#目次
1.はじめに
2.記事の概要
3.アプリ作成の理由
4.成果物についての情報
5.機械学習
6.アプリを作ってみての課題
7.Pythonを学んでみて
8.終わりに
1.はじめに
はじめまして。プログラミング未経験でエンジニアへの転職を目指し、Aidemyの講座を受講している文系公務員です。初めての投稿のため、至らない点ばかりかと思いますが、何卒ご容赦を。
2.記事の概要
講座提出用にQiitaに記事を投稿させていただきます。アプリの作成経緯や準備、作成過程を書いていこうかなと思います。
3.アプリ作成の理由
タイトルにもありますように、ガンダムの画像を判別するアプリを作っていこうかと思います。その理由なんですが、2点ありまして。1点目が学習したプログラミング言語であるPythonで機械学習やディープラーニングを使った画像認識ができるから。これを使えば、1979年からこれまで数多く登場しているガンダムを判別できるのではないかと考えました。2点目なんですが、単純にガンダムが好きだから。初めて見た「機動戦士ガンダムSEED」からガンダムというものにハマり、これまで多くの作品を見てきました。そんな自分のアニメ好きの原点とも言えるガンダムでポートフォリオを作り、自分の人生の分岐点である転職を一緒にやっていこうと思いました。
4.成果物についての情報
【実装環境】
Windows11
python3.11.0
GoogleColaboratory
Visual studio Code
完成したアプリは下記URLからアクセスして確かめてみてください!
https://g-discriminate3.onrender.com
↓↓↓ガンダムの名前はこちらを参考にして探してみてください↓↓↓
【判別したいガンダムの名前】 全10機
| 作品タイトル | 名前 |
|---|---|
| 機動戦士ガンダムSEED | ストライク、フリーダム |
| 機動戦士ガンダムSEED DESTINY | インパルス、デスティニー |
| 機動戦士ガンダム00 | エクシア、ダブルオー |
| 機動戦士ガンダムUC | ユニコーンガンダム |
| 機動戦士ガンダムAGE | AGE-1 |
| 機動戦士ガンダム 鉄血のオルフェンズ | バルバトスルプスレクス |
| 機動戦士ガンダム 水星の魔女 | エアリアル |
【使用技術:スクレイピング】
Aidemyのチューター様から教えていただいたコードを使って、ウェブサイトからガンダムの画像をスクレイピングしました。
!pip install icrawler
# Bing用クローラーのモジュールをインポート
from icrawler.builtin import BingImageCrawler
# Bing用クローラーの生成
bing_crawler = BingImageCrawler(
downloader_threads=4, # ダウンローダーのスレッド数
storage={'root_dir': 'ストライク'}) # ダウンロード先のディレクトリ名
# クロール(キーワード検索による画像収集)の実行
bing_crawler.crawl(
keyword="ストライクガンダム", # 検索キーワード(日本語もOK)
max_num=200) # ダウンロードする画像の最大枚数
序盤で一番苦労したのが画像収集です。最初は、32機のガンダムを判別させようと考え、各機約100枚かつ自力で画像を集めたため、とても時間がかかりました。また、検索した画像の中には、改造ガンプラの画像や全く同じ画像も含まれていたため、それを抜きながら画像を保存していくのが大変でした。
5.機械学習
ここからは、実際に作成したコードを記載していきます。まずは、画像の処理やラベル作成のためのコードです。
from google.colab import drive #GoogleDriveのマウント
drive.mount('/content/drive')
import glob
import os
import cv2 #画像処理用のライブラリ
import numpy as np #データ処理のパッケージ
import matplotlib.pyplot as plt #データの可視化
import pandas as pd#データ分析用のライブラリ
folder_paths=glob.glob("/content/drive/MyDrive/GUMDAM_10/")
folder_paths
#/content/*はご自身のgoogleDriveのパス
folder_paths=glob.glob("/content/drive/MyDrive/GUMDAM_10/*")
img_list=[]
label_list=[]
image_size = 250
for folder_path in folder_paths:
folder_path=folder_path+"/*"
image_paths=glob.glob(folder_path)
for image_path in image_paths:
if image_path.endswith(".jpg"):
img = cv2.imread(image_path)
#画像のサイズの揃える※サイズは要検討
img=cv2.resize(img,(image_size, image_size))
#画像処理入れるならここに
img_list.append(img)
label_list.append(image_path)
img_np=np.array(img_list)
img_np=np.reshape(img_np,[-1,image_size, image_size, 3])
#ラベル作成のための辞書作成
#splitの※2は調整必要
#label_list[1].split("/")で確認可能
split_label=[label.split("/")[5] for label in label_list]
label_set=set(split_label)
label_dict={}
for label_idx,label in enumerate(label_set):
label_dict[label]=label_idx
#ラベル作成
label_num_list=[]
for label in label_list:
#splitの※2は調整必要
#label_list[1].split("/")で確認可能
label_num=label_dict[label.split("/")[5]]
label_num_list.append(label_num)
