概要
人間の姿勢推定モデルとして不動の地位を確立しているOpenPoseの論文を読んだので、今更ですが解説します。最近PyTorchで実装もしてみたので、そのへんの気づきも盛り込んだ記事にしています。
OpenPoseは、3つのチャレンジを実現した手法です。
- 不特定多数の人物に対応
- 人物間の干渉に頑健
- 人物が増えてもリアルタイム実行
人間の姿勢推定には大きく分けてトップダウンとボトムアップのやり方があります。
トップダウンのやり方は、まずは人の検出を行い、その検出矩形内でキーポイント(鼻や目、耳、肩といった人間の関節や、わかりやすいポイント)を見つける、という方法です。このやり方は、例えばMask R-CNNをベースにしたやり方が知られており、torchvisionなどではpretrainedモデルがすぐに使えるようになっています。トップダウンのやり方は、直感的にわかりやすい方法ですが、人の数が増えてきたときに人数分の処理が増えてしまうという欠点があります。
一方で、ボトムアップのやり方は、画像からまずはキーポイントの候補を見つけ出し、それらを各人物ごとにマージしていく、というやり方です。このやり方は、マージの計算速度が人数に依らずある程度一定であるという条件をクリアできさえすれば、人数に依らない安定した推論速度が可能となります。もちろん、どのようにキーポイント候補をマージするのか、というアルゴリズム上の課題があります。OpenPoseは、このボトムアップのやり方の1つです。
なお、この記事におけるOpenPoseとは、OSSとして公開されているものではなく、元論文で提案された手法としてのOpenPoseです。ライブラリの使い方のような話題は書いていないのでご注意ください。
以下のような順序で説明していきます。
- モデル:モデルの構造と入出力について
- データの前処理:訓練処理におけるターゲットの作成方法について
- 損失関数:損失関数について
- 推論処理(後処理):モデル出力の後処理について
※細かい訓練手順(OptimizerやScheduler)などは、今後ひまなときに追記するかもしれません。
書誌情報
- Cao, Z., et al. "Realtime multi-person 2d pose estimation using part affinity fields. CoRR abs/1611.08050." arXiv preprint arXiv:1611.08050 (2016).
- Cao, Zhe, et al. "OpenPose: realtime multi-person 2D pose estimation using Part Affinity Fields." arXiv preprint arXiv:1812.08008 (2018).
モデル
モデルについて説明していきます。
まずは入出力について説明し、その後、具体的なアーキテクチャについて説明します。
入出力
モデルへの入力はRGB画像です。出力は2つのマップで、ConfidenceMap(以下、CMap)とPartAffinityFields(以下、PAFs)です。それぞれ、キーポイントの数$K$、キーポイント同士をつなぐエッジの数$E$とすると、各マップのサイズは、$K \times H \times W$と$2E \times H \times W$となります。
一例をお見せすると、一番左の入力画像を入力すると、CMapとして左から2, 3番目のようなヒートマップを出力し、残りの2つのようなPAFsを出力します。

