PDF/TIFF Document Text Detectionとは
Google Cloud Platform上のCloudVisionAPIという画像分析を行うAPIの中の一種。
CloudVisionAPIにはText Detection という画像のOCRの機能が存在している
類似サービス
基本的にJPG/PNG内のテキストを検出する物が多い
- Amazon Rekognition
- Azure Computer Vision
- IBM Watson: Visual Recognition
-
Tesseract OCR テッセラクトと読む。Hewlett-Packardが開発してGoogleがOSS化したもの
など。
AWSやAzureといったクラウドサービスを提供しているところでは、機能として用意されている。
あとはパナソニックが出してたりする。
なぜPDF/TIFF Document Text Detectionなのか。
- ちょうど調査しているタイミング(※2019/4月時点)でGAになった。
- Goのライブラリが存在していた。
- PDFを直接OCRできるAPIが他ではなかった (※他のAPIではJPG/PNGのOCRを行うことが主用途)
-
https://aws.amazon.com/jp/textract/
- AWSもPDFを直接OCRできるもの出してるけど日本語未対応のようだ
使うもの
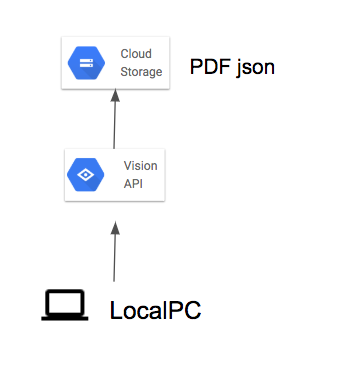
注意点
- 結果は、GCSにjson形式で出力されるので利用する際には、GCSからjsonを取得してくる必要がある。
- 割と複雑なjsonなのでGoで取り扱うのは大変だった。
ソースコード
結果
1.国土交通省: 令和元年度「年末年始の輸送等に関する安全総点検」の取組を実施します
https://www.mlit.go.jp/report/press/content/001317333.pdf
結果: https://github.com/ytakky2014/gcp-pdf-tiff-document-text-detection/blob/master/result/1.txt
問題なくOCRできている。
2.経済産業省: 生産性向上特別措置法【生産性革命法】及び産業競争力強化法等の一部を改正する法律の概要
https://www.meti.go.jp/policy/jigyou_saisei/seisanseisochihoukyoukahou/pdf/gaiyou-1.pdf
結果: https://github.com/ytakky2014/gcp-pdf-tiff-document-text-detection/blob/master/result/2.txt
段組みされているPDFでも問題なくOCR化されている
3.令和元年度 情報セキュリティマネジメント試験 午後 問題
https://www.jitec.ipa.go.jp/1_04hanni_sukiru/mondai_kaitou_2019h31_2/2019r01a_sg_pm_qs.pdf
割と長いPDFもOCR化できているし、図表内のテキストもOCRできているがさすがに試験問題だと文のみだと理解ができないところもある。
なお、jsonを一部マスクしたのもリポジトリ内においてあるのでそちらも参照。
まとめ
- PDF/TIFF Document Text Detection結構良い。すぐ使える
- GCSにさえPDFを入れておけば、GCSにファイルに出力が出るので使いやすい。
- 今回リポジトリに結果は載せなかったが、試したところ手書きした写真をPDF化したものに対して実行してもテキストを抽出できていた。
- GCPはやっぱり機械学習系に強いなと思う。これからはデータをどうやって活用していくかという時代になっていくと思うので、積極的にこのような技術を使えるようにしていきたいですね。