はじめに
Glue Job(Sparkタイプ)を使って、Redshift Serverlessのデータを参照したりインサートしたりするために、
GlueデータカタログのConnectionを使って、Redshift Serverlessと接続する方法を整理しています。
以下のAWS記事を参考にしています。
ユーザーガイド: Redshift 接続
Repost: 接続トラブルシューティング
この記事でわかること
本記事では接続までで、GlueJobを実行する部分は次回記事にて掲載します
構成図
Glue JobとRedshift Serverless間の接続についての構成を、図にしてみます。
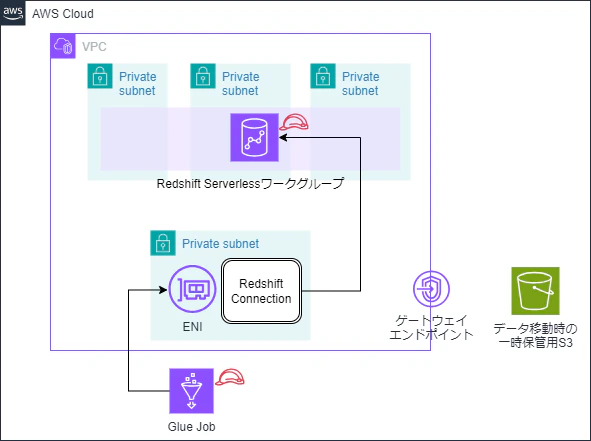
リソース一覧
IAM関係リソース
- Glue Job用のIAMロール、ポリシー
- Redshift Serverless用のIAMロール、ポリシー
Glue Jobのロールには、S3アクセス関連のポリシーを付与(Redshift関連は不要)し、
Redshift用のロールには、S3の読み取りと書き込みを許可するポリシーが必要1です。
ネットワーク関係リソース
- Glue用VPCプライベートサブネット
- Redshift Serverless用VPCプライベートサブネット × 3
- Connection用のセキュリティグループ
Glue JobがVPC内で動くときのサブネットを指定します。
Redshift Serverlessのワークグループは、サブネットを3つ以上紐づけが必要です2。
今回のセキュリティグループは、GlueとRedshift双方に設定するものを作成します3。
