はじめに
本記事は ↓ の続きです。
前回記事では、GlueとRedshift Serverlessが接続できる状況まで確認しました。
ここから、Glue JobでRedshift Serverlessのテーブルにデータ書き込みする流れを整理していきます。
(前回記事で紹介したリソースは構築済み前提で進めていきます)
この記事でわかること
構成図
Glue JobでRedshift Serverlessにデータをインサートするための構成を図にしています。
(前回記事から 生データ保管用S3 , GlueJobスクリプト格納用S3 を追加)

準備
今回の検証のために、以下準備を行います。
生データの準備
- オープンデータを使う
今回、東京都オープンデータカタログサイト のオープンデータを利用してみます。
「都民のくらしむき」東京都生計分析調査報告(月報) 令和6年7月」ページから、
「1世帯当たり1か月間の品目別生計支出-全世帯-」CSVファイルをダウンロードします。
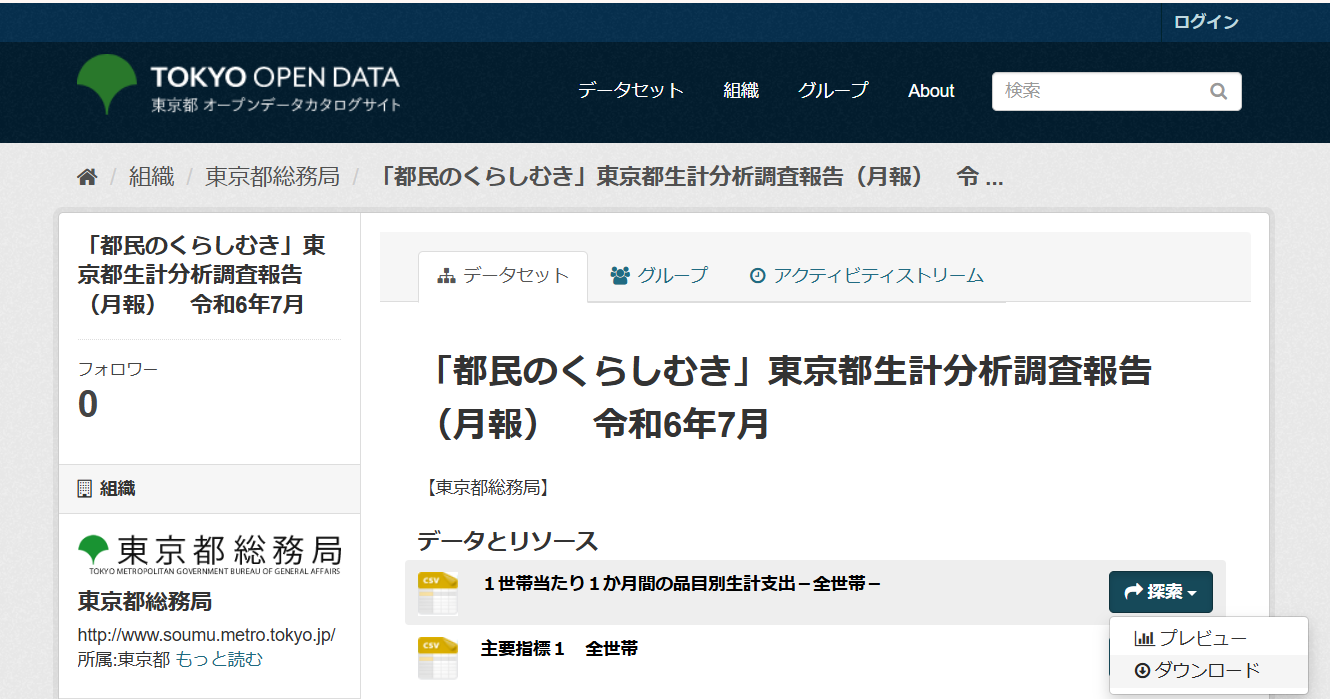
出典:「都民のくらしむき」東京都生計分析調査報告(月報) 令和6年7月、東京都・東京都総務局、クリエイティブ・コモンズ・ライセンス 表示4.0国際
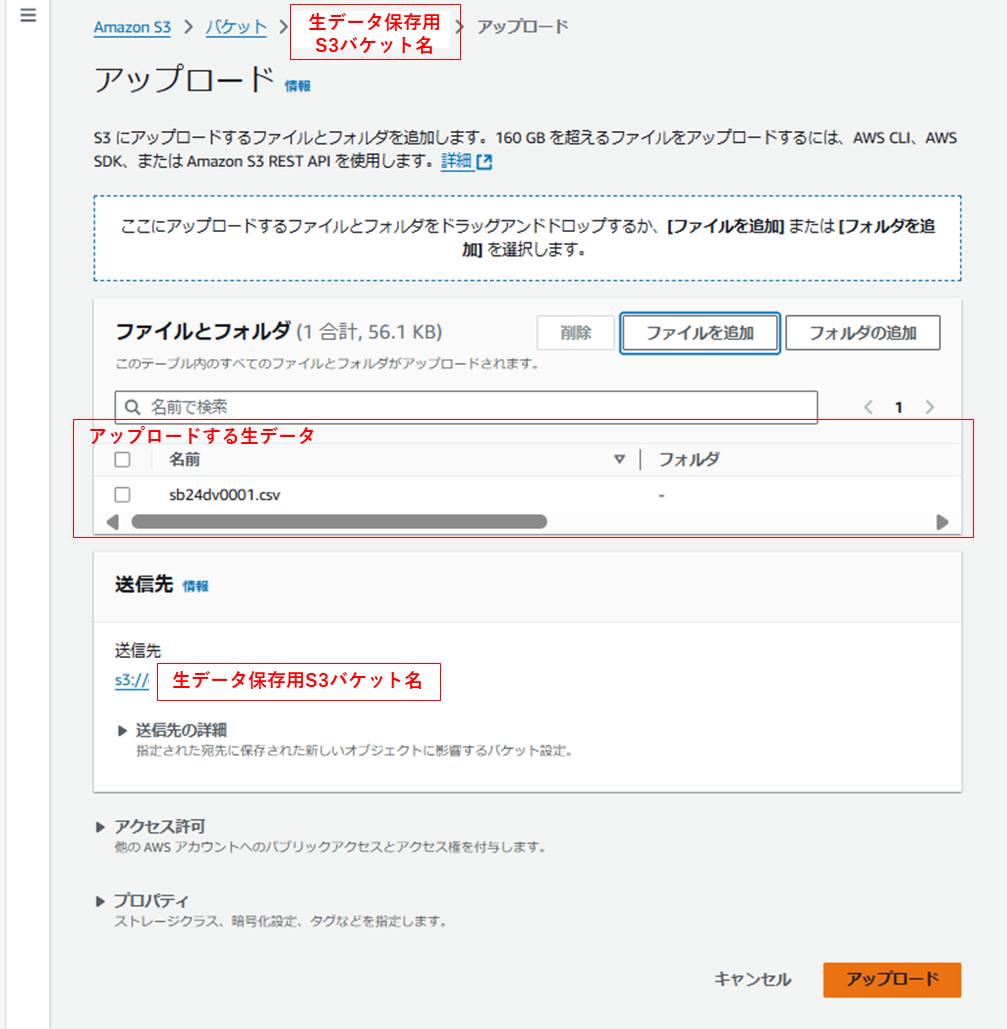
生データをアップロード
- 生データ保管用のS3に格納する
ダウンロードしたCSVファイルを、生データ保管用S3にアップロードしておきます。
(GlueJobは実行時にこのS3にアクセスし、生データを読み込みます)
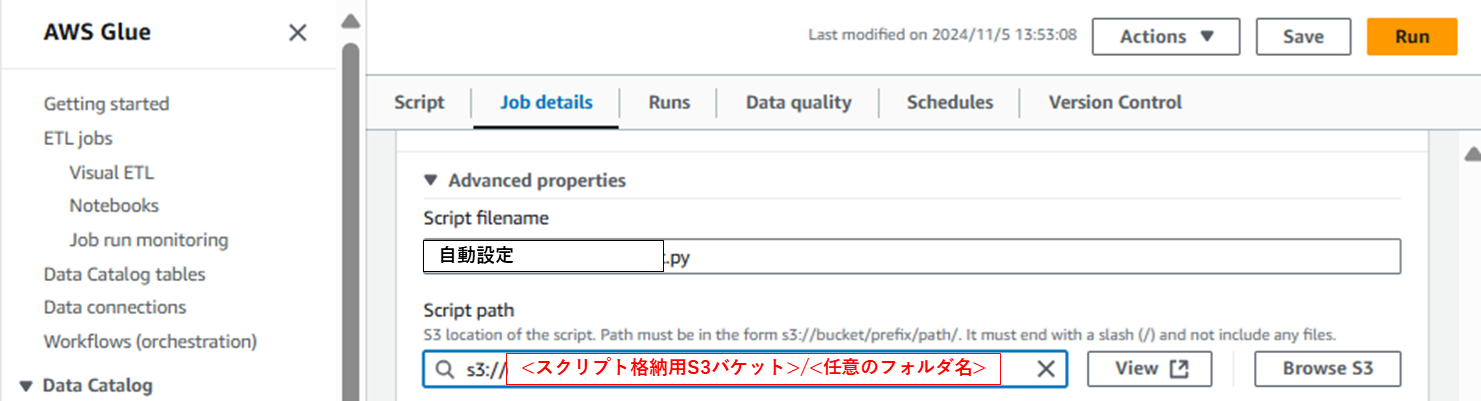
設定の更新
(前回記事からGlue関連で更新が必要な項目をまとめています)
