こんにちは!インサイトテクノロジーの松尾です。
エンタープライズなシステムにおいて、ライセンスコスト削減やモダンなアーキテクチャへの刷新を目的とした OracleからAmazon Aurora PostgreSQLへの移行 は、もはや定番のプロジェクトとなりました。
AWS SCT(Schema Conversion Tool)でスキーマを変換し、AWS DMSでデータを流し込む。ここまでは順調。しかし、移行プロジェクトの後半、アプリケーションを繋いでテストを始めた瞬間に立ちふさがるのが、**「クエリの性能劣化」**というラスボスです。
「Oracle環境では普通に動いていたクエリが、Auroraに変えたら返ってこない・・・」
「移行前後の比較テストで、1,000本以上のクエリに性能劣化が見つかり、チーム全員が途方に暮れる・・・」
そんな絶望を救い、DBA(データベース管理者)または担当のアプリケーション開発者の胃を守ってくれる(かもしれない)新機能が「Insight SQL Testing」に実装されました!
なぜOracleからAurora PostgreSQLへの移行で性能が劣化するのか?
そもそも、なぜSQLの構文が正しくても性能が落ちるのでしょうか。
その理由の一つとして、OracleとPostgreSQL(Aurora)では、「クエリオプティマイザの賢さの方向性」と「データの持ち方」が根本的に異なるからです。
Oracleは数十年の歴史の中で、「多少行儀の悪いSQL」でもオプティマイザが気を利かせて、よしなにインデックスを使ってくれる仕組みが非常に発達しています。対してPostgreSQLは、より厳格です。クエリの書き方が「PostgreSQLの作法」に則っていないと、すぐにインデックスを放棄してフルスキャン(Seq Scan)を選択します。
また、アプリケーション自体でのOracle利用の歴史の中で、チューニングコメント(ヒント句)を利用して性能を担保していたような場合、それをそのままPostgreSQLでは利用できなかったりします。Oracle専用のヒント句はPostgreSQLにとってはただの「コメント」であり、オプティマイザを制御する力を持たないからです。
そういったSQLが開発の終盤で見つかった場合に、大規模な手戻りが発生してしまったり、慣れないPostgreSQLの実行計画を前にチューニングに苦戦した・・・なんて経験、ないでしょうか?
現場を救う「Insight SQL Testing」の新機能とは?
これまでの移行テストでは、劣化したクエリを見つけたら、エンジニアが一つずつ EXPLAIN ANALYZE を叩き、実行計画のツリーを目を皿のようにして眺め、「あ、ここでSeq Scanしてるな・・原因はヒント句が効いてないからか?それとも型変換か?または・・・」と推理していました。クエリが数千本あれば、これだけで数ヶ月溶けます。
最新の Insight SQL Testing は、この「推理と修正案の作成」を自動化してくれます。
強力な機能:性能劣化理由の自動特定
テスト(アセスメント)を実行すると、ツールがOracleとAuroraの実行結果を比較し、クエリ単体レベルで性能が劣化したクエリを自動でリストアップします。ここまでは従来通りですが、新機能(パフォーマンス分析機能)ではその「中身」まで踏み込みます。
パフォーマンス分析機能を使うと、画面上には、単に「遅い」と表示されるだけでなく、「Index Usage Violation(型変換によるインデックス未適用)」 や 「Optimizer Hint Ignored(ヒント句の無効化)」 といった診断結果がはっきりと表示されます。
「なんとなく遅い」が「〇〇のせいで遅い」に変わる。この「言語化」がプロジェクトのスピードを劇的に変えます。
究極の機能:修正SQLのリコメンド
さらに驚くべきは、「じゃあ、どう書けばいいのか」をコードレベルで提案してくれる点です。
性能劣化の根本原因の説明と修正リコメンドにより、安心してSQLの修正作業を進めていけます。
さらに、結果を返すようなSQL文であれば、その修正したSQLを実行して、返す結果が変わらないかもSQL Testingで再テスト可能です。性能改善だけでなく、ロジックが壊れていないか(結果の一致確認)まで同じツールで完結できるのです。
実施例
あるSQLを例に、具体的な実行例を紹介します。
Oracleで実行した元のSQL
以下のSQLをOracleのアプリケーションで利用していたと仮定します。何やらコメント句があり、そこでINDEXを使うように指定していたと思われますね・・・。
SELECT
/*+ INDEX(mig_perf_orders_dt idx_mig_perf_orders_dt_trunc) */ COUNT(*),
SUM(amount)
FROM
mig_perf_orders_dt
WHERE
TRUNC(order_ts) = DATE '2025-03-01';
PostgreSQLで実行可能にするには??
