ポイント
- K-means clustering を実装し、具体的な数値例で確認。
- MNIST データを使用し、clustering と prediction を試行。
データ 1
import matplotlib.cm as cm
n_input = 10
dim = 2
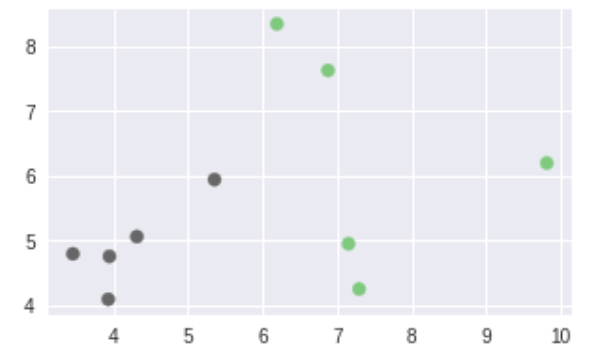
x_1 = np.random.normal(loc = [7.0, 7.0], scale = [2.0, 2.0], size = [n_input//2, dim])
x_2 = np.random.normal(loc = [5.0, 5.0], scale = [1.0, 1.0], size = [n_input//2, dim])
x = np.concatenate([x_1, x_2], axis = 0).astype(np.float32)
y_1 = np.array([0] * (n_input//2))
y_2 = np.array([1] * (n_input//2))
y = np.concatenate([y_1, y_2]).astype(np.int32)
fig = plt.figure(figsize = (5, 3))
ax = fig.add_subplot(1, 1, 1)
ax.scatter(x[:, 0], x[:, 1], c = y, cmap = cm.Accent)
plt.show()

サンプルコード 1-1 (Class)
class k_means():
def __init__(self):
pass
# Manual
def inference_1(self, x, dim, n_clusters):
indices = [1, 6]
c_init = x[indices]
c = tf.Variable(c_init, dtype = tf.float32)
x_tmp = tf.tile(tf.expand_dims(x, 1), [1, n_clusters, 1])
c_tmp = tf.expand_dims(c, 0)
all_scores = tf.reduce_sum(tf.square(x_tmp - c_tmp), axis = 2)
scores = tf.reduce_min(all_scores, axis = 1)
cluster_idx = tf.argmin(all_scores, axis = 1)
cluster_one_hot = tf.one_hot(cluster_idx, depth = n_clusters)
tmp_1 = tf.tile(tf.expand_dims(cluster_one_hot, n_clusters), [1, 1, dim])
tmp_2 = tf.expand_dims(tf.reduce_sum(cluster_one_hot, axis = 0), axis = 1)
c_next = tf.reduce_sum(x_tmp * tmp_1, axis= 0) / tmp_2
training_op = tf.assign(c, c_next)
return c, all_scores, scores, cluster_idx, training_op
# API
def inference_2(self, x, n_clusters):
indices = [1, 6]
c_init = x[indices]
graph = tf.contrib.factorization.KMeans(x, \
num_clusters = n_clusters, initial_clusters = c_init)
# graph = tf.contrib.factorization.KMeans(x, num_clusters = n_clusters)
return graph.training_graph()
def fit(self):
pass
サンプルコード 1-2 (Manual)
tf.reset_default_graph()
km = k_means()
dim = 2
n_clasters = 2
c, all_scores, scores, cluster_idx, training_op = km.inference_1(x, dim, n_clasters)
init_var = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init_var)
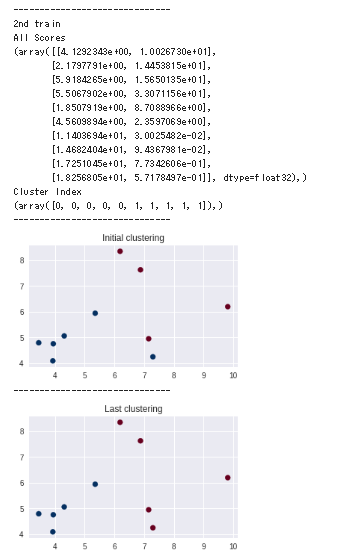
print ('-' * 30)
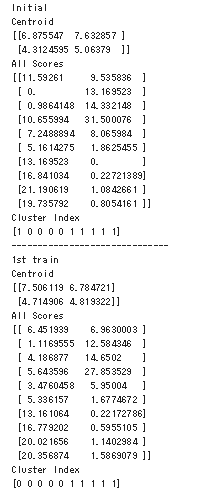
print ('Initial')
print ('Centroid')
print (sess.run(c))
print ('All Scores')
print (sess.run(all_scores))
print ('Cluster Index')
print (sess.run(cluster_idx))
initial_cluster_idx = sess.run(cluster_idx)
sess.run(training_op)
print ('-' * 30)
print ('1st train')
print ('Centroid')
print (sess.run(c))
