こんにちは、インサイトテクノロジーの松尾です!
本投稿では、 RDS for Oracle のセッション接続情報を S3 へ自動保存する方法を紹介します。
はじめに
RDS for Oracle では標準監査の監査ログを有効化し、その情報を簡単に CloudWatch Logs へ出力することができます。ただし、標準監査では、 V$SESSION に含まれる「 PROGRAM (実行プログラム名)」などの情報が一部記録されません。「どのアプリから接続されたか」を特定したい場合、これでは不十分なことがあります。
例えば、「 A さんの PC から接続された」ことは標準監査でわかっても、「 Excel からなのか、自作のツールからなのか、 SQL*Plus からなのか」は標準監査ではわかりません。これを特定できるのが V$SESSION.PROGRAM です。
これらの情報を取得したい場合、どのような選択肢があるでしょうか?
統合監査を使う方法も一つです。 Database Activity Streams ( DAS )を使ったり、以前別の投稿で紹介したように、統合監査ログを S3 に保存することも可能だと思います。
一方で、古いバージョンから移行してきた環境や、すでに標準監査で運用が固まっている環境において、統合監査への切り替え( Unified Auditing の有効化)は設定や運用変更のハードルが高い場合もあります。
そこで本投稿では、ログオントリガーを活用してこれらの情報を V$SESSION からキャプチャし、S3 統合機能を使って定期的に外部保存する仕組みを構成します。
1. 全体像とメリット
今回は「定期的なサンプリング」ではなく、「ログオントリガー」 を採用します。
- 全接続を捕捉: サンプリング間隔の合間に発生した短いセッションも逃さない
- 重複なし: ログイン時のみ記録するため同一セッションの二重記録を防止
-
低負荷・クリーン: S3 転送後に DB 内レコードと一時ファイルを削除(※)しストレージを圧迫させない
※upload_to_s3は非同期処理のため、削除は「次回のジョブ実行時」に行う設計としています。
以下のような流れで、ログイン時の接続情報を S3 に保存します。
-
接続時: ログオントリガーが
V$SESSIONからPROGRAMを含む詳細情報を取得し一時テーブルへ保存 -
1時間ごと:
DBMS_SCHEDULERが起動 -
対象固定:
STATUSを'NEW'から'JOB_ID'に更新し書き出し中のデータ混入を防止 -
ファイル化:
UTL_FILEでDATA_PUMP_DIR内に CSV を作成 -
外部転送:
S3_INTEGRATION機能により CSV を S3 へアップロード - 掃除: アップロード後、 RDS 上の CSV ファイルを削除しテーブル内の送信済みレコードを削除
2. AWS 側の事前準備(コンソール操作手順)
RDS インスタンスが S3 バケットに対して書き込みを行えるよう、 AWS コンソールで以下の設定を行います。
2-1. S3 バケットの作成
- S3 コンソールからログ保存用のバケットを作成(例:
rds-oracle-audit-logs-bucket)
2-2. IAM ポリシーの作成
- IAM コンソールの左メニューから [ポリシー] を選択し、 [ポリシーを作成] をクリック
- [JSON] エディタを開き、以下の内容を貼り付け(バケット名は自身のものに書き換え)
- 名前を付けて保存(例:
rds-s3-upload-policy)

{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "S3AccessForRDS",
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:ListBucket",
"s3:GetBucketLocation"
],
"Resource": [
"arn:aws:s3:::rds-oracle-audit-logs-bucket",
"arn:aws:s3:::rds-oracle-audit-logs-bucket/*"
]
}
]
}
2-3. IAM ロールの作成とアタッチ
- IAM コンソールの左メニューから [ロール] を選択し、 [ロールを作成] をクリック