Insight SQL TestingでこのSQLをテスト(アセスメント)してみましょう。すると、実はこのままではこのSQLは実行できませんでした。
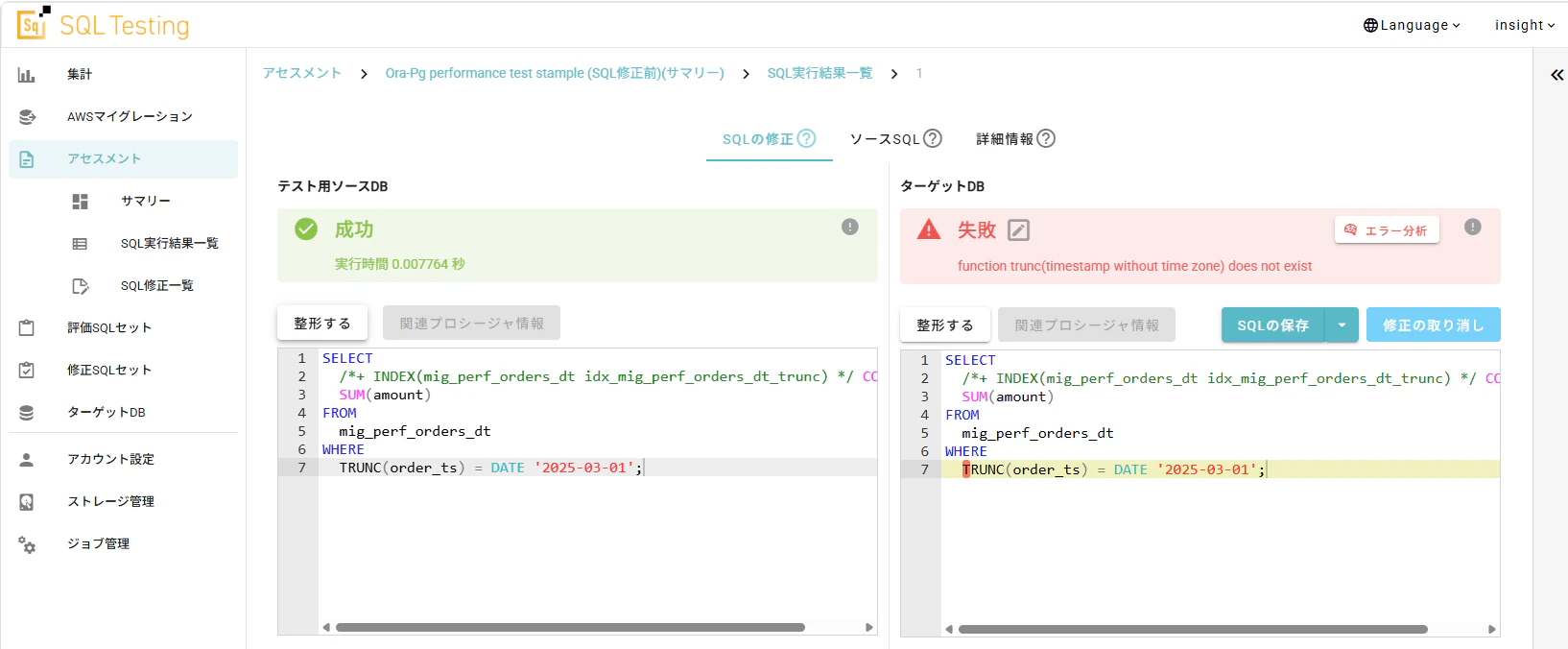
エラーメッセージからは、PostgreSQLにはOracleと同じ挙動をするTRUNC関数が標準では存在しないため、TRUNC関数の利用でエラーが出ていることがわかりますね。
