初めに
本稿は、付け焼刃の知識でPowerBIをえっちらおっちら運用している筆者が、所属部内のPowerBIビギナー宛てに記したガイドを一般向けに書き直したものです。
本人も理解が甘いうえに、敢えて曖昧に記述した点があり正確性に欠けることをご了承ください。また、私の所属が半導体設計部署なので、そのニュアンスを少々含みます。
ちなみにPL-300の模試には落ちました
想定読者
- PowerBIのハンズオンを試したことがある
- 自分でちょこっとだけレポートを作ろうとしたことがある
- 列やテーブルの割り振りで悩んだことがあるとベター
- 「スタースキーマ」が何か知らない
これを読むと
- データモデリングの概要と重要性がわかる
- 次のお勉強のとっかかりができる
データモデリングとは
人が見やすいと感じるデータ形式と、機械が高速に処理しやすいデータ形式は両立しない。
PowerBIで図表を配置したり、Excelで資料用の集計表を作成したりする作業は、いわば前者の(人用の)データ形式を整える作業である。これに対して後者の(機械用の)データ形式を整える諸々の作業を包括してデータモデリングと呼ぶ。
ここではPowerBIにおけるデータモデリングの基礎について述べる。
旧来のデータモデリング
例えば従来Excelで行っているような以下の作業も大雑把にはデータモデリングの一部であると言える。
- 生データの整形
- 元データを複数のテーブルへ分解
- 各テーブルに割り振る列の決定
- テーブル間のデータの紐づけ(紐づけ用のID列の作成, VlookUp関数の設定)
- etc...
旧来のExcelを用いたデータまとめの現場ではこのような作業は担当者の肌感や所属部署の慣例に倣って行われてきた。
Power BIのデータモデリング
一方で、PowerBIに読み込ませるデータでは明確な「こう設計すべき」体系が存在する。それはスタースキーマと呼ばれる。
適切に設計されたスタースキーマは以下のようなメリットをもたらす。
- パフォーマンスの向上: レポートの動作速度が向上
- メンテナンス性の向上: データの追加や変更が容易になる
- スケーラビリティ: データ量の増加に対応できる
- 理解しやすさ: データの外観が明確になる
データモデリングはBIレポートの基礎を作る工程であり、レポートの作りやすさ・使いやすさの殆どを左右すると言って過言ではない。
BIを習熟するにつれて、作業全体の大半をこの作業が占めるようになる。逆に言えば、今のBIレポートの作業が効率的ではないと感じているなら、データモデリングについて学ぶことで大幅な改善が見込める。
スタースキーマとは
スタースキーマは、分析対象となるデータを格納したテーブルを中心とし、その周りに分析の軸となる値(いわゆるマスタ)を格納したテーブルを紐づける構造である。星のように見えることからこう呼ばれる。
イメージ図
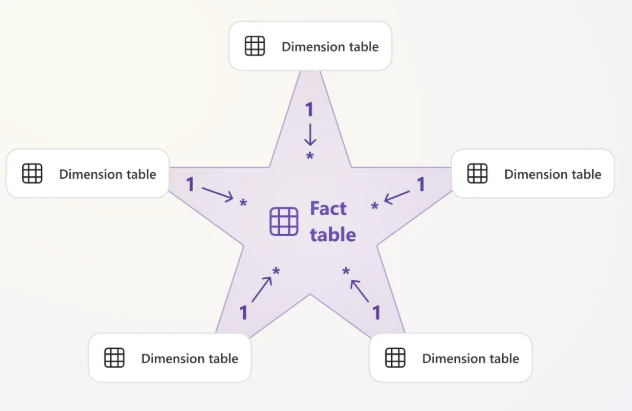
中心の分析対象のデータを格納したテーブルのことをファクトテーブル、その周りの分析の軸となる値を格納したテーブルをディメンションテーブルと呼ぶ。
ファクトテーブルとディメンションテーブル
ファクトテーブル
ファクトテーブルは、主な分析対象のデータを記録するテーブルである。
例:注文ファクトテーブル
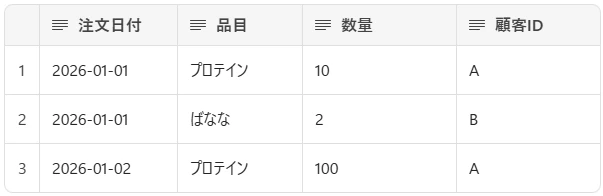
特徴
- 数値や区分のデータの列を含む: 売上金額、数量、利益、電気特性値、合否など
- 外部キー(id)列を含む: 後述のディメンションテーブルを参照するための紐づけ用の列を持つ
- 比較的行数が多い: 適切に設計されれば数千万行オーダーでも扱える
ディメンションテーブル
ディメンションテーブルは、ファクトを「誰が」 「何を」 「いつ」 「どこで」という観点で説明する属性情報を持つテーブル。
例:顧客ディメンションテーブル
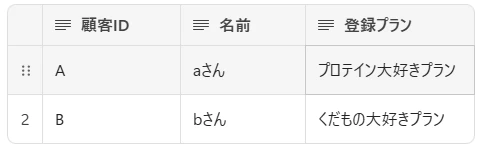
特徴
- 説明的な属性を含む: 名前、カテゴリ、地域、ウエハ仕様など
- 主キーを持つ: ファクトテーブルから参照される
- 行数が比較的少ない: 数行~数千行オーダー。いわゆるマスターデータ を格納する
リレーションシップの設定
リレーションシップとは
一般に「データの紐づけ」と呼ばれる作業は正式にはリレーションシップと呼ばれる。テーブル間の関係を定義し、データを正しく集計・フィルタリングするための設定である。
PowerBIにおいてリレーションシップを作成することは即ち次の3つの要素を定義することである。