Glue関連リソース
- Glue Job
- GlueデータカタログConnection
Glue Jobに、作成したGlue Job用のロールを紐づけます。
Glue Connectionには、サブネットやセキュリティグループ、Redshiftの認証情報なども設定していきます。
Redshift Serverless関連リソース
- Redshift Serverlessワークグループ、名前空間
ワークグループに、サブネット、セキュリティグループを設定します。
名前空間には、ロールを紐づけます。
(その他Glue Job実行時に必要なリソース)
- S3バケット
- S3用VPCエンドポイント
SparkタイプGlue JobでConnectionを使ってRedshiftに接続する場合、
データの移動はS3を経由して行われる45ため、Glue Jobを実行する際にはS3が必要となります。
またそのときVPC内のConnectionがVPC外のS3と接続するために、エンドポイントが必要です。
(ゲートウェイ型のエンドポイントを利用しています)
設定手順
AWSマネージドコンソールの設定画面をもとに整理しています。
※プライベートサブネット, S3バケット, S3用ゲートウェイエンドポイントは、作成済みとして進めます。
セキュリティグループの設定
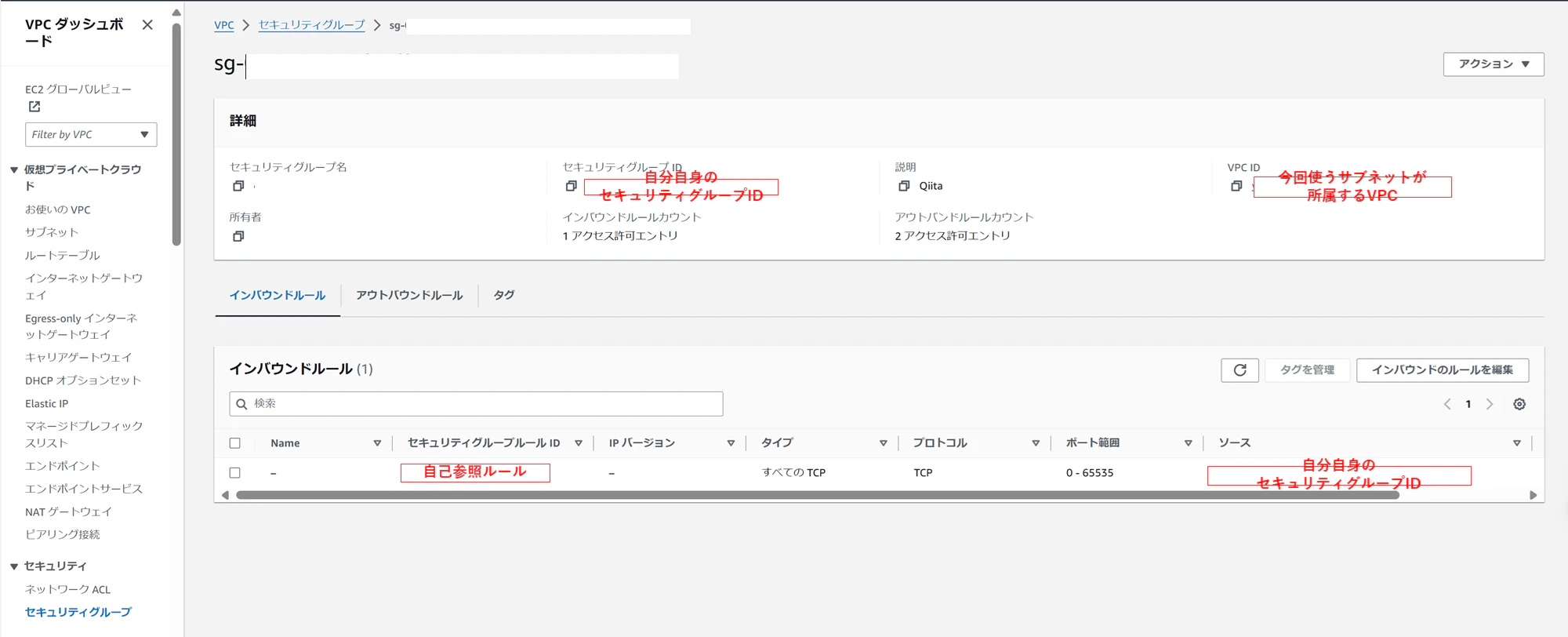
VPC画面サイドバーのセキュリティグループから、セキュリティグループを作成します。
インバウンドルールに自己参照ルールを設定します。
(自己参照ルールとは6)