Insight SQL TestingではSQL実行エラーに対してのエラー分析機能を使うことで、エラーの原因とSQL修正案を得ることができます。
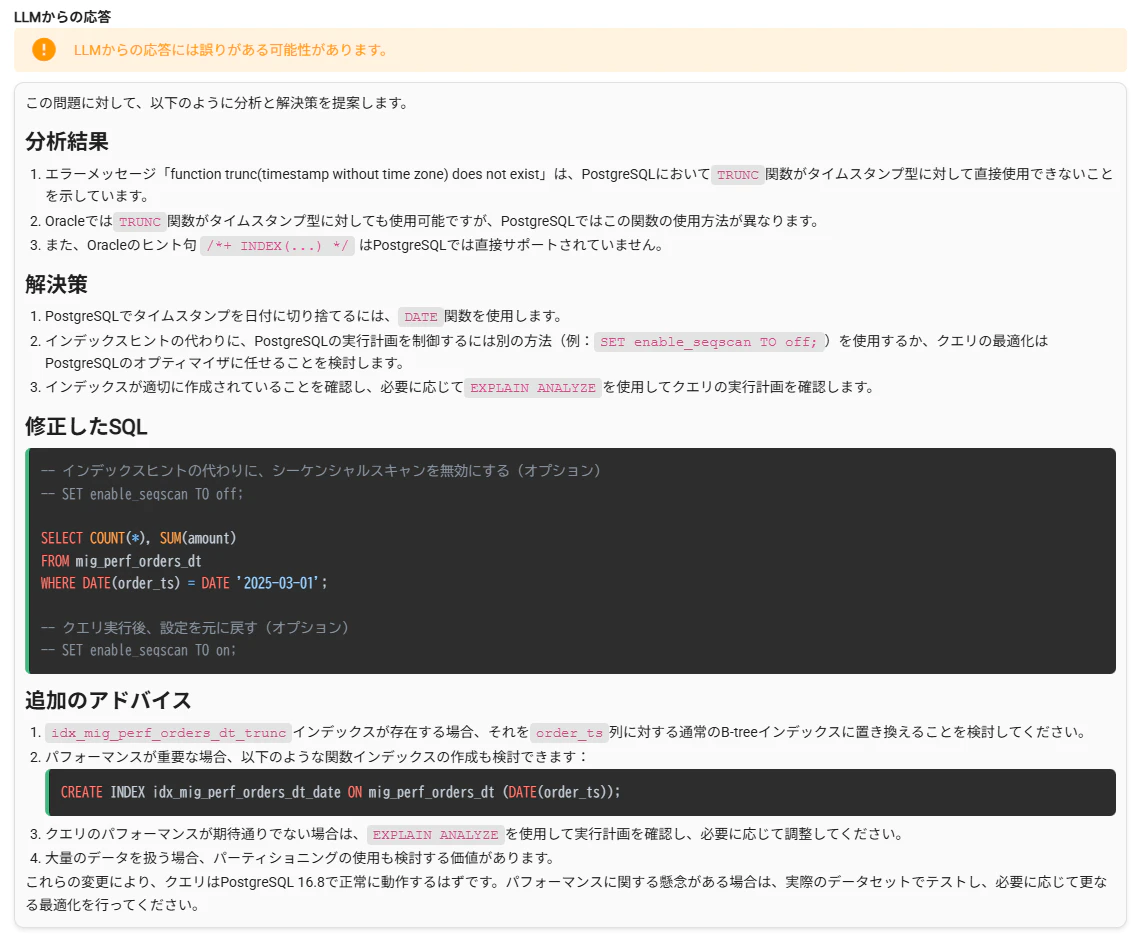
ちなみに、ここでもパフォーマンスに対する問題がありそうなことがLLMからのコメントに出ていますね!
