記事一覧:https://qiita.com/takulabo/items/d5f56132c02d4136687c
ローカルLLM統合サーバに最適 ( Xinference )

ローカルLLMサーバとして次のようなものがよく使われます。
vLLM、Ollama、LM Studio、Xinference
最近は、vLLMを利用していましたが、
モデル設定、Structured Output対応、API互換、モデル管理
などの面で 手間がかかる部分がありました。
そこで今回、
Xinference を利用したLLMサーバ構築に移行してみます。
結果、統合管理として現在の最適解でした。
※embedding、Rerank、Image、Audio、Video等モデルを管理できます。
この記事では以下を解説します。
・ Xinferenceとは何か
・ LLMサーバ比較
・Xinferenceのセットアップ
Xinferenceとは
Xinference は ローカルでLLMを管理・実行するための推論サーバです。
特徴は以下です。
- OpenAI互換API
- モデル管理機能
- Embedding / Reranker対応 (RAG作成用も動作)
- 画像モデル対応
- Structured Output対応
- Web UI
つまり、「LLMを管理するOSのようなサーバ」 です。
vLLMのようなモデル = サーバという構造ではなく
サーバ
├ LLM
├ Embedding
├ Reranker
└ Multimodal
という モデル管理型サーバになっています。
LLMサーバ比較
現在よく利用されるローカルLLMサーバを比較すると次のようになります。
| 機能 | Xinference | vLLM | Ollama | LM Studio |
|---|---|---|---|---|
| OpenAI互換API | ○ | ○ | ○ | ○ |
| モデル管理 | ◎ | △ | ○ | ○ |
| Structured Output | ○ | △ | × | △ |
| Function Calling | ○ | ○ | △ | △ |
| Embedding | ○ | △ | △ | × |
| Reranker | ○ | × | × | × |
| Multimodal | ○ | △ | △ | ○ |
| WebUI | ○ | × | ○ | ○ |
| GPU効率 | ○ | ◎ | △ | △ |
| 商用利用 | ○ | ○ | ○ | ○ |
LM Studio : GUI中心のローカルLLM
| 特徴 | GUIで簡単, デスクトップ用途に向いている |
|---|---|
| 弱点 | サーバ用途にはやや不向き |
Ollama : 最も簡単なローカルLLMサーバ
| 特徴 | 簡単に起動できる, モデルダウンロードが楽 |
|---|---|
| 弱点 | 機能拡張が弱い, Structured Outputが弱い |
vLLM : 高速推論に特化したLLMサーバ
| 特徴 | GPU効率が非常に高い, 本番推論向け |
|---|---|
| 弱点 | モデル管理機能がない, 設定がシビア |
Xinference : 研究用途・開発用途に非常に強いLLMサーバ
| 特徴 | モデル管理, AI機能に強い(Structured, Embedding,Reranker等) |
|---|
Xinferenceをセットアップする
今回は以下のディレクトリに構築します。
~/services/xinference/docker/
構成
services
└ xinference
└ docker
├Dockerfile
└ docker-compose.yaml
環境確認
GPU利用状況確認
nvidia-smi
出力があること:
GPU:NVIDIA GB10
Driver:580.95.05,CUDA 13.0
VLLM::EngineCore
ディレクトリ作成
まずディレクトリを作成します。
mkdir -p ~/services/xinference/docker
cd ~/services/xinference/docker
docker-compose.yaml作成
次に Xinference コンテナを作成します。
sudo nano docker-compose.yaml
# ~/services/xinference/docker/docker-compose.yaml
services:
xinference:
build: .
