これは ZOZO Advent Calendar 2025 カレンダー Vol.3 の 17日目の記事です
【SQL Server】実行プランの見方 〜基礎編〜
「なぜこのクエリは遅いのか?」 その答えは、実行プランにあります。
SQL Serverのパフォーマンスチューニングで欠かせない「実行プラン」の読み方について、2回に分けて解説します。今回は基礎編として、実行プランの概要と基本的な見方を紹介します。
実行プランとは?
実行プランとは、SQL Serverが「どのようにデータを取ってくるか?」を示した計画図です。
- SQL Serverがプランを自動作成
- グラフィカルなものとテキストベースの2種類がある(基本的にはグラフィカルなものを使用)

参考:おうちで学べるデータベースのきほん 第2版(https://www.shoeisha.co.jp/book/detail/9784798185330)
クライアントからクエリが渡された後、DB内部では以下の流れでデータを取得します。
| ステップ | 処理内容 |
|---|---|
| パース(構文解析) | 文法ミスの検出と中間形式(クエリツリー)への変換。プランキャッシュに実行プランがあれば「データアクセス」にジャンプ |
| 実行プラン作成 | オプティマイザが統計情報を基に複数の実行プランを生成 |
| 実行プラン評価 | 最も低コストな(効率的な)プランを選択 |
| データアクセス | 実行プランに従ってデータ取得し、結果を返却。プランをキャッシュ |
なぜ実行プランが大事か?
実行プランは「なぜ遅いのか?」「どこを直せば速くなるのか?」を知るための最重要な手がかりです。
SQLのチューニングやトラブルシュートを行う際には、必ず実行プランを確認しましょう。
SSMSでの実行プラン取得方法
今回はSSMS(SQL Server Management Studio)での実行プラン取得方法を紹介します。
推定実行プランと実際の実行プラン
| 種類 | 説明 |
|---|---|
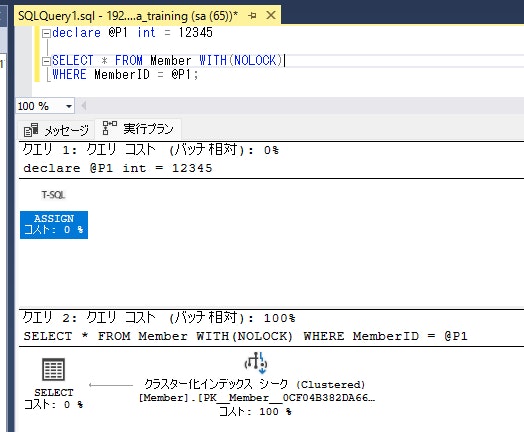
| 推定実行プラン | クエリを実行せずに、SQL Serverが選ぶ予定の実行プランを表示 |
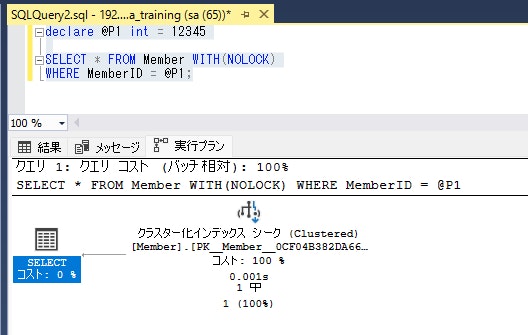
| 実際の実行プラン | クエリを実行した結果として得られる。実際に処理した行数・使用リソース・待機時間などの情報を含む |
「実際の実行プラン」が取得できるほうが情報量が多く好ましいです。
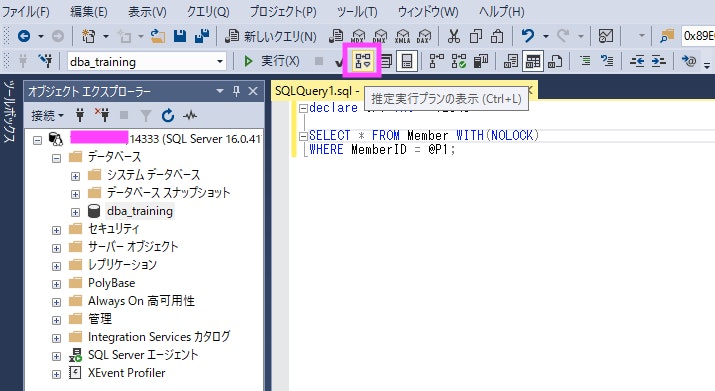
推定実行プランの取得
