 = cos_sim_df_init2[['compared_song_id','target_song_id','cos_sim']]
cos_sim_df_init_comb = pd.concat([cos_sim_df_init1, cos_sim_df_init2],axis=0).drop_duplicates()
# コサイン類似度降順で並びなおす
cos_sim_df_init_comb = cos_sim_df_init_comb.sort_values(by='cos_sim', ascending=False).reset_index(drop=True)
# TOP3の情報を表示する
for i in range(3):
target_song_id = cos_sim_df_init_comb.loc[i, 'target_song_id']
compared_song_id = cos_sim_df_init_comb.loc[i, 'compared_song_id']
cos_sim = cos_sim_df_init_comb.loc[i, 'cos_sim']
print('◆類似度TOP{} ({})'.format(i+1, round(cos_sim,3)))
print('{}/{}/{}'.format(song_dict[target_song_id]['artist_name']
,song_dict[target_song_id]['song_name']
,song_dict[target_song_id]['lyric']))
print('{}/{}/{}'.format(song_dict[compared_song_id]['artist_name']
,song_dict[compared_song_id]['song_name']
,song_dict[compared_song_id]['lyric']))
print()
print('-----------------------------------------------')
◆類似度TOP1 (0.631)
椎名林檎/丸の内サディスティック (EXPO Ver.)/Playing cops and robbers 'neath Ginza signs All wh
椎名林檎/丸の内サディスティック/報酬は入社後並行線で 東京は愛せど何も無い リッケン620頂戴 19万も持って居ない 御茶の水
◆類似度TOP2 (0.428)
椎名林檎/やっつけ仕事/毎日 襲来する強敵 電話の電鈴(ベル) 追つては平穏なる感度を慾するのさ 高速 渋滞とは云つても低
椎名林檎/やつつけ仕事/毎日襲来する強敵電話のベル 追っては平穏なる感度を欲するのさ 高速 渋滞とは云っても低速だろう 真
◆類似度TOP3 (0.274)
椎名林檎/カプチーノ/あと少しあたしの成長を待って あなたを夢中にさせたくて 藻掻くあたしを可愛がってね 今度逢う時はコ
椎名林檎/プライベイト/今日あたりはたった一人“ランチに繰り出してみる”ことも “満員の地下鉄に乗る”も大事なことなんだと思
-----------------------------------------------
◆類似度TOP1 (0.916)
西野カナ/*Epilogue* ~Just LOVE~/Good night, Have sweet dreams 今日はどんな1日だった? wow Tod
西野カナ/*Prologue* ~Let's go~/Wake up, Have a nice day 今日はどんな日になるかな wow Today, I
◆類似度TOP2 (0.867)
西野カナ/*Prologue*~Kirari~/アラーム鳴る前に目覚めた morning sun 閉ざす雲突き抜けた光 カーテンにこぼれた お気に
西野カナ/Kirari/アラーム鳴る前に目覚めた morning sun 閉ざす雲突き抜けた光 カーテンにこぼれた お気に
◆類似度TOP3 (0.465)
西野カナ/アイラブユー/正直最初はそうでもなかった いい人だけどなんだかなぁ そういう昔話をするたびに キミはスネるけど
西野カナ/GO FOR IT !!/L.O.V.E. Y.O.U!! L.O.V.E. Y.O.U!! GO! GO! GO FOR I
-----------------------------------------------
◆類似度TOP1 (0.249)
Cocco/楽園/夏の終りを知るのは なにも あなただけじゃない わたしだけでもない 雨に怯えていたのは そうね 小
Cocco/2.24/歪? 輩? 賄? さようなら あなた 白い体は 波に ゆらゆら揺れて 消える 黙っていれば過ぎる
◆類似度TOP2 (0.242)
Cocco/花爛/どこかにいれば 会えるはず どこにもいない 影じゃなく どうして / なんでの くり返し 己が招
椎名林檎/ありきたりな女/幼い頃から耳を澄ませば、ほんとうに小さな音も聴こえて来た。遠い雲 が雨を手放す間に、木々の笑う声。時
◆類似度TOP3 (0.24)
Cocco/飛花落花/眠る場所も ないくせに 帰る場所は あると信じたい それ以上 何も言わないで もう罰を 受けてるから
Cocco/バイバイパンプキンパイ/ここにいて 私の側に ここにいて 手をつないでいて 黄金に光る 季節に問う 立ち昇る あの雲は ど
-----------------------------------------------
椎名林檎のTOP1(丸の内サディスティックと丸の内サディスティック (EXPO Ver.))、TOP2(やっつけ仕事 vs やつつけ仕事)と西野カナのTOP2(Prologue*~Kirari~とKirari)に関しては、同じ曲のアレンジ違いのようなので、ほぼ歌詞が同じでした。
西野カナのTOP1(*Epilogue* ~Just LOVE~ vs *Prologue* ~Let's go~)も、同じ枠組みで作られているようで、歌詞がかなり似ています。類似度が高くて当然ですね。
こういうバージョン違いを除外するために、次回からはモデル用のデータセットを作る前に類似度を算出して確認するプロセスをはさんでもいいかもしれません。
CoccoのTOP1の「楽園」と「2.24」の歌詞を確認したところ、どちらにも「しゃりら」という独特な擬音語が使われており、世界観もダークで似ていると感じました。類似度のスコアは0.249と低めですが、なかなかいい感じです。
9. 終わりに
自然言語処理の中でもシンプルなテクニックを使って分析をしましたが、十分面白い結果が得られました。
自分の解釈(歌手のクセや特徴)と、自然言語処理による定量的な分析結果は一致するのか、というほぼ自己満足のための分析ではありましたが、遠く感じていた自然言語処理の世界が少し身近に感じられるようになりました![]()
単語の前後関係(文脈)や時系列も加味できるアルゴリズム(Doc2VecやLSTM)を使えるようになったら、できることがもっと広がるので、引き続き地道に勉強していきたいと思います。
ここまで読んでいただき、ありがとうございました![]()