- 信頼されたエンティティで「 AWS サービス」の「 RDS 」、ユースケース「 RDS - Add Role to Database 」を選択
- 「許可を追加」画面で、先ほど作成した
rds-s3-upload-policyを検索してチェックを入れ、次へ - ロール名を付けて作成(例:
rds-s3-upload-role)

2-4. オプショングループの作成
- RDS コンソールで、
rds-s3-integration-option-groupなどの名前で「S3_INTEGRATION」オプションを追加したオプショングループを作成
2-5. RDS インスタンスへのロール追加、オプショングループの設定
- RDS コンソールの「データベース」から対象インスタンスを選択
- 「接続とセキュリティ」タブの「 IAM ロールの管理」セクションで作成したロールを選択
- 「機能」で
S3_INTEGRATIONを選択し [ロールの追加] をクリック

- 「修正」を選択し、作成したオプショングループを設定
※即時適用を選択すれば、通常は再起動不要
※初めて IAM ロールを関連付けた際など、環境によっては再起動が必要になる場合があります。ステータスが pending-reboot になっていないか確認してください

3. ステップ 1 : S3 疎通確認テスト
本番用の自動化設定を行う前に、 sqlplus 等でログインし RDS から S3 へファイルを送れるかチェックします。
PL/SQL コードの変更箇所
-
V_BUCKET: 作成した S3 バケット名に変更してください
実行手順
-
sqlplus等で RDS インスタンスにマスターユーザーでログインし以下のコードブロックを貼り付け
-- ======================================================
-- S3 統合 疎通確認用テストスクリプト(匿名ブロック)
-- ======================================================
SET SERVEROUTPUT ON
DECLARE
V_BUCKET VARCHAR2(100) := 'rds-oracle-audit-logs-bucket'; -- ★自身のバケット名に書き換え
V_FILENAME VARCHAR2(100) := 's3_connectivity_test.txt';
V_FILE UTL_FILE.FILE_TYPE;
V_TASK_ID VARCHAR2(255);
BEGIN
-- 1. ファイル作成
V_FILE := UTL_FILE.FOPEN('DATA_PUMP_DIR', V_FILENAME, 'W');
UTL_FILE.PUT_LINE(V_FILE, 'S3 Connectivity Test at ' || TO_CHAR(SYSDATE, 'YYYY-MM-DD HH24:MI:SS'));
UTL_FILE.FCLOSE(V_FILE);
-- 2. S3へアップロード依頼(非同期)
EXECUTE IMMEDIATE
'SELECT rdsadmin.rdsadmin_s3_tasks.upload_to_s3(
p_bucket_name => :1, p_prefix => :2, p_s3_prefix => :3, p_directory_name => :4) FROM DUAL'
INTO V_TASK_ID USING V_BUCKET, V_FILENAME, 'test_uploads/', 'DATA_PUMP_DIR';
DBMS_OUTPUT.PUT_LINE('Task ID: ' || V_TASK_ID);
END;
/
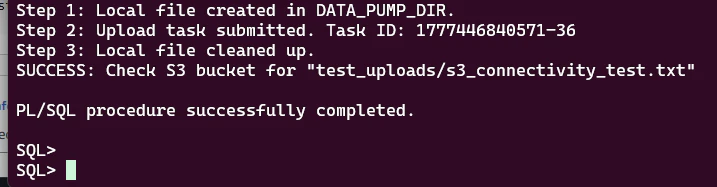
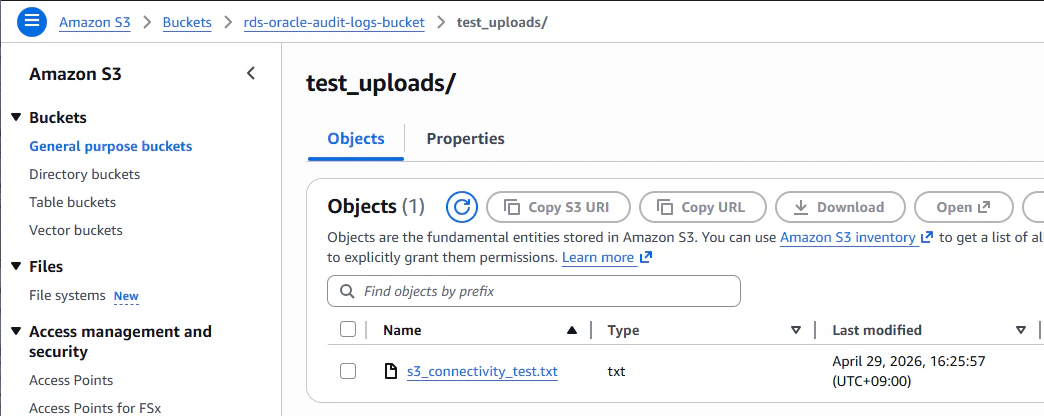
S3 コンソールの test_uploads/ フォルダを確認し、ファイルの中に S3 Connectivity Test at ... というテキストが書き込まれていれば疎通成功です。
4. ステップ 2 :セッション監査の自動化設定
疎通確認後、以下の SQL を sqlplus 上で一括実行して環境を構築します。
PL/SQL コードの変更箇所
-
V_BUCKET: プロシージャ内の変数を自身のバケット名に変更してください -