[Type (タイプ)] All TCP、[Protocol (プロトコル)] は TCP、[Port Range (ポート範囲)] にはすべてのポートが含まれ、[Source (ソース)] は [Group ID (グループ ID)] と同じセキュリティグループ名であるというルール
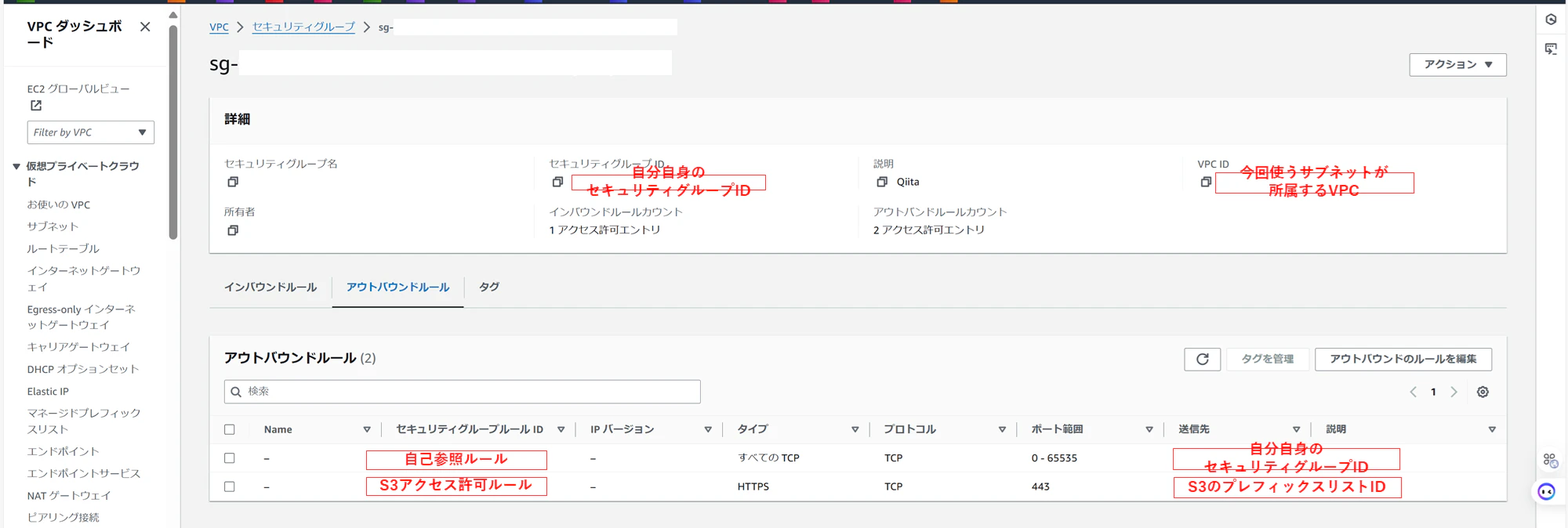
アウトバウンドルールは、自己参照ルールと、S3エンドポイントへのアクセスを許可するルールを設定します3。
IAMの設定
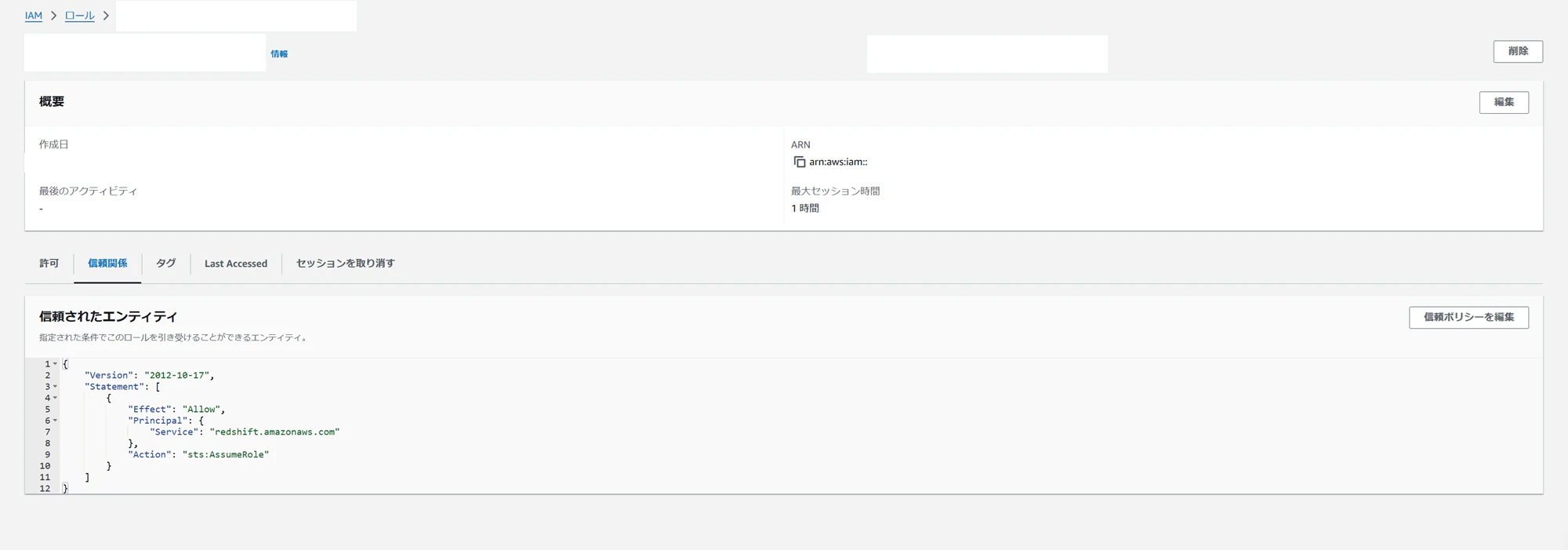
IAM画面サイドバーのロールから、IAMロールを作成します。まずはRedshiftServerless用のロールを作成します。
まず、Redshift Serverlessがこのロールを使用できるように信頼ポリシーを定義しています。
続けて、ロールにアタッチするポリシーの設定をします。
S3の読込み、書込みアクションを許可します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListBucket",
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject",
"s3:AbortMultipartUpload",
"s3:ListMultipartUploadParts",
"s3:ListBucketMultipartUploads"
],
"Resource": [
"arn:aws:s3:::<利用するS3バケット名>/*",
"arn:aws:s3:::<利用するS3バケット名>"
