私は趣味で仕事のSlack Botを開発・運用しておりまして(?)、そこにLLMでBigQueryからデータを抽出するAIエージェント機能を搭載しましたので、その知見をまとめておきたいと思います。
前提
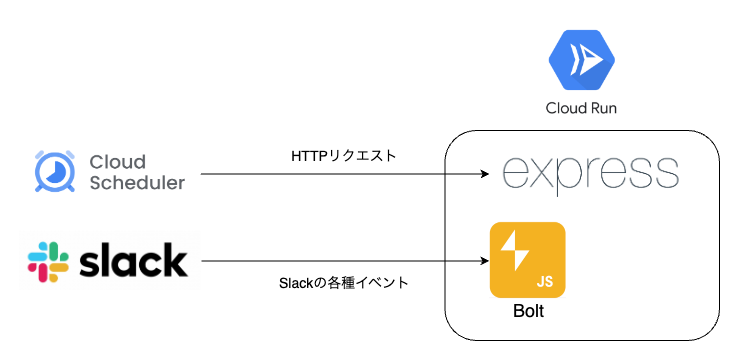
Slack Botのアーキテクチャは以下のようになっています。今回のBigQueryからデータを抽出するための指示はSlackのメッセージを通じて受け取るのですが、そうしたSlackのインターフェース周りのことはこの記事には書きません。あくまでLLMにまつわる取り組みについてまとめていきます。
成果物
以下のようにユーザーからのデータ抽出の依頼に対して、その要件を満たすクエリを提案してくれます。その後、クエリの実行の許可を出すと、実際にBigQueryのAPIを呼び出して、その結果をTSVファイルにしてSlack上で返却してくれるようになっています。

とてもシンプルな機能ではありますが、精度を高めるための工夫を様々していますので、順番に説明していきます。
処理フロー
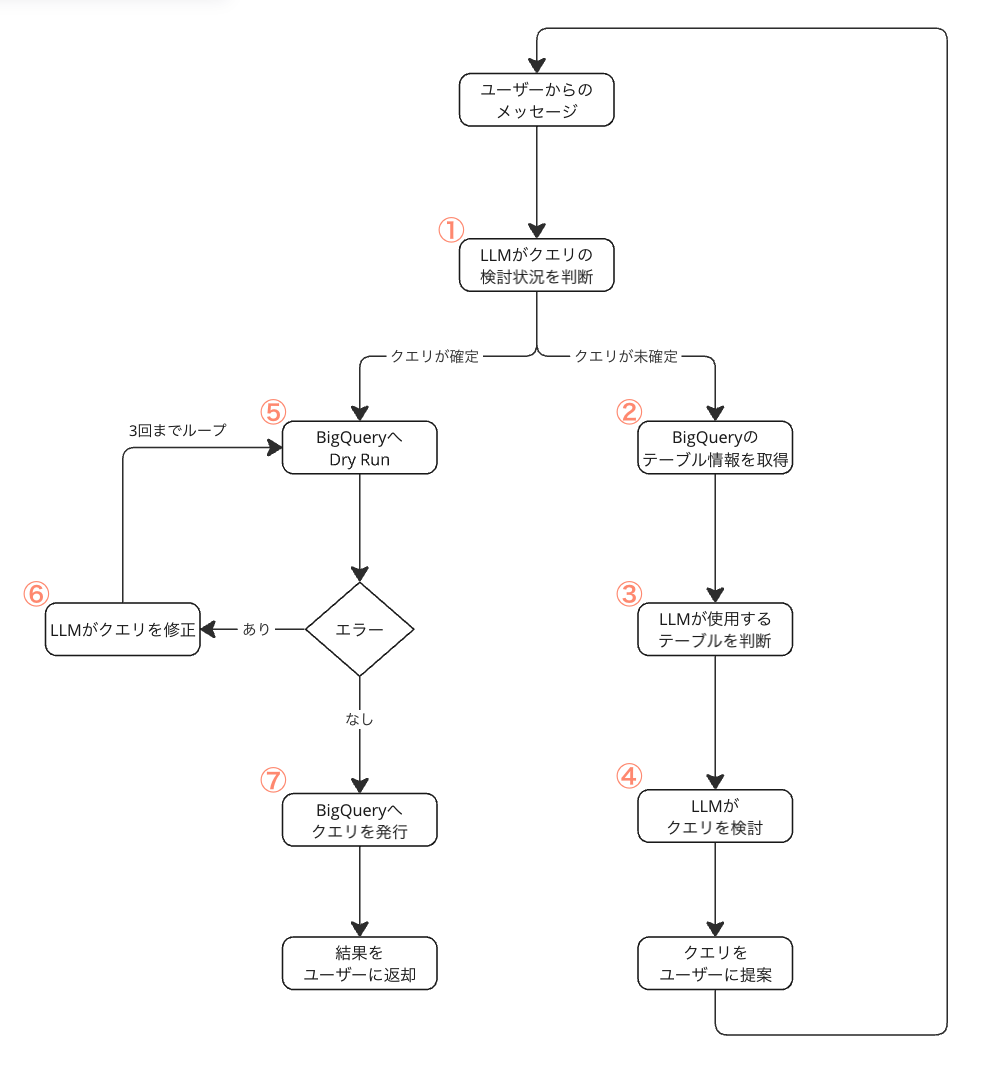
全体像はこのようになっています。一つずつ工程を取り上げて説明します。
1. LLMがクエリの検討状況を判断
まず最初に、ユーザーからメッセージがあったSlackのスレッドの会話をLLMに渡して、今後の処理の分岐を判断させます。ここの分岐は比較的シンプルなもののため、モデルはGPT-4oを使い、システムプロンプトも次のようにとても簡潔なものです。※${bigQueryAgentDeveloperPrompt()}で呼び出しているプロンプトは後述します。
You are AI given the following instruction. Judge whether a query to meet the user needs is already fixed or not. Your out must be in this JSON schema: { "isFixed": boolean }.\n\n ```${bigQueryAgentDeveloperPrompt()}```
2. BigQueryのテーブル情報を取得
クエリが未確定であれば、クエリを検討するために必要なBigQueryのテーブル情報を取得します。ここでどれだけ正確に詳細な情報を集められるかがデータ抽出の質に大きく影響します。非常に重要なステップです。