p_s3_prefix: 必要に応じて S3 上のフォルダパスを変更してください
実行手順
-
sqlplus等で RDS インスタンスにマスターユーザーでログインし以下のコードブロックを貼り付け
-- ======================================================
-- 1. 履歴保存用テーブルの作成
-- ======================================================
CREATE TABLE SESSION_LOG_HISTORY (
SID NUMBER,
SERIAL# NUMBER,
USERNAME VARCHAR2(30),
PROGRAM VARCHAR2(48),
MACHINE VARCHAR2(64),
IP_ADDRESS VARCHAR2(45),
LOGON_TIME DATE,
STATUS VARCHAR2(20) DEFAULT 'NEW'
);
CREATE INDEX IDX_SESSION_LOG_STATUS ON SESSION_LOG_HISTORY(STATUS);
-- ======================================================
-- 2. ログオントリガーの作成
-- ======================================================
CREATE OR REPLACE TRIGGER TRG_CAPTURE_LOGON
AFTER LOGON ON DATABASE
BEGIN
-- システムユーザー以外の接続を記録
IF USER NOT IN ('DBSNMP', 'RDSADMIN', 'SYS', 'SYSTEM', 'OUTLN') THEN
INSERT INTO SESSION_LOG_HISTORY (
SID, SERIAL#, USERNAME, PROGRAM, MACHINE, IP_ADDRESS, LOGON_TIME
)
SELECT
SID,
SERIAL#,
USERNAME,
PROGRAM,
MACHINE,
SYS_CONTEXT('USERENV', 'IP_ADDRESS'),
LOGON_TIME
FROM V$SESSION
WHERE SID = SYS_CONTEXT('USERENV', 'SID');
END IF;
EXCEPTION
WHEN OTHERS THEN NULL; -- トリガー起因でログイン不能になるのを防ぐ
END;
/
-- ======================================================
-- 3. S3転送プロシージャの作成
-- ======================================================
CREATE OR REPLACE PROCEDURE P_EXPORT_SESSION_LOG_TO_S3
AUTHID CURRENT_USER -- ロール権限を有効化し、rdsadminパッケージへのアクセスを許可
AS
V_FILE UTL_FILE.FILE_TYPE;
V_FILENAME VARCHAR2(100);
V_JOB_ID VARCHAR2(30);
V_TASK_ID VARCHAR2(255);
-- ★自身のバケット名に書き換えてください
V_BUCKET VARCHAR2(100) := 'rds-oracle-audit-logs-bucket';
V_SQL VARCHAR2(1000);
-- 動的SQLの結果を受け取るための定義
TYPE REFCUR IS REF CURSOR;
C_FILES REFCUR;
V_FILE_NAME_BUF VARCHAR2(500);
BEGIN
-- [A] 古い CSV ファイルの削除
-- upload_to_s3 は非同期のため、安全のために「次回の実行時」に削除
V_SQL := 'SELECT FILENAME FROM TABLE(rdsadmin.rds_file_util.listdir(''DATA_PUMP_DIR'')) WHERE FILENAME LIKE ''session_log_%.csv''';