- GlueJobの設定に、スクリプト格納用S3バケットを指定する
今回のインサート処理で使うGlueJobスクリプトを格納するS3パスを指定します1。
- GlueJobのIAMを更新する
前回記事で作成したGlueJob用IAMポリシーに、生データ保管用S3, スクリプト格納用S3へのアクセス許可を追加します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"glue:GetConnection",
"glue:StartJobRun",
"glue:GetJobRun",
"glue:GetJobRuns",
"glue:BatchStopJobRun"
],
"Resource": [
"arn:aws:glue:*:*:*"
]
},
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::<データ移動時の一時保管用S3バケット名>",
"arn:aws:s3:::<データ移動時の一時保管用S3バケット名>/*",
"arn:aws:s3:::<生データ保管用S3バケット名>",
"arn:aws:s3:::<生データ保管用S3バケット名>/*",
"arn:aws:s3:::<スクリプト格納用S3バケット名>",
"arn:aws:s3:::<スクリプト格納用S3バケット名>/*"
]
},
{
"Effect": "Allow",
"Action": [
"ec2:DescribeVpcAttribute",
"ec2:DescribeVpcs",
"ec2:DescribeSubnets",
"ec2:DescribeSecurityGroups",
"ec2:DescribeNetworkInterfaces",
"ec2:DescribeVpcEndpoints",
"ec2:DescribeRouteTables",
"ec2:CreateNetworkInterface",
"ec2:DeleteNetworkInterface",
"ec2:CreateTags"
],
"Resource": [
"*"
]
},
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": "arn:aws:logs:*:*:*:*"
},
{
"Effect": "Allow",
"Action": [
"cloudwatch:PutMetricData",
"cloudwatch:GetMetricData",
"cloudwatch:GetMetricStatistics",
"cloudwatch:ListMetrics"
],
"Resource": "*"
}
]
}
Amazon Qで聞いてみる
せっかくなので、AWSの生成AIサービス「Amazon Q data integration in AWS Glue」2で、質問してみます。
(聞きたいこと)
「GlueJobでS3にある生データを加工後、GlueデータカタログのConnectionを使ってRedshiftServerlessに接続し、加工データを挿入するスクリプトを教えてください」
(2024年11月現在 日本語未対応のため英語に翻訳して・・)
Please provide a script for a Glue Job that processes raw data from S3, connects to Redshift Serverless using a Glue Data Catalog Connection, and inserts the processed data into Redshift Serverless.