そのための適切なアプローチはスキーマに対するメタデータがどの程度整っているかに依りますが、正直ここが万全の状態になっている企業はほぼ存在しないのではないでしょうか。Column Descriptionが書かれていないだけでなく、1つのJSONのカラムに、データがAカテゴリのときはこのスキーマ、Bカテゴリのときはあのスキーマ...のように、1つのカラムで複数のJSONのスキーマを取り扱っているということも珍しくないのではないかと想像します。こういう状況に対して、どのようにアプローチをすればよいのでしょうか。
2-1. LLMが動的にテーブルを調査すれば解決するのではないか?
最初の仮説はこれでした。ユーザーの依頼に関連しそうなカラムをLLMに選ばせて、そのカラムを中心にデータのバリエーションを網羅する探索目的のクエリを発行し、その結果を基にクエリを書かせれば精度が高まると考えました。その時のプロンプトの一部が以下です。
Investigate the table column(s) schema in detail (EXPLORATORY QUERY).
- If the user’s request involves a JSON column (for example,
attributes), you must first use the “If key columns are JSON” sample query to investigate the JSON structure before writing any extraction or aggregation queries. This step cannot be skipped or replaced with a simple LENGTH() or DISTINCT() query.- If the columns are non-JSON, you can follow the “If key columns are not JSON” sample query.
- Under no circumstances should you write the final data extraction query immediately when a JSON column is involved; you must confirm the JSON keys and typical data patterns to avoid mistakes.
