概要
$\mathrm{U}^2$-NetというSaliency Object Detection(SOD)のためのネットワーク構造を提案している論文を読んだので紹介します。
SODは画像中の目立つ物体の領域を特定するというタスクですが、本論文で提案している$\mathrm{U}^2$-NetはSOTAを達成しているほか、軽量バージョンでも当時のSOTAに匹敵する精度を実現しています。

また、論文の段階ではSODを主な適用先とみなしていたようですが、直感的にわかるように、本手法は一般的なセマンティックセグメンテーションやエッジ検出のようなタスクにも使えることが明らかになってきています。つい先日、公式のリポジトリが更新され、人物の顔画像に対する線画抽出タスクでも高精度な結果が得られるということが紹介されています。

公式実装がすぐに使えるように整備されており、特殊な実装が必要なモジュールもないということあるためか、Qiitaにも使ってみたという記事やTensorflow Liteに移植してみたという記事が上がっていますので、そちらの記事も併せてご覧ください。
- https://qiita.com/john-rocky/items/9bc43884f6c34ef47aff
- https://qiita.com/SatoshiGachiFujimoto/items/680d7b07cb2bd347b184
- https://qiita.com/PINTO/items/ed06e03eb5c007c2e102
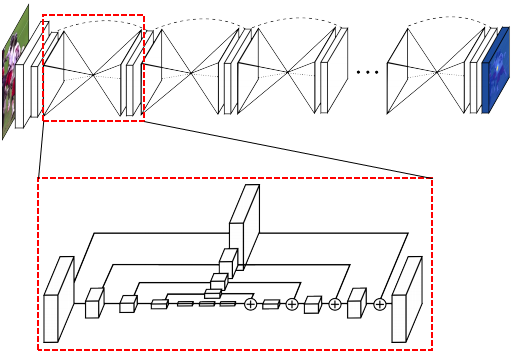
この記事では、$\mathrm{U}^2$-Netそのもののネットワーク構造について紹介します。このネットワークは、名前から推察される通り、いわゆるU-Net構造を拡張した構造になっています。下図がその概略図です。
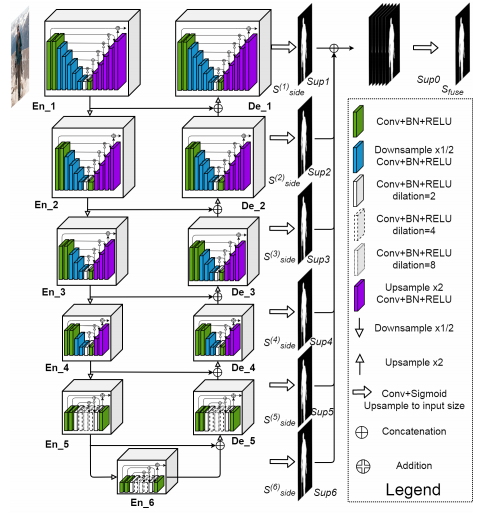
まず、全体がU-Net風のEncoder-Decoder構造になっており、入力された画像や特徴量はEncoder側のブロックの処理を適用されると、一方ではダウンサンプルされて下段のEncoderブロックの処理へと入力され、他方ではDecooder側のブロックへの入力に使われています。次に、各ブロックの中身を見てみると、これまたU-Net風のEncoder-Decoder構造が入っていることがわかります。
本手法の名前である$\mathrm{U}^2$-Netは、以上のような2次のU-Net構造を指しています。以下、なぜこのような構造が導き出されたのか、確認していきます。
書誌情報
- Qin, Xuebin, et al. "U2-Net: Going deeper with nested U-structure for salient object detection." Pattern Recognition 106 (2020): 107404.
