Reference
Distributed Representations of Sentences and Documents
Library
!apt-get install libmecab-dev mecab mecab-ipadic-utf8
!apt-get -q -y install swig
!pip install mecab-python3
!echo `mecab-config --dicdir`"/mecab-ipadic-neologd"

import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import MeCab
from tqdm import tqdm
from gensim.models.doc2vec import Doc2Vec, TaggedDocument
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
Data
df_news = pd.read_csv('/content/gdrive/My Drive/xxx/xxx.csv')
print ('shape of df_news: ', df_news.shape)
df_news.head()

df_g = df_news.groupby('NEWS_DATE')['NEWS_TITLE'].sum().reset_index()
print (df_g.shape)
df_g.head()

dates = df_g['NEWS_DATE']
titles = df_g['NEWS_TITLE']
idx = np.random.randint(len(dates))
txt = titles[idx]
tagger = MeCab.Tagger()
# tagger = MeCab.Tagger('-d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd')
tagger.parse('')
node = tagger.parseToNode(txt)
result = []
s1 = txt
flag = 0
while node:
s2 = node.surface
s3 = s1.replace(s2, '')
hinshi = node.feature.split(',')[0]
if flag == 1:
result.append(s3)
flag = 0
if hinshi in ['名詞']:
flag = 1
elif hinshi in ['動詞', '形容詞']:
result.append(node.feature.split(',')[6])
else:
pass
s1 = s2
node = node.next
print ('Date: ', dates[idx])
print ('words: ', result)
print ('# of words: ', len(result))

Doc2Vec
%%time
tagged_docs = []
for date, title in tqdm(zip(dates, titles)):
tagger = MeCab.Tagger()
tagger.parse('')
node = tagger.parseToNode(title)
words = []
s1 = title
flag = 0
while node:
s2 = node.surface
s3 = s1.replace(s2, '')
hinshi = node.feature.split(',')[0]
if flag == 1:
words.append(s3)
flag = 0
if hinshi in ['名詞']:
flag = 1
elif hinshi in ['動詞', '形容詞']:
words.append(node.feature.split(',')[6])
else:
pass
s1 = s2
node = node.next
tagged_docs.append(TaggedDocument(words=words, tags=[date]))
%%time
vec_size = 50
alpha = 0.025
alpha_delta = 0.0002
max_epochs = 20
model = Doc2Vec(vector_size=vec_size, alpha=alpha, min_alpha=alpha, min_count=1, dm =1)
model.build_vocab(tagged_docs)
for epoch in range(max_epochs):
model.train(tagged_docs, total_examples=model.corpus_count,
epochs=model.iter)
model.alpha -= alpha_delta
model.min_alpha = model.alpha
idx = np.random.randint(len(tagged_docs))
print ('Date: ', dates[idx])
print ('similar dates: ', model.docvecs.most_similar(dates[idx], topn=3))
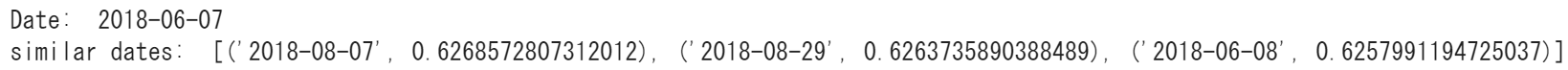
date1 = '2018-06-07'
date2 = '2018-08-29'
print (df_news[df_news['NEWS_DATE']==date1].sort_values('NEWS_TIME'))
print ()
print (df_news[df_news['NEWS_DATE']==date2].sort_values('NEWS_TIME'))


# save and load model
from gensim.test.utils import get_tmpfile
path = '/content/gdrive/My Drive/xxx/'
fname = get_tmpfile(path+'doc2vec_model')
model.save(fname)
loaded_model = Doc2Vec.load(fname)
# no more updates
model.delete_temporary_training_data(keep_doctags_vectors=True, keep_inference=True)
# infer vector for a new document
vector = model.infer_vector(['米ダウ平均', '上昇'])
print (vector[:10])

Clustering
doc_vectors = model.docvecs.vectors_docs
print ('shape of doc_vectors: ', doc_vectors.shape)
# print (doc_vectors[0])
kmeans_model = KMeans(n_clusters=3, init='k-means++', max_iter=100)
kmeans_model.fit(doc_vectors)
labels=kmeans_model.labels_.tolist()
pca = PCA(n_components=2).fit(doc_vectors)
datapoint = pca.transform(doc_vectors)
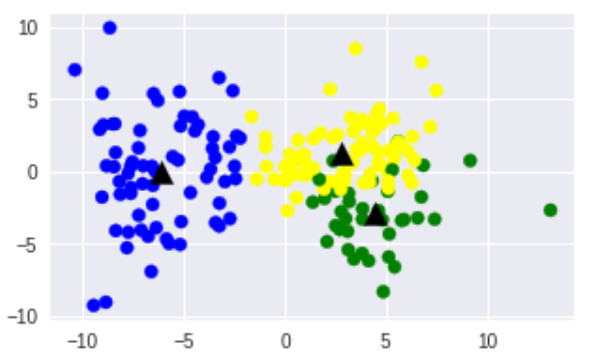
plt.figure(figsize=(5, 3))
# label1 = ["#FFFF00", "#008000", "#0000FF", "#800080"]
label1 = ["#FFFF00", "#008000", "#0000FF"]
color = [label1[i] for i in labels]
plt.scatter(datapoint[:, 0], datapoint[:, 1], c=color)
centroids = kmeans_model.cluster_centers_
centroidpoint = pca.transform(centroids)
plt.scatter(centroidpoint[:, 0], centroidpoint[:, 1], marker='^', s=150, c='#000000')
plt.show()
Word2Vec
# model = gensim.models.Word2Vec.load(path + 'ja.bin')
model = gensim.models.Word2Vec.load(path + 'jv.bin')
# model.wv['king']
model.wv.most_similar('king')
# model.wv.most_similar(positive=['woman', 'king'], negative=['man'])
