概要
近年、機械学習の公平性などの文脈で、ジェンダーや人種によって生じるバイアスが問題になっています。
このようなバイアスは、例えば画像分類タスクを解く際に、そこに写っている人物の性別から予測できてしまう、という事態をもたらします。
そのようなバイアスを避けるためには、画像分類のラベルと性別とが相関しないように、うまくバランスされたデータセット(Balanced Datasets)を用意すればいいように思います。しかし、本論文は、データセットのラベルのバランスを揃えるだけでは不十分だよ、ということを示しています。そのために、バイアスを評価する指標DatasetLeakageとModelLeakage、およびBias amplificationを提案し、そのようなバイアスを取り除くことができるモデルによって、その指標の有効性を示しています。
書誌情報
- Wang, Tianlu, et al. "Balanced datasets are not enough: Estimating and mitigating gender bias in deep image representations." Proceedings of the IEEE International Conference on Computer Vision. 2019.
- http://openaccess.thecvf.com/content_ICCV_2019/html/Wang_Balanced_Datasets_Are_Not_Enough_Estimating_and_Mitigating_Gender_Bias_ICCV_2019_paper.html
新規性・重要ポイント
データセットが持っているバイアスを定量化するDatasetLeakageと、モデルが持っているバイアスModelLeakageを定量化し、その差である、モデルによってもたらされたバイアスの増加分Bias amplificationと呼ばれる指標を提案しています。
DatasetLeakage
データセットが持っているバイアスは、下式の$\lambda_D$で定義されます。$Y_i$は画像のラベル、$g_i$は画像の性別、$f$は$Y_i$から$g_i$を予測する関数となっています。本論文では、$f$はAttackerと呼んでおり、4層のMLPで実装されます。
要するに、DatasetLeakageは、ラベルから性別をどの程度予測できてしまうのか、を定量化する指標です。
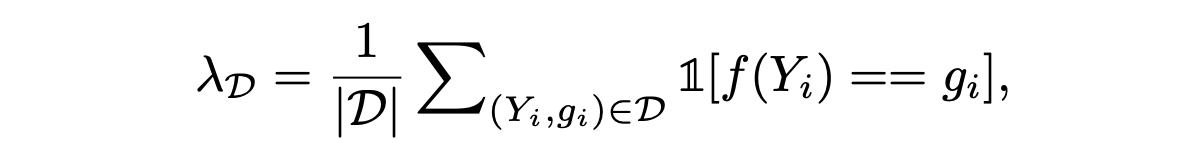
また、ラベル$Y$にF1scoreが$a$となるようにノイズを加えるという操作$r$を行ったときのLeakageを$\lambda_D(a)$と定義しています。なお、ここでF1scoreは、性別予測の精度ではなく、ラベル予測(実際には予測ではなくノイズを加えているだけ)の精度であることに注意しましょう。
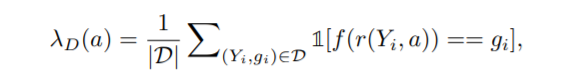
DatasetLeakageは、データセットのみから決まる指標です。
ModelLeakage
学習済みのモデル(F1socreが$a$)が持っているバイアスは、下式の$\lambda_M(a)$で定義されます。$\hat{Y_i}$は、モデルの予測結果です。
