ポイント
- LSTMに2種類のドロップアウト (d(h)、d(g)) を実装し、(トイデータを用いて)パフォーマンスを検証。
- d(h)、d(g) のどちらにおいても過学習を抑える効果を確認。
- d(g) より d(h) の方がパフォーマンスが良い(今後、別タスク、別データで追加検証)。
レファレンス
1. Recurrent Dropout without Memory Loss
検証方法
- モデルがデータの規則性を理解する(正解率98%以上に達する)までに要したイテレーション回数をチェックする。
- 複数回の試行の平均と標準偏差をパフォーマンスの指標とする。
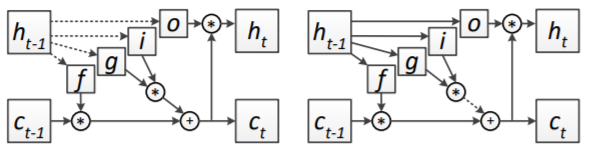
(参照論文より引用)
d(h): 左図、 d(g): 右図 破線がドロップアウト・コネクション
データ
入力 $x(t)$:
x(t) = \begin{pmatrix}
s(t)\\
m(t)
\end{pmatrix} \\
s(t) \in \{0, 1, 2, 3, 4\}\\
m(t) \in \{0, 1\},\quad \sum_{t=1}^{T} m(t) = 2
出力 $y$:
y = \sum_{t=1}^{T} s(t) m(t)
例:
s = [2, 3, 1, 0, 4]\\
m = [0, 0, 1, 0, 1]\\
\rightarrow\\
y = 5
検証結果
数値計算例:
- T = 5
- サンプル数:1,000 (トレーニング:500、テスト:500)
- バッチサイズ:30
- 隠れ層のユニット数:30
- オプティマイザー:Adam
- 試行回数:5回
| データ | 指標 | ベース | d(h) | d(g) |
|---|---|---|---|---|
| トレーニング | 平均 | 319.40 | 419.60 | 554.60 |
| 標準偏差 | 26.00 | 31.23 | 87.02 | |
| テスト | 平均 | 514.00 | 466.00 | 504.60 |
| 標準偏差 | 95.85 | 56.25 | 53.52 |
ベース:ドロップアウトなし
サンプルコード
def get_dropout_mask(self, keep_prob, shape):
keep_prob = tf.convert_to_tensor(keep_prob)
random_tensor = keep_prob + tf.random_uniform(shape)
binary_tensor = tf.floor(random_tensor)
dropout_mask = binary_tensor / keep_prob
return dropout_mask
def LSTM(self, x, h, c, n_in, n_units, dropout_mask):
w_x = self.weight_variable('w_x', [n_in, n_units * 4])
w_h = self.weight_variable('w_h', [n_units, n_units * 4])
b = self.bias_variable('b', [n_units * 4])
# h Dropout
#h *= dropout_mask
i, f, o, g = tf.split(tf.add(tf.add(tf.matmul(x, w_x), \
tf.matmul(h, w_h)), b), 4, axis = 1)
i = tf.nn.sigmoid(i)
f = tf.nn.sigmoid(f)
o = tf.nn.sigmoid(o)
g = tf.nn.tanh(g)
# g Dropout
g *= dropout_mask
c = tf.add(tf.multiply(f, c), tf.multiply(i, g))
h = tf.multiply(o, tf.nn.tanh(c))
return h, c
def inference(self, x, length, n_in, n_units, \
n_out, batch_size, keep_prob):
h = tf.zeros(shape = [batch_size, n_units], \
dtype = tf.float32)
c = tf.zeros(shape = [batch_size, n_units], \
dtype = tf.float32)
list_h = []
list_c = []
lstm_dropout_mask = self.get_dropout_mask(keep_prob, \
[batch_size, n_units])
with tf.variable_scope('lstm'):
for t in range(length):
if t > 0:
tf.get_variable_scope().reuse_variables()
h, c = self.LSTM(x[:, t, :], h, c, n_in, n_units, \
lstm_dropout_mask)
list_h.append(h)
list_c.append(c)
with tf.variable_scope('pred'):
w = self.weight_variable('w', [n_units, n_out])
b = self.bias_variable('b', [n_out])
pred = tf.add(tf.matmul(list_h[-1], w), b)
return pred