はじめに
先日、Lambdaを用いて、S3へ推論結果を格納したり、S3から推論結果を取得したりする処理を実装する機会がありました。
今後似たような処理を実装する際にすぐに思い出すことができるよう全体の流れを整理したいと思い、記事に残すことにしました。
シナリオ
API GatewayへのリクエストをトリガーにLambda関数を実行し以下の処理を行う。
- A - S3へJSONファイルを保存する
- B - S3からJSONファイルを取得する
A - S3へJSONファイルを保存
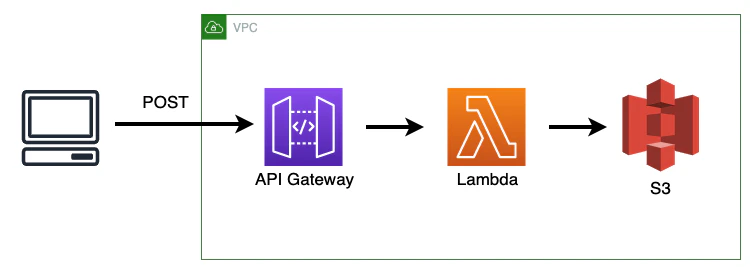
1. S3のバケットを準備する
- 「バケットを作成」をクリック
- バケット名を入力。今回は
sample-json-testとする。
2. Lamda関数の作成
今回はリクエストを送る際に発行されるrequest_idをそのままファイル名にしてJSONファイルを保存します。
- Lambdaのトップページから「一から作成」をクリック
- 関数名を
upload-json-to-s3、ランタイムをPython 3.8に設定し「関数の作成」をクリック - 以下のコードを書き、「Deploy」をクリック
import json
import boto3
s3 = boto3.resource('s3')
# バケット名を指定
BUCKET_NAME = "sample-json-test"
def lambda_handler(event, context):
# request_idを取得
request_id = context.aws_request_id
# バケット名,オブジェクト名を指定
bucket = s3.Bucket(BUCKET_NAME)
object_key_name = f"{request_id}.json"
# オブジェクトを生成
obj = bucket.Object(object_key_name)
# 対象のバケットにjsonデータをアップロード
json_data = event
r = obj.put(Body = json.dumps(json_data))
return {
'request_id': request_id,
'statusCode': 200,
}
テストの実行
- 「Test」をクリックしイベント名を適当に入力する
- 「作成」をクリック
- 「テスト」のタブをクリックし、内容を確認後、「テスト」をクリック
- レスポンス内容の中に
"errorMessage": "An error occurred (AccessDenied) when calling the PutObject operation: Access Denied"という記載があり、S3にアクセスするための権限がないことが分かる。
ポリシーの付与
- 「設定」タブをクリックし該当するロール名をクリック
- 「ポリシーをアタッチします」をクリックし、
AmazonS3FullAccessを選択した後、「ポリシーのアタッチ」をクリック
※ AmazonS3FullAccessは全てのバケットに全てのアクション(ダウンロードやアップロード、バケットの作成等の操作の種類のこと)でアクセス可能なポリシーなので、本来はセキュリティの観点からアクセス制限をかけたポリシーを選択(自作)する必要があります。
再度テストの実行
- 「テスト」をクリック
- レスポンスとして
"statusCode": 200が返ってくることを確認
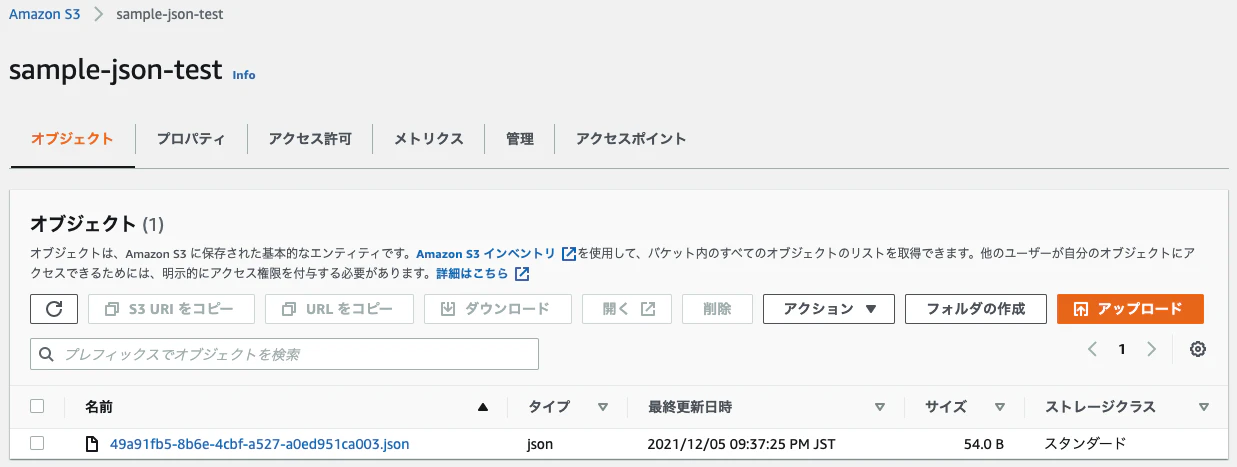
指定したS3バケットを見に行く
以下のようにrequest_idをファイル名としたJSONファイルが格納されていることが確認できます。
2. API Gatewayの設定
RESTAPIのメソッドを定義した後APIキーを作成しデプロイを行う
メソッドの作成
- 「APIを作成」 -> REST API を選択し「構築」 をクリック
- APIの名前(今回は
operation-of-s3とする)を入力し、「APIの作成」をクリック - 「アクション」 -> 「メソッドの作成」 -> 「POST」を選択
- Lambda関数に先ほど作成した
upload-json-to-s3を入力し、「保存」 ボタンをクリック
APIキーの作成、設定
現時点ではAPIが完全にパブリックに公開されている状態なのでAPIキーを設定する。
- サイドバーの「APIキー」 -> 「アクション」 -> 「APIキーの作成」 -> 名前を入力 -> 「保存」
