はじめに
TensorFlowのチュートリアルで、MNISTを使って学習すると90%以上の精度がでます。そこで誰しも思うのが、「自分で書いた手書きデータも当然予測できるよね?」だと思います。
私も以前、同じことを思って自分の手書きデータを予測させてみたのですが、精度は50%程度だったのを覚えてます。90%以上の精度がでるはずなのに、なぜ!?
今回はようやく解決できたので記事にしました。キーとなるのは前処理でした。
MNISTの前処理
MNISTは、THE MNIST DATABASE of handwritten digitsで公開されている手書きの数字データです。公開サイトを見ると、ちゃんと前処理について書いてあります。
The original black and white (bilevel) images from NIST were size normalized to fit in a 20x20 pixel box while preserving their aspect ratio. The resulting images contain grey levels as a result of the anti-aliasing technique used by the normalization algorithm. the images were centered in a 28x28 image by computing the center of mass of the pixels, and translating the image so as to position this point at the center of the 28x28 field.
MNISTは20×20ピクセルに変換された画像(ただしアスペクト比は保ったまま)の重心を、28×28ピクセルの画像の中心に合わせた画像となってます。
当初、私の予測させるための画像は、28×28ピクセルに数字を書いただけでした。
では実際に前処理の有無で精度がどう変わるか見ていきましょう。
使用するモデル
TensorFlowで以下のネットワークを組みました。KerasのAPIを使っています。
200エポック回して、MNISTのテストデータで精度が97%程度でした。
(※コードは抜粋です。今後も基本的にコードは抜粋です。)
# Define model
model = tf.keras.Sequential([
tf.keras.layers.Dense(100, activation="relu", input_shape=(28 * 28,)),
tf.keras.layers.Dense(100, activation="relu"),
tf.keras.layers.Dense(10, activation="softmax")
])
model.compile(optimizer='sgd',
loss='categorical_crossentropy',
metrics=['accuracy'])
前処理前のデータで予測
最初は、28×28ピクセルの画像に数字を書いた前処理前のデータで予想しました。
以下の画像になります。

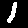








結果は下記の通りで、60%の精度でした。
(0から順に9まで予測した結果です。)
# Predict raw data
images = []
for i in range(10):
im = Image.open('data/{}.png'.format(i)).convert('L')
im = np.array(im)
im = im.reshape((28 * 28))
im = np.true_divide(im, 255)
images.append(im)
pred = model.predict_classes(np.array(images))
score = metrics.accuracy_score([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], pred)
print(pred)
print('Accuracy is {}%'.format(score * 100))
[3 1 2 3 4 5 5 3 3 9]
Accuracy is 60.0%
前処理後のデータで予測
次は前処理を行います。以下のコードで20×20ピクセルにリサイズしてから、重心を28×28ピクセルの画像の中心に貼り付けます。
# Define preprocess
def preprocess(image):
# Resize to 20 * 20
im = image.resize((20, 20))
# Pasete to 28 * 28
im_ret = Image.new('L', (28, 28))
im_ret.paste(im, (4, 4))
# Compute the center of mass and translate the image
# to the point at the center of 28 * 28
y_center, x_center = center_of_mass(np.array(im_ret))
x_move = x_center - 14
y_move = y_center - 14
im_ret = im_ret.transform(size=(28, 28), method=Image.AFFINE,
data=(1, 0, x_move, 0, 1, y_move))
return im_ret
前処理を行った画像は以下になります。




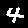





結果は下記の通り、90%の精度になりました。
(0から順に9まで予測した結果です。)
# Predict proprocessed data
images = []
for i in range(10):
im = Image.open('data/{}.png'.format(i)).convert('L')
im = preprocess(im)
im.save('data/conv{}.png'.format(i))
im = np.array(im)
im = im.reshape((28 * 28))
im = np.true_divide(im, 255)
images.append(im)
pred = model.predict_classes(np.array(images))
score = metrics.accuracy_score([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], pred)
print(pred)
print('Accuracy is {}%'.format(score * 100))
[0 1 2 3 4 5 6 7 2 9]
Accuracy is 90.0%
位置をずらして予測
追加の実験で数字の7で、位置を上下左右にずらして予測させてみました。予測に使った画像は以下の通りになります。




結果は下記の通り、ずらした画像は4つのうち1つしか当たりませんでした。
(比較のため、ずらしていない画像の予測も行っています。一番最初の結果がずらしていない画像になります。そのあとは上下左右の順に予測しています。)
# Predict shifted data
images = []
for i in ['', 't', 'b', 'l', 'r']:
im = Image.open('data/conv7{}.png'.format(i)).convert('L')
im = np.array(im)
im = im.reshape((28 * 28))
im = np.true_divide(im, 255)
images.append(im)
pred = model.predict_classes(np.array(images))
score = metrics.accuracy_score([7, 7, 7, 7, 7], pred)
print(pred)
print('Accuracy is {}%'.format(score * 100))
[7 3 4 7 5]
Accuracy is 40.0%
まとめ
今回はMNISTで学習したモデルで自分の手書きデータを予測してみました。0から9の数字のデータなので、簡単に予測できるのかと思いきや、前処理の有無で結果がずいぶんと違っていました。
データ分析の本等を読むとデータの前処理の重要性が必ずと言っていいほど書かれています。今回はそれを実感しました。
今回使ったソースコードはGitHubに公開していますので、処理の詳細を確認したい方は参照して下さい。
ちなみに初めてTensorFlowを触ったときに書いた記事でも、手書きデータでの予測をやっていました。読み返すと50%や60%の精度となっています。こちらの記事も更新しておきました。
Cloud9でTensorFlowのチュートリアル(初心者のためのMNIST)をやってみた~手書き画像の分類~
Cloud9でTensorFlowのチュートリアルで畳み込みニューラルネットワーク(CNN)をやってみた~手書き画像の分類~