-- If key columns are JSON
-- 1) Extract JSON keys from each record into an array
WITH extracted AS (
SELECT
main.<PRIMARY_KEY_COLUMN> AS pk_alias, -- Example: Primary key for identification
main.<SOME_OTHER_COLUMN> AS some_col_alias, -- Example: Additional column for context
main.<ANOTHER_COLUMN> AS another_alias, -- Example: Another relevant column
main.<JSON_COLUMN> AS json_alias, -- JSON data column
REGEXP_EXTRACT_ALL(
main.<JSON_COLUMN>,
r'"([^"]+)":'
) AS key_array
FROM `<PROJECT>.<DATASET>.<TABLE>` AS main
[WHERE DATE(_PARTITIONTIME) >= DATE_SUB(CURRENT_DATE(), INTERVAL 14 DAY)] -- If time partitioning is set
),
-- 2) Convert the array of keys into a distinct, sorted string (key_set)
key_sets AS (
SELECT
pk_alias,
some_col_alias,
another_alias,
json_alias,
ARRAY_TO_STRING(
(
SELECT ARRAY_AGG(DISTINCT key ORDER BY key)
FROM UNNEST(key_array) AS key
),
','
) AS key_set
FROM extracted
),
-- 3) Count the number of times each distinct key_set occurs
counts AS (
SELECT
key_set,
COUNT(*) AS cnt
FROM key_sets
GROUP BY key_set
)
-- 4) Return each key_set, its total count, and
-- a sample record (multiple columns) for that key_set
SELECT
ks.key_set,
c.cnt,
ARRAY_AGG(
STRUCT(
ks.pk_alias AS pk_sample, -- Sample primary key
ks.some_col_alias AS some_col_sample,-- Sample value from an additional column
ks.another_alias AS another_sample, -- Sample value from another column
ks.json_alias AS json_sample -- Sample JSON data
-- Add more key columns if needed
)
ORDER BY ks.pk_alias -- Picking the first sample by primary key order
LIMIT 1
)[SAFE_OFFSET(0)] AS example
FROM key_sets AS ks
JOIN counts AS c
USING (key_set)
GROUP BY
ks.key_set,
c.cnt
ORDER BY
c.cnt DESC;
-- If key columns are not JSON
-- 1) Create a subquery that selects distinct combinations of two category columns (with aliases if they are nested fields). Columns like ID, Name, or Code that uniquely identify a record should generally not be used in DISTINCT.
WITH distinct_categories AS (
SELECT DISTINCT
main.category1 AS category1_alias,
main.category2 AS category2_alias
FROM project.dataset.table AS main
[WHERE DATE(_PARTITIONTIME) >= DATE_SUB(CURRENT_DATE(), INTERVAL 14 DAY)] -- If timePartitioning is set
),
-- 2) Select 50 random category combinations
random_categories AS (
SELECT
category1_alias,
category2_alias
FROM distinct_categories
ORDER BY RAND()
LIMIT 50
)
-- 3) Join the main table with these two random categories
-- 4) Group by the categories and use ANY_VALUE to pick one row per category combination
SELECT
r.category1_alias,
r.category2_alias,
ANY_VALUE(main.col1) AS col1,
ANY_VALUE(main.col2) AS col2,
ANY_VALUE(main.col3) AS col3
-- ... Add as many columns as necessary
FROM project.dataset.table AS main
JOIN random_categories AS r
ON main.category1 = r.category1_alias
AND main.category2 = r.category2_alias
[WHERE DATE(_PARTITIONTIME) >= DATE_SUB(CURRENT_DATE(), INTERVAL 14 DAY)] -- If timePartitioning is set
GROUP BY
r.category1_alias,
r.category2_alias
LIMIT 50;
このプロンプトはo1モデルに渡していたのですが、実はどこまでfew shotsを混ぜるか悩みました。というのも、o1モデル発表時の公式ドキュメントには以下の記載があったためです。しかし、実際にo1モデルで試行錯誤をしてみると、確実にJSONのカラムのプロパティ単位まで調査をさせようと思うと、前述のようなサンプルクエリを渡す必要があると感じました。
「o1」は、シンプルなプロンプトで最も高いパフォーマンスを発揮します。「few-shot」や「段階的に考える」といった指示は、パフォーマンス向上につながらない場合があり、時には逆効果になることもあります。
OpenAI o1 の APIの使い方, npaka
尚、2025年2月22日に改めてOpenAIの公式ドキュメントを見てみると、以下のようになっており、「最初は例示なしでいって複雑なことがやりたいなら徐々に例示していけ」と、だいぶ表現が変わっているようです。これは私の感覚とも非常に近いものでした。
Try zero shot first, then few shot if needed: Reasoning models often don't need few-shot examples to produce good results, so try to write prompts without examples first. If you have more complex requirements for your desired output, it may help to include a few examples of inputs and desired outputs in your prompt. Just ensure that the examples align very closely with your prompt instructions, as discrepancies between the two may produce poor results.
