ポイント
- LSTMをベースに Batch Normalization を実装。MNIST 手書き数字データでパフォーマンスを検証。
- Batch Normalization、Dropout ともに効果を確認できず。
- 今後、別タスク、別データで追加検証。
レファレンス
1. Recurrent Batch Normalization
2. Recurrent Dropout without Memory Loss
検証方法
- Base model( Normalization なし)、Recurrent Dropout と比較。
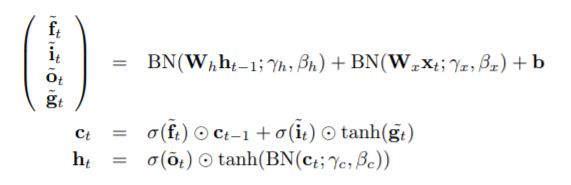
(参照論文1より引用)
データ
MNIST handwritten digits
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('***/mnist', \
one_hot = True)
検証結果
数値計算例:
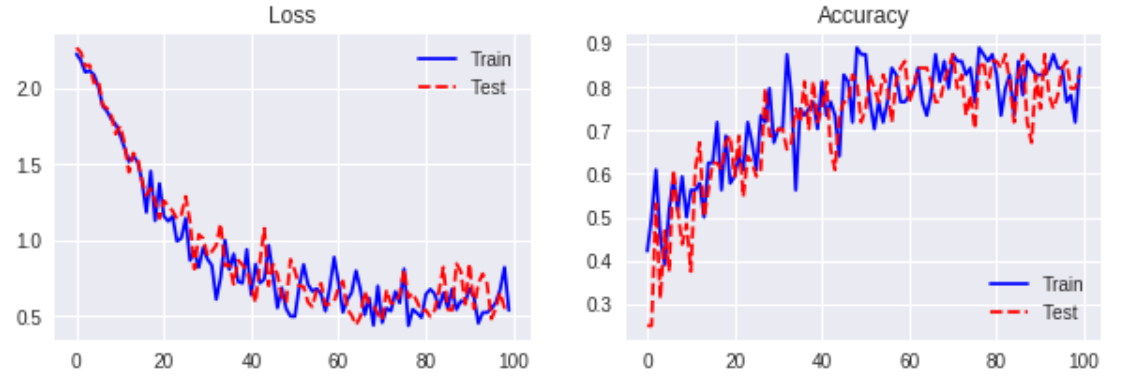
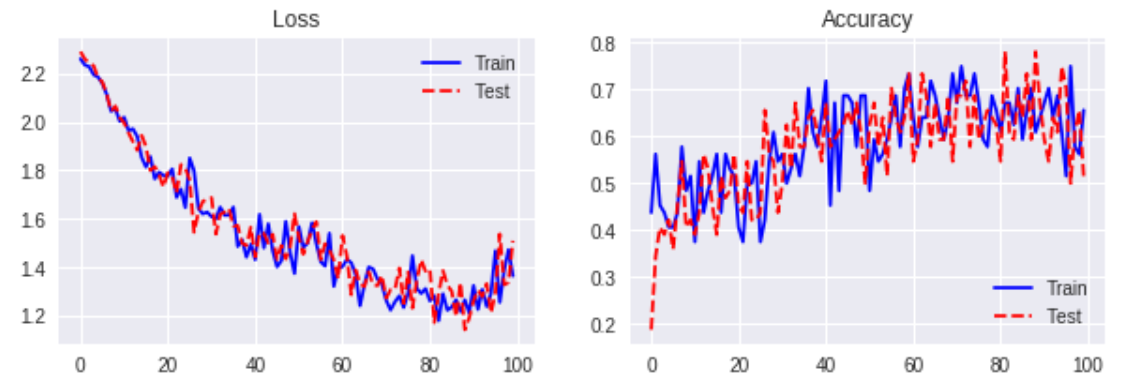
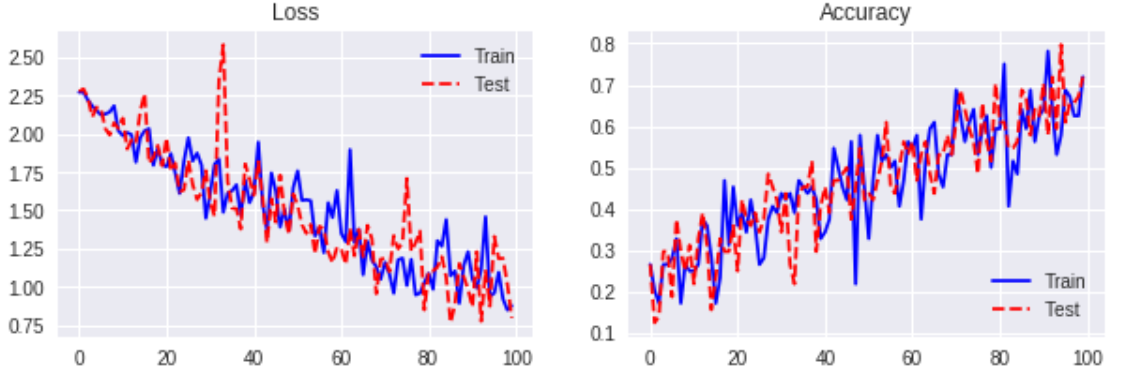
- n_units = 100
- learning_rate = 0.01
- batch_size = 64
- keep_prob = 0.8
Base Model ( without Normalization )
Recurrent Batch Normalization
Recurrent Dropout
サンプルコード
# Batch Normalization
def inference(self, x, length, n_in, n_units, n_out, \
batch_size, forget_bias, keep_prob):
x = tf.reshape(x, [-1, length, n_in])
h = tf.zeros(shape = [batch_size, n_units], \
dtype = tf.float32)
c = tf.zeros(shape = [batch_size, n_units], \
dtype = tf.float32)
list_h = []
list_c = []
with tf.variable_scope('lstm'):
init_norm = tf.truncated_normal_initializer(mean = \
0.0, stddev = 0.05, dtype = tf.float32)
init_constant1 = tf.constant_initializer(value = \
0.0, dtype = tf.float32)
init_constant2 = tf.constant_initializer(value = 0.1, \
dtype = tf.float32)
w_x = tf.get_variable('w_x', shape = [n_in, n_units \
* 4], initializer = init_norm)
w_h = tf.get_variable('w_h', shape = [n_units, \
n_units * 4], initializer = init_norm)
b = tf.get_variable('b', shape = [n_units * 4], \
initializer = init_constant1)
gamma_x = tf.get_variable('gamma_x', shape = \
