前回の続き。今回は実際に予測モデルの構築、kaggleへのサブミットまでを行う。
動作環境
・Kaggle kernel上
準備
ライブラリのインポート
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
import plotly.offline as py
import plotly.graph_objs as go
import cufflinks as cf
py.init_notebook_mode(connected=True)
# デフォルトでPlotlyがオンラインモードになっているので、オフラインモードへと変更
# cf.go_offline()# 恒久的にデフォルトをオフラインモードに
データセットの読み込み
train=pd.read_csv("../input/train.csv")
test=pd.read_csv("../input/test.csv")
data=[train,test]
前処理
どう前処理するか
・欠損値を何らかの形で埋める
・不必要と思しきデータを排除する
・連続した数字データをカテゴライズ
(例えば、0~99までの数字を含むデータをそのまま扱うと100クラスに区別されたことになり、大雑把に多い、少ないを把握できない)
・文字データを数字におきかえる(分類器は数字しか受け付けない)
分類器につっこむ前に上記の処理が必要...
具体的には....
欠損値を数えた結果、欠損しているのはAge, Cabin, Embarked。
●Cabinは891人中687人のデータが欠損しているので、あんまり使えなさそう
●Embarkedが欠損しているのは高々2名分なので、これはそれほど影響はなさそう。
●Name・・・生死には関係ないと思われる。ただし、Mr.やMrs.などの敬称は人物の属性を表すので関係あるかも。
●PassengerId・・・通し番号なので、関係が薄いと思われる。(断言はできないが)今回は排除。
●ticket・・・分類器には数字化したデータしか用いることができないことを考えると、規則性がわからない文字列に頼るのはあまり得策ではなさそう。
使用する分類器
今回は、ランダムフォレストによって、予測モデルを構築する。
そのため、ゴールとしてはrandom forest classifierに突っ込むことだが、分類器は基本的には数字のデータにしておかなければいけない。
今回のデータセットの意味を考えると、氏名が生死に影響するとは考えにくい。
しかし、"Name"にはすべて、"Mr"や"Mrs"といった敬称が含まれており、これはその人の属性を表すものとして、結果に影響を与えそうである。(性別や年齢のセグメントで敬称が変わるため)
そこで、"Name"から全員分の敬称を抜き出すことを考える。敬称は多岐に渡るようであるから、いくつかのパターンに分類する。
名前は敬称だけ抜き取る
import re
def get_title(name):
title_search = re.search(' ([A-Za-z]+)\.', name)
if title_search:
return title_search.group(1)
return ""
# "Title"という列を作り、その中に全員分の敬称を収録する
for df in [train,test]:
df['Title'] = df['Name'].apply(get_title)
train.info() #確認

train.Title

# trainに対して
train.Title.value_counts()

# testに対して
test.Title.value_counts()

# Mr, Miss, Others(その他)におきかえ
for df in data:
df['Title'] = df['Title'].replace(['Lady', 'Countess','Capt', 'Col','Don', 'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Dona'], 'Others')
df['Title'] = df['Title'].replace(["Mlle","Ms"],"Miss")
df['Title'] = df['Title'].replace("Mme","Mrs")
train.Title.value_counts()
# 改めて、どの敬称がいくつずつ含まれているのかを調べる

欠損値を埋める
train.isnull().sum()
# 改めてtrain、testそれぞれについて各列における欠損値の個数を確認

test.isnull().sum()

欠損しているのは
●trainについて・・・Embarked、Age、Cabinの3種類
●testについて・・・Fare、Age、Cabinの3種類
まずはtrainのembarkedから埋めていく。
欠けているのは高々二人分なので、一番乗ってきた人が多い港で補完する。
train.Embarked.value_counts()
# train.Embarkedの値とその個数を一覧にして表示する

train.Embarked=train.Embarked.fillna("S")
# "S"が最も多かったので、欠損値に"S"を代入
train.Embarked.value_counts() #確認する