- テーブル間の紐づけ列の設定
- カーディナリティの設定
- リレーションシップの方向の設定
カーディナリティの種類
紐づけ元のテーブルの1行、あるいはn行に対し、紐づけ先のテーブルに何行の値が存在しうるかを示す値のことをカーディナリティ(多重度)という。
カーディナリティには次の3種類がある。
1. 一対多(1:*)
- 最も一般的: ディメンションテーブルの1行に対応する行がファクトテーブルにn行存在する
2. 多対多(:)
- 使用には注意が必要: パフォーマンスの悪化を招きやすい
- レポート側での適切な制御: レポート側で適切なフィルタを設定しないと誤集計を招く可能性がある
- 基本的に使いたくないが、実務ではやむをえず用いる場面もある
余談
筆者はBI素人時代にメモリ8GBの個人PCで多対多を濫用した結果、メモリ使用率を99%までぶち上げてシステムダウンさせたことがある
端末もアチアチで火傷しました
3. 一対一(1:1)
- 基本的に使用しない: 紐づけの計算コストがかかるため、基本的に1:1の関係は用いず、一つのテーブルに統合すべき
ほぼ原則的にカーディナリティは1対多を用い、例外的に多対多を用いる。一対一が出てきたときは一つのテーブルに統合すること。
フィルター方向
- 単一方向: ディメンションからファクトへフィルター設定が伝播する
- 双方向: ディメンションからファクトへ、ファクトからディメンションへフィルターが伝播する
パフォーマンスの観点から、基本的にディメンションテーブル→ファクトテーブルの単一方向を用いる。ただし、データ側からディメンションを参照したい場合は双方向やDAX: CROSSFIELTER関数を用いる。
リレーションシップ設定のベストプラクティス
- 主キーと外部キーを明確にする: ディメンションとファクトで対応する列名を全く同じに揃えておくと設定をミスしにくい
- 単一方向フィルターを使用: パフォーマンス確保のため。必要が生じた際のみ双方向フィルターを用いる
- 多対多は慎重に使用: 本当に必要な場合のみ。使うなら誤集計への対策が必須
設計例:半導体チップ実験データの分析モデル
シナリオ
半導体チップ製造工場で、製造されたチップの電気特性の検査結果を分析し、製造パラメータとの関係性を把握したい。
このシナリオでのスタースキーマの設計例を考える。
必要なテーブル
ファクトテーブル
- 実験データテーブル: 各チップの測定項目ごとの実験結果を記録
ディメンションテーブル
- ウエハ仕様テーブル: ウエハごとの製造パラメータ
- 測定条件テーブル: 測定項目毎の電圧・電流の設定値、及び良品/不良品の規格値
テーブル詳細
ファクトテーブル:実験データ
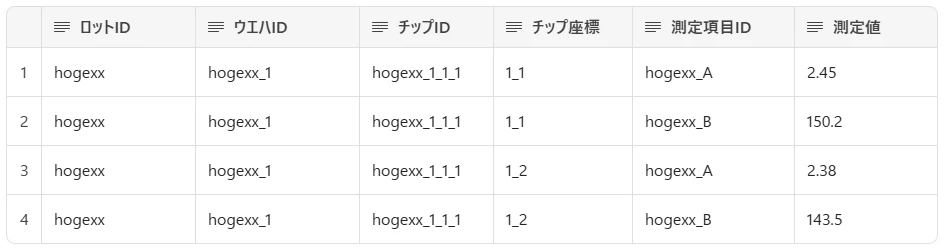
- 一行が1つの測定値を表す
- 生データでは測定項目が列持ちになっているので、行持ちに変換する必要がある
- チップID列は ロット番号_ウエハ番号_チップ座標の組み合わせ
ディメンションテーブル:ウエハ仕様

- 1行が1ウエハを表す
ディメンションテーブル:測定条件
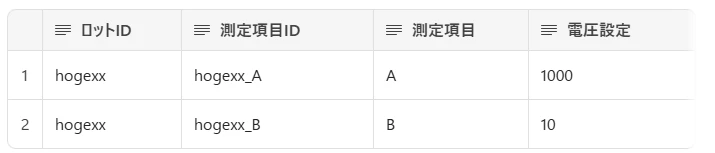
- 1行が1ロットの1測定項目を表す
モデル図
下図に上記の3テーブルのリレーションシップを簡単に示す。

- 矢印の上の「1」, 「*」がカーディナリティを示す
- 矢印の向きがそのままフィルタの向きを示す
- 矢印中のテキストはリレーションシップの列を示す
- 通常、リレーションシップ元と先で列名を揃えるので図中の列名の表記も一つになっている
分析の例
このモデルを使用すると、以下のような分析が可能になる。
- 製造パラメータと特性値の関係分析
- ロット・製品カテゴリ別の歩留集計
まとめ
Power BIでの効果的なデータモデリングとは、スタースキーマの厳格な実践である。
良いデータモデルは、高速で正確な分析の基盤となる。最初に時間をかけてモデルを適切に設計することで、長期的な効率性と拡張性が得られる。
次のステップ
ここまで読んだBI初心者の方はおそらく「私のデータ、こんな綺麗な形していないけど??」と思うでしょう。
そのようなデータを綺麗に整形するためのツールがPowerQueryなので、引き続きPowerQueryのお勉強へ進むべき...ですが、そんな時間は取れないという人はせめてExcelで綺麗なデータを用意するところから試してみてはいかがでしょうか。
(そして手間に絶望してPowerQueryのお勉強を始めたくなるまでが既定路線...)