print ('All Scores')
print (sess.run(all_scores))
print ('Cluster Index')
print (sess.run(cluster_idx))
sess.run(training_op)
print ('-' * 30)
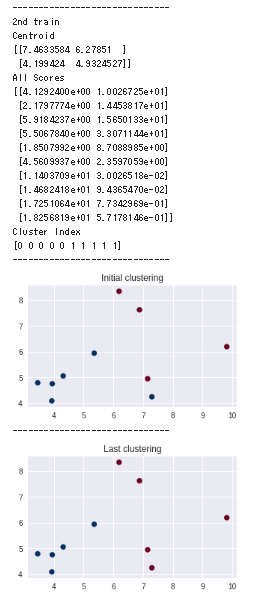
print ('2nd train')
print ('Centroid')
print (sess.run(c))
print ('All Scores')
print (sess.run(all_scores))
print ('Cluster Index')
print (sess.run(cluster_idx))
last_cluster_idx = sess.run(cluster_idx)
print ('-' * 30)
fig = plt.figure(figsize = (5, 3))
ax = fig.add_subplot(1, 1, 1)
ax.scatter(x[:, 0], x[:, 1], c = initial_cluster_idx, cmap = cm.RdBu)
ax.set_title('Initial clustering')
plt.show()
print ('-' * 30)
fig = plt.figure(figsize = (5, 3))
ax = fig.add_subplot(1, 1, 1)
ax.scatter(x[:, 0], x[:, 1], c = last_cluster_idx, cmap = cm.RdBu)
ax.set_title('Last clustering')
plt.show()
サンプルコード 1-3 (API)
tf.reset_default_graph()
km = k_means()
n_clasters = 2
all_scores, cluster_idx, scores, cluster_centers_initialized, init_op, training_op = km.inference_2(x, n_clasters)
init_var = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init_var)
sess.run(init_op)
print ('-' * 30)
print ('Initial')
print ('All Scores')
print (sess.run(all_scores))
print ('Cluster Index')
print (sess.run(cluster_idx))
initial_cluster_idx = sess.run(cluster_idx)
sess.run(training_op)
print ('-' * 30)
print ('1st train')
print ('All Scores')
print (sess.run(all_scores))
print ('Cluster Index')
print (sess.run(cluster_idx))
sess.run(training_op)
print ('-' * 30)
print ('2nd train')
print ('All Scores')
print (sess.run(all_scores))
print ('Cluster Index')
print (sess.run(cluster_idx))
last_cluster_idx = sess.run(cluster_idx)
print ('-' * 30)
fig = plt.figure(figsize = (5, 3))
ax = fig.add_subplot(1, 1, 1)
ax.scatter(x[:, 0], x[:, 1], c = initial_cluster_idx[0], cmap = cm.RdBu)
ax.set_title('Initial clustering')
plt.show()
print ('-' * 30)
fig = plt.figure(figsize = (5, 3))
ax = fig.add_subplot(1, 1, 1)
ax.scatter(x[:, 0], x[:, 1], c = last_cluster_idx[0], cmap = cm.RdBu)
ax.set_title('Last clustering')
plt.show()

データ 2
import matplotlib.cm as cm
def create_data(n_input, dim, n_classes):
n_input_per_class = n_input // n_classes
x_1 = np.random.normal(loc = [7.0, 7.0], scale = [1.5, 1.5], size = [n_input_per_class, dim])
x_2 = np.random.normal(loc = [5.0, 1.0], scale = [1.5, 1.5], size = [n_input_per_class, dim])
x_3 = np.random.normal(loc = [2.0, 4.0], scale = [1.5, 1.5], size = [n_input_per_class, dim])