Reasoning best practices > How to prompt reasoning models effectively
2-2. いやちょっと待て、これなら事前にバッチ処理しておけばよいのでは?
ここまでやって感じたのがこれでした。毎回LLMを呼び出すのはお金も時間もかかる。調査で使うクエリも試行錯誤の結果ある程度固定的なものになったので、事前にすべてのJSONのカラムのプロパティ単位での調査をしておいて、その結果をLLMに渡して使用するテーブルを選ばせるほうが効率的だと考えました。
最終的に、以下の処理を定期的に回して、その結果をGCSに格納しておくようにしました。全テーブルのレコードをランダムに20程度取得しておいて、その中から一つずつJSONのスキーマかどうかをチェックしていき、JSONの場合はプロパティ単位ですべてのバリエーションとデータを取得していきます。LLMを挟むよりずっと早くて安い。LLMは汎用性の高いモデルですが、プログラムの中に組み込んで動かすケースをなるべく最小化したほうが、プログラムとしての安定性は増すと思います。そのための仕組み作りにLLMを活用するほうが費用対効果が高くなるケースが多いと思います。
const query = generateRandomOrderQuery(
projectId,
datasetId,
tableId,
timePartitioning ? true : false
)
const requestQueryRes = await bigQuery.requestQuery(query)
const records = await bigQuery.fetchAllQueryResultsWithHeadersAndRecordType(requestQueryRes.jobId, requestQueryRes.location)
if (!records || records.length === 0) continue; // null の場合の処理
const [header, ...dataRows] = records;
const isJSONs = new Array(header.length).fill(false);
for (const row of dataRows) {
for (let colIndex = 0; colIndex < row.length; colIndex++) {
const cellValue = row[colIndex];
if (typeof cellValue === "string") {
try {
const parsedValue = JSON.parse(cellValue);
if(parsedValue) isJSONs[colIndex] = true
} catch {
// JSON Objectではない
}
}
}
}
const jsonKeySet = []
for (let colIndex = 0; colIndex < isJSONs.length; colIndex++) {
const isJSON = isJSONs[colIndex];
if (isJSON && projectId && datasetId && tableId) {
const queryForJsonKeySet = generateJsonKeySetQuery(
projectId,
datasetId,
tableId,
header[colIndex],
timePartitioning ? true : false
);
try {
const requestQueryResForJsonKeySet = await bigQuery.requestQuery(
queryForJsonKeySet
);
const recordsForJsonKeySet =
await bigQuery.fetchAllQueryResultsWithHeadersAndRecordType(
requestQueryResForJsonKeySet.jobId,
requestQueryResForJsonKeySet.location
);
jsonKeySet.push({
columnName: header[colIndex],
jsonKeySetData: recordsForJsonKeySet,
});
} catch (e) {
logger(
"WARNING",
"JSONのカラムの詳細データを取得するクエリが失敗しました。。",
{ e, queryForJsonKeySet }
);
}
}
}
result.push({ projectId, datasetId, tableId, description, labels,fields,timePartitioning, records, jsonKeySet });
3. LLMが使用するテーブルを判断
というわけで、BigQueryの詳細なテーブル情報をすべてLLMに渡して、その中からユーザーの依頼に応えるために使用すべきテーブルを選ばせます。ここのプロンプトは非常にシンプルです。ただ、取り扱うテーブルスキーマの情報量が多くなるため、o1モデルに選ばせるほうが確実です。
You are an AI agent specialized in extracting data from BigQuery. You extract data as requested by users.