]
}
]
}
次に、GlueJob用のロールを作成します。
まず、Glue Jobがこのロールを使用できるように信頼ポリシーを定義しています。
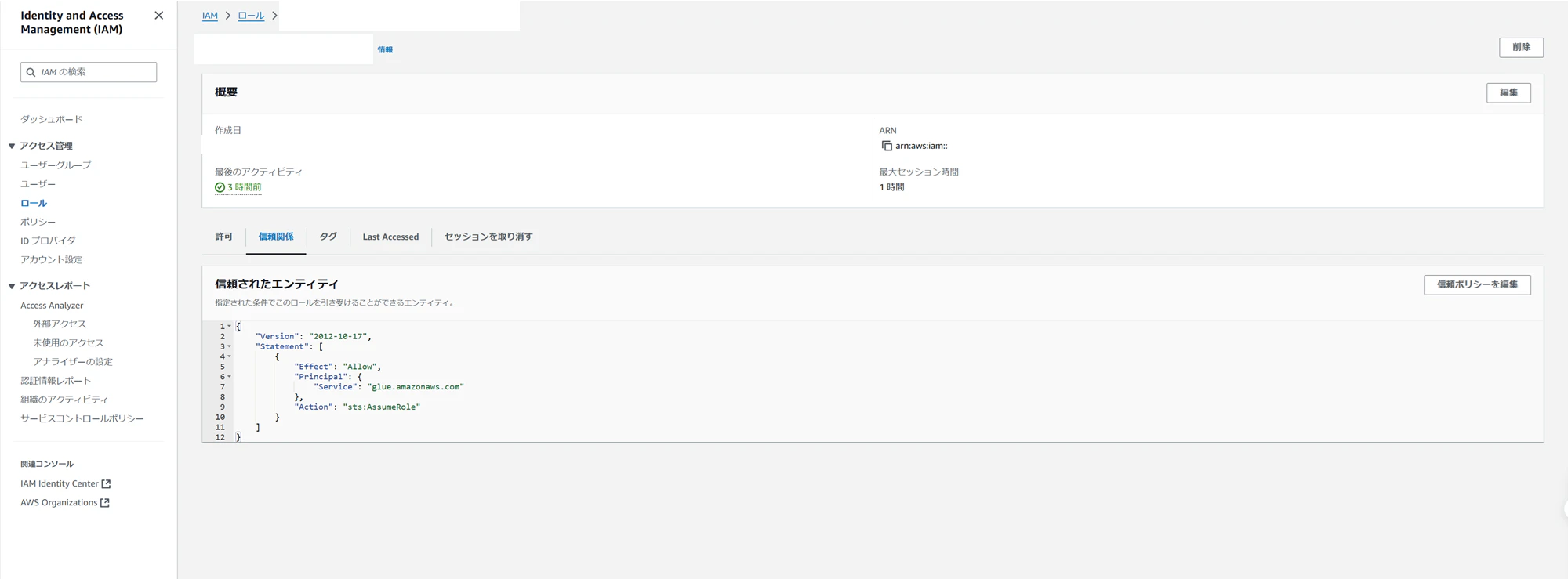
続けて、ロールにアタッチするポリシーを設定します。
GlueJobの実行関連アクション許可、S3の読込み、書込みアクション許可、ネットワーク関連アクション許可を設定します。
(CloudWatch関連アクション許可は任意ですが、今後ログ確認するために設定しています)
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"glue:GetConnection",
"glue:StartJobRun",
"glue:GetJobRun",
"glue:GetJobRuns",
"glue:BatchStopJobRun"
],
"Resource": [
"arn:aws:glue:*:*:*"
]
},
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::<利用するS3バケット名>/*",
"arn:aws:s3:::<利用するS3バケット名>"
]
},
{
"Effect": "Allow",
"Action": [
"ec2:DescribeVpcAttribute",
"ec2:DescribeVpcs",
"ec2:DescribeSubnets",
"ec2:DescribeSecurityGroups",
"ec2:DescribeNetworkInterfaces",