x = np.concatenate([x_1, x_2, x_3], axis = 0).astype(np.float32)
y_1 = np.array([0] * (n_input_per_class))
y_2 = np.array([1] * (n_input_per_class))
y_3 = np.array([2] * (n_input_per_class))
y = np.concatenate([y_1, y_2, y_3]).astype(np.int32)
y_one_hot = np.identity(n_classes)[y].astype(np.int32)
return x, y, y_one_hot
n_input = 30
dim = 2
n_classes = 3
x_train, y_train, y_one_hot_train = create_data(n_input, dim, n_classes)
x_test, y_test, y_one_hot_test = create_data(n_input, dim, n_classes)
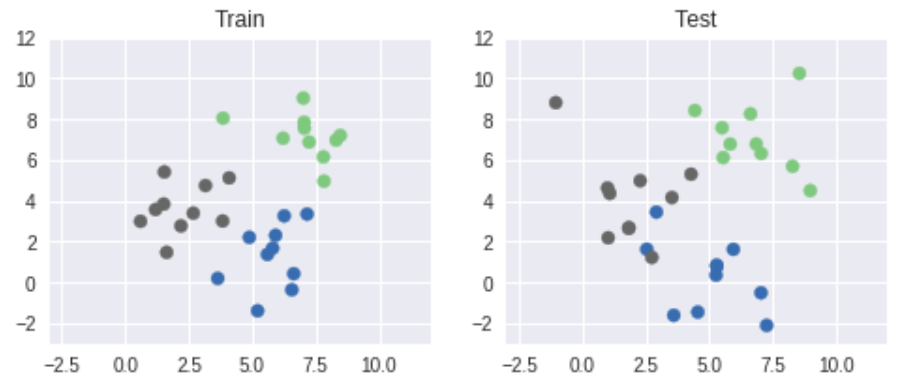
fig = plt.figure(figsize = (8, 3))
ax = fig.add_subplot(1, 2, 1)
ax.scatter(x_train[:, 0], x_train[:, 1], c = y_train, cmap = 'Accent') # Accent, RdYlBu
ax.set_xlim(-3.0, 12.0)
ax.set_ylim(-3.0, 12.0)
ax.set_title('Train')
ax = fig.add_subplot(1, 2, 2)
ax.scatter(x_test[:, 0], x_test[:, 1], c = y_test, cmap = 'Accent') # Accent, RdYlBu
ax.set_xlim(-3.0, 12.0)
ax.set_ylim(-3.0, 12.0)
ax.set_title('Test')
plt.show()
サンプルコード 2-1 (Class)
class k_means_2():
def __init__(self):
pass
def inference(self, x, n_clusters):
r_seed = np.random.randint(100)
graph = tf.contrib.factorization.KMeans(x, num_clusters = n_clusters, \
random_seed = r_seed)
return graph.training_graph()
def predict(self):
pass
def accuracy(self, cluster_idx, labels, lookup_table):
y = tf.nn.embedding_lookup(lookup_table, cluster_idx)
correct_preds = tf.equal(tf.squeeze(y), tf.argmax(labels, axis = 1))
accuracy = tf.reduce_mean(tf.cast(correct_preds, tf.float32))
return accuracy
def fit(self, input_train, labels_train, input_test, labels_test, \
dim, n_clusters, n_classes, n_iter, show_step):
tf.reset_default_graph()
x = tf.placeholder(shape = [None, dim], dtype = tf.float32)
t = tf.placeholder(shape = [None, n_classes], dtype = tf.int32)
feed_dict_train = {x: input_train, t: labels_train}
feed_dict_test = {x: input_test, t: labels_test}
all_scores, cluster_idx, scores, cluster_centers_initialized, init_op, training_op = self.inference(x, n_clusters)
average_score = tf.reduce_mean(scores)
init_var = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init_var)
sess.run(init_op, feed_dict = feed_dict_train)
for i in range(n_iter):
sess.run(training_op, feed_dict = feed_dict_train)
if (i + 1) % show_step == 0:
average_score_train = sess.run(average_score, feed_dict = feed_dict_train)
average_score_test = sess.run(average_score, feed_dict = feed_dict_test)
