概要
Kerasで2クラスロジスティック回帰をするときにデータのスケーリングを変えて見て、結果がどう変わるか見てみる記事。
スケーリング
スケーリングについては以下の記事に詳細がわかりやすく書かれています。
Feature Scalingはなぜ必要?
各フィーチャーの値の幅がバラついていると、勾配降下法で重みを更新するときの更新幅(偏微分の値)がフィーチャーごとに大きく異なってってしまうので学習が遅くなるよう。
2クラスロジスティック回帰
今回は以下の記事のコードとデータを参考にして実験しました。
Kerasによる2クラスロジスティック回帰
上記サイトでデータのスケーリングをしている箇所がある。
X = preprocessing.scale(X)
ここを変えてみて結果がどう変わるか見てみる。
ちなみにこれは
X = X - x.mean()) / x.std()
と同じ。
試してみるスケーリングパターン
- スケーリングなし
- 標準偏差除算
- 平均値減算
- 平均値減算+標準偏差除算
batch=10
Epoch=600
で結果を可視化してみる。
データ分布
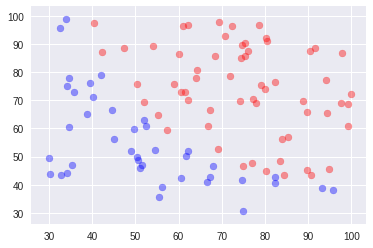
1.スケーリングなし
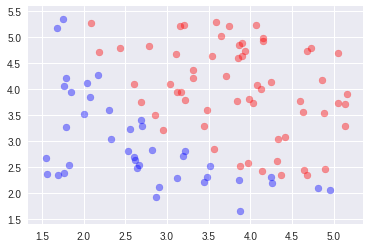
2.標準偏差除算
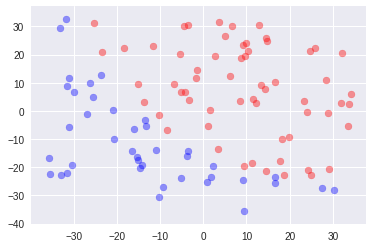
3.平均値減算
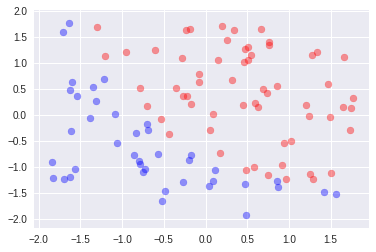
4.平均値減算+標準偏差除算
accuracy
1.スケーリングなし
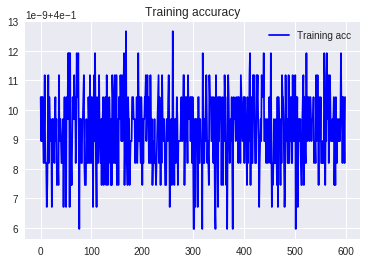
全くだめ。
2.標準偏差除算
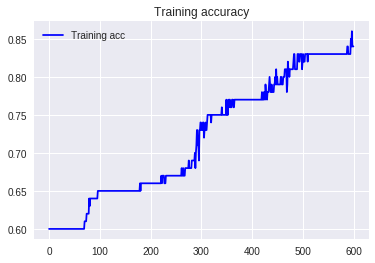
もっとEpoch増やせば上がりそう。
3.平均値減算