Ageを補完する。(train,test両方)
一番荒っぽいが手っ取り早い方法は、 全ての年齢の欠損値を「年齢のデータが残っている乗客の平均年齢」で埋めてしまうことである。 しかし、これでは若干雑すぎるので「敬称ごとの平均で埋める」という方法を採用する。 敬称の区別は年齢の情報を含んだものであると考えられるため、有効だと思われる。
敬称別での年齢の平均をとって、欠損値を埋めよう。 for文を用いることで、train、test両方に対して一気に処理をしてしまおう。
for df in data:
for title in train.Title.unique():
df.loc[(df.Age.isnull())&(df.Title==title),"Age"] = df.loc[df.Title==title,'Age'].mean()
# unique()は重複しない値をリストにして返すpandasの関数
# 参考
df.loc[df.Title=='Mr','Age'].mean()

# 参考unique関数
train.Title.unique()

testのFareが1箇所欠けているので、これを埋める
高々1箇所なので、testの他のFare列の中央値を入れてしまえば十分。
# testのFareを埋める
test.Fare=test.Fare.fillna(test.Fare.median())
残るはCabinの情報だが・・・
Cabinは欠損値の方が多いため、今回はCabinの情報は使えないものと判断し、あとで丸ごと削除することとする。
これでCabin以外の欠損値はすべて補完できたはずである。
念のため確認を行う。
train.isnull().sum()

test.isnull().sum()

データのカテゴリ化
バラバラの値をとるデータをカテゴリ化する。
運賃の額(Fare)と、年齢(Age)のデータはそれぞれバラバラの値をとっているが、分類器にデータを投入することを考えると、これらのデータをカテゴリ化しておく必要がある。
分類器は数字のみ受け付けるため、カテゴリ名には数字を割り当てることとするが、分類器はfloat型(浮動小数)には対応しないため、必ずint型に整形しておく必要があることに注意。
for df in data:#train,testともに適用
# "Age"を5クラスにわけ、"Age_band"列を新たに作り、クラスの値を代入
df.loc[ df['Age'] <= 22, 'Age_band'] = 0
df.loc[(df['Age'] > 22) & (df['Age'] <= 30), 'Age_band'] = 1
df.loc[(df['Age'] > 30) & (df['Age'] <= 37), 'Age_band'] = 2
df.loc[(df['Age'] > 37) & (df['Age'] <= 59), 'Age_band'] = 3
df.loc[ df['Age'] > 59, 'Age_band'] = 4
df.Age_band = df.Age_band.astype(int)
'''
for df in data:
# "Fare"を4クラスにわけ、"Fare_band"列を新たに作り、クラスの値を代入
df.loc[ df['Fare'] <= 8, 'Fare_band'] = 0.
df.loc[(df['Fare'] > 8) & (df['Fare'] <= 15), 'Fare_band'] = 1
df.loc[(df['Fare'] > 15) & (df['Fare'] <= 31), 'Fare_band'] = 2
df.loc[ df['Fare'] > 31, 'Fare_band'] = 3
df.Fare_band = df.Fare_band.astype(int)
'''
# 上の方法でもよいがここではqcutを用いた手法を用いる
for df in data:
df['Fare_band']=pd.qcut(df.Fare,4,labels=range(4))
少し寄り道
新しい列Title,Age_band,Fare_bandを作ったことで
新たな切り口でデータを視覚化することが可能になった。
ここで、Title、Age_band、Fare_bandを切り口としていくつかグラフを作成する。
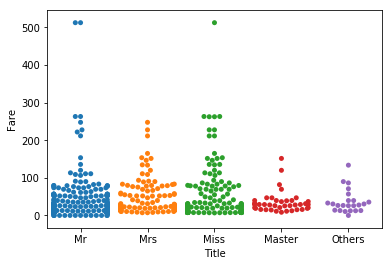
敬称(Title)と支払った運賃(Fare)の関係を調べて視覚化してみよう。
sns.swarmplot("Title","Fare",data=train)
# 敬称(Title)と支払った運賃(Fare)の関係
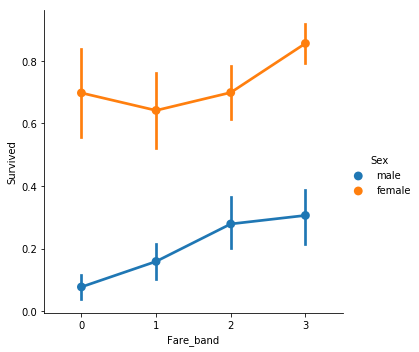
運賃のクラス(Fare_band)と性別(Sex)で生存率がどう変わるかを調べよう。
sns.factorplot("Fare_band","Survived",data=train,hue="Sex")
# 運賃のクラス(Fare_band)・性別(Sex)と生存率の関係
不要と思しきデータの削除
・PassengerId・・・形式が扱いにくい(クラス分類しにくい)上に、あまり生死と関係がなさそう
・Name・・・敬称を集めたTitle列を作ったので用済み
・Ticket・・・規則性が見出せず扱いに困る
・Cabin・・・欠損値が多すぎるので不採用
・Age・・・Age_bandを作ったので用済み
・Fare・・・Fare_bandを作ったので用済み
drop_columns = ['PassengerId', 'Name', 'Ticket', 'Cabin','Age','Fare']
# 上の6つのcolumn名をリストに。
train.info()