SSMSで <推定実行プランを表示> ボタンを押すと、クエリを実行せずに実行プランを確認できます。
実際の実行プランの取得
<実際の実行プランを含める> を押した上で、<実行> ボタンでクエリを実行します。
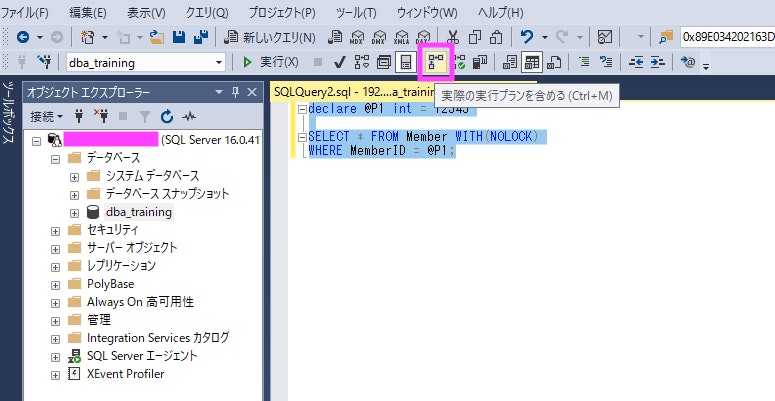

結果に加えて、実際の実行プランがタブで表示されます。
実行プランを見てみよう
基本的な実行プランの見方
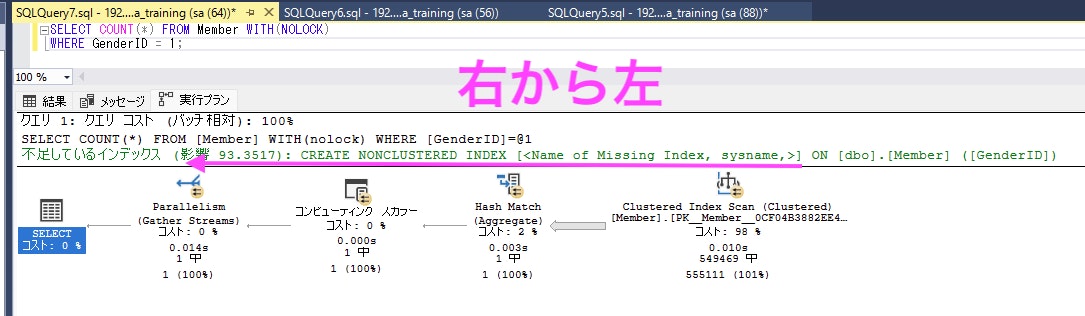
- データのアクセス順序は「右から左」 :右端がデータの取得元
- 演算子に注目:どんな処理が行われているか意識しよう
SELECT COUNT(*) FROM Member WITH(NOLOCK)
WHERE GenderID = 1;
演算子の詳細チェック
実行プランの各演算子には、詳細な情報が含まれています。
| 項番 | 内容 |
|---|---|
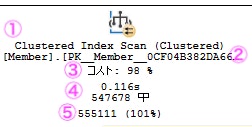
| ① | 演算子アイコンと処理種別:この演算子が行っている処理の種類。何の処理をしているか? |
| ② | 処理対象のテーブルとインデックス名:どのテーブルのどのインデックスに対して処理しているか?この演算子がアクセスしている対象を表す |
| ③ | この演算子のコスト割合(Estimated Operator Cost):クエリ全体の中でどれくらい重いかを示す。全体を100%とした相対比。コスト高いものは要チェック(参考値) |
| ④ | 処理時間と推定行数(Estimated Rows):処理を実行するのにかかった時間(実行時間)と推定行数。実際に対象データを処理した時間、処理する前に統計情報から推測した推定の出力行数(処理の結果、何件返しそうか?) |
| ⑤ | 実際の出力行数(Actual Rows):この演算子が処理した結果、実際に返した行数。「〇件のデータが処理され、左側の次の演算子に引き渡された」 |
演算子にフォーカスを当てるとより詳細な情報を確認できる
演算子にマウスカーソルを合わせると、ポップアップでさらに詳細な情報が表示されます。

| 項目名 | 意味・説明 |
|---|---|
| 物理操作 | 実際に実行された処理(例:Index Seek、Scanなど) |
| 論理操作 | 最適化時に想定された処理(物理操作と同じ場合も多い) |
| 実際の実行モード | 実行時の処理単位(Row:行単位で処理) |
| 推定実行モード | 実行前の予測処理単位 |
| ストレージ | 行ストア(RowStore)か列ストア(ColumnStore)か |
