はじめに
今回はPythonとSportify APIを使って下記のようなグラフを生成したいと思います。
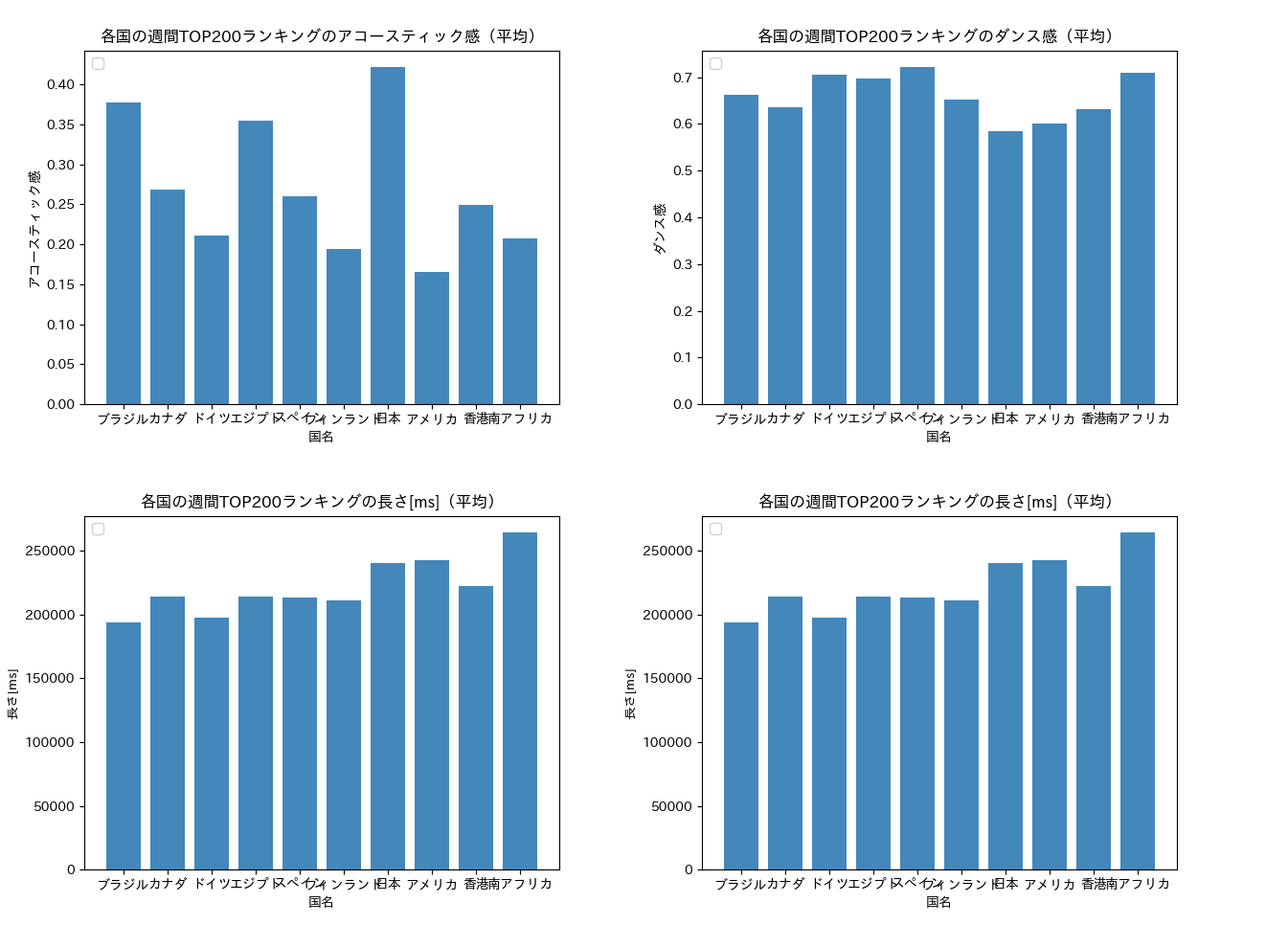
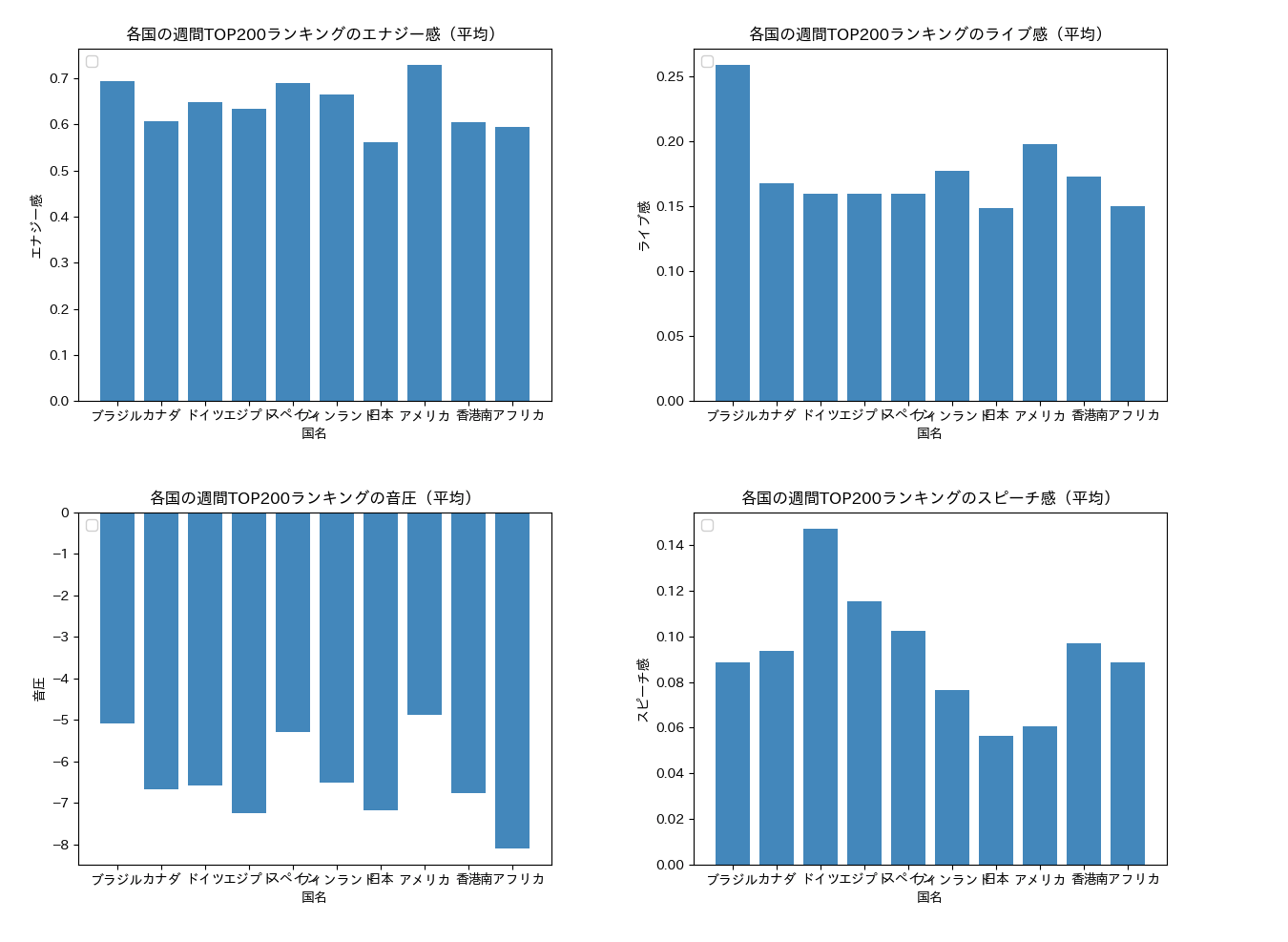
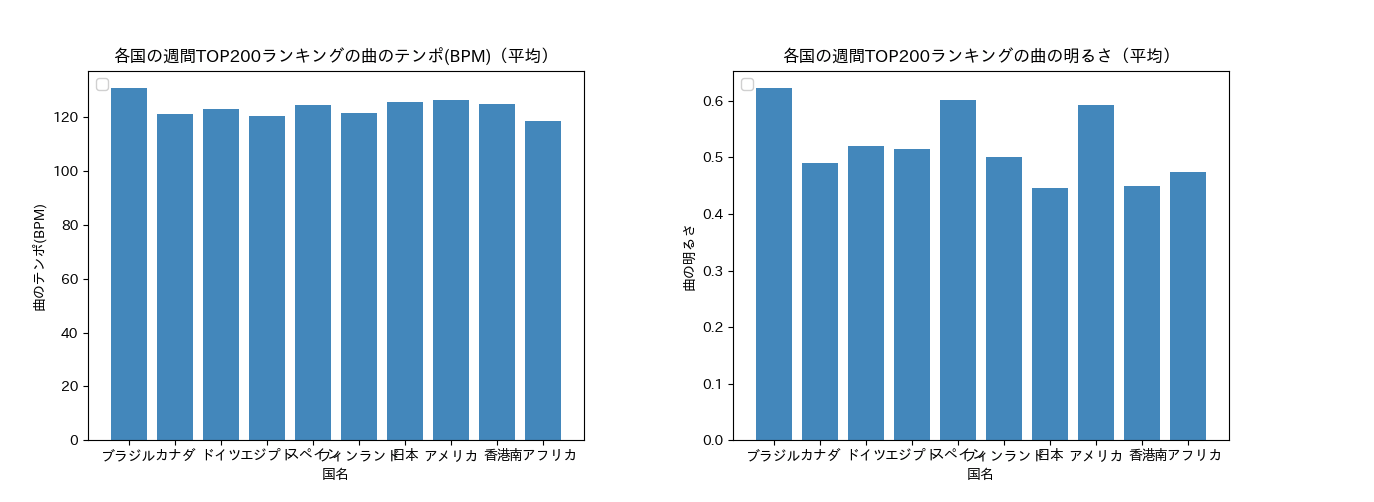
自分が気になるお好きな国別トップ200チャートから曲の特徴の平均値を取得しグラフ化したものです。
例えばこのグラフから、今日本は他国に比べてアコースティック感の強い曲が流行っているということが分かります。
余談にはなりますが、Sportifyアカウントを持っている人向けに、自分が普段よく聴く曲の特徴を可視化する方法も記事にしているので
良かったらこちらもご覧下さい。
環境
- Python 3.7.5
ディレクトリ構成
├── csv
├── images
├── main.py
予めcsvディレクトリとimagesディレクトリを作っておきます。
後述しますが、ダウンロードしたcsvファイルはcsvディレクトリに配置し、
main.pyの実行後に生成されるグラフはimagesディレクトリ配下に配置されます。
準備
Sportify APIのClient IDとシークレットキーを取得
下記の記事を参考に取得しました。
取得したい国のトップチャートcsvをダウンロードする
下記から各国のトップ200チャートをcsv形式でダウンロードできます。
日別、週間別で好きな時期のチャートを取得できます。
今回は冒頭で貼りつけたキャプチャの通り、
ブラジル、カナダ、ドイツ、エジプト、スペイン、フィンランド、日本、アメリカ、香港、南アフリカ
の週間TOP200チャートをダウンロードしました。
ダウンロードしたcsvファイルは./csv配下に配置します。
必要なライブラリをインストール
pandasのインストール
csvの処理に使います。
$ pip install pandas
matplotlibのインストール
グラフ生成に使います。
また日本語をグラフ内に表示させる為、日本語化モジュールもインストールします。
$ pip install matplotlib
$ pip install japanize-matplotlib
実装
import spotipy
from spotipy.oauth2 import SpotifyClientCredentials