[n_units * 4], initializer = init_constant2)
gamma_h = tf.get_variable('gamma_h', shape = \
[n_units * 4], initializer = init_constant2)
gamma_c = tf.get_variable('gamma_c', shape = \
[n_units], initializer = init_constant2)
beta_c = tf.get_variable('beta_c', shape = \
[n_units], initializer = init_constant1)
dropout_mask = self.get_dropout_mask(keep_prob, \
[n_units])
for t in range(length):
t_x = tf.matmul(x[:, t, :], w_x)
mean_x, var_x = tf.nn.moments(t_x, [0])
bn_x = gamma_x * (t_x - mean_x) / \
tf.sqrt(var_x + 1e-10)
# dropout
#h *= dropout_mask
t_h = tf.matmul(h, w_h)
mean_h, var_h = tf.nn.moments(t_h, [0])
bn_h = gamma_h * (t_h - mean_h) / \
tf.sqrt(var_h + 1e-10)
# batch normalization
i, f, o, g = tf.split(tf.add(tf.add(bn_x, bn_h), \
b), 4, axis = 1)
i = tf.nn.sigmoid(i)
f = tf.nn.sigmoid(f + forget_bias)
o = tf.nn.sigmoid(o)
g = tf.nn.tanh(g)
# dropout
#g *= dropout_mask
c = tf.add(tf.multiply(f, c), tf.multiply(i, g))
# batch normalization
mean_c, var_c = tf.nn.moments(c, [0])
c = gamma_c * (c - mean_c) / tf.sqrt(var_c + 1e-10)
c = tf.add(c, beta_c)
h = tf.multiply(o, tf.nn.tanh(c))
list_h.append(h)
list_c.append(c)
with tf.variable_scope('pred'):
w = self.weight_variable('w', [n_units, n_out])
b = self.bias_variable('b', [n_out])
y = tf.add(tf.matmul(list_h[-1], w), b)
y = tf.nn.softmax(y, axis = 1)
return y
# Dropout Mask
def get_dropout_mask(self, keep_prob, shape):
keep_prob = tf.convert_to_tensor(keep_prob)
random_tensor = keep_prob + tf.random_uniform(shape)
binary_tensor = tf.floor(random_tensor)
dropout_mask = binary_tensor / keep_prob
return dropout_mask