はじめに
threading を用いた並行処理をさせる常駐型の Python プログラムにおいて、データベースに接続する際に sqlalchemy の create_engine の使い方を間違えるとデータベース接続数が爆増してしまうので注意が必要です。本稿ではそれについて簡単に説明したいと思います。
TL;DR
以下のいずれかの方法を選択すると必要以上に接続数が増えることはないでしょう。
- create_engine() はプログラム開始時に一回だけ呼んで Engine クラスインスタンスを使い回す
- NullPool を指定してコネクションプールを使わないようにし、scoped_session でセッションを生成する
環境
以下の環境で実験しています。
| 項目名 | バージョン |
|---|---|
| OS | Ubuntu 18.04.6 LTS |
| Python | 3.10.0 |
| MySQL | 5.7.36-0ubuntu0.18.04.1 |
| SQLAlchemy | 1.4.26 |
テストコード
ディレクトリ構成
|--app
| |--worker.py
|--config
| |--database.py
|--main.py
メイン
import sys
import threading
from random import randint
from time import sleep
from concurrent.futures import ThreadPoolExecutor
from app.worker import worker
def f(t):
sleep(t)
return t
with ThreadPoolExecutor(max_workers=20) as executor:
futures = [executor.submit(f, t) for t in [randint(1,3) for _ in range(500)]]
for future in futures:
future.add_done_callback(worker)
result = [f.result() for f in futures]
ThreadPoolExecutor() で 20 個のワーカーを用意します。そして各スレッドに 1~3 秒待つだけの単純な関数を実行させます。そして callback として worker() を呼ぶように設定します。これは Google Cloud PubSub にメッセージがパブリッシュされたら非同期でサブスクライブして callback 関数を呼ぶというのを模擬するような単純な作りにしています(ローカルPCでは PubSub が使えないので苦肉の策でこんな形にしています)。
callback関数
from random import randint
from time import sleep
from config.database import get_db_session
def worker(*args):
session = get_db_session()
session.begin()
result = session.execute("SELECT * FROM users WHERE users.id = {};".format(randint(1,100)))
sleep(1)
session.commit()
後述する get_db_session() 関数でデータベースセッションを取得して、users テーブルを SELECT するだけの簡単な関数です。
get_db_session 関数
from sqlalchemy.orm import sessionmaker
from sqlalchemy.engine.url import URL
from sqlalchemy.engine.create import create_engine
username = 'USER'
password = 'PASSWORD'
hostname = 'localhost'
dbname = 'DATABASE'
url = URL.create(
drivername='mysql+mysqldb',
username=username,
password=password,
host=hostname,
database=dbname,
query={"charset": "utf8"},
)
def get_db_session():
engine = create_engine(url, pool_recycle=10)
return sessionmaker(bind=engine)()