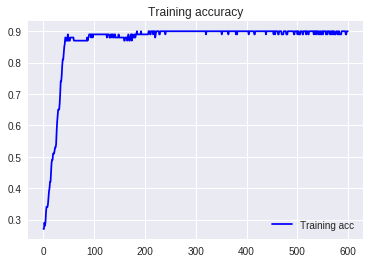
この中では一番精度がいい。
4.平均値減算+標準偏差除算
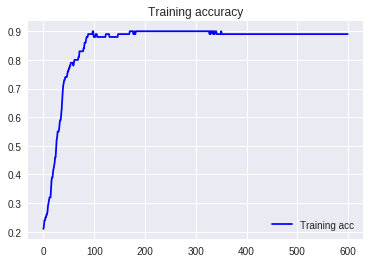
平均値減算より90%付近に到達するのに時間がかかっている。
loss
1.スケーリングなし
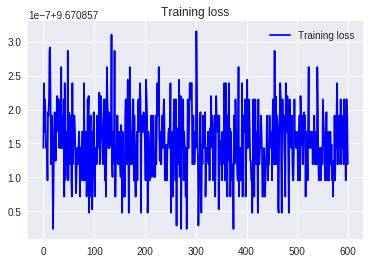
2.標準偏差除算
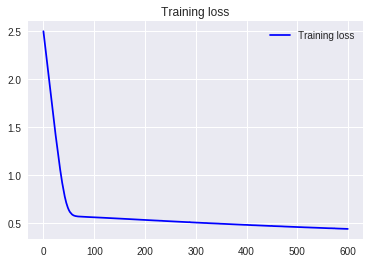
3.平均値減算
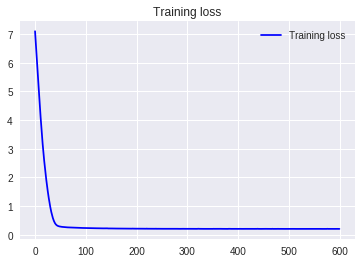
4.平均値減算+標準偏差除算
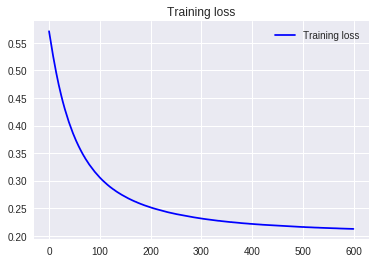
decision boundary
1.スケーリングなし
スケーリングなしは全く収束していないので割愛
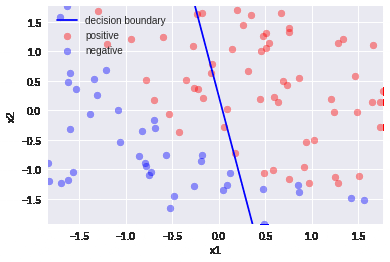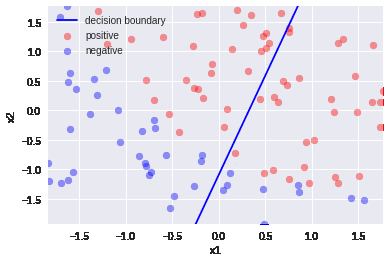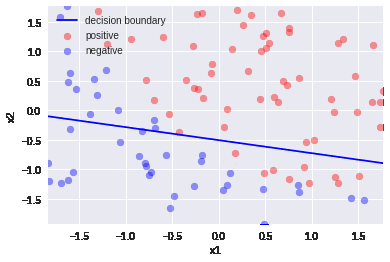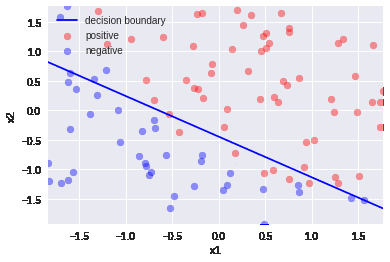
2.標準偏差除算
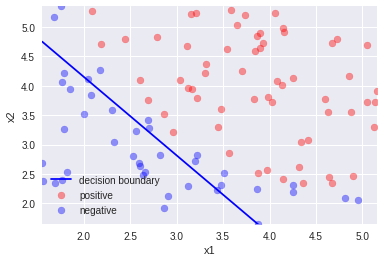
まだロスが下がりきっていないので線がうまく引けていない。
3.平均値減算
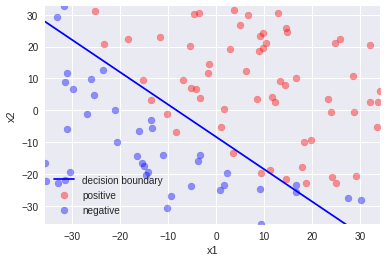
4.平均値減算+標準偏差除算
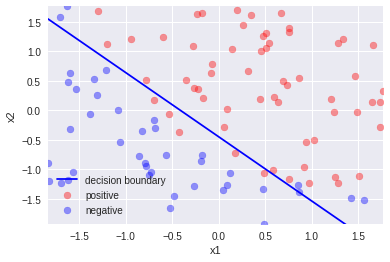
まとめ
スケーリングありのときの収束過程
今回のデータの例に限っては、平均減算が一番速く学習が収束した。スケーリングは今までお決まりの処理として書いていたけど、こうやって実際に違いを見ることでスケーリングの大切さを再認識できた。