train = train.drop(drop_columns, axis = 1)
test = test.drop(drop_columns, axis = 1)
'''
for df in data:
df=df.drop(drop_columns,axis=1)
'''
データをすべて数字になおす
いま文字列の形で記述されているのは
・Sex列
・Title列
・Embarked列
である。いずれもカテゴリであるので、ラベルとして数字を割り当ててあげればよい。
(例) Mr:0, Miss:1, Mrs:2 ・・・など
data=[train,test]#for文でdropした場合には不要
for df in data:
# 性別を数字でおきかえ
df.loc[df['Sex']=="female", "Sex"]=0
df.loc[df['Sex']=='male','Sex']=1
# 敬称を数字で置き換え
df.loc[df['Title']=='Mr', 'Title']=0
df.loc[df['Title']=='Miss', 'Title']=1
df.loc[df['Title']=='Mrs', 'Title']=2
df.loc[df['Title']=='Master', 'Title']=3
df.loc[df['Title']=='Others', 'Title']=4
# 乗船した港3種類を数字でおきかえ
df.loc[df['Embarked']=='S', 'Embarked']=0
df.loc[df['Embarked']=='C', 'Embarked']=1
df.loc[df['Embarked']=='Q', 'Embarked']=2
train #データの確認
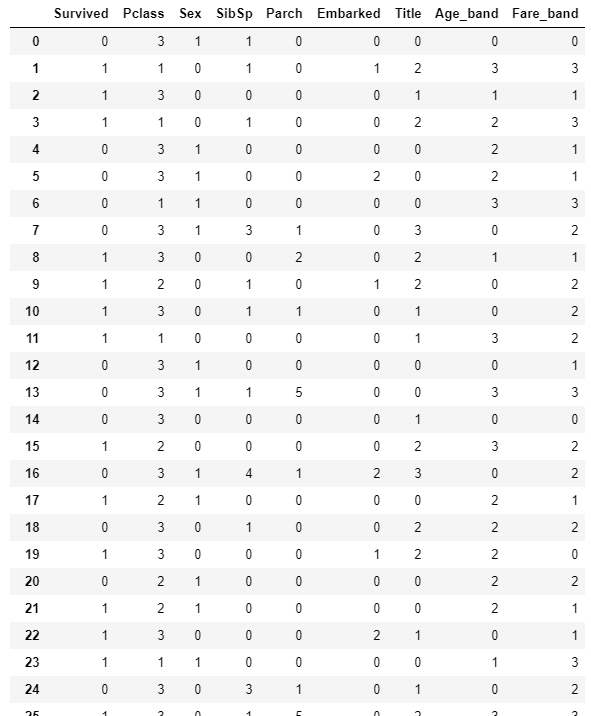
データを分類器につっこむ
from sklearn.model_selection import train_test_split
train.head()
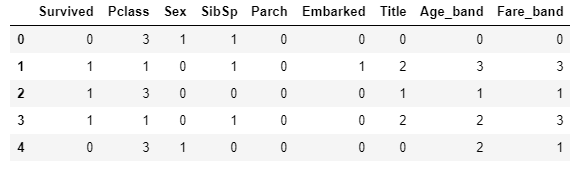
test.head()
testのデータには答え("Survived")がついておらず、これを用いて学習器の良し悪しを確かめる術がないので、
trainの一部のデータを分類器の検証用に用いることとする。
train→tr_train、tr_test に分割
(tr_trainデータ数):(tr_testのデータ数)=7:3
となるように指定する。
tr_train,tr_test=train_test_split(train, test_size=0.3)
# tr_train,tr_testに振り分けられるデータはランダムに決まる
print(tr_train.info())
print(tr_test.info())

