はじめに
- Qiitaに投稿すると「いいね!」や「ストック」等のフィードバックがあります。
- 「いいね!」を押してもらった際、何件程度もらったら良いこと(良い記事)なのでしょうか?
- Qiita APIから抽出したデータを利用して、検証してみました。
対象データ
- 期間:2011年9月 〜2018年11月 (2011-09-15 ~ 2018-11-12)
- データは下記リンクより習得(すでに抽出済みのデータがKaggleにupしたあったので、そこからtsv形式で取得)
- Qiitaの投稿記事からデータセット作った
- Qiitaの記事データをQiita API, Scrapyで収集
データの読取・前処理
- Pandasでtsv形式のデータを読み取る
- csv形式の際はpd.read_csvだが、今回はtsv形式なので、pd.read_tableで読み取る
- デフォルトでは、タイムスタンプデータもstr型で読まれてしまうので、datetime型へ変換する
- 不要なデータを削除(列方向・行方向)を削除して、分析用データセットを作成する
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# データ読み込み
data = pd.read_table('qiita_data1113.tsv')
# データ基本情報の確認
data.head()
data.info()
# 前処理(データ型変換)
data['created_at'] = pd.to_datetime(data['created_at'])
data['updated_at'] = pd.to_datetime(data['updated_at'])
# 必要データセットの作成
## 列方向:不要なカラムの除去
df = data.set_index('created_at')[['title', 'likes_count', 'comments_count', 'page_views_count', 'tags']]
## 行方向:期間を調整 (2011-09-15 ~ 2018-11-12)なので月単位でデータを揃える
df = df['2011-10' : '2018-10']
データの可視化①
- 分析の前にデータの基本情報を理解する為の可視化を行う
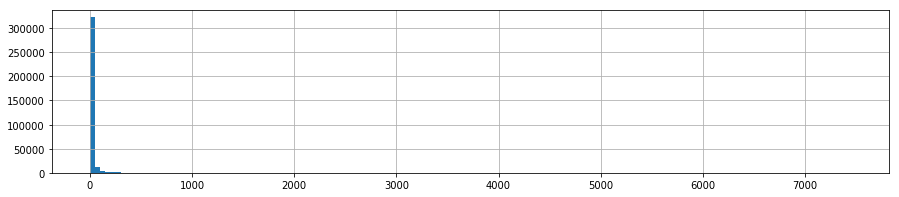
- 今回対象とするデータ(いいね数)の分布と統計情報を確認する
df['likes_count'].hist(bins=np.arange(0, df['likes_count'].max(), 50), figsize=(15, 3))
def stats(df_col):
print('平均: ', round(df_col.mean(), 2), ', 最小: ', df_col.min(), ', 最大: ', df_col.max(),
', 中央値: ', df_col.median(), ', 標準偏差: ', round(df_col.std(),2))
stats(df['likes_count'])

データの可視化②
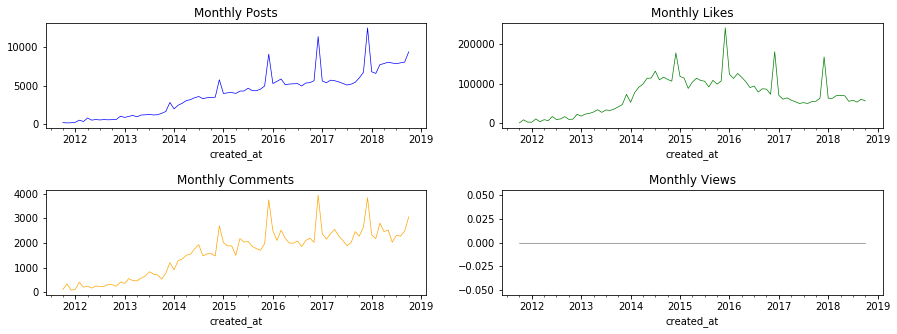
- 次に時間軸の影響を把握する為の、関連データを時系列データとして可視化する
fig, ax = plt.subplots(nrows=2, ncols=2, figsize=(15, 5))
plt.subplots_adjust(wspace=0.2, hspace=0.6)
df.resample('MS').count()[['title']].plot(ax=ax[0, 0], title = 'Monthly Posts', c='blue', lw=.7, legend=False)
df.resample('MS').sum()[['likes_count']].plot(ax=ax[0, 1], title = 'Monthly Likes', c='green', lw=.7, legend=False)
df.resample('MS').sum()[['comments_count']].plot(ax=ax[1, 0], title = 'Monthly Comments', c = 'orange', lw=.7, legend=False)
df.resample('MS').sum()[['page_views_count']].plot(ax=ax[1, 1], title = 'Monthly Views', c = 'gray', lw=.7, legend=False)
(ここまでの) まとめ
- 「いいね!」数は非常に0によった非負の分布(正規分布でない)
- 一方で、非常に多くの「いいね!」を獲得する記事があるため、平均が引っ張られている(平均17.4)
- 時系列でみると年々、投稿数は増加しているが、「いいね!」数は2015-1016年をピークに減少傾向にある(「いいね」をとるのが難しくなってきている?)