- https://arxiv.org/abs/2005.09007
- 公式実装(PyTorch)
ReSidual U-block
まず、筆者らは、従来のSODのモデルが、タスクに特化したネットワーク構造を採用していないことを問題視します。従来の手法のバックボーンとしてよく使用されていたResNetやDenseNetなどは、画像分類モデルのために考案されたものです。特に、これらのネットワークの初期には、ストライドが2のConv層やPooling層が存在しており、高解像度の情報が適切に扱えないのではないかと指摘しています。ここで問題とされているのは、以下の表で示されるResNetの構造における、赤枠で囲った部分です。
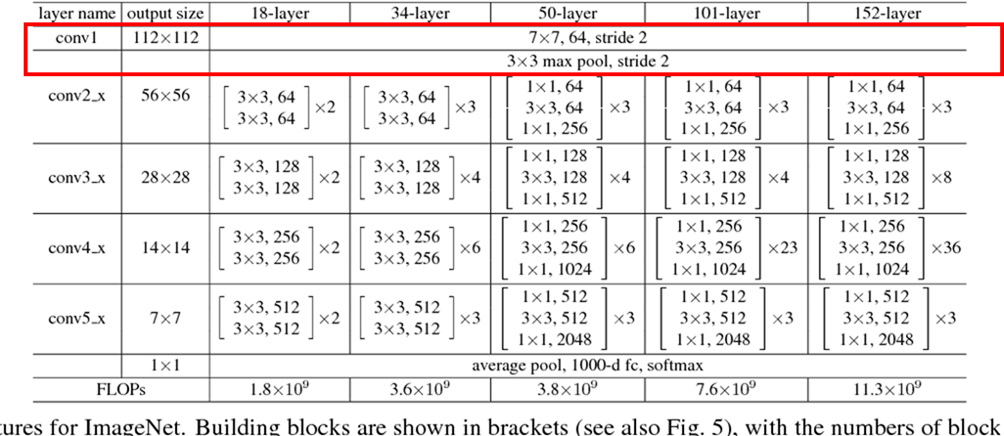
そのため、筆者らは、画像分類のモデルに依存しない、スクラッチで訓練できるネットワーク構造が必要であると主張します。そのようなネットワークの基礎となるブロックとして、以下のようなバリエーションを考えています。
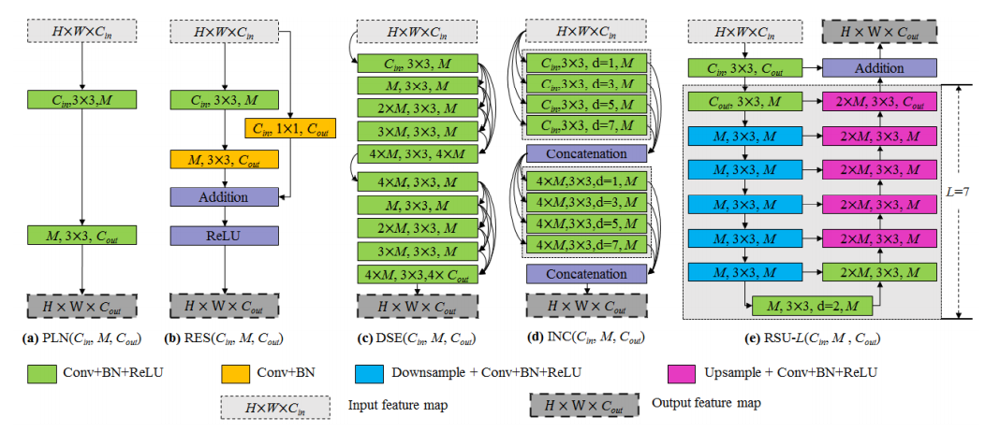
まず、(a)(b)(c)を確認します。それぞれ、VGGNetなどで使用されるConv+BN+ReLUのみからなるブロック、ResNetで使われるResBlock、DenseNetで使われるDenseBlockを表しています。これらのブロックの問題点は、すべてのConv層のカーネルサイズが3や1であり、大域的な情報を捉えにくいのではないか、という点にあります。SODというタスクでは、大域的な情報を捉えつつ、局所的な情報と混合していくという処理ができることが望ましいため、これら3つの構造はやや不十分です。(a)(b)(c)の順に、PLN、RES、DSEという名前を付けておきます。
次に(d)を見てみます。$d=1,3,5,7$によって、DilatedConv層が使用されていることがうかがえます。一般にInceptionモジュールというと、様々なカーネルサイズのConv層を並列に並べる印象ですが、ここでは、様々なdilationのConv層を並列に並べていることからInception風の構造と呼ぶことにしており、INCと名付けられています。異なるdilationのConv層を組み合わせることで、大域的な情報と局所的な情報を混合した特徴マップを作成できるのではないかと期待できます。
最後に、(e)を見てみます。このブロックでは、U-Net風の構造が採用されていますが、出力の直前にAdditionが設けられているため、全体としてはResidualな構造になっています。U-Net風の構造になっているため、大域的な情報はEncoder側でダウンサンプルされることで効率的に計算され、高解像度の情報も横方向への接続によって保持することができます。なお、全体の深さは、$L$によってコントロールすることができます。このブロックはReSidualなU-Netブロックということで、RSU-Lと名付けられています。
これらのブロックの計算量をGFLOPSで比較したのが以下のグラフになります。
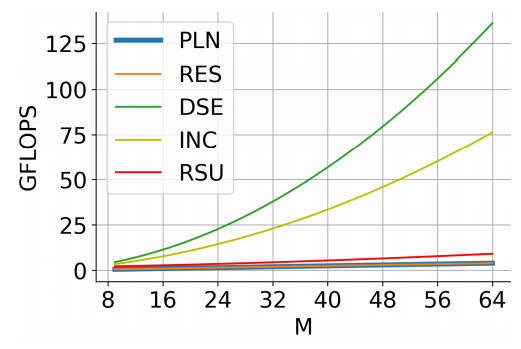