| 読み取った行数 | 実際にどれだけの行やデータページを読み込んだか(I/Oコストを見る上で重要)。例えば、1件しか返さないのに10万件読んでいたら無駄にデータを読み込んでいると判断できる |
| すべての実行の実際の行数 | 実行が複数回あった場合の合計実行行数。全実行の合計で何行出力したか |
| 実際のバッチ数 | 並列処理などのバッチの回数 |
| I/Oの推定コスト | ディスク読み込みにかかる推定コスト |
| CPUの推定コスト | CPU処理の推定コスト |
| サブツリーの推定コスト | この演算子および配下演算子の合計推定コスト |
| 実行回数 | この演算子が実行された回数(1回であれば、操作は1回のみ行った) |
| 予測実行回数 | SQL Serverが予測した実行回数 |
| すべての実行の予測行数 | 複数回実行時の合計予測行数 |
| 実行ごとの予測行数 | 1回の実行あたりの予測行数 |
| 行の推定サイズ | 1行あたりのデータサイズ(バイト単位) |
| 実際の再バインド数 | 実行プランの再バインド回数(再コンパイルの一種) |
| 実際の巻き戻し数 | 読み直しが発生した回数(通常は0) |
| 順序付け | 処理結果が順序付きかどうか(True/False) |
| ノードID | 実行プラン内のこの演算子の識別番号 |
| オブジェクト | この演算子がアクセスするインデックスやテーブル |
まずはここを見ろ!重要な項目
項目がたくさんあって混乱しますよね。まずは以下の4つを押さえておけばOKです!
| 項目名 | なぜ重要か? |
|---|---|
| オブジェクト | アクセス対象のテーブルやインデックスがどこかを示す。どこにアクセスしているのかを特定できる |
| 物理操作 | 実際に行われた処理の種類(Index Seek、Scanなど)。実行時にどう動いたかを把握できる。どの演算子操作が行われたか? |
| 読み取った行数 | 実行時にどれだけデータが読まれたか。読み込みすぎていたら、無駄なI/Oが発生している証拠。例えば、1件しか返さないのに10万件読んでいたら無駄にデータを読み込んでいると判断できる |
| 読み取った行数と予測行数の差異 | 予測行数と読み取った行数が大きくズレていると「間違ったプランが選ばれてる」可能性があるかも?統計情報のずれがあったか? |

参考: 「SQL実践入門 1.4 実行計画がSQL文のパフォーマンスを決める」より(https://gihyo.jp/book/2025/978-4-297-15190-4)
述語情報について
演算子の詳細情報には、他にも色々な情報が見れます(述語・オブジェクト・出力一覧・シーク述語)。