- 他方、「コメント数」は投稿数に応じて変動している(「いいね!」は取りにくくなっているが、コメントはそうでもない?)
- 記事ごとの閲覧数は全てN/Aで欠損(「いいね!数/閲覧数」のような指標が比較するのが良さそうだったのですが、データがなく残念です)
「いいね!」数の分析
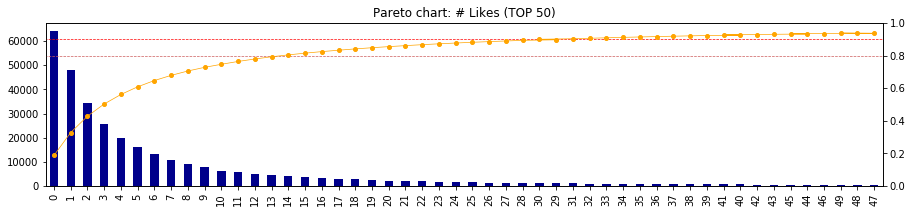
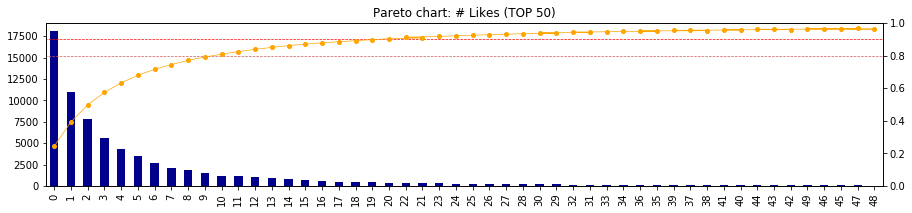
- 「いいね!」をパレート分析で可視化してみる
- グラフの見方は下記の通り
- 「いいね!」が0件の投稿が約60,000件あり(左軸)、全体の約20%を占める
- 「いいね!」が1件以下の投稿が約50,000件弱あり(左軸)、全体の約40%を占める
- 「いいね!」が2件以下の投稿が約35,000件あり(左軸)、全体の約50%を占める
- 「いいね!」が13件とれれば、全体累積構成比率の80%(TOP20%の記事!)
- 「いいね!」が30件とれれば、全体累積構成比率の90%(TOP10%の記事!)
def Pareto(df_col, top):
t = df_col.value_counts()
r = t/t.sum()
r_ = r.cumsum()
fig, ax1 = plt.subplots()
t.head(top).plot.bar(figsize=(15, 3), color='darkblue', ax=ax1)
ax2 = ax1.twinx()
r_.head(top).plot(figsize=(15, 3), color='orange', ax=ax2, marker='o', markersize=4, lw=.7)
plt.hlines(y=0.8, xmin=-1, xmax=len(t), lw=.7, color='indianred', linestyle='--')
plt.hlines(y=0.9, xmin=-1, xmax=len(t), lw=.7, color='red', linestyle='--')
plt.ylim(0, 1.)