## Your Action
Your actions are essentially as follows:
- Understand user needs.
- Determine which table(s) to retrieve data from in order to meet the user’s needs.
- Return output in this JSON format: "{ data: [{projectId: , datasetId: , tableId: }, ...]}". If there is no suitable tables, return a empty array: "{data:[]}".
## Table Schema
${Table Schema}
4. LLMがクエリを検討
選択したテーブルに対してクエリをLLMに書いてもらいます。このときLLMに渡すのは選択したテーブルのスキーマとデータだけに絞ります。このように3と4のステップを分けることでクエリの精度が高まります。処理時間とのトレードオフですが、ここは必要なステップと感じます。プロンプトは少し長くなり以下のようになります。※これが前述の「1. LLMがクエリの検討状況を判断」で参照していたものです
You are an AI agent specialized in extracting data from BigQuery. You extract data as requested by users.
## Important Rules (Must Follow Exactly)
- If timePartitioning is set, retrieve only data from within the last two weeks if the target duration is not specified (use a WHERE clause to filter based on the partitioning column, considering today is ${getJapanTime()}.
- If timePartitioning is not set, retrieve data as-is (no time-based filtering).
- Retrieve necessary columns explicitly (avoid using SELECT *).
- If data extraction involves JSON schema columns, DO NOT casually apply LENGTH() or DISTINCT() to the entire JSON object. (This also applies if the schema is String, but the data is actually stored as a JSON string, such as "{"key":"value"}".)
- Always refer to the records or jsonKeySet data and handle the data property-by-property, parsing the JSON string and extract specific properties before applying functions.
- For example, if the column json_column is stored as a JSON string, use: DISTINCT(JSON_VALUE(json_column, '$.someKey')).## Your Action
Your actions are essentially as follows:
- Understand user needs. If the needs are unclear, explain what data can be extracted from the table schema, and ask users to specify their requirements. Only proceed to the next step once you have confirmed that you understand the user’s needs.
- Determine which table(s) to retrieve data from in order to meet the user’s needs.
- Write an appropriate query to meet user needs. The rules for queries are as mentioned earlier.
- Show users your query along with explanations regarding the data that can be obtained in detail, and seek their approval to call the BigQuery API with the query, e.g. "...以下のクエリを実行してもよろしいでしょうか?". If user approval cannot be obtained, ask questions and discuss how to change your query.
Other. Always communicate with users in the languages in which they converse with you.
## Table Schema
${Table Schema}
このプロンプトには重要な点がいくつかあります。