"ec2:DescribeVpcEndpoints",
"ec2:DescribeRouteTables",
"ec2:CreateTags",
"ec2:CreateNetworkInterface",
"ec2:DeleteNetworkInterface"
],
"Resource": [
"*"
]
},
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": "arn:aws:logs:*:*:log-group:*"
},
{
"Effect": "Allow",
"Action": [
"cloudwatch:PutMetricData",
"cloudwatch:GetMetricData",
"cloudwatch:GetMetricStatistics",
"cloudwatch:ListMetrics"
],
"Resource": "*"
}
]
}
RedshiftServerlessの設定
Redshift画面からサーバレスダッシュボード画面に移動し、ワークグループを作成します。
プライベートサブネット3つと、先ほど作成したセキュリティグループを設定します。
(今回必要な設定以外は、基本デフォルト設定のままにしています)
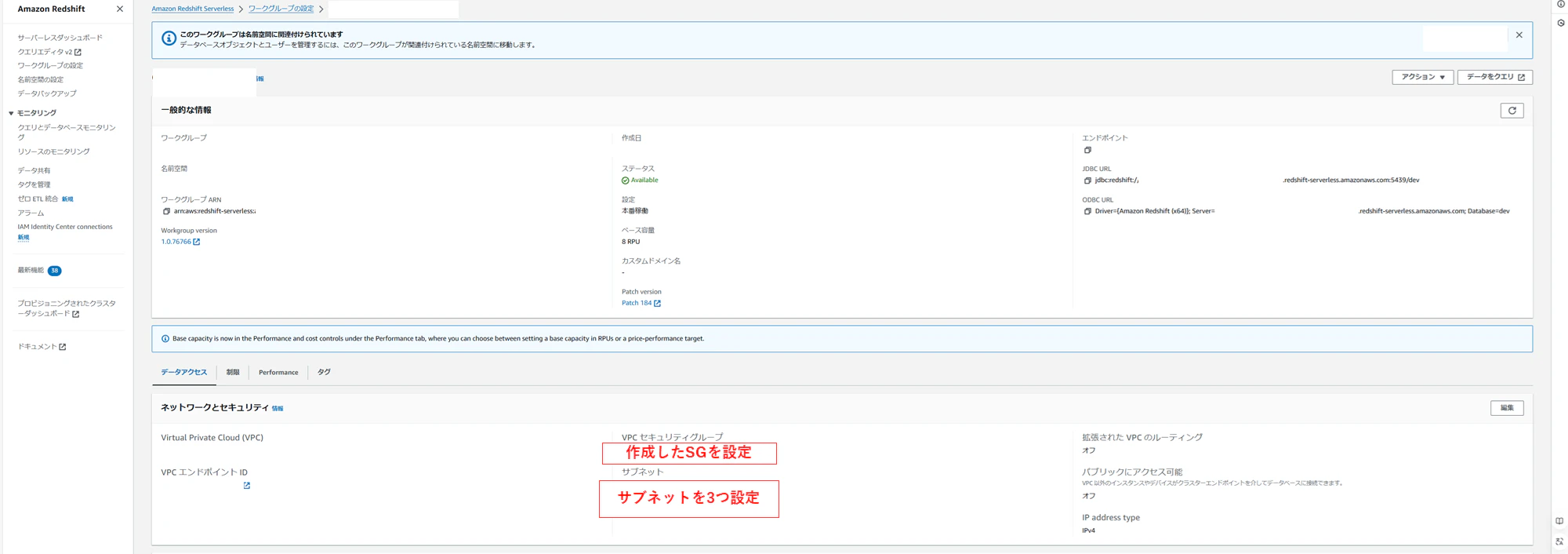
続けて、名前空間を設定します。
(管理者ユーザー名とパスワードは任意で問題ないですが、後でGlue Connection設定で使います)

Glueの設定
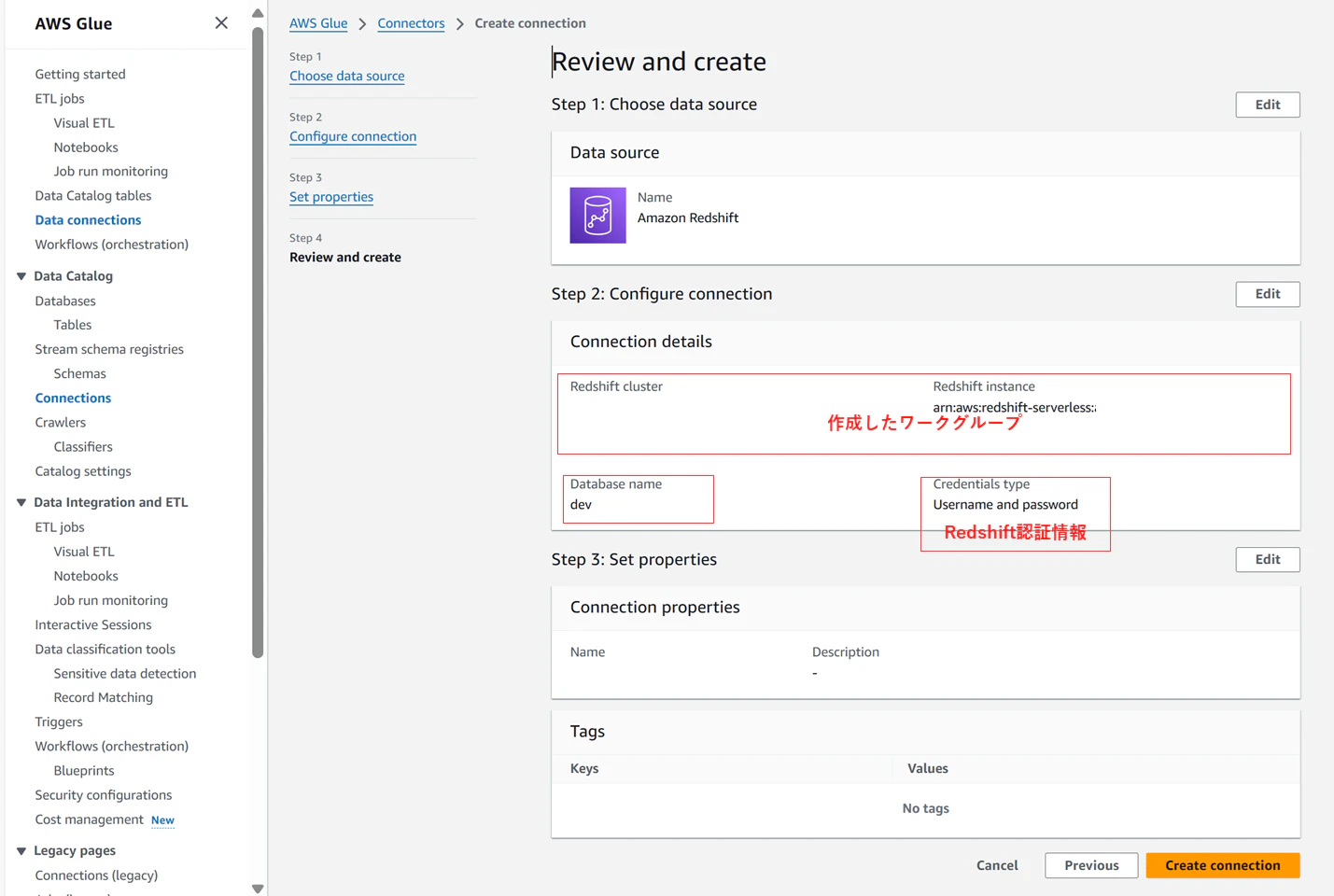