tr_train_Xにはtr_trainの"Survived"列【以外】のデータを、
tr_train_Yにはtr_trainの"Survived"列のみを、
tr_test_Xにはtr_testの"Survived"列【以外】のデータを、
tr_test_Yにはtr_testの"Survived"列のみを納める。
tr_train_X = tr_train[train.columns[1:]]
tr_train_Y = tr_train[train.columns[0]]
tr_test_X = tr_test[train.columns[1:]]
tr_test_Y = tr_test[train.columns[0]]
決定木(DecisionTreeClassifier)
決定木のモデルを設定。
from sklearn.tree import DecisionTreeClassifier
model=DecisionTreeClassifier()
このモデルにtr_train_Xのデータを学習させ、tr_train_Yのデータを分類し判別率を算出
model.fit(tr_train_X,tr_train_Y)
predict= model.predict(tr_test_X)
判別率をsklearn.metricsを用いて見てみる
from sklearn import metrics
print('判別率:',metrics.accuracy_score(predict, tr_test_Y))

ランダムフォレスト(RandomForestClassifier)
ランダムフォレストのモデルを設定。とりあえず、n_estimatorは100としておく。
from sklearn.ensemble import RandomForestClassifier
model=RandomForestClassifier(n_estimators=100)
このモデルにtr_train_Xのデータを学習させ、tr_train_Yのデータを分類し判別率を算出
model.fit(tr_train_X,tr_train_Y)
predict= model.predict(tr_test_X)
判別率をsklearn.metricsで確認
from sklearn import metrics
print('判別率:',metrics.accuracy_score(predict, tr_test_Y))

K-分割交差検証
from sklearn.model_selection import KFold, cross_val_score, cross_val_predict
kf=KFold(n_splits=5, random_state=30, shuffle=True)
x=train[train.columns[1:]]
y=train["Survived"]
cv_result = cross_val_score(model, x, y, cv = kf)
print(cv_result)
print("平均精度:{}".format(cv_result.mean()))