PLNやRESは計算コストが非常に小さく、中間層のチャネル数である$M$を増やしてもFLOPsは小さく抑えることができます。一方で、DSEやINCでは、$M$の増加に従い、計算コストが大きく増大します。そして、RSUは、SODにとって望ましい性質を備えていながら、計算コストはPLNやRESに匹敵するような小ささに収まっています。RSUは上図では横幅が大きく描写されていたので、計算コストも高そうに見えますが、実際にはDSEやINCのような複雑な結線は存在しませんし、ダウンサンプルされた特徴量に対する低コストな計算も多いため、計算コストはそこまで大きくならないわけです。
以上の議論から、SODのための新たなネットワークの基礎としてRSUを採用するのが良いだろう、という方針が立てられます。
U2-Net
RSUのようなU-Net風の構造をもったブロックを採用しているネットワークは、既存の手法でも提案されています。例えば、人の姿勢推定(関節位置の推定)のために用いられるHourglassNetworkでは、似たようなブロックを採用して、これらを直列にならべた構造になっています。
しかし、これらの既存のネットワーク構造は、深くなるにつれてブロック数$n$に比例した計算コストがかかります。
この問題を解決するために、本手法ではまたもやU-Netに頼ります。再掲となりますが、以下のようにRSUを基本単位とするU-Net風のEncoder-Decoderによって、ネットワークの深さと計算量の抑制を同時に実現します。下段になるに従い、入力される特徴マップの解像度は低くなっていくので、それに合わせて、RSUの深さ$L$も浅くしていきます。また、En_5, En_6, De_5などでは、すでに十分入力される特徴マップの解像度が低くなっているため、RSUブロック内ではダウンサンプルは使用せずに、DilatedConv層を使用します。
$\mathrm{U}^2$-Netの各段階での特徴マップに対してConv層+Sigmoid活性化を適用したのち、入力画像サイズまで拡大したものを各段階での出力$S^{(i)}_{\mathrm{side}}$とします。これらを結合し、最後にまたConv層+Sigmoid活性化を適用して、最終的な出力$S_{\mathrm{fuse}}$が得られます。
$\mathrm{U}^2$-Netの訓練は、真のSaliency Mapに対して、各段階での出力$S^{(m)}_{\mathrm{side}}$や最終出力$S_{\mathrm{fuse}}$が近づくように、binary cross entropy損失によって行われます。
\mathcal{L}=\sum_{m=1}^{M} w_{\text {side}}^{(m)} \ell_{\text {side}}^{(m)}+w_{\text {fuse}} \ell_{\text {fuse}}
\ell=-\sum_{(r, c)}^{(H, W)}\left[P_{G(r, c)} \log P_{S(r, c)}+\left(1-P_{G(r, c)}\right) \log \left(1-P_{S(r, c)}\right)\right]
最終的に、本論文では、RSUの中間層のチャネル数$M$が大きいバージョンと小さいバージョンの2つを提案しています。それぞれ、GTX 1080Ti上で30FPS, 40FPSで動作する軽量なモデルとなっています。
まとめ
以上、SODのためのネットワーク構造$\mathrm{U}^2$-Netを紹介しました。ネーミングと構造だけ見ると奇抜に見えるかもしれませんが、定量的な分析を通した基礎ブロックの選択をしており、納得感のある設計になっていると思います。
SODだけでなく、いくつかのタスクへの応用が利くことが確認され始めているので、これからの動向をウォッチしていこうと思います。