cluster_idx_train = sess.run(cluster_idx, feed_dict = feed_dict_train)
cluster_idx_test = sess.run(cluster_idx, feed_dict = feed_dict_test)
count = np.zeros(shape = [n_clusters, n_classes], dtype = np.int32)
for j in range(len(labels_train)):
count[cluster_idx_train[0][j]] += labels_train[j]
lookup_table = np.reshape(np.argmax(count, axis = 1), [-1, 1])
accuracy_train = sess.run(self.accuracy(cluster_idx_train[0], labels_train, lookup_table))
accuracy_test = sess.run(self.accuracy(cluster_idx_test[0], labels_test, lookup_table))
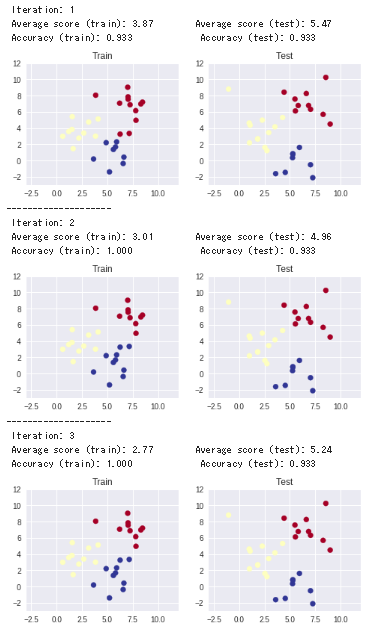
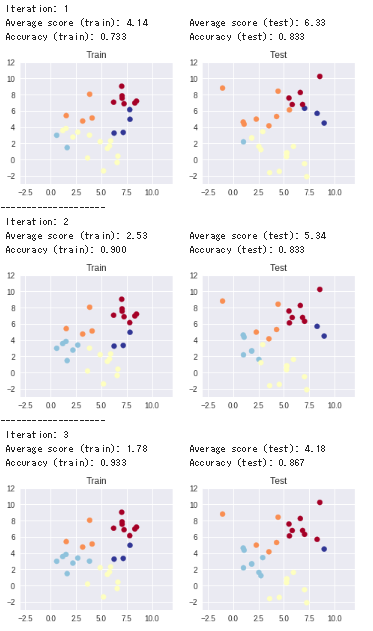
print ('--------------------')
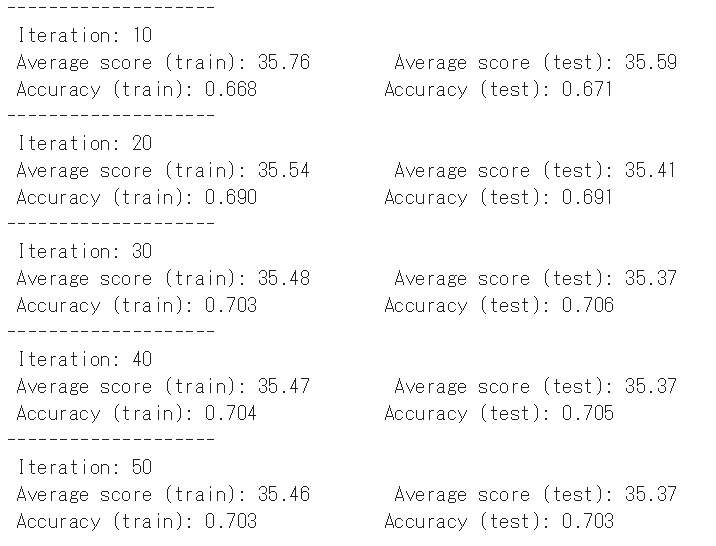
print (' Iteration: ' + str(i + 1))
print (' Average score (train): {:.2f} Average score (test): {:.2f}' \
.format(average_score_train, average_score_test))
print (' Accuracy (train): {:.3f} Accuracy (test): {:.3f}' \
.format(accuracy_train, accuracy_test))
fig = plt.figure(figsize = (8, 3))
ax = fig.add_subplot(1, 2, 1)
ax.scatter(input_train[:, 0], input_train[:, 1], c = cluster_idx_train[0], cmap = 'RdYlBu') # Accent, RdYlBu
ax.set_xlim(-3.0, 12.0)
ax.set_ylim(-3.0, 12.0)
ax.set_title('Train')
ax = fig.add_subplot(1, 2, 2)
ax.scatter(input_test[:, 0], input_test[:, 1], c = cluster_idx_test[0], cmap = 'RdYlBu') # Accent, RdYlBu
ax.set_xlim(-3.0, 12.0)
ax.set_ylim(-3.0, 12.0)
ax.set_title('Test')
plt.show()
サンプルコード 2-2 (n_clusters = 3)
input_train = x_train
labels_train = y_one_hot_train
input_test = x_test
labels_test = y_one_hot_test
dim = 2
n_clusters = 3
n_classes = 3
n_iter = 3
show_step = 1
kmeans.fit(input_train, labels_train, input_test, labels_test, \
dim, n_clusters, n_classes, n_iter, show_step)
サンプルコード 2-3 (n_clusters = 5)
input_train = x_train
labels_train = y_one_hot_train
input_test = x_test
labels_test = y_one_hot_test
dim = 2
n_clusters = 5
n_classes = 3
n_iter = 3
show_step = 1
kmeans.fit(input_train, labels_train, input_test, labels_test, \
dim, n_clusters, n_classes, n_iter, show_step)
データ 3 (MNIST)
サンプルコード 3
input_train = mnist.train.images[:55000]
labels_train = mnist.train.labels[:55000].astype(np.int32)
input_test = mnist.test.images[:10000]
labels_test = mnist.test.labels[:10000].astype(np.int32)
dim = 28*28
n_clusters = 20
n_classes = 10
n_iter = 50
show_step = 10
kmeans.fit(input_train, labels_train, input_test, labels_test, \
dim, n_clusters, n_classes, n_iter, show_step)