これが問題となる箇所です。create_engine() を呼んで Engine クラスインスタンスを生成し、sessionmaker()() で生成されるセッションクラスインスタンスを返します。
データベース接続数の計測
実験1
上記プログラムを実行している傍ら、以下のシェルスクリプトを実行してデータベース接続数を計測します。
# !/bin/bash
QUERY="select count(*) from information_schema.PROCESSLIST where USER = 'USER';"
while test true
do
t=$(date +%s.%3N)
cnt=$(mysql -u root -N -ss -e "${QUERY}")
echo "${t},${cnt}"
done
下図がその結果となります。横軸が時間(単位は秒)で、縦軸が接続数です。一定間隔で約30個の接続が解消されてますが、全体として右肩上がりで接続数が増えていることがわかります。これは各スレッドが create_engine() を呼び、内部で新たに QueuePool クラスインスタンスが生成されるからだと考えられます。
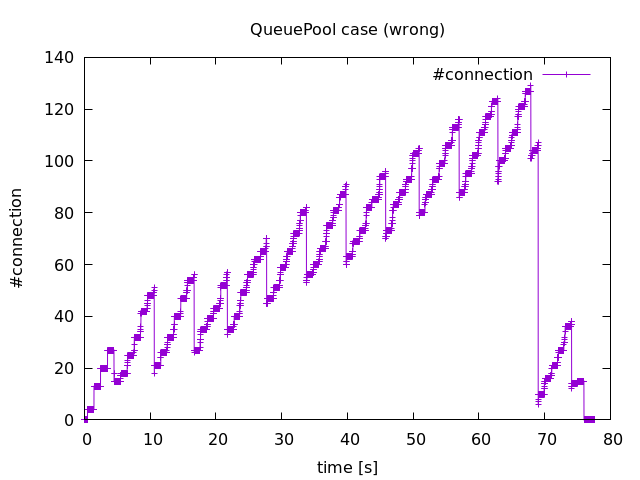
70秒付近で接続数が急激に減少している理由についてはわかりませんでした。こちら の方法を参考にして、call イベントを全てプリントさせたのですが、該当の時間帯に dispose() や close_all() といったメソッドが呼ばれた形跡はありませんでした。
実験2
database.py を以下のように修正します。つまり engine の定義をメソッドの外に出して一回しか呼ばれないようにします。
from sqlalchemy.orm import sessionmaker
from sqlalchemy.engine.url import URL
from sqlalchemy.engine.create import create_engine
username = 'USER'
password = 'PASSWORD'
hostname = 'localhost'
dbname = 'DATABASE'
url = URL.create(
drivername='mysql+mysqldb',
username=username,
password=password,
host=hostname,
database=dbname,
query={"charset": "utf8"},
)
engine = create_engine(url, pool_recycle=10)
def get_db_session():
return sessionmaker(bind=engine)()
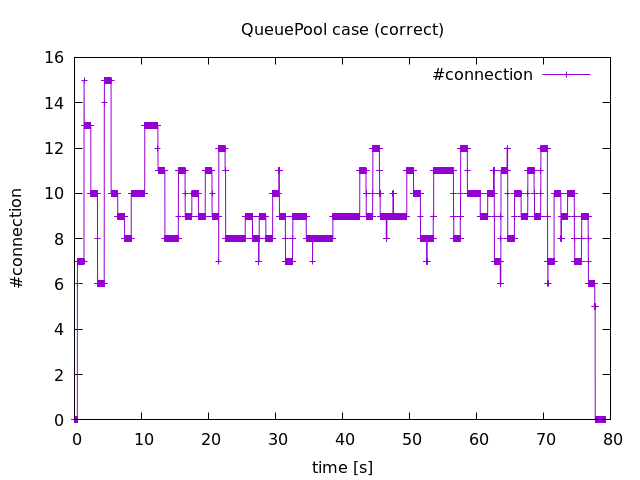
以下がこの時の結果となります。最大でも接続数は15個で収まっていることがわかります。これは QueuePool の pool_size, max_overflow のデフォルト値がそれぞれ 5, 10 であるため、15以上のコネクションが作成されないから当然の結果です。
実験3
コネクションプールを使わない方法が以下のようになります。もちろん engine が毎回呼ばれるようにする必要性はないと思いますが‥。
from sqlalchemy.orm import sessionmaker, scoped_session
from sqlalchemy.engine.url import URL
from sqlalchemy.engine.create import create_engine
from sqlalchemy.pool import NullPool
username = 'USER'
password = 'PASSWORD'
hostname = 'localhost'
dbname = 'DATABASE'
url = URL.create(
drivername='mysql+mysqldb',
username=username,
password=password,
host=hostname,
database=dbname,
query={"charset": "utf8"},
)
def get_db_session():
engine = create_engine(url, echo=True, poolclass=NullPool)
return scoped_session(sessionmaker(bind=engine))()
結果は割愛しますが、実験2と概ね同じ結果が得られます。ただし接続数の時間変化は激しくなります。