import matplotlib.pyplot as plt
import japanize_matplotlib
import pandas as pd
import statistics
import glob
# 取得したClient IDとシークレットキーを入れる
client_id = '****************'
client_secret = '****************'
client_credentials_manager = SpotifyClientCredentials(client_id, client_secret)
sp = spotipy.Spotify(client_credentials_manager=client_credentials_manager)
top_records = []
# ダウンロードしたcsvファイルを読み込む
for csv in sorted(glob.glob("./csv/*.csv")):
top_records.append(pd.read_csv(csv, header=1))
top_track_info = []
top_records_count = len(top_records)
# 国ごとに曲の情報を取得する
for i in range(top_records_count):
top_ure_list = top_records[i]["URL"].unique()
top_track_id = [top_url.split('/')[-1] for top_url in top_ure_list]
top_track_info.append(pd.DataFrame())
for id in top_track_id:
info = pd.DataFrame.from_dict(sp.audio_features(id))
top_track_info[i] = top_track_info[i].append(info)
top_track_info[i] = top_track_info[i].reset_index(drop=True)
top_track_info[i].head(10)
top_track_info[i]["rank"] = top_track_info[i].index + 1
cols = top_track_info[0].columns
excludes = ("analysis_url", "id", "rank", "track_href", "type", "uri", 'instrumentalness', 'key', 'mode', 'time_signature')
col_nm = {"acousticness": "アコースティック感", "danceability": "ダンス感", "duration_ms": "長さ[ms]", "energy": "エナジー感", "liveness": "ライブ感", "loudness": "音圧", "speechiness": "スピーチ感", "tempo": "曲のテンポ(BPM)", "valence": "曲の明るさ"}
contry = ("ブラジル", "カナダ", "ドイツ", "エジプト", "スペイン", "フィンランド", "日本", "アメリカ", "香港", "南アフリカ")
# 特徴ごとにグラフを生成する
for col in cols:
avgs = []
if(col in excludes): continue
plt.title("各国の週間TOP200ランキングの" + col_nm[col] + "(平均)")
# 国ごとに平均値を取得
for i in range(top_records_count):
avgs.append(statistics.mean(top_track_info[i][col]))
plt.bar(contry, avgs, alpha=0.8)
plt.legend(loc="upper left", fontsize=11)
plt.xlabel("国名")
plt.ylabel(col_nm[col])
plt.savefig("./images/" + col + ".png")
plt.clf()
実行
$ python main.py
imagesディレクトリ配下に、画像が生成されていく。
最後に
僕は普段はSportifyを利用する際、日本かグローバルのチャートしか聴いていませんでしたが、
こんなに多くの国のチャートが時期ごとに聴けるのは驚きでした。
普段馴染みのない国の音楽を聴くきっかけにもなり、良い体験ができました。
あなたも自分の好きな国や時期で是非試してみてください!