PostgreSQLで実行できるように書き直したSQLを使って実行すると?
先ほどのエラー分析でもインデックスに対する指摘がありましたが、いったん無視して、実行エラーだけ解決して再実行してみます。
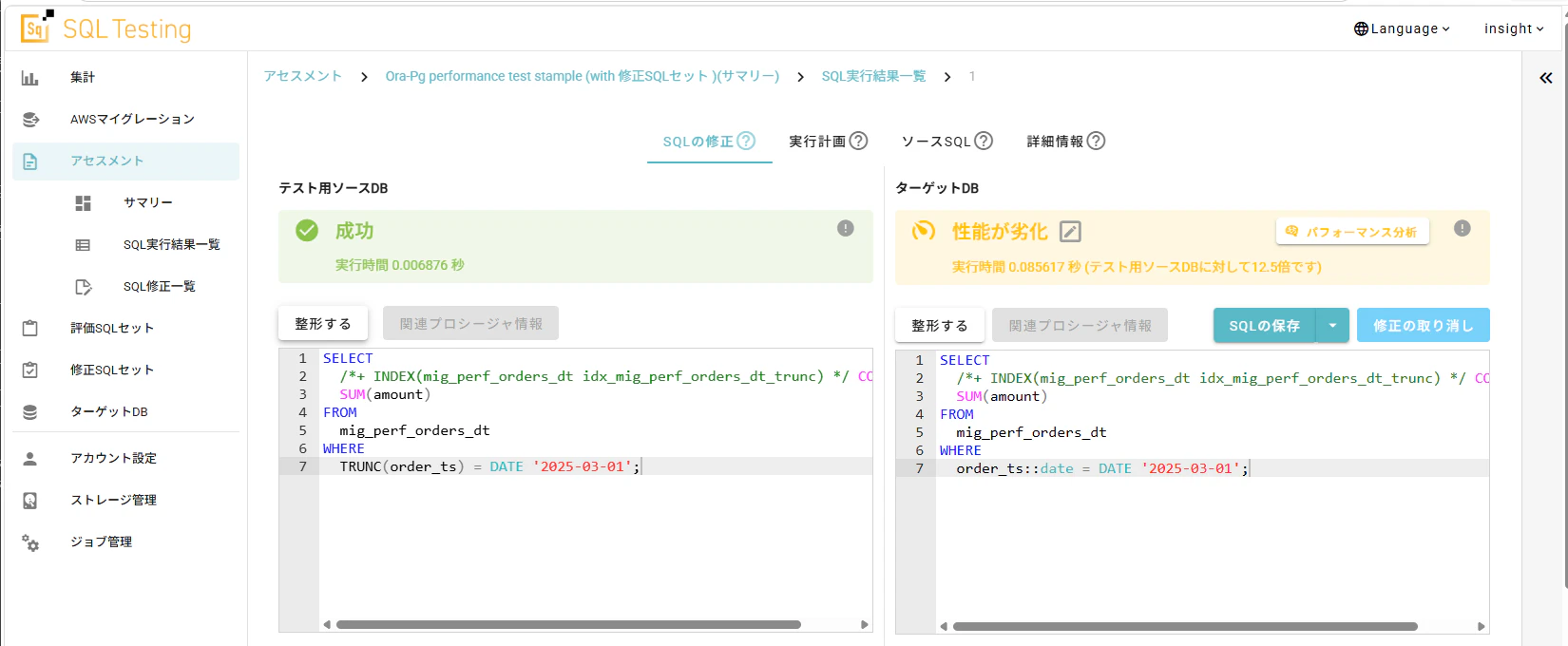
はい、性能劣化と判定されました。
今回のサンプルデータとサンプルクエリでは微々たる差に見えるかもしれませんが、本番環境の膨大なデータ量や、秒間何百回も実行される高負荷状況を想像してみてください。この「小さな差」がシステムの命取りになります。
性能検証を行う際は、単に「動くデータ」を入れるのではなく、**オプティマイザが適切に判断できる「意味のある(統計情報が有効に働く)データ量」や「実稼働環境を想定したデータ量」**でテストすることがAuroraのクエリオプティマイザの特性を正しく引き出すため観点でも不可欠です。
では、実行計画を見てみましょう。Insight SQL Testingは自動で実行計画を取得する機能があり、これも地味にうれしい機能ではないでしょうか。
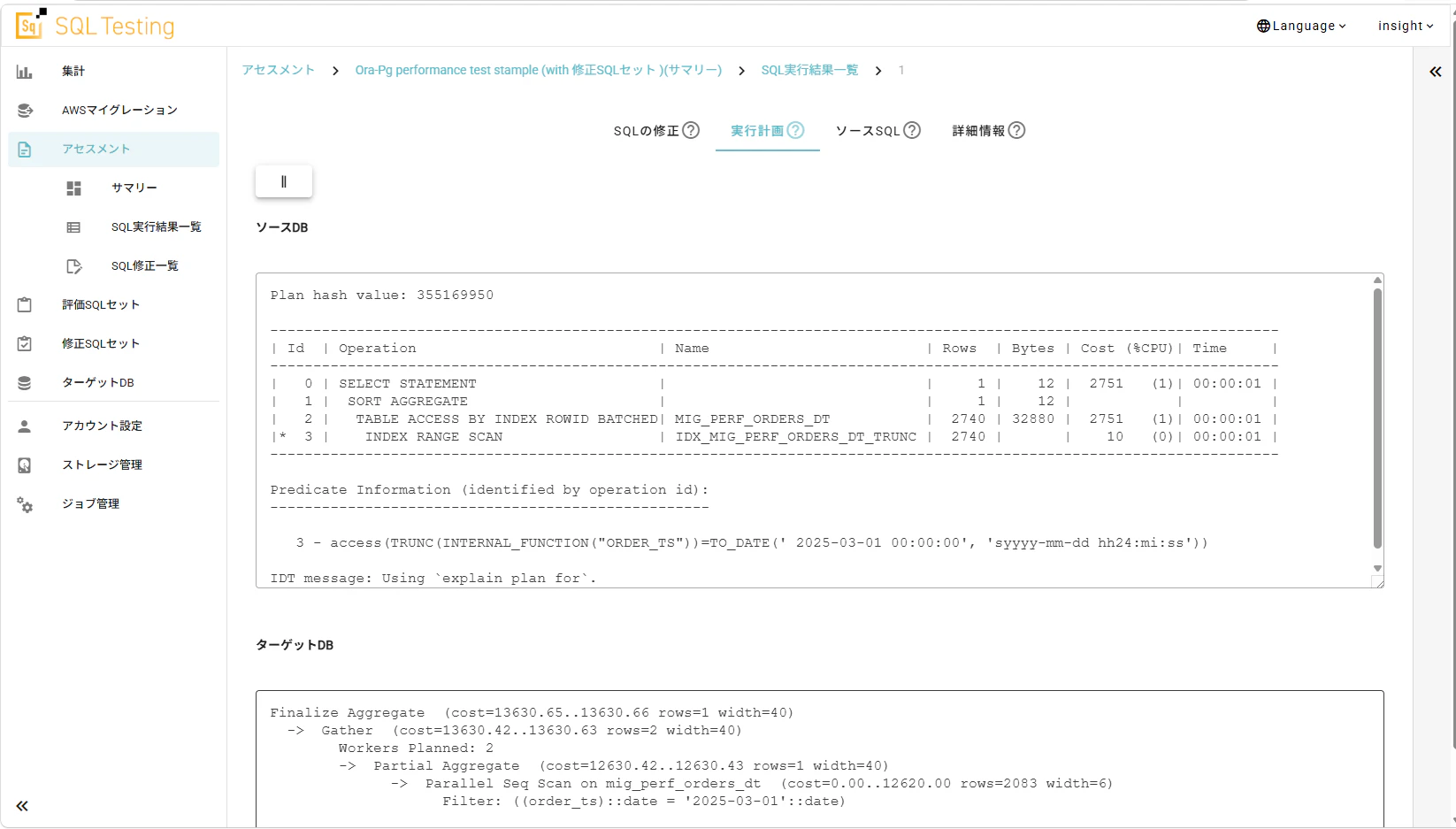
Oracleの実行計画
Plan hash value: 355169950