この実験の動機
もともとは次のようなアプリケーションを運用していて問題が起きたことがきっかけでした。すなわち、上述したように、Google Cloud PubSub にメッセージがパブリッシュされたら非同期でサブスクライブして callback 関数を呼んで処理をするというものです。callback 関数ではデータベースからデータを読み出し、整形してペイロードを生成し、外部APIサーバに POST します。
このようなアプリケーションに過負荷をかけるために PubSub に大量のメッセージをパブリッシュさせて処理させようとしたところ、データベース接続数が爆増して、接続数最大値に達してアプリケーションが落ちてしまいました。コネクションプール数を 5、オーバーフローを許さず、サーバを500台起動した場合、同時にセッションは2つしか callback 関数内で使われてなかったので、5000接続までしか理論的には生成できないと思っていたのですが、5000 を優に超えてしまったわけです。
まず疑ったのは Python 用 PubSub ライブラリで、こちら によれば、非同期でサブスクライブするワーカー数が 10 となっているのがいけないと思い、これを明示的に 1 にしてみたのですが問題は解消しませんでした。PubSub の実装を調べてみると、StreamingPullManager.open() 内部でスレッドが4つ生成されていました。つまり非同期Pullのワーカーを1にしたところで意図せず並行処理されているということです。この状態で実験1で使った database.py を用いると、QueuePool が最大でスレッド数分作られてしまうので、20,000接続作られてもおかしくない状態だったことになります(実際には Cloud SQL 側の max_connections がそれ以下なのでエラーでアプリケーションは異常終了しましたが)。
アプリケーションの改修にかける時間に制限があったので、その時は結果オーライということで、実験3のような修正をしてお茶を濁しました。今回上記のような実験をして、何が問題だったのか理解が深まりました。
まとめ
マルチスレッドで処理するプログラムにおいて、sqlalchemy の create_engine の呼び方を気を付けないとデータベース接続数が爆増するということがわかりました。
実験1の結果を見ると、8秒くらいの間隔でデータベース接続が close されていること、この実験パラメタでは70秒目くらいで急激に接続数が減少することが何によって起きているのかわかりませんでした。前者は MySQL の connect_timeout(10秒)が関係しているのだろうと推察されますが、後者についてはよくわからなかったので、後日調べてみたいと思います。
後日談
接続数減少の原因に対する結論
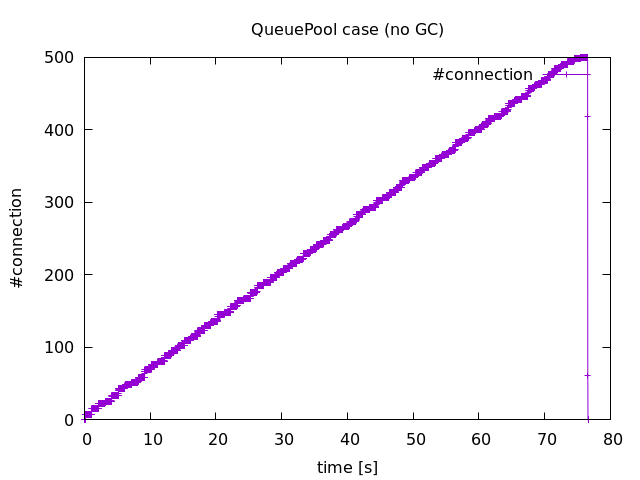
実験1の結果で接続数が突然減少する結果を得ましたが、その原因についてわかりました。結論は GC でした。main.py において
import gc
gc.disable()
を追加したところ、接続数の時間変化は以下のようになりました。ご覧の通り接続数は減少しておりませんよね。
結論に至る経緯
さて、この結論に至るまでにそこそこ時間かけちゃいましたが、GC だと判るきっかけは MySQLdb パッケージで定義されている _mysql_ConnectionObject_close() が呼ばれてない代わりに _mysql_ConnectionObject_dealloc() が呼ばれてるということが分かったからです。因みに、前者は明示的に _mysql.connection.close() した時に呼ばれるメソッドで、後者は _mysql.connection クラスインスタンスの destructor です。
MySQLdb パッケージ内では明示的にインスタンスを削除 del している箇所はありません。また sqlalchemy でもコネクション関連を削除している部分はありますが、それは StaticPool を使っている時だけです。QueuePool を使っている今回のケースでは明示的に _mysql.connection クラスインスタンスを削除することがないため、アプリケーション内で勝手に削除されるとしたらそれは GC 以外ないだろうと思うに至ったわけです。
なお詳細は割愛しますが、MySQL をソースビルドして、COM_QUIT がクライアント側から呼ばれていること、COM_QUIT は mysqlclient ライブラリで定義されている mysql_close() を呼ぶことで発行されることは事前に調べておきました。