左から2番めは右肩を表すヒートマップで、3番めは右肘を表すヒートマップです。また、残りの2つは、どちらも右肩と右肘をつなぐエッジを表現したPAFsです。PAFsは、一つのエッジあたり、2つのチャネルを使用して表現しますが、この2つのチャネルには、右肩から右肘への方向を表す、単位ベクトルが格納されています。右から2番めの画像は、右肩から右肘への単位ベクトルのx成分、一番右の画像は、単位ベクトルのy成分が格納されています。緑は0を、黄色は1を表し、青は-1を表します。この例では、単位ベクトルの成分がすべて正の値をとっていますが、そうでないケースもあります。
アーキテクチャ
俗にOpenPoseと呼ばれる手法には、論文が2バージョンあり、1つは2016年に発表されたもの、もうひとつは2018年に発表されたものです。
2つの論文の最も大きな違いは、ネットワークアーキテクチャにあります。以下の図の上は、2016年のバージョンで、下は2018年のバージョンです。
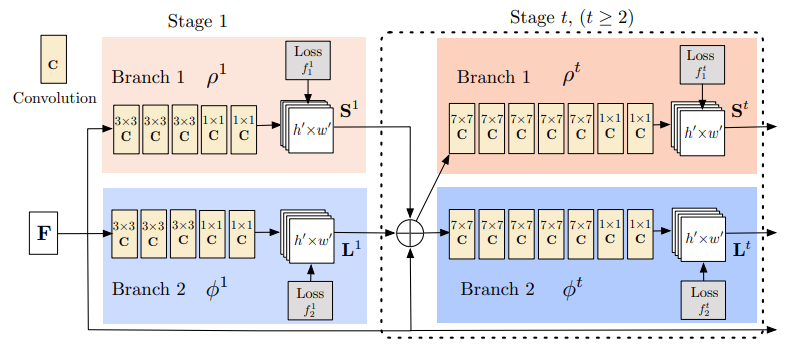
2016年版ではCMapとPAFsを同時に、再帰的に洗練させていくようなイメージで推論されます。
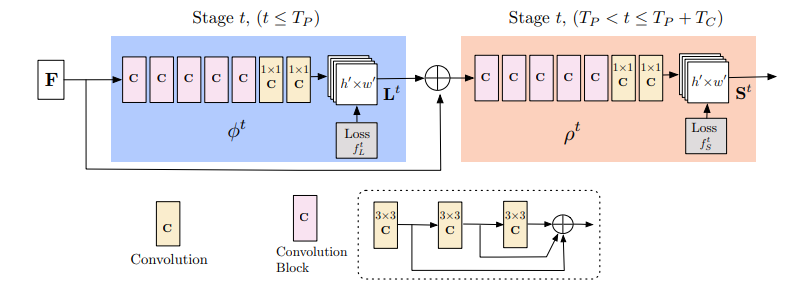
一方で、2018年版では、先にPAFsを洗練させ、それを元にCMapを推論する、という流れになっています。また、2018年版は、よく見るとResidualな構造を持ったConvolutionBlock(ピンクのボックス)が取り入れられており、よりリッチな構造になっています。
以降は2018年版について説明していきます。
図中の$F$と表現されている最初の入力となっている情報は、VGG19で抽出された特徴量マップです。この$F$は、推論のステージの各段階で毎回入力されます。
まず、PAFsを洗練するブロックについて説明します。このブロックの最初のステージでは、入力は$F$のみで、PAFs$P_1$を出力します。2段目以降のステージ$t$では、$F$と$P_{t-1}$をともに入力し、PAFs$P_t$が出力されます。これによって、今までのステージで洗練されたPAFsと元の画像特徴である$F$をともに参照しながら、徐々にPAFsを洗練させていく、という処理を行います。
次に、CMapを洗練するブロックについて説明します。このブロックの最初のステージでは、$F$とPAFsの最終結果$P_{T_P}$が入力され、CMap$C_1$が出力されます。そして、2段目以降のステージ$s$では、$F, P_{T_P}, C_{s-1}$が入力され、$C_s$が出力されます。こちらも同様に、CMapが徐々に洗練されていくイメージです。
以上のような推論処理の結果、各ステージで得られたPAFs, CMapというのが最終結果として得られます。これらにはそれぞれ、損失が設定されており、この損失を通じてネットワークを訓練していきます。
論文では、PAFsのブロックは5ステージ、CMapのブロックは1ステージのとき、最も良い結果が得られたと実験的に示されています。
データの前処理
CMapやPAFsのターゲットを、データセットからどのように作るのかを説明します。
通常、人間の姿勢推定のデータセットには、入力画像と人間のキーポイントの組が人数分用意されているわけですが、ここからCMapとPAFsのターゲットを作成する必要があります。
例えば、MSCOCOに、Keypointsというタスクが用意されています。MSCOCOでは、以下の17点がキーポイントとして用意されています。
- 鼻
- 左目
- 右目
- 左耳
- 右耳
- 左肩
- 右肩
- 左肘
- 右肘
- 左手首
- 右手首
- 左尻
- 右尻
- 左膝
- 右膝
- 左足首
- 右足首
この17点だけではなく、必要に応じて、例えば左肩と右肩の中点から「首元」といったキーポイントを作ることもできます。OpenPoseの論文で使用しているデータセット(MPII Multi-Person Dataset)では、別のキーポイントが定義されています。
また、どのキーポイント間をエッジとしてPAFsの推論対象とするのかは、定義次第です。
今回は、MS COCOをベースに話を進めていきます。
CMapのターゲットの設定
まず、キーポイントのターゲットをどう作るかについて説明します。MS COCOでは、各キーポイントの画像における座標が用意されています。ここからCMapを作るために、キーポイントの座標を中心としたガウス分布風のヒートマップ$\mathbf{S}_{j, k}^{*}(\mathbf{p})$を下式で作成します。
\mathbf{S}_{j, k}^{*}(\mathbf{p})=\exp \left(-\frac{\left\|\mathbf{p}-\mathbf{x}_{j, k}\right\|_{2}^{2}}{\sigma^{2}}\right)
ここで、$j$はキーポイントのインデックス、$k$は画面に写っている人物のインデックスを表します。
$\mathbf{p}$がキーポイントの座標を表す2次元ベクトル、$\mathbf{x}_{j, k}$はCMapの座標を表す2次元ベクトルです。これにより、CMapの座標とキーポイントの座標が完全に一致するときには1となり、キーポイントから離れた場所では0に漸近するヒートマップを作ることができます。
また、複数の人物が写っている場合は、あるキーポイントに対応するヒートマップをそれぞれ算出し、maxを取ります。
\mathbf{S}_{j}^{*}(\mathbf{p})=\max_{k} \mathbf{S}_{j, k}^{*}(\mathbf{p})
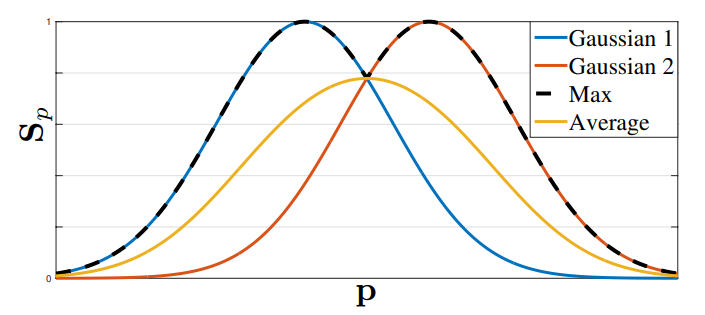
断面図的に横から見ると、以下の図のようになります。最終的にCMapのターゲットとして使われるのは、黒い点線部分です。
PAFsのターゲットの設定
続けて、PAFsのターゲットの作成方法を説明します。PAFsは先にも述べたとおり、あるキーポイントからあるキーポイントへの方向を表す単位ベクトルを、2チャネルのマップに埋め込んだものです。
しかし、どこにでも同じ単位ベクトルを埋めるわけではなく、エッジに近い場所にのみ埋め込みます。
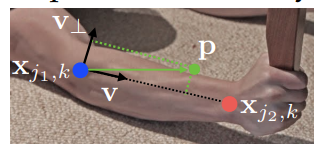
以下は、右肘から右手首までの方向を表す単位ベクトル$\mathbf{v}$が得られているときのPAFsターゲットを説明するための図です。下の数式と併せてご確認ください。
\mathbf{L}_{c, k}^{*}(\mathbf{p})=\left\{\begin{array}{ll}
{\mathbf{v}} & {\text { if } \mathbf{p} \text { on limb } c, k} \\
{0} & {\text { otherwise }}
\end{array}\right.
「もしも$\mathbf{p}$が$k$番目の人の$c$番目のエッジ(limb)の上にあるのであれば、単位ベクトル$\mathbf{v}$が格納される」という式です。何をもって「limbの上にある」と定義しているのかというと、以下のような式を満たしているとき、と定義されています。
0 \leq \mathbf{v} \cdot\left(\mathbf{p}-\mathbf{x}_{j_{1}, k}\right) \leq l_{c, k} \text { and }\left|\mathbf{v}_{\perp} \cdot\left(\mathbf{p}-\mathbf{x}_{j_{1}, k}\right)\right| \leq \sigma_{l}
つまり、始点となるキーポイントからの距離がエッジの長さ$l_{c, k}$を超えず、逆方向を向いていないこと(1つ目の条件)、エッジへの距離が十分に近いこと(2つ目の条件)という2つの条件を満たしていれば、limbの上にある、という条件となります。
複数人のエッジがある場合は、PAFsのターゲットを足し合わせ、その座標にPAFsを持っている人数$n_{c}(\mathbf{p})$で割ります。
\mathbf{L}_{c}^{*}(\mathbf{p})=\frac{1}{n_{c}(\mathbf{p})} \sum_{k} \mathbf{L}_{c, k}^{*}(\mathbf{p})
以上のように、CMapとPAFsのターゲットを作ると、冒頭に示したようなヒートマップが得られます。
損失関数
PAFsにも、CMapにも、同様の損失関数が定義されています。
\begin{aligned}
&f_{\mathbf{L}}^{t_{i}}=\sum_{c=1}^{C} \sum_{\mathbf{p}} \mathbf{W}(\mathbf{p}) \cdot\left\|\mathbf{L}_{c}^{t_{i}}(\mathbf{p})-\mathbf{L}_{c}^{*}(\mathbf{p})\right\|_{2}^{2}\\
&f_{\mathbf{S}}^{t_{k}}=\sum_{j=1}^{J} \sum_{\mathbf{p}} \mathbf{W}(\mathbf{p}) \cdot\left\|\mathbf{S}_{j}^{t_{k}}(\mathbf{p})-\mathbf{S}_{j}^{*}(\mathbf{p})\right\|_{2}^{2}
\end{aligned}
$C$はエッジの数、$J$はキーポイントの数、を表します。基本的には、各ステージで得られたPAFsやCMapとターゲットとなっているPAFsやCMapを比べて2乗誤差を取るというものです。これをマップ中の全座標に対して足し合わせることで損失が得られます。
気になるのが$\mathbf{W}(\mathbf{p})$で、これは、いかなるアノテーションもされていない座標では0、何らかのアノテーションがついている座標は1にするというマスクです。人のキーポイント検出のデータセットでは、しばしば、オクルージョンなどのせいで「見えていないけれど存在する」のでキーポイントとしてアノテーションするか迷ってしまったのかなというデータや、画像中に写っている人物が多すぎて、そのうちの少人数にしかアノテーションしていないようなデータがたまに含まれています。そのようなノイジーなデータでは、本当はキーポイントで、推論結果もそうなっているにも関わらず、ターゲットが間違っている、という事態が生じてしまいます。そのため、何らかのアノテーションがされている場所のみをマスクする必要がある、というわけです。
最終的な損失関数は、全ステージでのPAFsやCMapの推論結果に対する損失が足し合わされたものとなります。
$f=\sum_{t=1}^{T_{P}} f_{\mathrm{L}}^{t}+\sum_{t=T_{P}+1}^{T_{P}+T_{C}} f_{\mathrm{S}}^{t}$
推論後の後処理
PAFsとCMapが得られた後はどのような処理をするのか、ということを確認していきます。一部、論文で省略されている部分もあるので、実装時はこうしましたよ、ということを記載しています。
CMapのNMS
CMapのNMSは、論文中ではきちんと説明されていません(見落としていたらごめんなさい)。基本方針は以下のとおりです。
- しきい値を定め、それ以下の点は取り除く
- CMapの局所極大点を探す
2つ目の局所極大点については、1ピクセルずらしたCMapを用意し、それらとの比較をすることで簡単に見つけることができます。
例えば、以下のように実装できます。
cmap_y1 = torch.zeros(cmap.shape)
cmap_y1[:, :, :-1, :] = cmap[:, :, 1:, :]
cmap_x1 = torch.zeros(cmap.shape)
cmap_x1[:, :, :, :-1] = cmap[:, :, :, 1:]
cmap_y2 = torch.zeros(cmap.shape)
cmap_y2[:, :, 1:, :] = cmap[:, :, :-1, :]
cmap_x2 = torch.zeros(cmap.shape)
cmap_x2[:, :, :, 1:] = cmap[:, :, :, :-1]
peak_map = (
(cmap > threshold)
& (cmap >= cmap_y1)
& (cmap >= cmap_x1)
& (cmap >= cmap_y2)
& (cmap >= cmap_x2)
)
peak_mapには、局所極大点のみがTrueとなったマップが与えられます。これから具体的な座標を取り出すには、以下のようにtorch.whereを使うと良いでしょう。
torch.where(peak_map)
PAFsの後処理
NMSによって、キーポイントの推論結果が得られました。ここから、各キーポイントの候補同士をつなぐエッジを、PAFsの推論結果を手がかりに推定していきます。
手順としては以下のとおりです。
- キーポイント間のエッジ候補に対するスコア(スコア行列)を計算する
- スコア行列を元に、2部グラフ問題を解きながら人物ごとにマージする
以下、詳細を示します。
スコア行列
PAFsは、キーポイント間の方向を表す単位ベクトルでした。そのため、例えば右肩のキーポイント候補が3個、右肘のキーポイント候補が5個得られていたとして、エッジの候補は3x5通り考えられます。そのエッジ候補全てに関してスコアを算出します。
スコアの算出の考え方は単純で、「PAFsが示している方向」と「エッジ候補の方向」が一致しているほど高スコアになる、というものです。というわけで、PAFsのベクトルとエッジ候補のベクトルの内積を取れば良いことになります。ただし、エッジ候補のベクトルは、正規化し単位ベクトルにする必要があります。
論文中では、このスコアは下式で表されます。
E=\int_{u=0}^{u=1} \mathbf{L}_{c}(\mathbf{p}(u)) \cdot \frac{\mathbf{d}_{j_{2}}-\mathbf{d}_{j_{1}}}{\left\|\mathbf{d}_{j_{2}}-\mathbf{d}_{j_{1}}\right\|_{2}} d u
$\mathbf{p}(u)$は、エッジ候補上に存在する補間点です。実際にはこのような積分ではなく、いくつかの点についてサンプルし、足し合わせることになります。
E=\sum_{n=1}^{N-1} \mathbf{L}_{c}(\mathbf{p}(\frac{n}{N})) \cdot \frac{\mathbf{d}_{j_{2}}-\mathbf{d}_{j_{1}}}{\left\|\mathbf{d}_{j_{2}}-\mathbf{d}_{j_{1}}\right\|_{2}}
$\mathbf{p}(u)$はPAFsのサブピクセルレベルの座標となることがほとんどですので、実装時は、torch.nn.functional.grid_sampleを使ってサンプルしました。
グラフのマージ
以上のようにして、人物のキーポイント候補とそのキーポイントをつなぐエッジ候補のスコアが得られました。ここまでくれば、直感的にどのキーポイント同士をつなげればいいのかわかりそうなものですが、実際にはこのような問題を解くのは難しく、NP完全問題となるそうです。
問題を理解するために、下図を御覧ください。
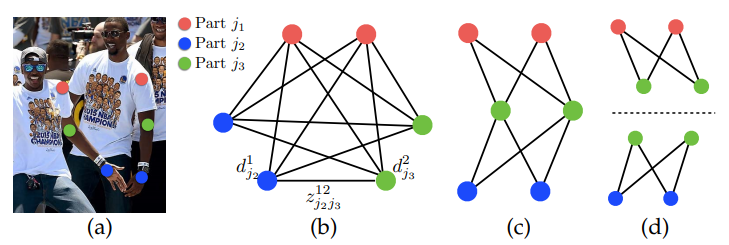
左肩・左肘・左手首がそれぞれ2つキーポイント候補として検出された場合について考えます。まず、理想的には、(b)のように左肩と左肘、左肘と左手首、左肩と左手首という全組み合わせについて、それぞれのエッジのスコアを算出し、各キーポイント候補がどの人物に割り当てられるのかを計算したいと考えます。しかし、これを解くのは困難なので、まずはエッジの定義にしたがって、左肩->左肘、左肘->左手首というエッジだけを考えれば良い、とします(c)。そして、ここが大胆な簡略化になりますが、左肩->左肘の最適なエッジの選択と、左肘->左手首の最適なエッジの選択は、分けて実施することにし、後でマージすることにします(d)。
このような簡略化を行うと、解くべき問題は、(d)のような二部グラフの割当問題を何個か解いて、その結果をマージする、という手順に落ち着きます。二部グラフの割当問題は、ハンガリアンアルゴリズムで解くことができます。ハンガリアンアルゴリズムは、scipyでscipy.optimize.linear_sum_assignmentとして実装されていますので、活用しましょう(入力として「コスト」行列を期待されているので「スコア」行列を入力する場合は、正負を反転させましょう)。
次に、マージの手順ですが、2018年版の論文ではややぼんやりしています。一応、私が実装したときの疑似アルゴリズムを書いておきます。
- スコア行列の中から最もスコアの高いエッジ候補を含む二部グラフを選択
- そのスコアがしきい値よりも小さいなら
- 全体の処理を終了
- そのスコアがしきい値以上なら
- 二部グラフ問題を解き、スコアのしきい値を適用し、複数のエッジ候補を得る。
- 得られたエッジ候補すべてについて
- エッジ候補を構成するキーポイント候補の両方が、いかなる既存の人候補でも使用されていない場合
- 新しい人候補を作成する。キーポイント候補に関わるスコア行列の要素を0にする。
- エッジ候補を構成するキーポイント候補の片方または両方が、1つの人候補ですでに使用されている場合
- その人候補にエッジ候補をマージする。キーポイント候補に関わるスコア行列の要素を0にする。
- エッジ候補を構成するキーポイント候補が、2つの人候補にまたがっている場合
- 2つの人候補間でいかなる競合もない場合
- エッジ候補と併せてマージする。キーポイント候補に関わるスコア行列の要素を0にする。
- 2つの人候補間で競合がある場合(例:相異なる「鼻」のキーポイント候補がすでに登録されている)
- エッジ候補は棄却する。対応するスコア行列の要素のみを0にし、二部グラフの選択からやり直す
- 2つの人候補間でいかなる競合もない場合
- エッジ候補を構成するキーポイント候補の両方が、いかなる既存の人候補でも使用されていない場合
- 二部グラフ選択へ戻る
- そのスコアがしきい値よりも小さいなら
と、なかなか頑張ってマージします。
ここらへんは結構for文でガリガリ書いていく感じなので、numbaとかで高速化すると良いかもしれません。
おまけ:エッジの定義には気をつけたほうがいい
のちのちPAFsの推論結果を元に、各人間ごとにマージしていくことを考えると、エッジの定義を決める際は、単一障害ポイントを設けないことに注意する必要があります。例えば、MS COCOの17個のキーポイントに対して、鼻を中心に、
- 鼻->目->耳
- 鼻->肩->肘->手首
- 鼻->肩->尻->膝->足首
といったエッジを左右それぞれ定義したとします。このとき、たまたま鼻がキーポイントとして検出できなかったという場合、仮に他のすべてのキーポイントのCMapとエッジのPAFsが正しく推論できていたとしても、その人物の各キーポイントがマージできないことがわかります。
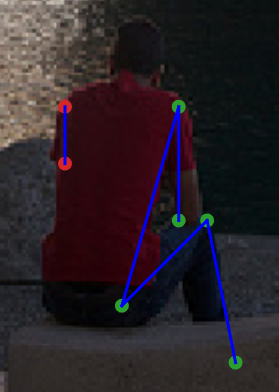
以下の画像を御覧ください。これはあるMS COCOの検証用画像の一部を切り抜いたもので、上に挙げたエッジの定義を用いて推論結果をマージしたものです。同一人物の中に、グラフが2つ検出されていることがわかります。人物が後ろを向いており、鼻が検出できていないことが最大の問題で、鼻を介してのみ接続可能な人物の左肩と右肩が接続されず、他の推論結果は合っているのにも関わらず同一人物としてマージできない、という残念な結果になっています。
皆様におかれましては、こういう失敗を招かないように、エッジの定義には十分ご注意ください。
まとめ
OpenPoseの論文を読んで、簡単にまとめてみました。また、実装時にちょっと大変だったポイントなども説明しました。
姿勢推定のような構造出力を行う深層学習モデルは、深層学習部分と後処理の部分の組み合わせが必要なことが多いです。普段なじみのない最適化アルゴリズムなどに触れるいい機会だなあと思います。