---------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 12 | 2751 (1)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 12 | | |
| 2 | TABLE ACCESS BY INDEX ROWID BATCHED| MIG_PERF_ORDERS_DT | 2740 | 32880 | 2751 (1)| 00:00:01 |
|* 3 | INDEX RANGE SCAN | IDX_MIG_PERF_ORDERS_DT_TRUNC | 2740 | | 10 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access(TRUNC(INTERNAL_FUNCTION("ORDER_TS"))=TO_DATE(' 2025-03-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
IDT message: Using `explain plan for`.
PostgreSQLでの実行計画
Finalize Aggregate (cost=13630.65..13630.66 rows=1 width=40)
-> Gather (cost=13630.42..13630.63 rows=2 width=40)
Workers Planned: 2
-> Partial Aggregate (cost=12630.42..12630.43 rows=1 width=40)
-> Parallel Seq Scan on mig_perf_orders_dt (cost=0.00..12620.00 rows=2083 width=6)
Filter: ((order_ts)::date = '2025-03-01'::date)
これを見てわかりますか?
なんとなくの記載内容からも、Oracleは INDEX RANGE SCAN を行っているのに対し、PostgreSQLは Parallel Seq Scan を選択しており、インデックスが活用されていないことがわかりますね!
で、インデックスを使うように何らかの修正を行っていきたいのですが、ここで追加されたパフォーマンス分析機能を使います。
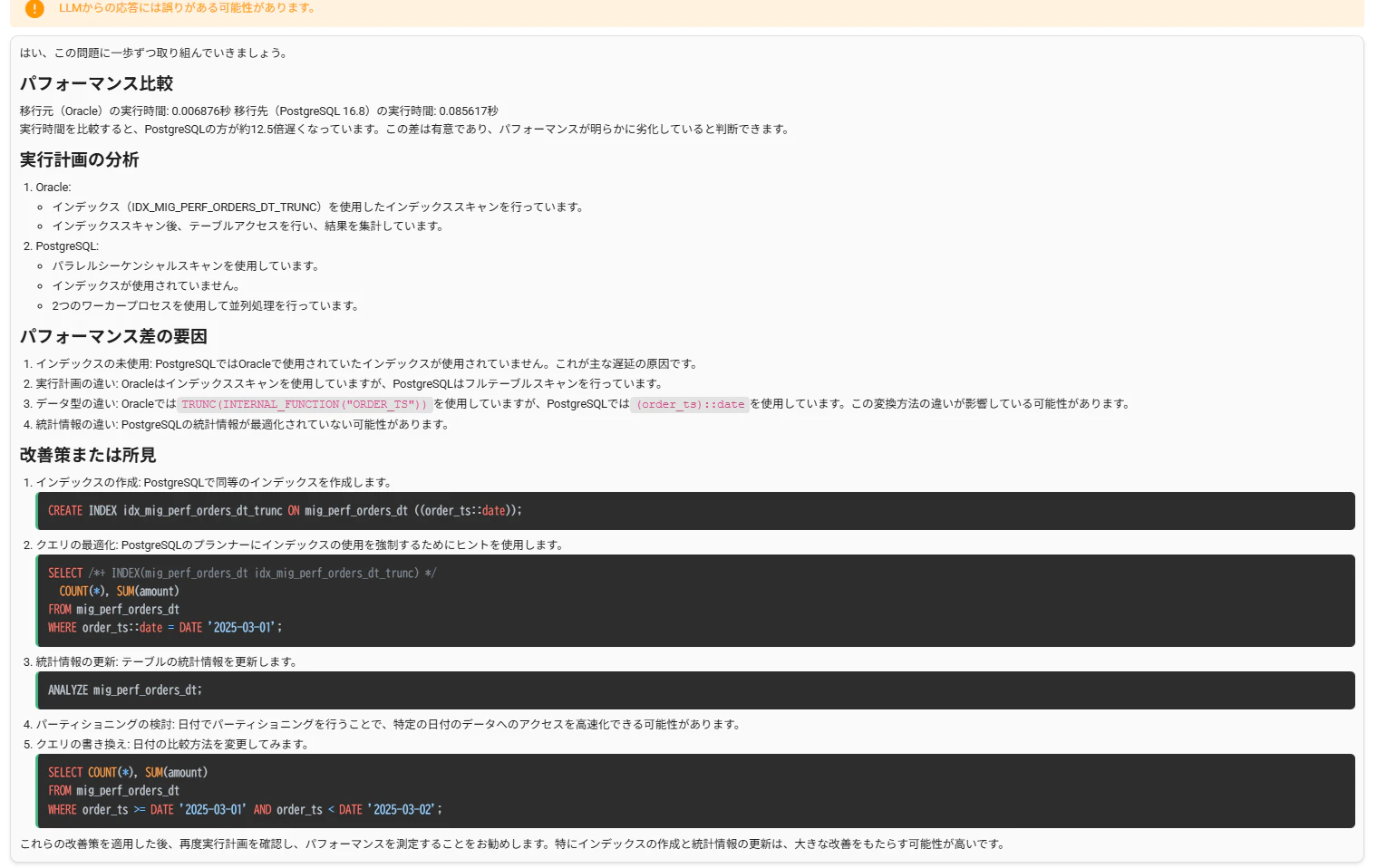
実際、インデックスが使われていないことも説明から明らかになりました。
インデックスを使う、クエリの書き方を変更するなどいくつかの修正案も提示されています。実際、対応方法としてはいくつかあると思います。WHERE文の型変換利用に合わせたインデックスを設定するのもいいでしょうし、order_ts カラム自体にインデックスを設定して、クエリの書き方を修正してもいいかもしれません。ここは他のクエリや利用ケースなどを勘案しながらになると思います。