スクリプトの返答が返ってきました。
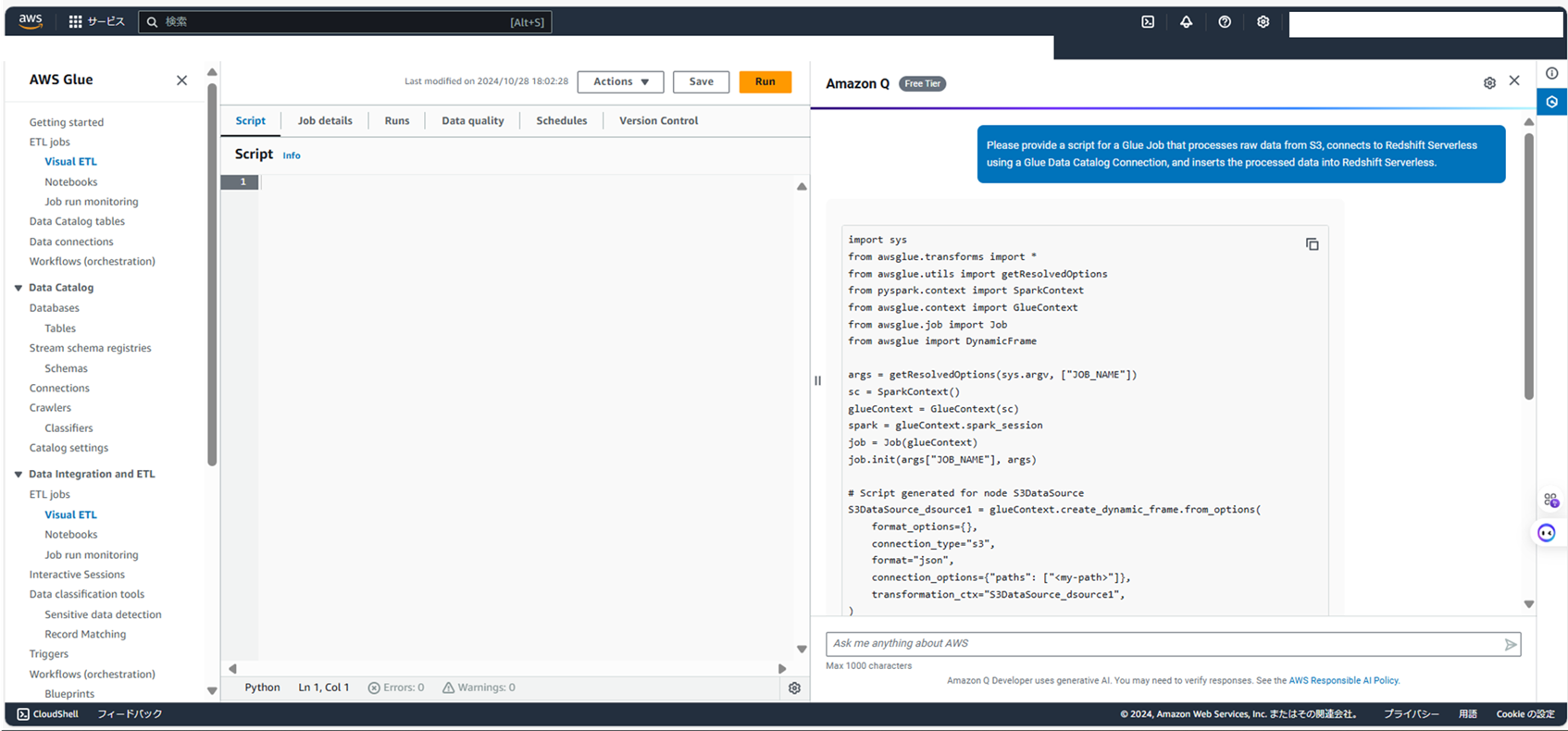
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from awsglue import DynamicFrame
args = getResolvedOptions(sys.argv, ["JOB_NAME"])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args["JOB_NAME"], args)
# Script generated for node S3DataSource
S3DataSource_dsource1 = glueContext.create_dynamic_frame.from_options(
format_options={},
connection_type="s3",
format="json",
connection_options={"paths": ["<my-path>"]},
transformation_ctx="S3DataSource_dsource1",
)
# Script generated for node RedshiftDataSink
RedshiftDataSink_dsink1 = glueContext.write_dynamic_frame.from_options(
frame=S3DataSource_dsource1,
connection_type="redshift",
connection_options={
"redshiftTmpDir": "<my-s3-temp-dir>",
"useConnectionProperties": "true",
"aws_iam_role": "arn:aws:iam::111111:role/Admin",
"dbtable": "public.<my-table>",
"connectionName": "<my-connection>",
},
transformation_ctx="RedshiftDataSink_dsink1",
)
job.commit()
こちらをフォーマットにして、今回のスクリプトをつくってみます。
スクリプト内容
Glue JobでRedshift Serverlessのテーブルにデータ書き込みするスクリプトの流れは 以下です。
パラメータを読み込む
このスクリプトで使うパラメータをGlueJobから取得し、実行環境を初期化する記述を書きます
- 1行目は、GlueJobから取得するパラメータを定義3していて、 "JOB_NAME" は GlueJob名 です(このパラメータはGlueJobに別途設定していなくても取得可能なものです)