Glue画面サイドバーのData Connectionsに移動し、Redshift用Connectionを選択します。
作成したRedshiftServerlessのワークグループとデータベース名(デフォルトのdev)を指定します。
Redshift認証情報は今回、RedshiftServerless名前空間作成時に設定した管理者ユーザーとパスワードを直書きして設定しています。
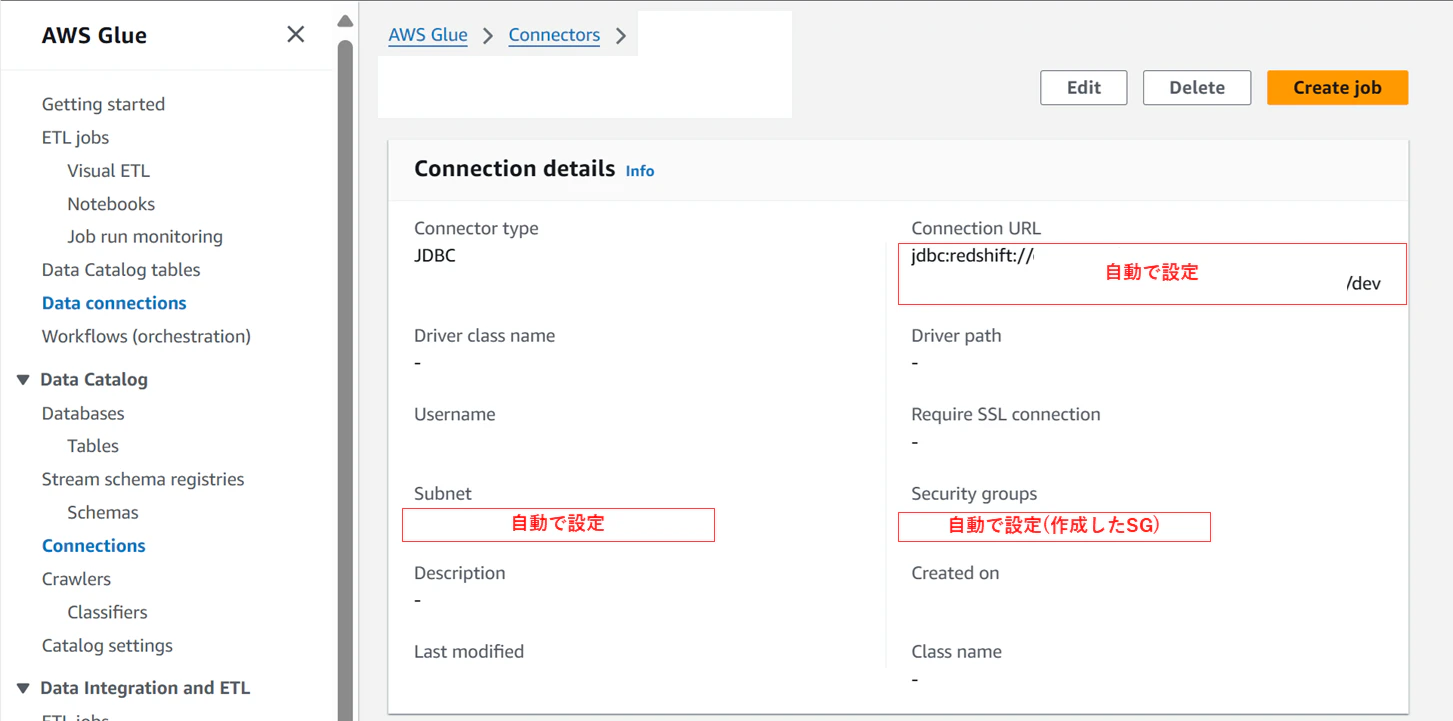
作成後、Connectionの設定を確認すると、ネットワーク情報(JDBC URL, サブネット, セキュリティグループ)が自動で設定されています。
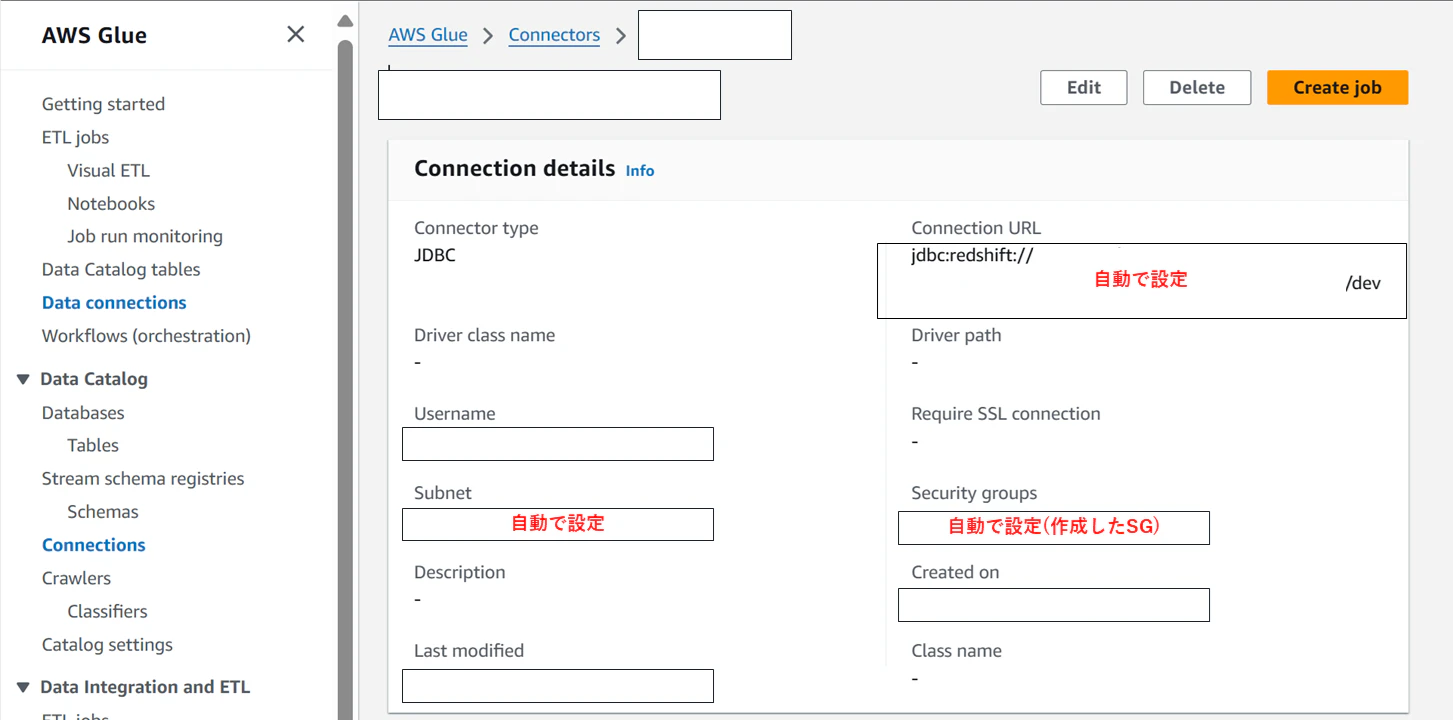
次に、Glue Jobを作成します。Glue画面サイドバーのETL jobsから新規作成を行います。
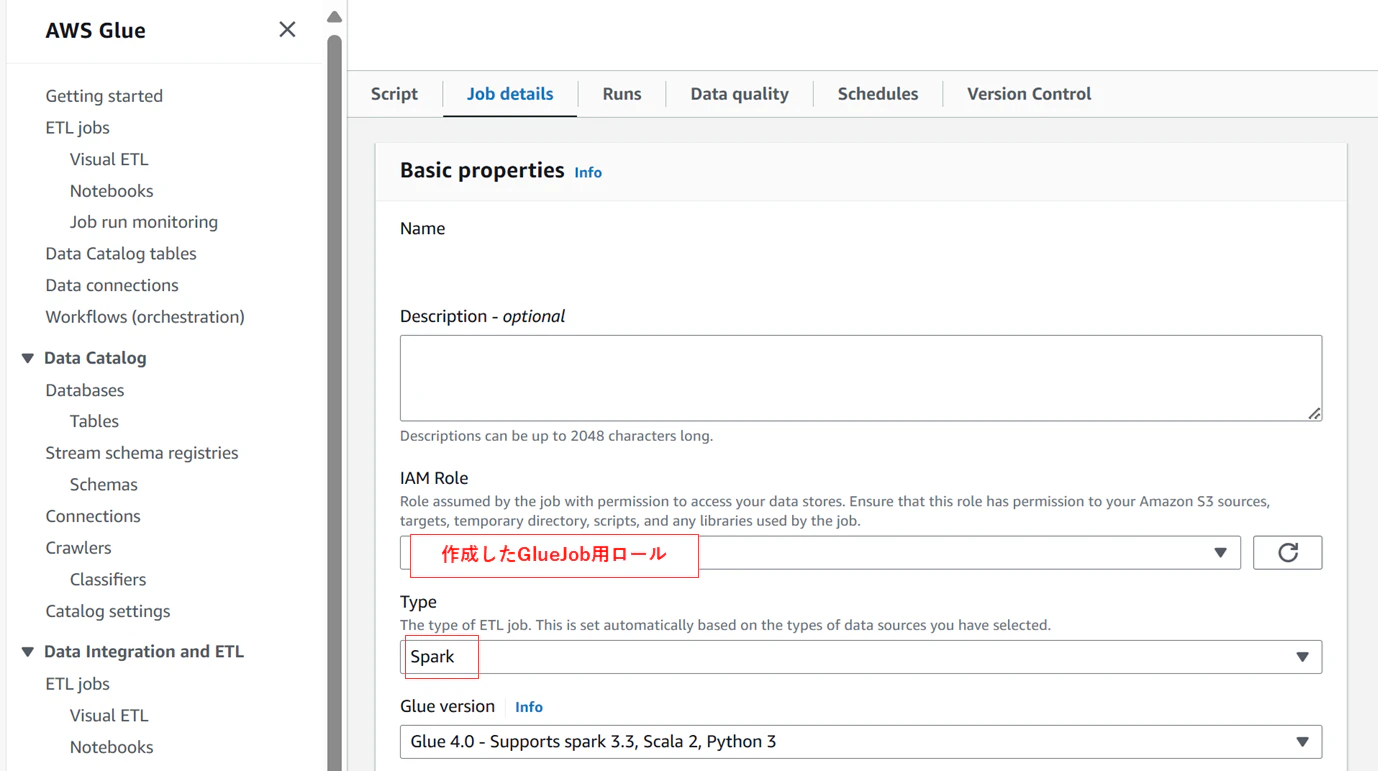
Job detailsタブにて、作成したGlueJob用ロールを設定します。タイプは「Spark」を指定します。
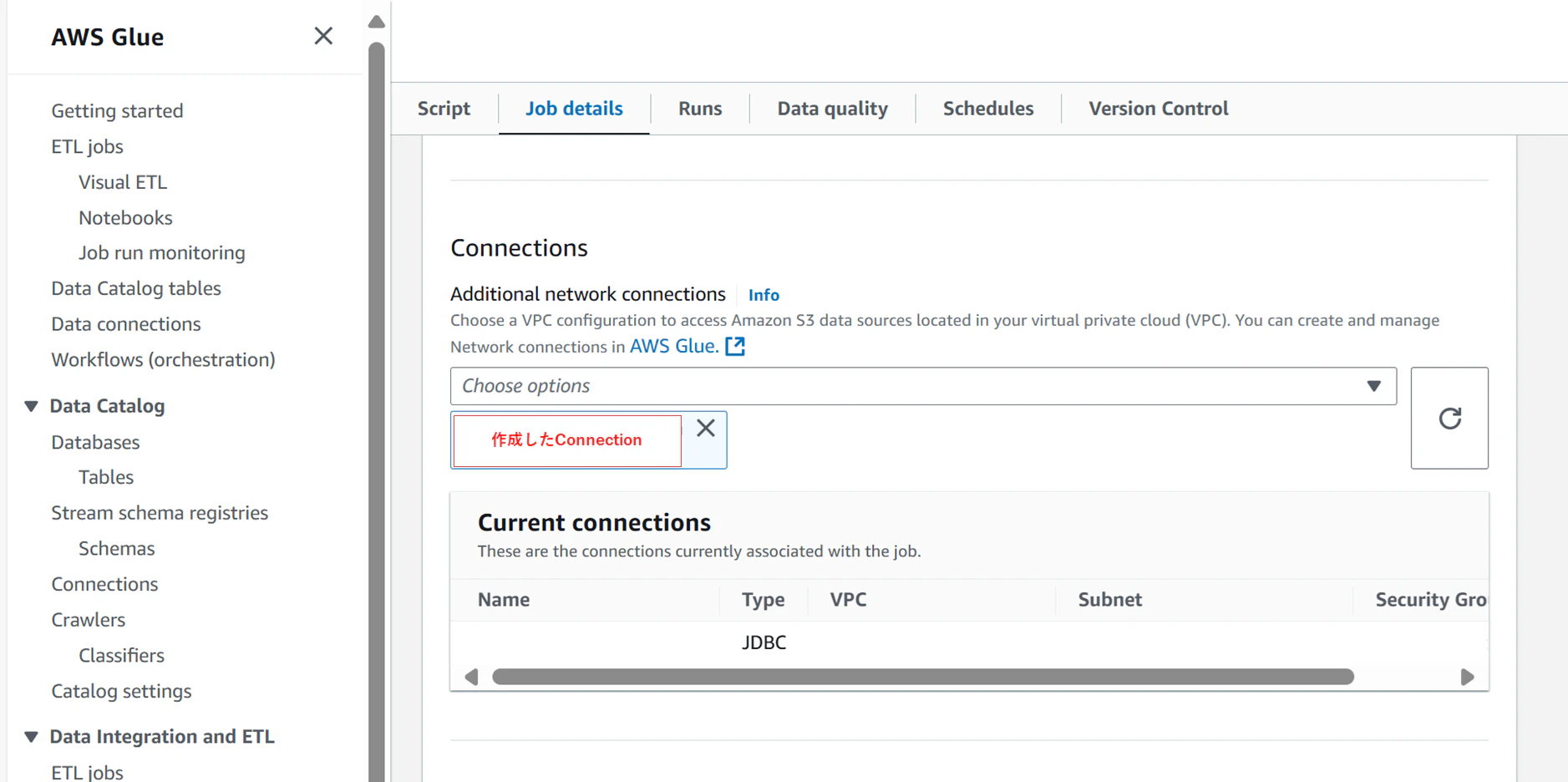
Connections設定には、先ほど作成したConnectionを指定します。
(その他、今回必要な設定以外は、基本デフォルト設定のままにしています)
接続確認してみる
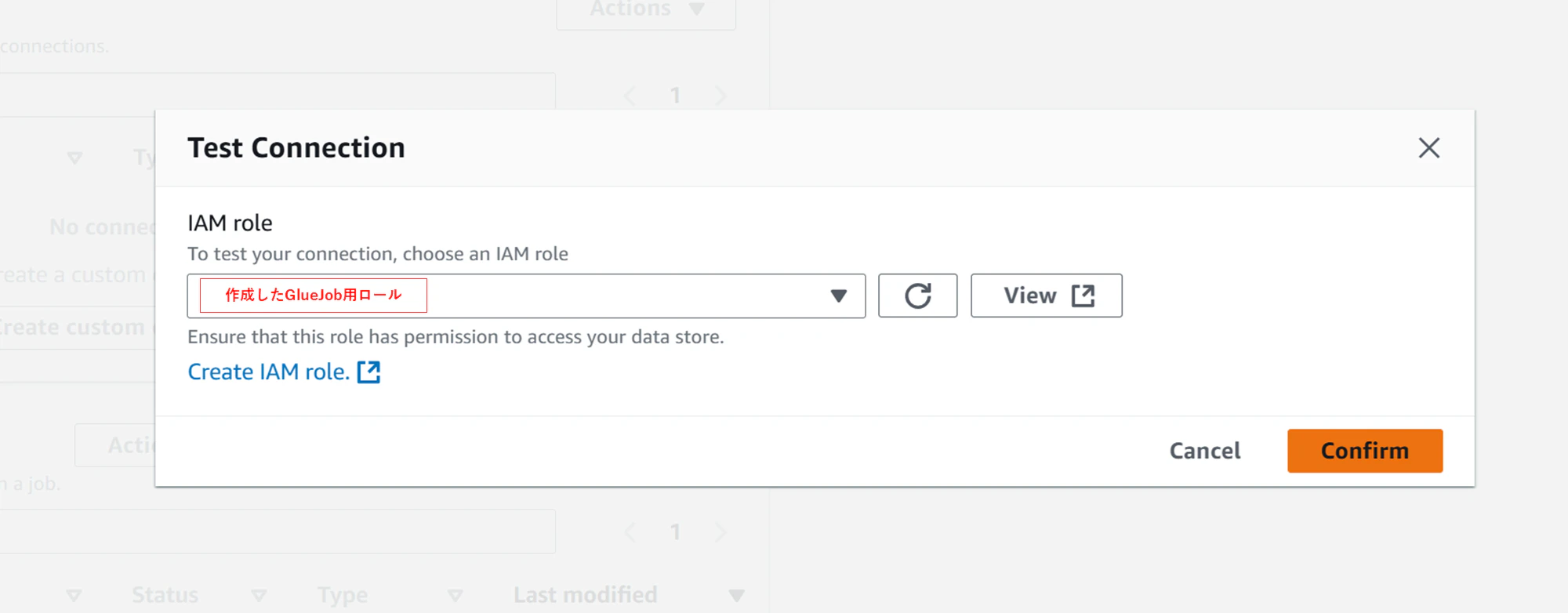
Data Connectionsの画面に戻って、作成したConnectionを選択し、接続確認を行います。
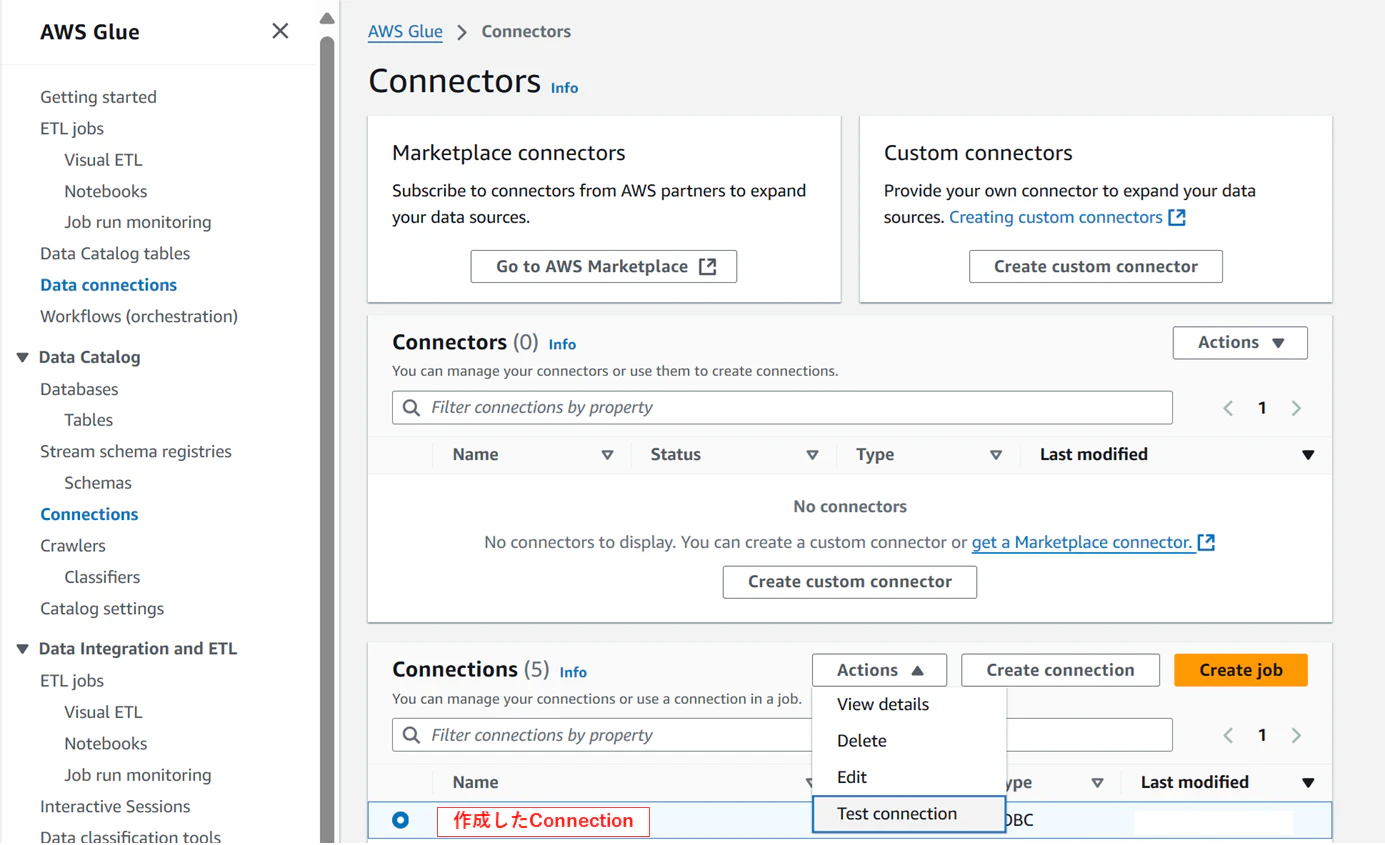
GlueJobロールを指定して、接続確認します。
(Connectionに設定されているJDBC URLに対して、テスト接続が行われます)
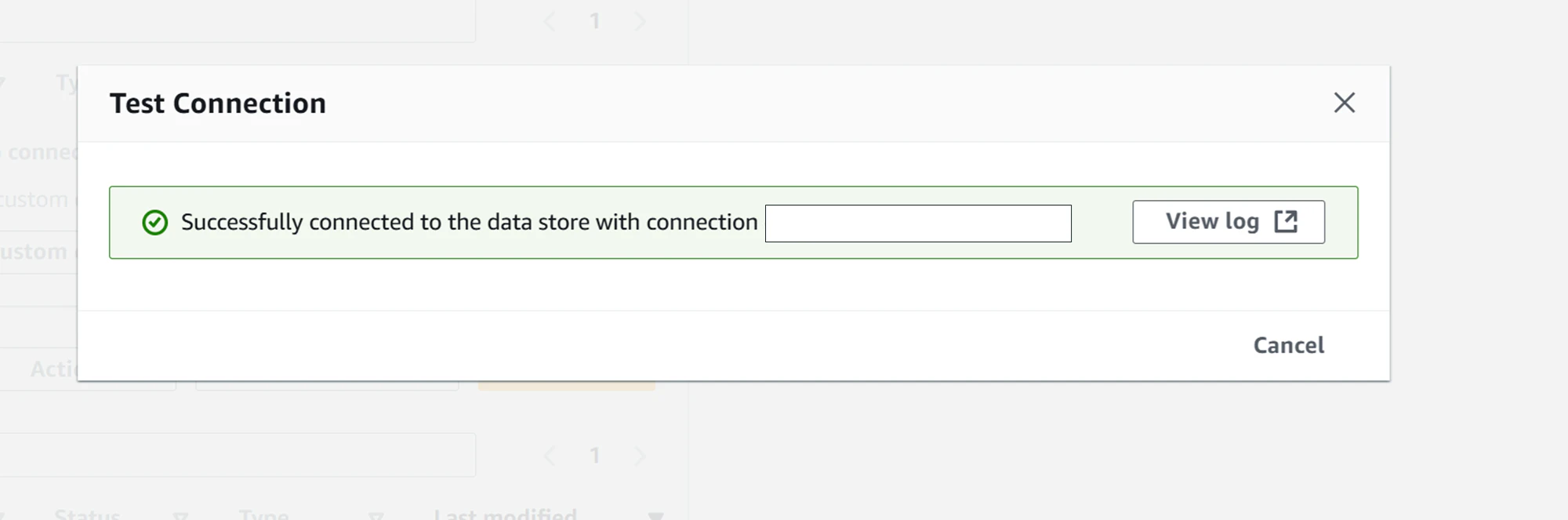
少し待つと、接続に成功した画面が確認できました!
GlueJobを実行してみる(次回記事)
Glue Jobで使うスクリプトの内容や一時保管用S3の場所を設定する方法など、次回の記事で詳細整理します。
最後に
GlueとRedshift Serverlessを接続するための具体的な手順を整理しました。
今回はRedshift認証情報をConnection設定に直書きしていますが、
Secrets Managerを使ったりなど、よりセキュアな接続方法にカスタマイズ可能なので、また整理したいと思います。
次回記事では、作成した接続を使って実際にGlue Jobを実行し、
Redshift Serverlessのテーブルにデータインサートを行う方法を整理しています。
参考URL
この記事で参考にしたURLです。
-
AWS記事:Redshift connections - Configuring IAM roles
https://docs.aws.amazon.com/glue/latest/dg/aws-glue-programming-etl-connect-redshift-home.html#aws-glue-programming-etl-redshift-config-iam ↩ -
Amazon Redshift サーバーレスを使用する場合の考慮事項
https://docs.aws.amazon.com/ja_jp/redshift/latest/mgmt/serverless-usage-considerations.html ↩ -
AWS記事:Redshift connections - Set up Amazon VPC
https://docs.aws.amazon.com/glue/latest/dg/aws-glue-programming-etl-connect-redshift-home.html#aws-glue-programming-etl-redshift-config-vpc ↩ ↩2 -
AWS記事:Redshift connections
https://docs.aws.amazon.com/glue/latest/dg/aws-glue-programming-etl-connect-redshift-home.html#aws-glue-programming-etl-redshift-using ↩ -
Apache Spark の Amazon Redshift 統合
https://docs.aws.amazon.com/redshift/latest/mgmt/spark-redshift-connector.html#spark-redshift-connector-considerations ↩ -
AWS記事:AWS Glue のための開発用ネットワークの設定
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/start-development-endpoint.html ↩