container_name: xinference
restart: unless-stopped
ports:
- "9997:9997"
volumes:
- ~/services/models:/workspace/models
- ~/services/hf_cache:/workspace/hf_cache
environment:
- NVIDIA_VISIBLE_DEVICES=all
- NVIDIA_DRIVER_CAPABILITIES=compute,utility
- HF_HOME=/workspace/hf_cache
# 🔥 GPU設定(必須)
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
# 🔥 共有メモリ(LLM必須)
ipc: host
# 🔥 互換用(残してOK)
runtime: nvidia
- 保存して終了
Ctrl+o → [Enter]
Ctrl+x
Dockerfile作成
Dockerfileを作成します。
sudo nano Dockerfile
# ~/services/xinference/docker/Dockerfile
FROM nvcr.io/nvidia/pytorch:25.09-py3
RUN pip install --upgrade pip
# 🔥 安定構成(vllm抜く)
RUN pip install -U \
transformers==4.44.2 \
accelerate \
xinference==1.6.1 \
gguf
# (任意)軽量系
RUN pip install llama-cpp-python
WORKDIR /workspace
CMD ["xinference-local", "--host", "0.0.0.0", "--port", "9997"]
- 保存して終了
Ctrl+o → [Enter]
Ctrl+x
コンテナ起動
docker-composeを起動します。
docker compose up -d
起動確認
docker ps
WebUI確認
ブラウザからアクセスします。
http://サーバIP:9997/ui
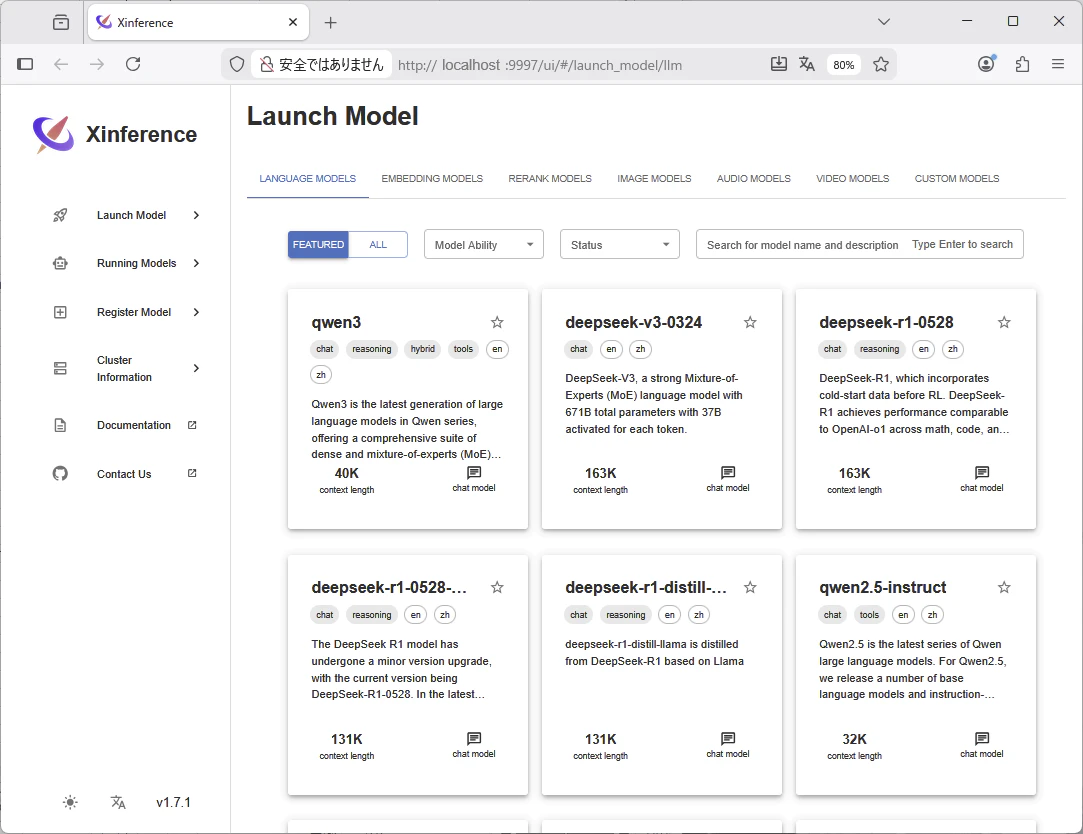
qwen2.5-instructクリック-セットアップ
Model: qwen2.5-instruct
Model Engine: Transformers
Model Format: pytorch
Model Size: 14B
Quantization: none
GPU Count per Replica: 1
Replica: 1
- 左下ロケットアイコン「🚀」をクリックして起動します。
APIドキュメント
http://サーバIP:9997/docs
モデルを起動する
Xinferenceでは
UIからモデルを起動することもできます。
またCLIでも起動可能です。
xinference launch --model-name qwen2.5-instruct
起動すると「model_uid」が発行されます。