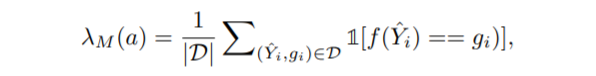
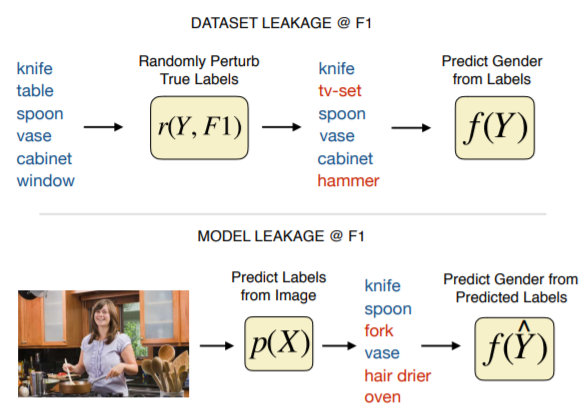
以上の2つのLeakageの算出を図解にしたのが下図です。
Bias amplification
2つのLeakageの差異を、Bias amplification$\Delta$と定義しています。
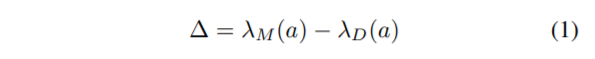
$\Delta$は、データセット$D$のせいではないバイアス(それはモデル$M$によってもたらされた)を評価する指標です。
本論文の主張は、このBias amplificationは、想像よりもかなり大きいですよ! というもので、そのことを実験を通じて説明しています。
実験
まず、何も考えずにモデルを構築してしまうと、Bias amplificationはこんなに大きくなってしまいますよ、ということを示します。その後、Adversarial Debiasingによって、このBiasを低減させることができますよ、ということを示しています。
実験は、MSCOCOデータセットと、imSituデータセットで行っています。
LeakageとBiasの評価
最初に、結果である下の表を見てみましょう。
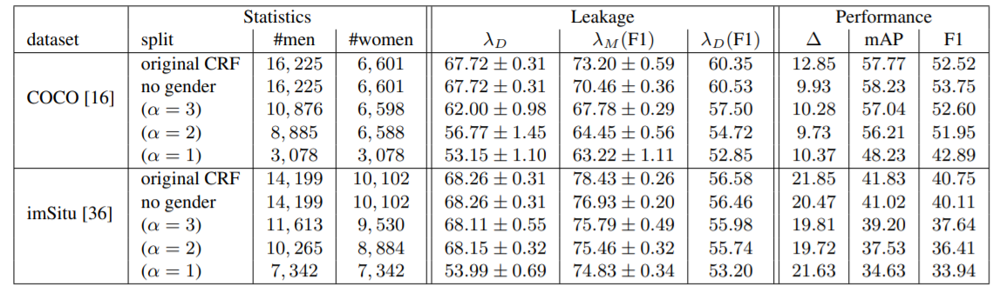
ベースラインとなる手法(original CRF)は、性別も予測できるように訓練していますが、「no gender」は性別を予測しないように訓練しています。
また、DatasetLeakageが小さくなるようにデータセット内のバランスを調整したケース($\alpha=3, 2, 1$)でも評価しています。
$\alpha$は、ラベルと性別のバランスを調整するためのパラメータで、下式のように使われます。#(m,y), #(w,y)は、それぞれ男性・女性とラベル$y$の共起の数を表しています。つまり、$\alpha=1$のとき、完全にバランスがとれたデータセットになっていると言えるというわけです。
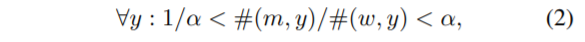
予測から性別を外すと、$\Delta$は少し小さくなりますが、$\alpha$を小さくしてラベルと性別のバランスを整えても、$\Delta$は横ばいのままです。そして、精度(mAP/F1score)は徐々に下がっていきます。
この結果から、DatasetLeakageが少なくなるようにラベルと性別のバランスを調整していても、Bias amplificationは大きいままだった、という結論を出しています。
Adversarial Debiasing
このようなBiasを軽減するために、Adversarial Debiasingと呼ばれる一連の手法が提案されています。以前、別の記事で紹介したLearning Not to Learnという手法も、その一つです。
基本的なアイディアは、画像から得られる特徴量によってラベルは予測できるようになってほしいが、性別は予測できてほしくない、という考えです。そのため、ラベルを予測しようとする分類器とは別に、性別を予測する敵対的(Adversarial)な分類器が訓練されます。