OPEN C_FILES FOR V_SQL;
LOOP
FETCH C_FILES INTO V_FILE_NAME_BUF;
EXIT WHEN C_FILES%NOTFOUND;
UTL_FILE.FREMOVE('DATA_PUMP_DIR', V_FILE_NAME_BUF);
END LOOP;
CLOSE C_FILES;
-- [B] 今回のファイル名決定と対象レコードのロック
V_JOB_ID := TO_CHAR(SYSDATE, 'YYYYMMDDHH24MISS');
V_FILENAME := 'session_log_' || V_JOB_ID || '.csv';
UPDATE SESSION_LOG_HISTORY SET STATUS = V_JOB_ID WHERE STATUS = 'NEW';
COMMIT;
-- [C] CSV 書き出し
-- ヘッダーに IP_ADDRESS を追加
V_FILE := UTL_FILE.FOPEN('DATA_PUMP_DIR', V_FILENAME, 'W', 32767);
UTL_FILE.PUT_LINE(V_FILE, 'SID,SERIAL#,USERNAME,PROGRAM,MACHINE,IP_ADDRESS,LOGON_TIME');
FOR r IN (SELECT * FROM SESSION_LOG_HISTORY WHERE STATUS = V_JOB_ID) LOOP
UTL_FILE.PUT_LINE(V_FILE,
r.SID || ',' ||
r.SERIAL# || ',' ||
r.USERNAME || ',' ||
r.PROGRAM || ',' ||
r.MACHINE || ',' ||
r.IP_ADDRESS || ',' ||
TO_CHAR(r.LOGON_TIME, 'YYYY-MM-DD HH24:MI:SS')
);
END LOOP;
UTL_FILE.FCLOSE(V_FILE);
-- [D] S3 転送依頼 (動的 SQL で実行し、コンパイルエラーを回避)
-- ★フォルダパスは自身の環境に合わせて書き換えてください(事前にS3上に作成する必要はありません)
V_SQL := 'SELECT rdsadmin.rdsadmin_s3_tasks.upload_to_s3(' ||
'p_bucket_name => :1, p_prefix => :2, p_s3_prefix => :3, p_directory_name => :4' ||
') FROM DUAL';
EXECUTE IMMEDIATE V_SQL INTO V_TASK_ID USING V_BUCKET, V_FILENAME, 'session_logs/', 'DATA_PUMP_DIR';
-- [E] 送信済みレコードの削除
DELETE FROM SESSION_LOG_HISTORY WHERE STATUS = V_JOB_ID;
COMMIT;
EXCEPTION
WHEN OTHERS THEN
IF UTL_FILE.IS_OPEN(V_FILE) THEN UTL_FILE.FCLOSE(V_FILE); END IF;
IF C_FILES%ISOPEN THEN CLOSE C_FILES; END IF;
RAISE;
END;
/
-- ======================================================
-- 4. スケジュールジョブの登録 (1時間間隔)
-- ======================================================
BEGIN
DBMS_SCHEDULER.CREATE_JOB (
job_name => 'JOB_SESSION_LOG_S3_EXPORT',
job_type => 'STORED_PROCEDURE',
job_action => 'P_EXPORT_SESSION_LOG_TO_S3',
start_date => TRUNC(SYSTIMESTAMP, 'HH24'),
repeat_interval => 'FREQ=HOURLY; INTERVAL=1; BYMINUTE=0; BYSECOND=0',
enabled => TRUE
);
END;
/
5. 動作確認の手順