plt.title('Pareto chart: # Likes (TOP {})'.format(top))
# TOP50で可視化(全件だと表示しきれない)
Pareto(df['likes_count'], top=50)
- ここで、時系列データの考察から、近年は「いいね!」がとりにくくなってきている事象を加味して、年度ごとのパレート図を出力してみる
# 関数を定義しておいたのでループで回すだけ
for time in ['2012', '2013', '2014', '2015', '2016', '2017', '2018']:
Pareto(df[time]['likes_count'], top=50)
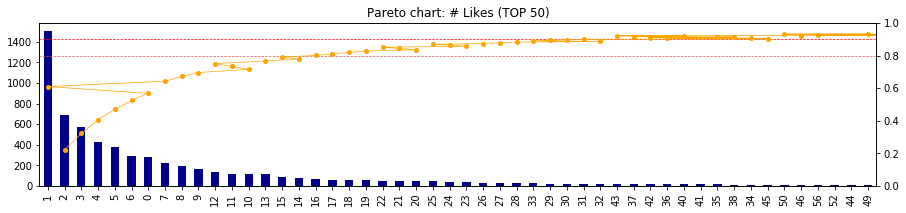
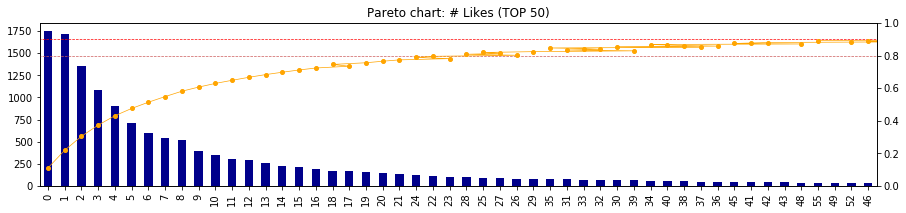
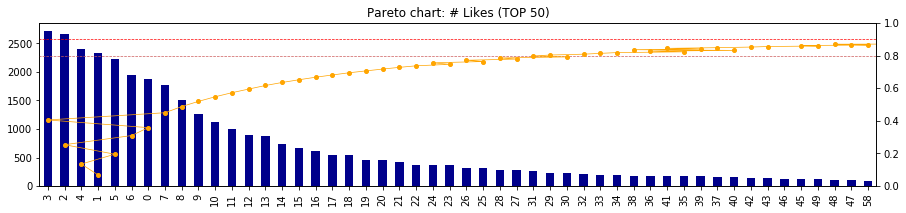
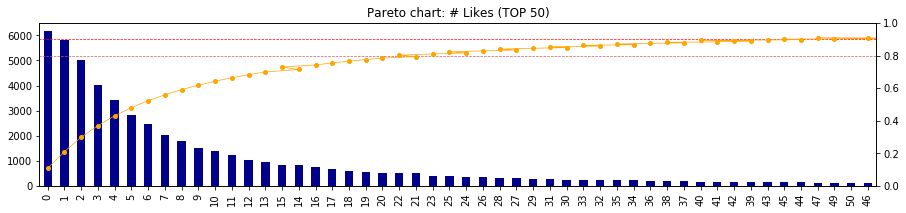
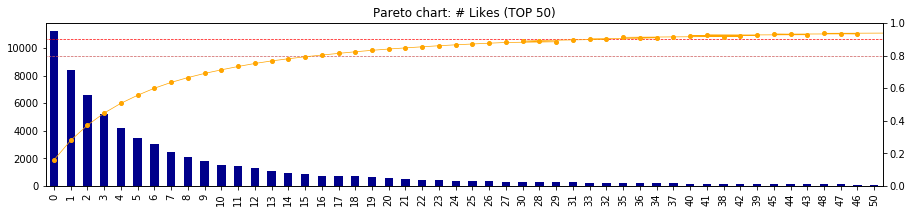

- 最近になればなるほど、累積80%地点(オレンジ線)、累積90%地点(赤線)が左へ移動している
- つまり、「いいね!」を取ることが難しくなってきている
まとめ:Qiita の「いいね!」は何件とれば「いいね!」なのか?
- ここ最近の傾向として、投稿記事は増えているにも関わらず、「いいね!」をとることが難しくなってきている。
- 上記の背景を踏まえて、直近(2018年)のデータをみると、下記となる。
- 「いいね!」が0件の投稿が全体の約30%を占める
- 「いいね!」が1件以下の投稿が全体の約53%を占める
- 「いいね!」が2件以下の投稿が全体の約66%を占める
- 「いいね!」が5件とれれば、全体累積構成比率の83%(TOP20%の記事!)
- 「いいね!」が8件とれれば、全体累積構成比率の90%(TOP10%の記事!)
- ということで、目安として、__10件の「いいね!」がつけば、Qiita内でもTOP10%を占める良記事__なのではないでしょうか?
さいごに
- Qiitaの投稿全体に対する「いいね!」に関する分析を行ってみました。
- 上記の観点以外にも、「ストック数」でみると傾向が変わる、言語別にみると違う、ユーザーごとに傾向がある、、、といった様々な観点があると思います。
- このあたりはドメイン知識から分析観点を絞り混んでいく部分なので(思いつくままに検証しているとキリがない...)、いったん全体像だけ分析してみました。
- 特定観点のフィーバック等あれば、よろしくお願いします。