下図は、Adversarial Debiasingのやり方の一つである、adv@imageのアーキテクチャです。
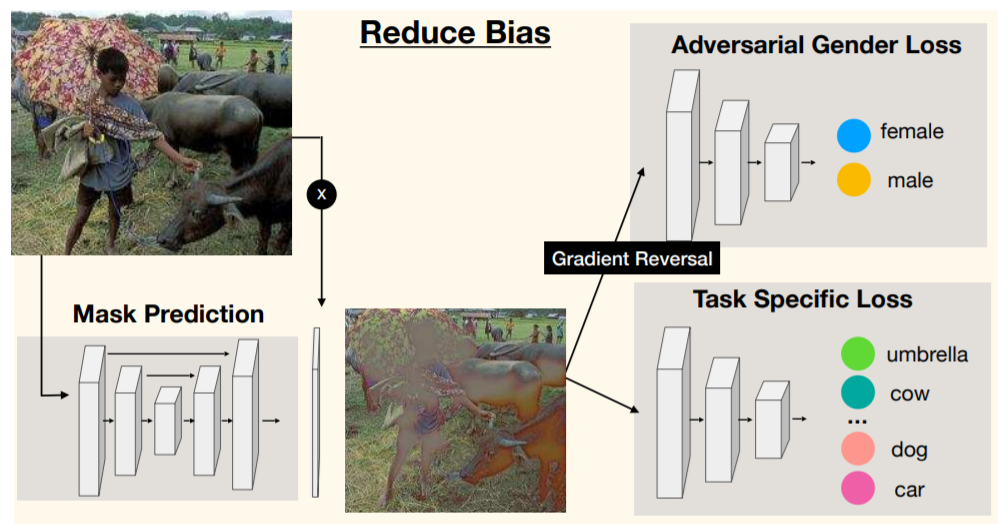
2つの分類器の片方は、敵対的な分類器で、GANの枠組みで言うところの、Discriminatorのような立ち位置です。GANに慣れた方は、ラベル分類ができつつも、性別分類器を騙せるようなマスク画像生成をできるようにネットワーク全体を訓練する、というふうに考えるとわかりやすいでしょう。
なお、「GradientReversal」は、勾配の符号をこの前後で反転させる、という手法です。これにより、Adversarial Gender Lossから計算される勾配は、性別分類器が性別を分類できるような方向に、Mask Predictionは性別分類ができにくくなる方向に計算されます。これにより、GANで一般に言われる「GeneratorとDiscriminatorを交互に訓練する」という必要がなくなります。
閑話休題。本論文では、前述のデータセットのバランスを取る方法や、人物の一部や全体を塗りつぶしたりぼかしたりすることで性別をわかりにくくする方法、adversarial debiasingの方法を比較しています。
adversarial debiasingの方法として以下の3つを検討しています。
- adv@image:ResNet18で性別を分類できないようにしながら、ResNet50でラベルを分類できるようにするための、入力画像に適用するマスクを出力できるU-Netを訓練します。
- adv@conv4:ResNet-50のconv4から得られる特徴量マップに対してラベル分類器と敵対的な性別分類機を接続しています。
- adv@conv5:ResNet-50のconv5から得られる特徴量マップに対してラベル分類器と敵対的な性別分類機を接続しています。
論文をざっと読んだ程度では、adv@conv4とconv5では、Mask予測は行っていないようにも読み取れましたが、別に行っても良いでしょう。
また、randomizationと呼んでいる比較手法では、ベースラインとなるモデルに対して、全結合層の直前のレイヤーに対してガウシアンノイズを加えることで、バイアスを抑えられないかを検討しています。もちろん、ノイズが大きければ大きいほど、分類精度は下がっていきます。
下のグラフは、各手法に対して、横軸Bias amplification、縦軸F1scoreをプロットしたものです。
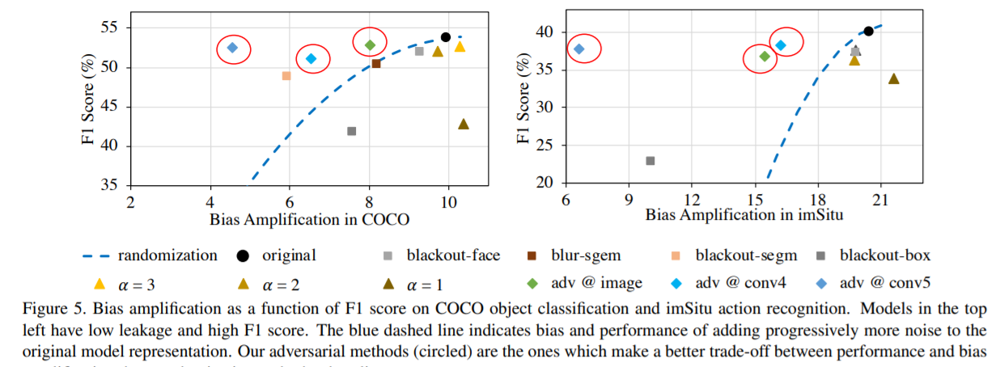
Adversarial Debiasingを行うことで、精度を維持しつつも、Bias amplificationを低くすることに成功していることが読み取れます。
ちなみに、adv@imageでは、Mask予測を行うので、どの部分がGenderに関係すると判断され、塗りつぶされたのかが可視化できます。

まとめ
Bias amplificationという指標を提案した論文について紹介しました。
Adversarial Debiasingは、情報理論的な定式化がなされることもありますが、本論文ではあまりそこに踏み込まずに、シンプルでわかりやすい指標を提案しています。