- テスト接続: SQL*Plus 等、複数のクライアントからログイン
-
テーブル確認:
SELECT * FROM SESSION_LOG_HISTORY;でデータがあることを確認

-
手動転送:
EXEC DBMS_SCHEDULER.RUN_JOB('JOB_SESSION_LOG_S3_EXPORT');を実行- 転送後に他の新規セッションがなければ、
SESSION_LOG_HISTORYは空になることを確認
- 転送後に他の新規セッションがなければ、
-
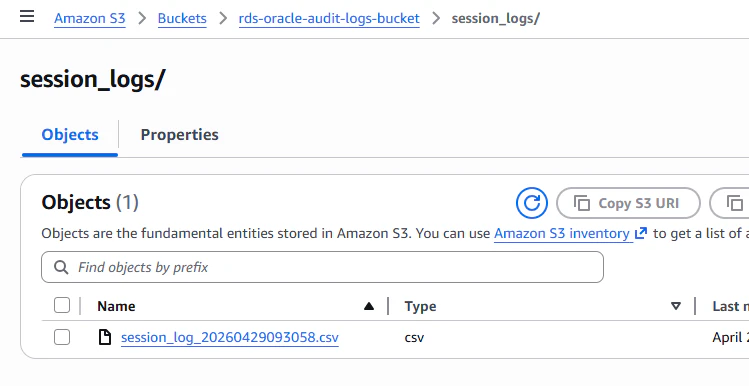
S3確認:
session_logs/フォルダに CSV が生成されているかチェック

SID,SERIAL#,USERNAME,PROGRAM,MACHINE,IP_ADDRESS,LOGON_TIME
36,34915,SCOTT,sqlplus@MATSUOT-G83LW (TNS V1-V3),MATSUOT-G83LW,xx.xx.xx.xx,2026-04-29 09:17:09
36,30777,TEST,sqlplus@MATSUOT-G83LW (TNS V1-V3),MATSUOT-G83LW,xx.xx.xx.xx,2026-04-29 09:17:19
その他、設定・動作状況を確認する SQL
- RDS 内に出力された CSV ファイルを確認(前回分が1ファイルのみ存在)
-
SELECT FILENAME FROM TABLE(rdsadmin.rds_file_util.listdir('DATA_PUMP_DIR')) WHERE FILENAME LIKE 'session_log_%.csv';

-
- スケジューラー経由でなく直接プロシージャーを実行
EXEC P_EXPORT_SESSION_LOG_TO_S3;
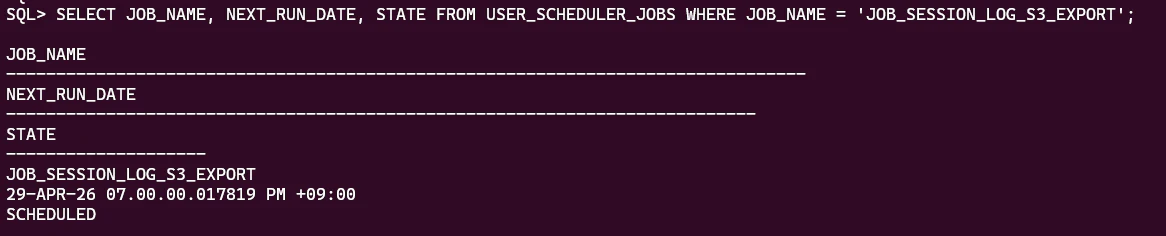
- スケジュール実行の予定の確認
-
SELECT JOB_NAME, NEXT_RUN_DATE, STATE FROM USER_SCHEDULER_JOBS WHERE JOB_NAME = 'JOB_SESSION_LOG_S3_EXPORT';
-
実際次の実行タイミングが来たら、期待通り動作しているか確認しましょう。
- S3 に新しいファイルが転送されている
-
DATA_PUMP_DIRにある CSV ファイルは一つのみ
どうでしたか?期待通りに動作したでしょうか?
本番環境に導入するにあたって考慮したい注意点
なお、本番環境で本手法を導入するにあたっては、以下を考慮してください。
- 超高頻度な接続環境: 1秒間に数百回以上などの大量の新規ログインが発生する場合、トリガーによるオーバーヘッドが無視できなくなる可能性
- コネクションプールの不使用: 接続・切断が激しいアプリではログ流量が爆発的に増え転送負荷が増大
- 改ざん防止の厳格な要件: 管理者によるログ操作を完全に防ぎたい場合は AWS DAS 等の利用を推奨
補足:PROGRAM 情報の特性について
ここで一つ知っておきたいのは、V$SESSION の「 PROGRAM (実行プログラム名)」情報はクライアント側からの「自己申告」であるという点です。たとえば、接続を行う自作アプリケーションの実行ファイル名を変えるだけで、この値は簡単に書き換えることができます。そのため、PROGRAM 単体で接続元を特定しようとするのではなく、あくまで判断材料の一つとして捉えるのがスマートです。

より確実に接続元を把握したい場合は、今回一緒に取得するようにした他のセッション情報、USERNAME(DB ユーザー名) や MACHINE(ホスト名)、そして IP アドレス をセットで確認することをお勧めします。実行プログラム名に比べて、ホスト名やネットワーク上の IP アドレスを偽装するのは一段と手間がかかるため、これらを組み合わせることで情報の信頼性がぐっと高まります。
おわりに
本投稿では、標準監査では取得困難な 「PROGRAM (実行プログラム名)」 を含む詳細情報を、 DB ストレージを圧迫せずに S3 へ自動で保存する方法を紹介しました。S3 へ CSV で保存することで Amazon Athena を組み合わせれば分析も容易ですし、2次利用も容易になると思います。本投稿が何かのお役に立てればと思います。