以下は、後者の方法を採用した実行例になります。
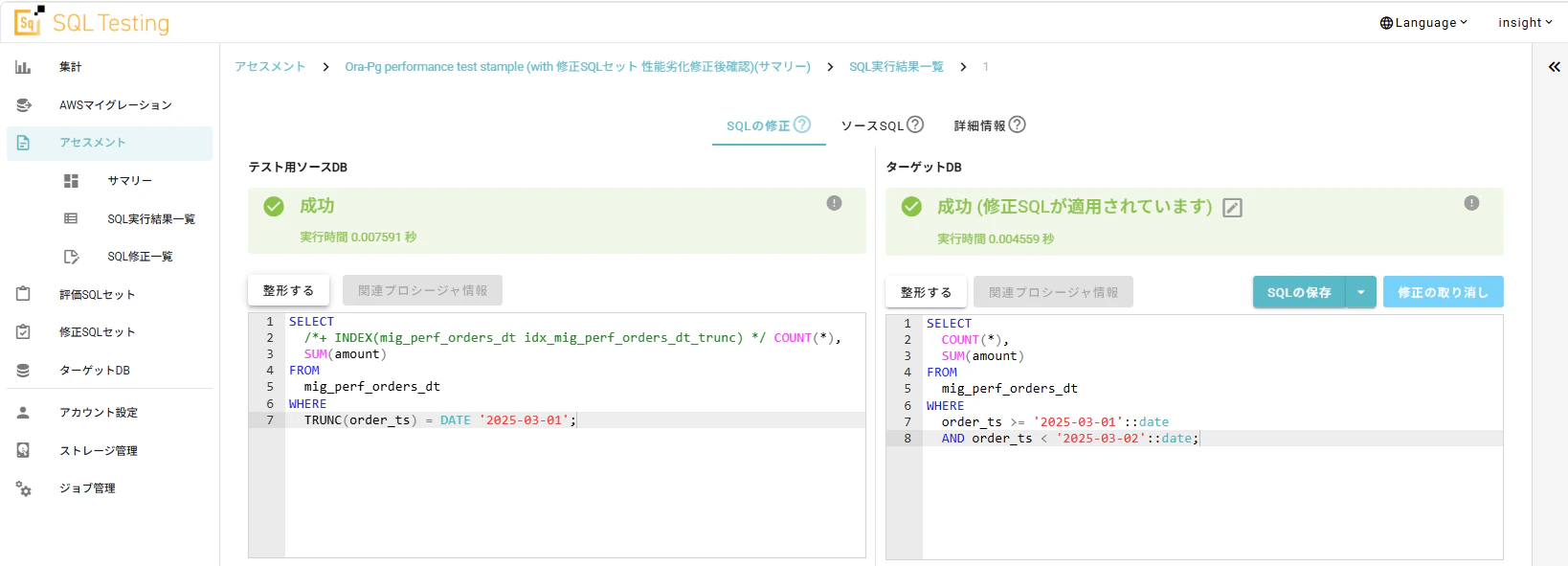
「PostgreSQLは遅いんだ」と嘆く前に、PostgreSQLがインデックスを使いやすい形に「翻訳」してあげる。その翻訳作業をツールが代行してくれるわけです。
このように、PostgreSQLにおいて「SARGable(Search ARGumentable)」と呼ばれる、インデックスを最大限に活かす書き方を即座に提案(先述の例:WHERE order_ts >= '2025-03-01' AND order_ts < '2025-03-02')。これをそのまま適用するだけで、チューニングの試行錯誤を大幅に短縮できます。クエリが少数であれば手作業で頑張るのも苦ではないでしょうが、対象のクエリが100本、1000本あるときのことを想像してみてください。
この機能が移行プロジェクトにもたらす価値
DBAや移行担当エンジニアの視点から見ると、この新機能には3つの大きなメリットがあります。
-
「属人化」の解消
実行計画を読み解くスキルは、一朝一夕には身につきません。熟練DBAの暗黙知をツールが補完することで、ツールが一次回答を出してくれるため、若手メンバーでもチューニング作業を進められるようになります。 -
工数の大幅削減