- 2行目以降で、Sparkの実行環境, GlueJob実行環境を初期化しています
args = getResolvedOptions(sys.argv, ["JOB_NAME"])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args["JOB_NAME"], args)
生データを読み込む
生データ保管用S3との接続設定を行います。
- format_optionsは、CSVファイルの中身に合わせて設定しています。
- formatは、 "csv" に変更します。
- connection_optionsの "paths" は、生データ格納先のパスを指定します。
S3DataSource_dsource1 = glueContext.create_dynamic_frame.from_options(
format_options={"quoteChar": '"', "withHeader": False, "separator": ",", "encoding": "SJIS"},
connection_type="s3",
format="csv",
connection_options={"paths": ["s3://<生データ保管用S3バケット名>/sb24dv0001.csv"]},
transformation_ctx="S3DataSource_dsource1",
)
生データを加工する
生データを、Redshift Serverlessのテーブル用データに加工する処理を記述します。
(生データの中身を見ると9月以降のフィールドが空なので、8月までのフィールドを選択してみます)
SelectFieldsTransform_transform1 = SelectFields.apply(
frame=S3DataSource_dsource1,
# 生データから8月までのフォールドのみ抜粋"
paths=[
"項目",
"階層",
"大分類",
"中分類",
"小分類",
"中間計",
"符号",
"項目名",
"1月(円)",
"2月(円)",
"3月(円)",
"4月(円)",
"5月(円)",
"6月(円)",
"7月(円)",
"8月(円)"
],
transformation_ctx="SelectFieldsTransform_transform1",
)
加工データを書き込む
加工したデータを、Redshift Serverlessのテーブルにインサートします。
DynamicFrameWriter クラスを利用します4。
ここで前回記事で作成した、一時保管用S3, GlueデータカタログConnectionを設定していきます。
- connection_options内の "redshiftTmpDir" は、一時保管用S3のパスを設定します
- "useConnectionProperties": "true" にすると、 GlueはConnectionの設定(認証情報等)を使って、RedshiftServerlessに接続します(接続にIAMロールは使わないので、テンプレートにあった "aws_iam_role" は不要です)
- "dbtable" で、データをインサートするRedshift Serverlessのテーブルを指定します(もし存在しなかったら、自動で新規作成されます)
- "connectionName" は、前回記事で作成したConnection名を指定します
RedshiftDataSink_dsink1 = glueContext.write_dynamic_frame.from_options(
frame=S3DataSource_dsource1,
connection_type="redshift",
connection_options={
"useConnectionProperties": "true",
"redshiftTmpDir": "s3://<データ移動時の一時保管用S3バケット名>/<任意のディレクトリ名>/",
"dbtable": "<任意のスキーマ名>.<任意のテーブル名>",
"connectionName": "<前回記事で作成したConnection名>",
},
transformation_ctx="RedshiftDataSink_dsink1",
)
job.commit()
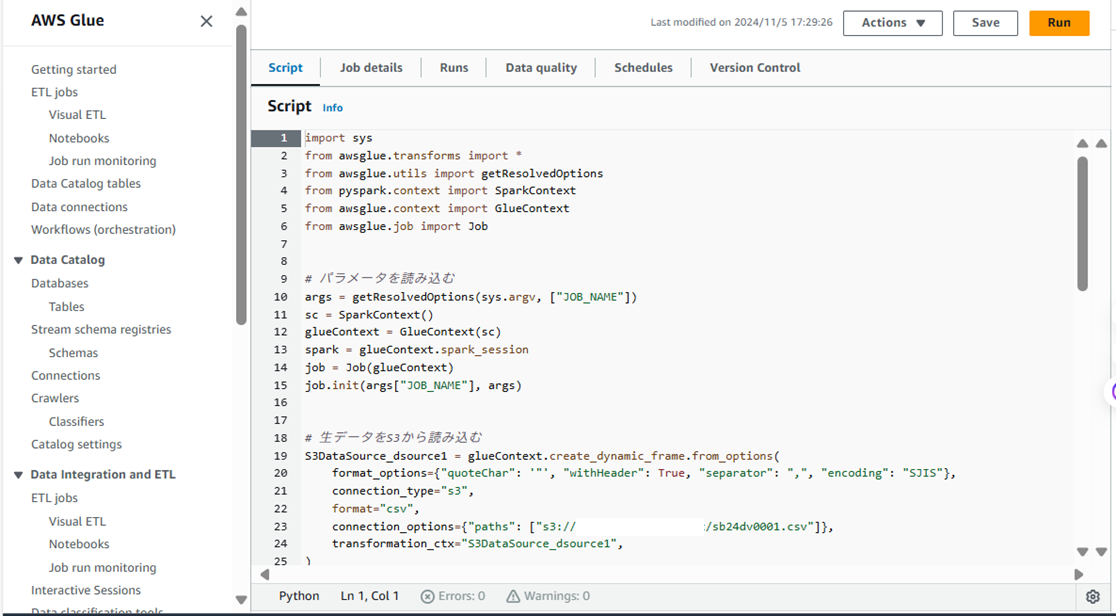
スクリプト全容
今回のスクリプト全体は以下内容です。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from awsglue import DynamicFrame
# パラメータを読み込む
args = getResolvedOptions(sys.argv, ["JOB_NAME"])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args["JOB_NAME"], args)
# 生データをS3から読み込む
S3DataSource_dsource1 = glueContext.create_dynamic_frame.from_options(
format_options={"quoteChar": '"', "withHeader": False, "separator": ",", "encoding": "SJIS"},
connection_type="s3",
format="csv",
connection_options={"paths": ["s3://<生データ保管用S3バケット名>/sb24dv0001.csv"]},
transformation_ctx="S3DataSource_dsource1",
)
# 生データを加工する
SelectFieldsTransform_transform1 = SelectFields.apply(
frame=S3DataSource_dsource1,
# 生データから、8月までのフォールドのみ選択"
paths=[
"項目",
"階層",
"大分類",
"中分類",
"小分類",
"中間計",
"符号",
"項目名",
"1月(円)",
"2月(円)",
"3月(円)",
"4月(円)",
"5月(円)",
"6月(円)",
"7月(円)",
"8月(円)"
],
transformation_ctx="SelectFieldsTransform_transform1",
)
# 加工データをRedshiftServerlessテーブルに書き込む
RedshiftDataSink_dsink1 = glueContext.write_dynamic_frame.from_options(
frame=S3DataSource_dsource1,
connection_type="redshift",
connection_options={
"useConnectionProperties": "true",
"redshiftTmpDir": "s3://<データ移動時の一時保管用S3バケット名>/<任意のディレクトリ名>/",
"dbtable": "<任意のスキーマ名>.<任意のテーブル名>",
"connectionName": "<前回記事で作成したConnection名>",
},
transformation_ctx="RedshiftDataSink_dsink1",
)
job.commit()
このスクリプトを、GlueJob画面の「Script」タブから貼り付けます。
実行~確認手順
Glue Jobを実行し、Redshift Serverlessのテーブルに書き込まれているかまで確認していきます。
- GlueJobの実行
- GlueJobのステータス確認
- RedshiftServerlessのテーブル確認(クエリ実行してみる)
GlueJobの実行
GlueJob画面の右上「Run」をクリックし、実行します
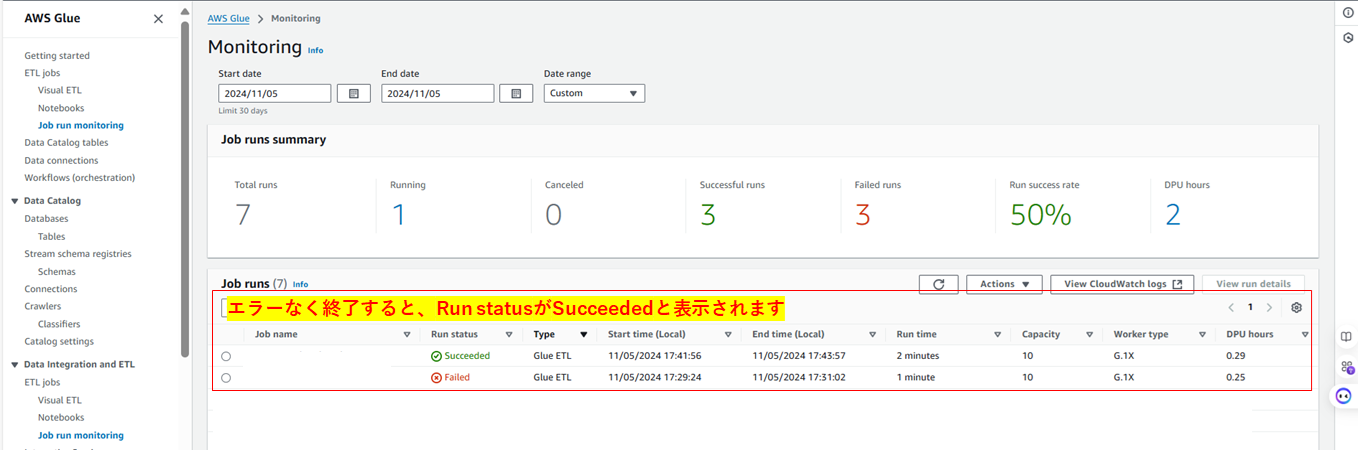
GlueJobのステータス確認
Glue画面サイドバーのJob run monitoringから、該当GlueJobのRun Statusを確認します
RedshiftServerlessのテーブル確認(クエリ実行してみる)
Redshift query editor v2で、selectクエリを実行してみると・・
8月までのフィールドを持つデータが取得できました!