label_np=np.array(label_num_list)
label_dict #各ガンダムに割り振られたラベルの表示
#各フォルダに入っている画像の表示
folder_paths=glob.glob("/content/drive/MyDrive/GUMDAM_10/*")
for folder_path in folder_paths:
folder_path=folder_path+"/*"
image_paths=glob.glob(folder_path)
print(image_paths)
np.unique(label_np) #ラベルの表示
img_np.shape #全画像の枚数とサイズ
【使用技術:機械学習】
ここからは、実際の学習を行うコードです。今回、モデルにはvgg16を選択。学習済みのモデルを使うことで、比較的短時間での学習を目指しました。
import os
import cv2 #画像処理用のライブラリ
import numpy as np #データ処理のパッケージ
import matplotlib.pyplot as plt #データの可視化
import pandas as pd#データ分析用のライブラリ
import tensorflow
from tensorflow.keras import optimizers
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input, Conv2D
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(img_np, label_np, test_size=0.2)
#男女識別2.1.4より
#vgg16を使って転移学習を行う
input_tensor = Input(shape=(image_size, image_size, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
#top_model.add(Dropout(rate=0.5))
top_model.add(Dense(128, activation='relu'))
top_model.add(Dropout(rate=0.5))
top_model.add(Dense(10, activation='softmax'))
#入力はvgg.input, 出力は, top_modelにvgg16の出力を入れたもの(男女識別2.1.3より)
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
#vgg16による特徴抽出部分の重みを固定
for layer in model.layers[:19]:
layer.trainable = False
#コンパイル
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])
#学習 バッチサイズ=2のn乗 エポック数=学習回数
history = model.fit(X_train, y_train, batch_size=32, epochs=60, validation_data=(X_test, y_test))
hist_df = pd.DataFrame(history.history)
#男女識別2.1.3より
for i in range(5):
x = X_test[i]
plt.imshow(x)
plt.show()
pred = np.argmax(model.predict(x.reshape(1,image_size,image_size,3)))
print(pred)
#精度の評価
score = model.evaluate(X_test, y_test, batch_size=32, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
# 可視化
plt.figure()
hist_df[['accuracy', 'val_accuracy']].plot()
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.show()
#モデルを保存
model.save("model.h5")
※今回、画像の合計枚数が1066枚あったため、画像の水増しや加工はしていません。
6.アプリを作ってみての課題
1.精度
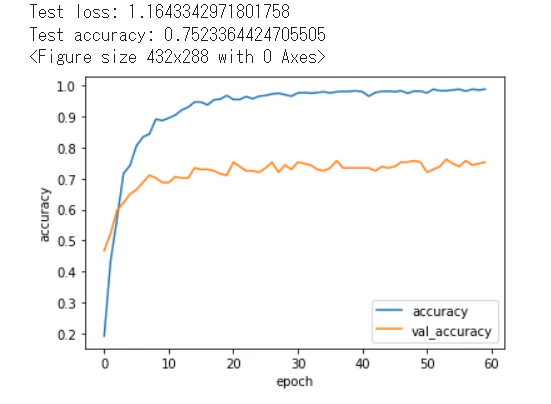
今回アプリを作ってみての課題は、精度(Accuracy)が上がらなかったことです。最初は全32機のガンダムの判別をしようと思ったのですが、いざ実行してみると精度はおよそ10%までしか上がりませんでした。32機分の画像の学習はデータが多すぎたようです。チューター様の提案で、32機ではなく10機にしたことで精度はおよそ70%まで上昇させることができました。
2.公開
いざアプリとして実装しようとしましたが、今度は学習した画像のサイズが大きく、Renderへデプロイする際に使うメモリーをオーバーしていまい、デプロイができませんでした。これもチューター様の提案で、画像サイズを500から250にすることにしたことで、ようやくデプロイすることができました。
結果として、画像サイズ250、エポック数60回、精度(Accuracy)はおよそ75%まで到達。たまに間違えることはありますが、何とかアプリとして実装することができました。

↓↓↓こちらが今回の評価指標に使った精度(Accuracy)をグラフ化したものです↓↓↓
7.Pythonを学んでみて
3カ月間という短い期間でしたが、pythonというプログラミング言語を勉強してきました。プログラミング初心者であったため、ここのコードの何がどうなっているのか、まったく分からないことが多かったです。しかし、Slackで質問したり、チューター様に何度もカウンセリングしていただいたりして、分からないものが分かるようになり、実行結果が正しく返ってきたときに感じた達成感は、学んでよかったと思える最高の瞬間でした。きっと、まだまだ勉強が足りないところがあると思うので、これからもpythonをはじめ、色々なプログラミング言語の学習を続けていきます!
8.終わりに
このブログが完成する頃には、転職活動が本格的にスタートし、何社か面接を受けているかと思います。今回、Aidemyの講座で学習したことを活かし、プログラマ―・エンジニアとしての人生を歩みつつ、色々な製品やアプリの作成に携わっていけたらなと思います。拙い文章であったかと思いますが、最後まで読んでいただきありがとうございました。