- リソース画面の「リクエストメソッド」をクリック
- APIキーの必要性を false から true に変更する
使用量プランの作成
- サイドバーの「使用料プラン」 -> 「作成」
- 名前を入力し, スロットリング、クォータを設定する(今回はどちらもチェックなし)
- 「APIステージの追加」で先ほど作成したAPIを選択 -> チェックボタン
- 「APIキー」タブをクリックし、先ほど作成したAPIキーを選択 -> チェックボタン
デプロイ
- 「アクション」 -> 「APIのデプロイ」
- デプロイされるステージを選択(今回は
devを新規作成) - 「デプロイ」をクリック
B - S3からJSONファイルを取得
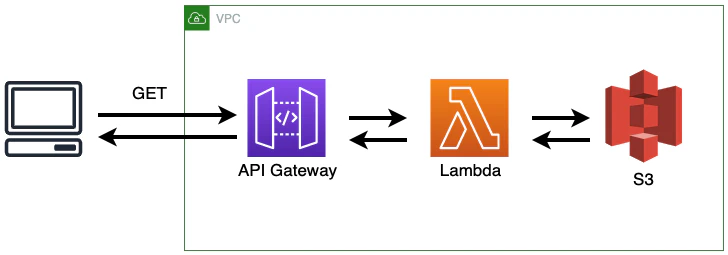
Lambda関数の作成
GETリクエストのボディに含まれるrequest_idをもとに、S3から対象のJSONファイルを取得し辞書型に変換した値を返すよう関数を作成します。
- 関数名を
get-json-from-s3, ランタイムをPython 3.8に設定 - 以下のコードを書き、「Deploy」をクリック
import json
import boto3
s3 = boto3.resource('s3')
# バケット名を指定
BUCKET_NAME = 'sample-json-test'
def lambda_handler(event, context):
# request_idを取得
request_id = event["request_id"]
# バケット名,オブジェクト名を指定
bucket = s3.Bucket(BUCKET_NAME)
object_key_name = '{}.json'.format(request_id)
# オブジェクトを生成
obj = bucket.Object(object_key_name)
try:
# 対象のjsonを取得し中身を取り出す
response = obj.get()
body = response['Body'].read()
# json -> 辞書型へ変換
json_data = json.loads(body.decode('utf-8'))
except:
print('指定したファイルは存在しません')
json_data = {}
return json_data
ポリシーの付与
AmazonS3ReadOnlyAccessのポリシーをロールに付与する
2. APIGatewayの作成
メソッドの作成
- 先ほど作成した
operation-of-s3を選択 - 「アクション」 -> 「メソッドの作成」 -> 「GET」を選択
- Lambda関数に先ほど作成した
get-json-to-s3を入力し、「保存」 ボタンをクリック
- 先述した内容を参考に以下を行う
- APIキーの必要性を false から true に変更
- デプロイ
3. 実際にAPIを叩いてみる
A - JSONファイルをS3に格納
以下の辞書型データをS3にJSONファイルとして格納する
{
"name":"yamada",
"age": 30
}
- curlコマンドでエンドポイントへPOSTリクエストを行う
$ curl -H "x-api-key: {APIキー}" -X POST "{APIエンドポイント}" -d "{\"name\":\"yamada\", \"age\":30}"
- レスポンスを確認する
{"request_id": "9c3c6107-ef1f-454d-bb15-2dc7b4de73f4", "statusCode": 200}
- S3のバケットにリクエストIDをファイル名としたJSONファイルの存在を確認する

B - S3からJSONファイルを取得
取得したリクエストIDを保持させてエンドポイントへGETリクエストを行う
$ curl -H "x-api-key: {APIキー}" -X GET "{APIエンドポイント}" -d "{\"request_id\":\"9c3c6107-ef1f-454d-bb15-2dc7b4de73f4\"}"
- レスポンスを確認する
{"name": "yamada", "age": 30}
感想
- シンプルな構成ですが、この流れを把握することができれば画像を加工して保存/取得したりと自分の実現したい処理を色々と作成できると思いました。
参考