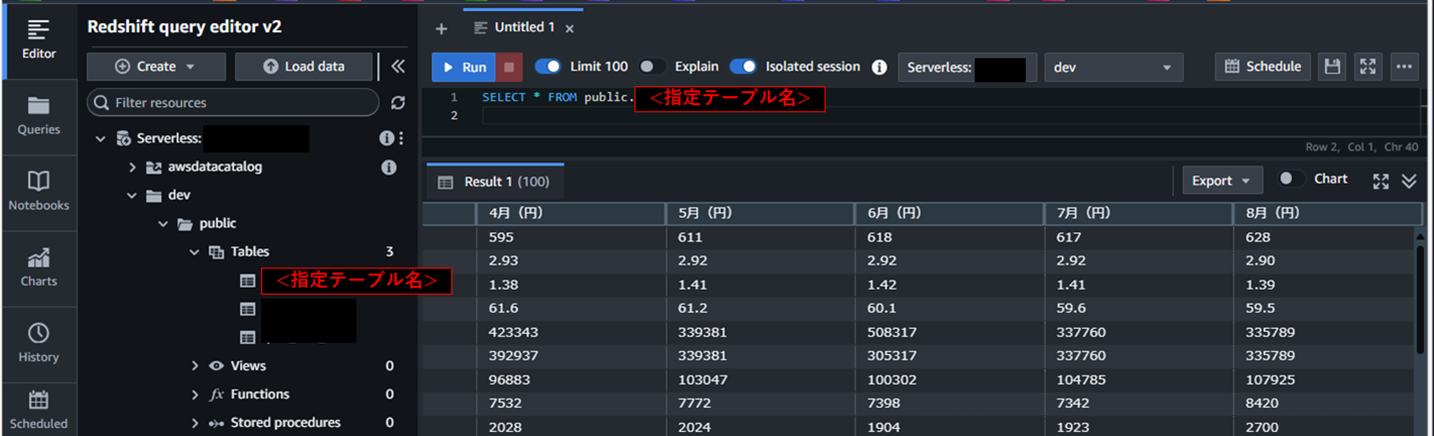
※このテーブルは、以下の著作物を改変して利用しています。
「都民のくらしむき」東京都生計分析調査報告(月報) 令和6年7月、東京都・東京都総務局、クリエイティブ・コモンズ・ライセンス 表示4.0国際
ちなみに、テーブルのスキーマを見ると、全てのカラム型がvarchar(65535)となっています。
テーブル書き込み時に指定したテーブルがないと、Sparkの型から自動的にRedshiftの型に変換されてテーブルが作成されるようです。
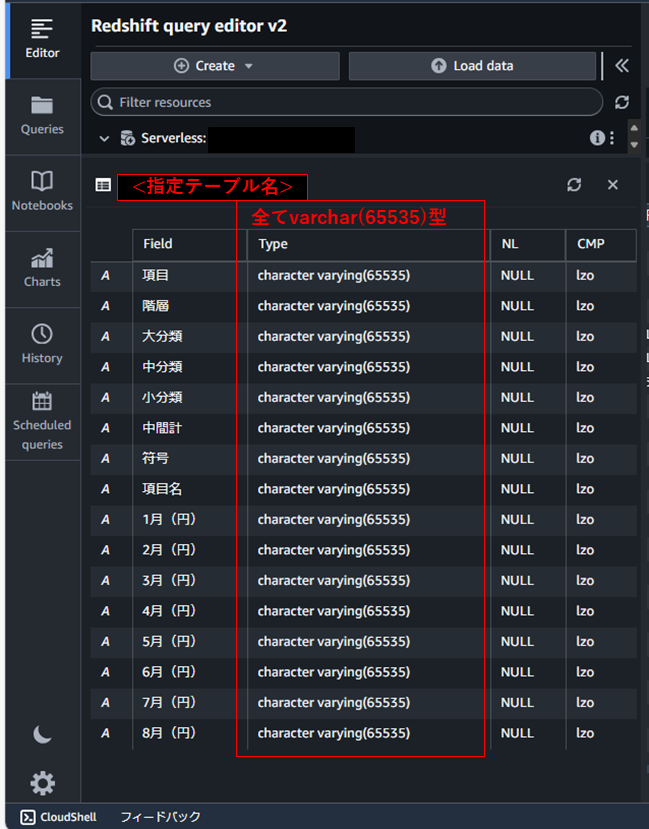
この場合、connection_optionsにpreactionsとpostactionsの記述を追加することで、指定の型を定義したテーブルにインサートすることができます。
以下の記事で整理しています。
最後に
今回は、Glue JobのSparkスクリプトで
Redshift Serverlessのテーブルにデータインサートするまでの手順を整理しました。
参考URL
この記事で参考にしたURLです。
-
AWS記事:ジョブスクリプトの編集またはアップロード
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/edit-nodes-script.html ↩ -
AWS記事:Amazon Q でのデータインテグレーション AWS Glue
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/q.html ↩ -
AWS記事:getResolvedOptions を使用して、パラメータにアクセスする
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/aws-glue-api-crawler-pyspark-extensions-get-resolved-options.html ↩ -
AWS記事:DynamicFrameWriter クラス
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/aws-glue-api-crawler-pyspark-extensions-dynamic-frame-writer.html ↩