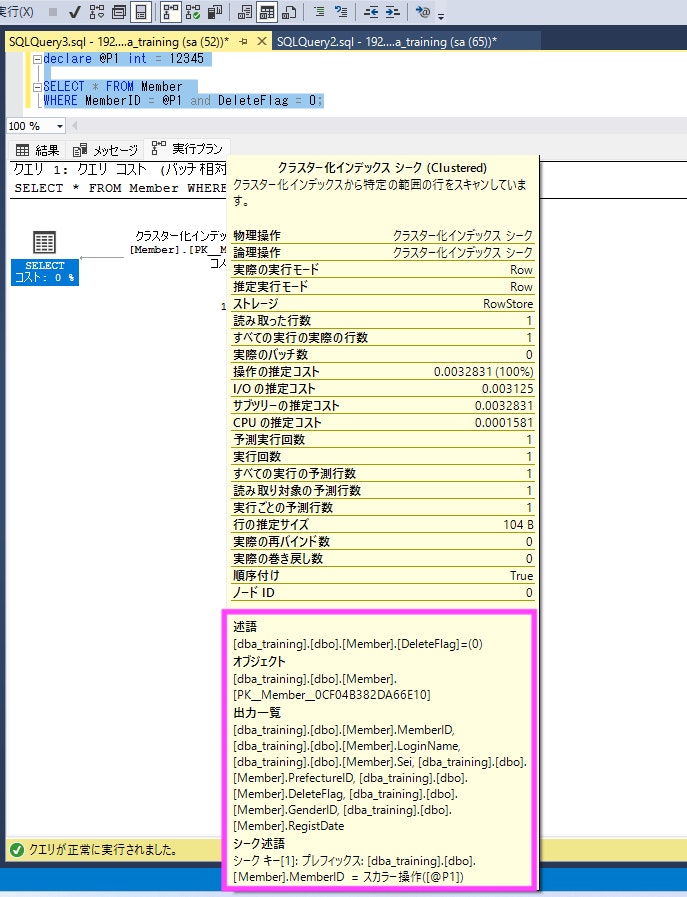
declare @P1 int = 12345
SELECT * FROM Member
WHERE MemberID = @P1 and DeleteFlag = 0;
| 項目名 | 意味 |
|---|---|
| オブジェクト | この演算子(例:Clustered Index Seek)がアクセスしているインデックスまたはテーブルのフル指定名。例:[dba_training].[dbo].[Member].[PK_Member_0CF04B382DA66E10] は dba_training データベースの Member テーブルにある PK_Member というクラスタ化インデックスにアクセスしている |
| 出力一覧 | この演算子が上位の演算子に返す列一覧(出力カラム)。つまり「この演算子が取得した値を後工程にどう渡してるか」がわかる |
| シーク述語 | Seek演算子のインデックス検索条件。シーク述語に書かれている条件は、インデックスキーにマッチしていて、インデックスツリーからデータを"探すとき"に使われた条件。WHERE に相当するもの。インデックスのキー列を使った検索条件のみがここに入る |
| 述語 |
WHERE句やJOIN条件などで評価される追加の条件。インデックスでは絞り込めなかった条件がここに来る。フィルター処理的な役割。シーク述語 に入ってない条件があれば、ここに現れることが多い |
シーク述語と述語の違い
| 種別 | いつ評価される? | 処理の流れ |
|---|---|---|
| シーク述語 | データを探すとき | インデックスツリーの中で絞り込む |
| 述語 | 探したあとに評価 | 取得したデータをフィルターする |
まとめ
今回は実行プランの基本的な見方について解説しました。
- 実行プランとは:SQL Serverが「どのようにデータを取ってくるか?」を示した計画図
- 見方の基本:「右から左」でデータの流れを追う、結合は「上と下」の関係を確認
- 重要項目:オブジェクト、物理操作、読み取った行数、推定との差異をチェック
実行プランを読めるようになると、SQLのパフォーマンス問題の原因特定がスムーズになります。
次回予告
次回は、実行プランでよく見かける基本的な演算子について詳しく解説します!
- データへのアクセス方法:Scan / Seek / キー参照(Key Lookup)
- 結合方法:Nested Loops / Hash Match / Merge Join
- JOINの使い分けとチューニング
お楽しみに!