グリッドサーチ
ハイパーパラメータチューニングの最も基本的な手法
from sklearn.model_selection import GridSearchCV
param={'n_estimators':range(100,1000,100),"max_depth":range(1, 10, 1)}#100から1000の100区切り
GS_rf=GridSearchCV(estimator=RandomForestClassifier(random_state=0),param_grid=param,verbose=True,cv=5)
GS_rf.fit(x,y)
print(GS_rf.best_score_)
print(GS_rf.best_estimator_)
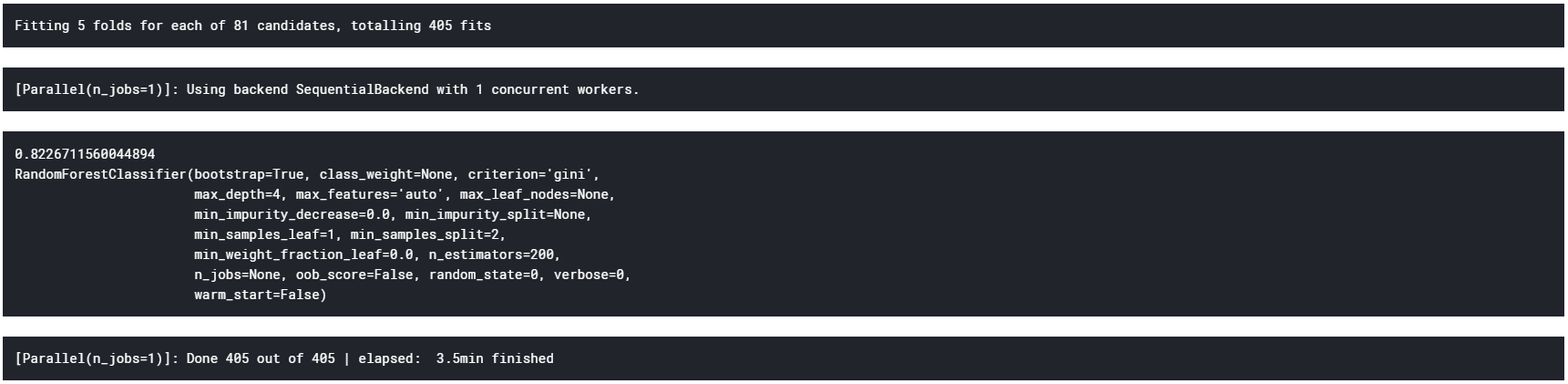
ランダムフォレストのパラメタチューニングの結果、試した条件の中では、
決定木の数:200
が最適で、このとき
精度:約81%
の分類器が得られることがわかった。
補足:GridSearchCVはパラメタチューニングを行う際、引数cvをn(整数)と設定すれば
どのパラメタの組み合わせが「最適」であるかを求めるために、裏でデータをn分割して交差検証を行ってくれる。
test
これまではtrainデータセットの一部を精度予測のテスト用に用いていたが、最後はtrainデータセット全てで学習を行う。
前準備として、
train_Xにはtrainの"Survived"列【以外】のデータを、
train_Yにはtrainの"Survived"列のみを、格納する。
train_X=train[train.columns[1:]]
train_Y=train[train.columns[0]]
test用のデータセット(test.csv)をこのモデルに従って分類。
また、分類結果を提出する形式にまとめる(csv形式)
model=RandomForestClassifier(max_depth=4, n_estimators=200)
model.fit(train_X,train_Y)
test_prediction = model.predict(test)
passenger_id = np.arange(892,1310)
test = pd.DataFrame( { 'PassengerId': passenger_id , 'Survived': test_prediction } )
test.shape
test.head()
test.to_csv( 'titanic_forsubmisson.csv' , index = False )
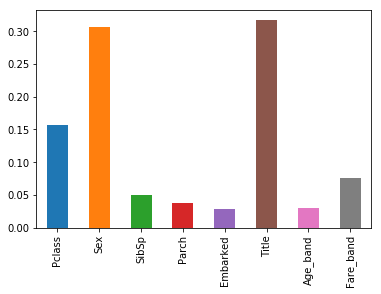
pd.Series(model.feature_importances_, index=tr_train_X.columns).plot.bar()
test_prediction

# PassengerIdを取得
PassengerId = np.array(test["PassengerId"]).astype(int)
# my_prediction(予測データ)とPassengerIdをデータフレームへ落とし込む
my_solution = pd.DataFrame(test_prediction, PassengerId, columns = ["Survived"])
# my_tree_one.csvとして書き出し
my_solution.to_csv("my_tree_one.csv", index_label = ["PassengerId"])
最終結果

2019/6/27時点