1,000本のクエリを人力で分析すれば数週間かかりますが、Insight SQL Testingならテストの結果を確認するだけ。浮いた時間を、より高度なアプリケーションのモダナイズに充てることができます。 -
手戻りリスクの最小化
「動くから大丈夫だろう」という慢心が、リリース直前の炎上を招きます。早い段階で「なぜ遅いか」の裏付けが取れていれば、自信を持ってカットオーバーを迎えられます。
まとめ
今回は型変換の事例をベースにしましたが、ヒント句の代替案やJOIN順序の最適化など、現場が直面する課題は多岐にわたります。
OracleからAurora PostgreSQLへの移行は、非常に難易度の高いミッションです。しかし、ツールの進化によって、かつては「職人の勘」に頼っていたパフォーマンス管理も、ツールの活用により大幅な工数削減が期待できます。
今回紹介した「Insight SQL Testing」のパフォーマンス分析機能は、まさにその象徴です。
- 性能劣化を見つける
- 理由を特定する
- 修正案を提示する
この3ステップを自動化することで、移行プロジェクトの成功率は格段に上がります。これから移行を計画されている方は、ぜひこういったツールの利用を検討してみてはいかがでしょうか?
本機能や「Insight SQL Testing」にご興味がある方は、ぜひお気軽にお問い合わせください。
https://www.insight-tec.com/products/sqltesting/
参考資料: