概要
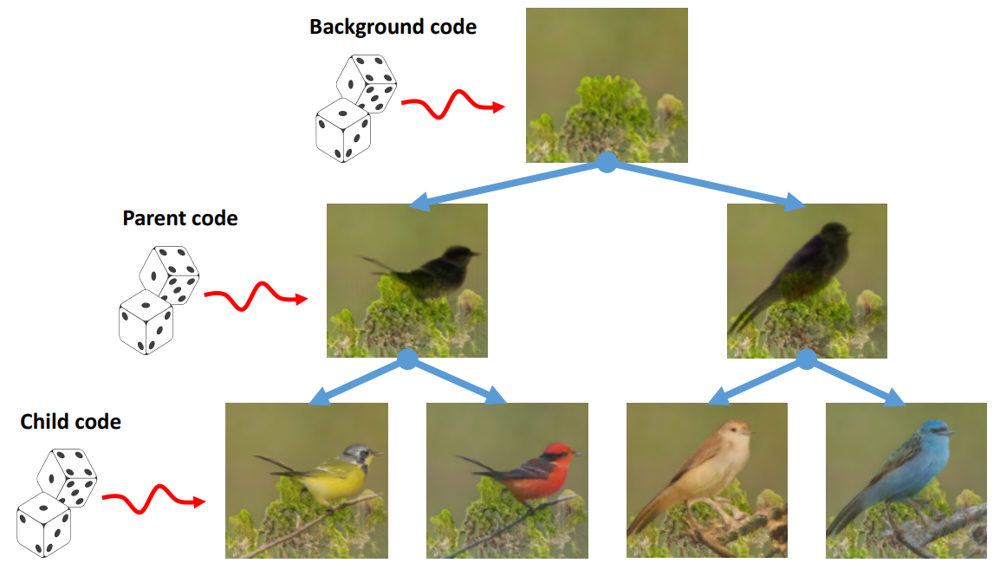
条件つき画像生成モデル MixNMatch を紹介します。どのような手法なのか、以下の図がわかりやすいのでこれを元に説明します。

上図の最初の 4 段の画像は、それぞれ Shape(形状)/Pose(姿勢)/Texture(色・模様)/Background(背景)を条件つけるための入力画像です。これらの入力画像から、最下段の合成画像が生成されます。この合成画像は、入力画像で指定された 4 つの因子を見事に反映した画像になっていることが確認できます。
例えば、一番右の列では、以下のような条件が指定されています。
- Shape:小さくて太い鳥の画像
- Pose:右を向いている鳥の画像
- Texture:ベースが黄色で、やや黒が混じっている鳥の画像
- Backgroud:砂地にいる鳥の画像
これらの条件に対して、「小さくて太い」「右を向いている」「ベースが黄色で、やや黒が混じっている」「砂地」にいる鳥の画像が合成されていることが確認できます。
このように、Shape/Pose/Texture/Background という要素を画像によって条件づけて新しい合成画像を生成する、というのがこの手法で実現していることです。必要なアノテーションは前景物体領域を表すバウンディングボックスのみで良く、その他の教師データの整備は不要です。
以下、ベースとなっている FineGAN という手法とともに、説明していきます。
書誌情報
- Li, Yuheng, et al. "MixNMatch: Multifactor Disentanglement and Encodingfor Conditional Image Generation." arXiv preprint arXiv:1911.11758 (2019).
- 公式実装(PyTorch)
ベース手法:FineGAN
本手法のベースとなっている FineGAN1について説明します。FineGAN は MixNMatch と同様に条件付きの画像生成モデルですが、与えられる条件は画像ではなく、潜在的なコードです。
この章では、FineGAN の元論文中の画像を引用して説明します。
推論の流れ
下図は FineGAN の生成モデルの枠組みを表しており、Background/Parent/Child という 3 階層の構造になっています。Background code が背景を、Parent code が形状と姿勢を、Child code が模様を生成するという階層的な生成過程を表しています。
より詳細な推論の過程を表したのが以下の図です。Background/Parent/Child という 3 段階の Stage があります。
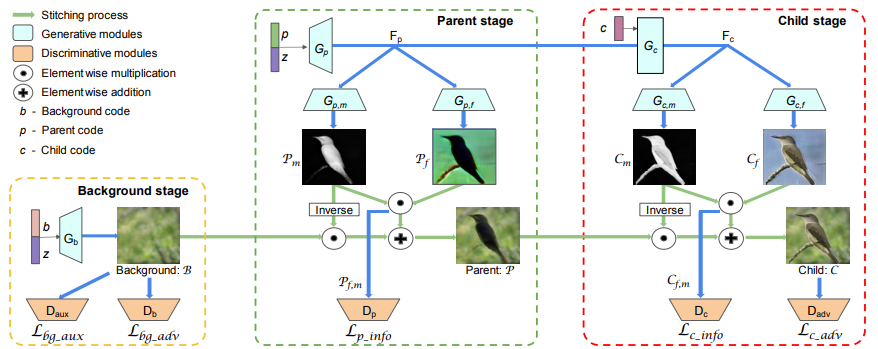
生成結果は 4 つの潜在変数$b, p, c, z$によって制御されています。$z$は連続値ですが、$b, p, c$は離散値です。
- Background stage では$b, z$によってベースとなる背景画像$\mathcal{B}$が生成されます。
- Parent stage では$p, z$を用いて、形状($p$によって表現される)と姿勢($z$によって表現される)が決められ、マスク$\mathcal{P_m}$と前景画像のベースとなる$\mathcal{P_f}$を生成します。マスクは背景画像$\mathcal{B}$と前景画像のベース$\mathcal{P_f}$をブレンドするのに使われ、Parent 画像$\mathcal{P}$が得られます。
- Child stage では、Parent stage で得られた特徴量に$c$も加えて、物体領域マスク$\mathcal{C_m}$と物体の細部を描いた$C_f$を生成します。Parent stage と同様、マスク$\mathcal{C_m}$を用いることで、Parent 画像$\mathcal{P}$と物体の細部を描いた画像$C_f$をブレンドします。
コード間の制約
FineGAN では、2 つのコード間の制約を設けています。
- 親コード$p$と子コード$c$の間には、明確な親子関係を設定します。親コードのカテゴリ数を子コードのカテゴリ数よりも少なくし(Np < Nc)、各親コード$p$に対して一定数の子コード$c$を紐付けます。これは、親コードが大雑把な物体カテゴリを表しており、子コードが詳細な物体カテゴリを表していると考えると自然な制約です。
- $b, c$の間には、$b = c$という制約を設定します。物体カテゴリと背景には強い相関があります。これを表現するために、背景コード$b$と子コード$c$が完全に連動するという制約を設けています。
このような制約は、訓練時のみ適用されます。
損失関数
各ステージでいくつかの損失関数が設定されています。いずれの損失関数も PatchGAN の枠組みで算出されています。
Bacground stage
まず、リアルな背景画像を生成するために、よくある形の敵対的損失を考えます。
$\mathcal{L}_{bg-adv}=\min _{G_{b}} \max _{D_{b}} \mathbb{E}_{x}\left[\log \left(D_{b}(x)\right)\right]+\mathbb{E}_{z, b}\left[\log \left(1-D_{b}\left(G_{b}(z, b)\right)\right)\right]$
また、事前に訓練した前景・背景分類器$D_{aux}$を用いて、以下のような補助損失$\mathcal{L}_{bg-aux}$を算出します。$D_{aux}$の教師データは、唯一のアノテーションである前景領域を表すバウンディングボックスを元に作成されています。
$\mathcal{L}_{bg-aux}=\min _{G_{b}} \mathbb{E}_{z, b}\left[\log \left(1-D_{aux}\left(G_{b}(z, b)\right)\right)\right]$
Parent stage
Parent stage では 1 つの損失関数が設定されています。この損失関数は、相互情報量$I(p;\mathcal{P_{f, m}})$を最大化するという InfoGAN 的な枠組みを採用しています。$\mathcal{P_{f,m}}$は、マスク$\mathcal{P_m}$と前景物体のベースとなる$\mathcal{P_f}$の要素積から得られます。
$\mathcal{L}_{p}=\mathcal{L}_{p_{info}}=\max_{D_{p}, G_{p, f}, G_{p, m}} \mathbb{E}_{z, p}[\log D_{p}\left(p | \mathcal{P}_{f, m}\right)]$
$D_{p}$は事後確率$P(p|\mathcal{P_{f,m}})$を近似できるように訓練されます。なぜこの損失が相互情報量を最大化することになるのか、というのは、以下の式変形を見ていただければわかります。
$I(p; \mathcal{P_{f,m}}) = H(p) - H(p|\mathcal{P_{f,m}}) = H(p) + \mathbb{E}_{z,p}[\log P(p|\mathcal{P_{f,m}})]$
$H(p)$は定数なので、上式の最大化の中では無視されますので、最大化の対象は$\mathbb{E}_{z,p}[\log P(p|\mathcal{P_{f,m}})]$のみになります。$D_{p}$は$P(p|\mathcal{P_{f,m}})$を近似できるように訓練されるので、最大化の対象は$\mathbb{E}_{z,p}[\log D_p(p|\mathcal{P_{f,m}})]$となります。
Child stage
Child stage では 2 つの損失関数が設定されています。片方は敵対的損失で、もう片方は相互情報量$I(c;\mathcal{C}_{f, m})$を最大化するものです。
$\mathcal{L}_{c-adv}=\min _{G_{c}} \max _{D_{adv}} \mathbb{E}_{x}\left[\log \left(D_{adv}(x)\right)\right]+\mathbb{E}_{z, b, p, c}\left[\log \left(1-D_{adv}(\mathcal{C})\right)\right]$
$\mathcal{L}_{c-info}=\max _{D_{c}, G_{c . f}, G_{c . . m}} \mathbb{E}_{z, p, c}\left[\log D_{c}\left(c | \mathcal{C}_{f, m}\right)\right]$
FineGAN内のGeneratorやDiscriminatorの訓練は、以降に示す他の損失と組み合わせて、適切なタイミングで行われます。
MixNMatch
ベースとなる FineGAN の説明が終わったので、ここからは MixNMatch の説明に移ります。
最初に全体像を捉えておきましょう。
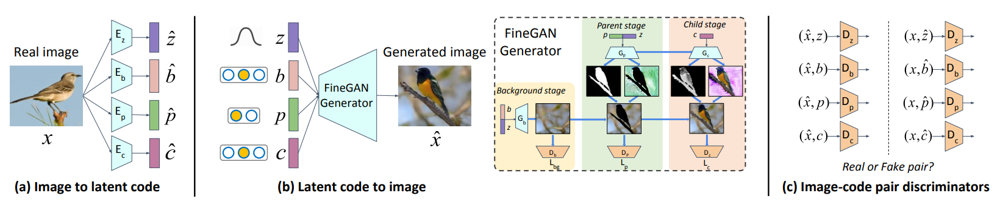
MixNMatch では実画像を条件づけに使用するため、実画像から 4 つのコード$\hat{b}, \hat{p}, \hat{c}, \hat{z}$を抽出するエンコーダー$E_b,E_p,E_c,E_z$が必要です。また、各コードに応じた Discriminator$D_b,D_p,D_c,D_z$も用意します。Discriminator は画像とある 1 つのコードを入力とし、その組み合わせが正しいか否かを判定できるように訓練されます。コードごとに個別に用意することで、FinGAN の訓練時に想定するコード間の制約をもとに真偽を判定してしまうということを回避しています。表記がかぶっていて混乱しますが、FineGAN で使用する Discriminator とは全く別に作るものなので注意しましょう。
双方向変換の損失
新たに用意された Encoder と Discriminator は、以下のような BiGAN ライクな双方向変換の枠組みで使用されます。下式の$E, D$は、$b,p,c,z$に関するものをまとめたものと考えてください。また、$G$は FineGAN の Generator を表しています。
$\mathcal{L}_{{bi-adv}} =\min _{G, E} \max _{D} \mathbb{E}_{x \sim P_{data}} \mathbb{E}_{\hat{y} \sim E(x)}[\log D(x, \hat{y})] +\mathbb{E}_{y \sim P_{\text {code}}} \mathbb{E}_{\hat{x} \sim G(y)}[\log (1-D(\hat{x}, y))]$
$P_{data}$は実データの分布、$P_{code}$はコードの分布です。コードの分布は FineGAN で使用したコード間の制約が課されているものです。
コード再構成損失
また、以下のようなコード再構成の損失も考えます。あるコード$y$をもとに Generator を用いて合成画像を生成たとき、その合成画像から Encoder によって抽出されたコードは、$y$に近くなっているべきだという損失です。
下式では CrossEntropy($CE$)と記載されていますが、連続変数である$z$については、L1 損失を使用します。なお、ここで使用するコード$y$はコード間の制約を用いてサンプルしたものと、いかなるコード間の制約も用いずにサンプルされたもの、両方を使用します。
$\mathcal{L}_{code-pred}= \min _{G,E} CE(E(G(y)), y)$
訓練手順
全体的な訓練の手順としては、各ステップごとに以下を繰り返す形で行います。
- FineGAN の Discriminator を更新
- 双方向変換の Discriminator を更新
- Encoder と FineGAN の Generator を更新
公式の実装を見てみると、更新対象のモジュールや算出する損失も多いため、少々複雑ではあります。
CodeモードとFeatureモード
いくつかのアプリケーションでは、Pose と Shape を個別にコントロールできる必要がなく、TextureとBackgroundのみを自由にコントロールしたいというケースが考えられます。そのような場合の 1 つのオプションとして、本論文では Feature モードというものを提案しています。なお、条件づけに使う画像からコードを抽出して使用する場合を Code モードと呼んでいます。
FineGAN の Generator はここではフリーズさせます。Parent stage で使用している $G_p$の推論途中で得られる特徴マップ$\phi(p, z)$を考えます。この特徴マップを直接画像から抽出するような$S$を訓練する、ということが目標となります。
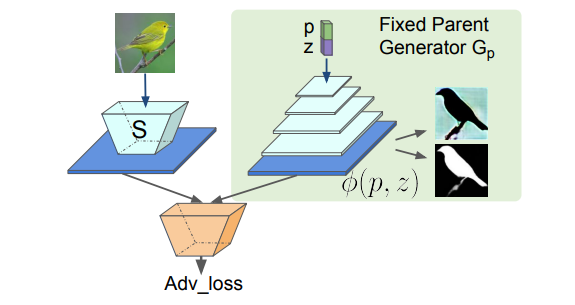
ここで、$\phi(p, z)$の分布に$S(x)$の分布を近づける GAN の問題として捉えることで$S$を訓練できます。Discriminator による判定も損失の他に、ランダムにサンプルされた$z,b,p,c$を用いて合成された画像[$ G(z,b,p,c)]から得られる特徴マップ$S(G(z,b,p,c))$と、$\phi(p, z)$の L1 距離も$S$の損失として使用します。
注意事項として、もとの FineGAN がうまくできていないとこの Feature モードのための訓練はうまくできないということが挙げられます。
Code モードと Feature モードは、甲乙つけがたい結果となりますが、Feature モードのほうがより形状を重視した結果になっていることが下の生成例から確認できます。

まとめ
以上、ざっとですが、MixNMatch について説明してみました。
Shape/Pose/Texture/Background を画像によって指定して新しい画像を合成するという本手法は、これだけでいろいろな応用があり、興味のあるドメインで訓練させればなかなか楽しめそうです。
例えば以下のように、スケッチやキャラクターの画像に対して任意の条件画像によって色付けを行うことができています。また、Pose を表す$z$をランダムウォークさせれば、それだけでアニメーション生成もできます。

本論文では鳥、犬、車が対象となっていましたが、別のドメインのデータでやってみると、意外な応用先があるかもしれません。
-
Krishna Kumar Singh, Utkarsh Ojha, and Yong Jae Lee. FineGAN: Unsupervised hierarchical disentanglement for fine-grained object generation and discovery. In CVPR, 2019. ↩