- Important Rules は微妙なカスタマイズが必要でした。例えば、プロパティ単位まで考慮してクエリを書かせるところは、Boldで強調していますが、これがなければ無視されることが多かったです。o1モデルと言えど、こういう細かいプロンプトエンジニアリングがまだまだ有効のようです。また、実際に僕が使用しているプロンプトにはデータの内容や業界用語の補足などを入れてあります。
- ユーザーの要求が不明であると感じた場合はヒアリングをするようにしています。本当はもっと手前のステップでヒアリングができればよいのですが、テーブルの情報を取得した後でなければ具体的な提案まで繋がらないことが多いので、このタイミングで入れています。
- 明確に「...以下のクエリを実行してもよろしいでしょうか?」と承認を仰ぐのは、ここの会話を次のステップで読ませることでfunction callのトリガーを引かせるためです。
5. BigQueryへDry Run
ここで業務フローのステップ上は一度「1. LLMがクエリの検討状況を判断」に戻ります。LLMが「...以下のクエリを実行してもよろしいでしょうか?」と承認を仰ぎ、ユーザーが「はい」等と承認を示すメッセージが投稿されれば、ほぼ100%の確率でfunction callが呼び出されます。
function callのtoolは以下のように一つだけ登録しています。クエリの文字列を返すのはもちろんですが、使用するテーブルの各種IDを別にしておくことで、この後のデバッグでピンポイントにLLMへテーブルのデータを渡しやすくする工夫をしています。
{
type: "function",
function: {
name: "callBigQueryAPI",
description:
"This function runs only when users explicitly approve and calls BigQuery API to get the data users request.",
strict: false,
parameters: {
type: "object",
required: ["query", "tables"],
properties: {
query: {
type: "string",
description: "BigQuery query to get the data users request.",
},
tables: {
type: "array",
description: "The tables used for BigQuery call",
items: {
type: "object",
required: ["projectId", "datasetId", "tableId"],
properties: {
projectId: {
type: "string",
description: "ID of the project containing the table.",
},
datasetId: {
type: "string",
description: "ID of the dataset containing the table.",
},
tableId: {
type: "string",
description: "ID of the table.",
},
},
additionalProperties: false,
},
},
},
additionalProperties: false,
},
},
}
このクエリでDry Runを実施し、エラーのありなしで次のステップが分岐します。
6. LLMがクエリを修正
Dry Runでエラーがある場合はLLMにクエリ、エラーメッセージ、テーブルの情報を渡して修正をさせます。エラーがなくなるまで修正させる仕様にすると、無限ループに陥ってしまう可能性もあるため、3回試行してダメならユーザーに依頼内容の変更や具体化を促すメッセージを返すようにしました。
修正のプロンプトはシンプルに以下です。ループの度にそれまでのクエリと修正履歴をプロンプトに含めることも考えましたが、なくても十分に精度が出たので、含めたときの精度は試していません。o1モデルでエラーメッセージとともに修正をさせると大体1回の修正でループを抜けることが多いです。
Please fix the following query:
```${query}```The error message after calling a dry run in BigQuery is this:
```${errorMessage}```
The related table schema is this:
```${JSON.stringify(tableSchema)}```
Return output in this JSON format: "{ query: }
7. BigQueryへクエリを発行
最後に確定したクエリをBigQueryに投げて全工程が完了です。ここで返ってきたデータをTSVに加工してユーザーに返却します。
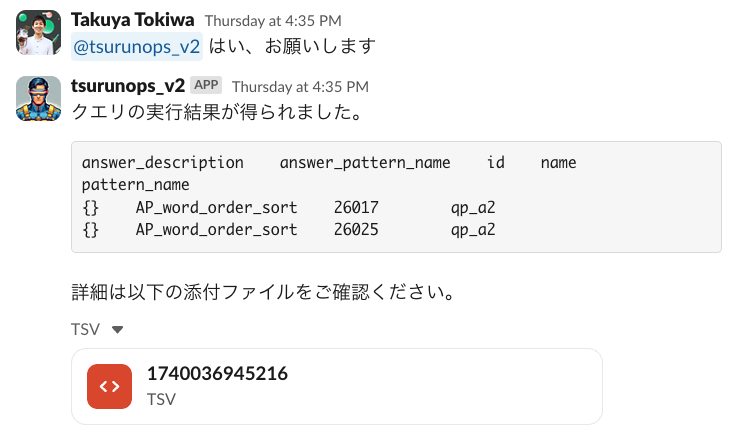
上記の画像では、テキストでも数行分をスレッドに投稿しておくことで続きの会話で文脈を活かした会話をしやすくするという工夫をしているのですが、こうしたSlackでLLMのBotを運用をするTipsはまた別の記事で共有したいと思います。
終わりに
というわけで、「LLMでBigQueryからデータを抽出するAIエージェント機能をSlack Botに搭載したお話」でした。実はこの機能はfunction callが登場したタイミングで、gpt-4-0613のモデルを使って実装したのですが、そのときはクエリのエラーが続出したり、期待通りのデータが出力できなかったりと、あまり実用性が高くありませんでした。その点、o1モデルは全然精度が違いますね・・・!さらにモデルが賢くなっていくと人間の仕事がどんどんAIに代替されていく未来を感じます。趣味でコードを書くには大変楽しい時代です。それではまた!