このIDを使ってAPIアクセスします。
確認
①モデル一覧確認
curl http://localhost:9997/v1/models
②チャット確認
curl http://localhost:9997/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "qwen2.5-instruct",
"messages": [
{"role": "user", "content": "こんにちは"}
]
}'
③Function Calling確認
curl http://localhost:9997/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "qwen2.5-instruct",
"messages": [
{"role": "user", "content": "interface gi1/0/1 をshutdownするコマンド作って"}
],
"tools": [
{
"type": "function",
"function": {
"name": "generate_config",
"parameters": {
"type": "object",
"properties": {
"command": { "type": "string" }
}
}
}
}
]
}'
⑤ ストリーミング確認
curl http://localhost:9997/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "qwen2.5-instruct",
"stream": true,
"messages": [
{"role": "user", "content": "簡単に自己紹介して"}
]
}'
Dify連携
-
Dify MarketplaceにてXorbits Inferenceをインストール
-
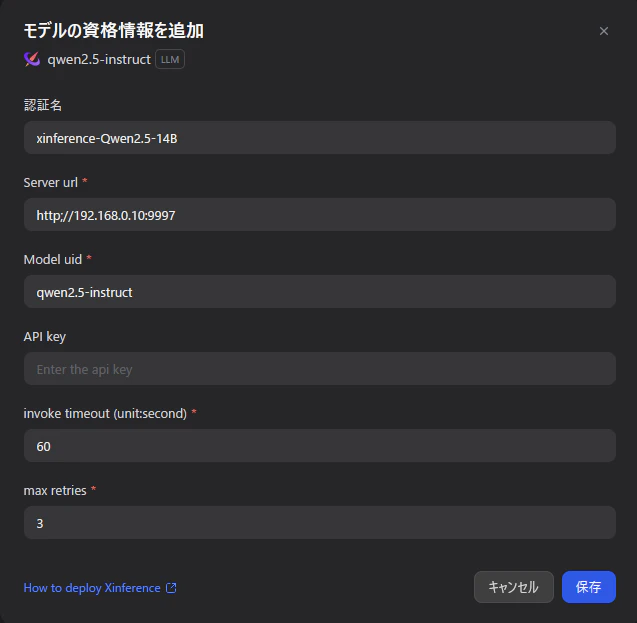
モデル設定
※ServerURLは、xinference起動中のアドレスに合わせて下さい。
-
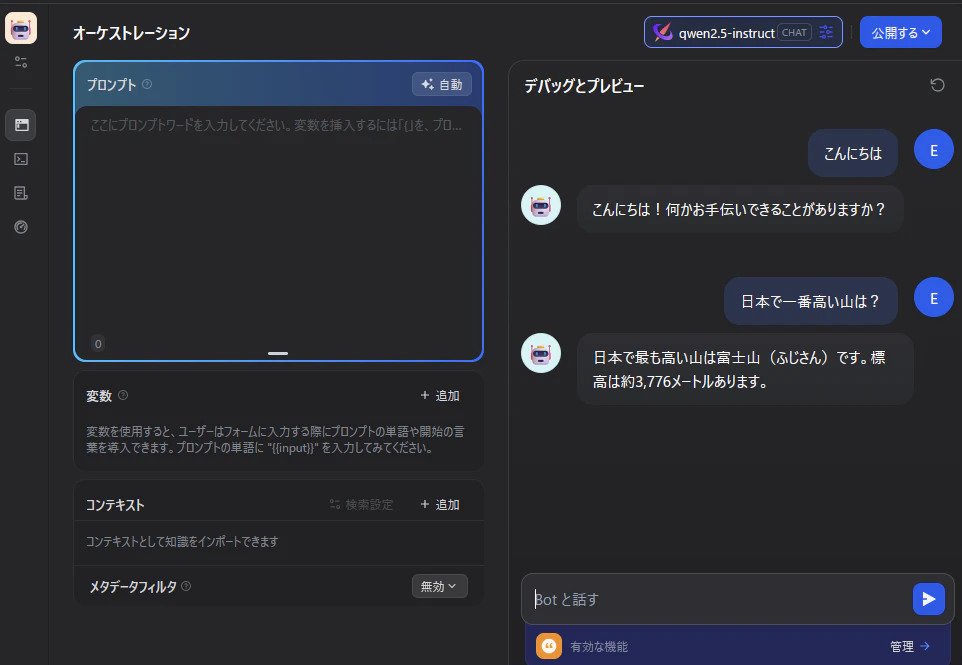
Difyチャット動作確認
まとめ
Xinferenceは(LLM,Embedding,Reranker,Multimodal)
をまとめて管理できる 強力なLLMサーバです。
AIエージェント, RAG, AI開発用途で 非常に使いやすく強力です。
LM studio,vllm,ollamaからの移行におすすめです。
ローカルLLMの進化は「単なる推論エンジン」から「AIオペレーティングシステム」に向かっている。
vLLMは優秀なエンジン、Xinferenceはその上の制御層に近いですね。
次の記事では、
- Xinference or vllm + Dify 構築
- Xinference or vllm + LangGraph
を組合わせ、OpenClawのようなローカルで動作する安全なクローズドループAIの構築を解説予定です。