はじめに
Elasticsearchでログを取り込むと言えばBeatsかLogstash、という方も多いと思いますが、Kibanaから集中管理できるElastic Agentが広く使われています。
Elastic Agentについてはこちらの記事をご参照ください。
https://qiita.com/yukshimizu/items/abec12ac46749db46b40
BeatsやLogstashでは取得側でパース等の設定をしていましたが、Elastic AgentではIngest Pipelineを使用してElasticsearch側でパースを行います。
Ingest Pipelineについてはこちらに正式ドキュメントがあります。
https://www.elastic.co/guide/en/elasticsearch/reference/8.11/ingest.html
本記事ではElastic AgentのIngegrationsが用意されていないOpenLDAPのログをGrokを用いてIngest Pipelineでパースを行ってインデックス手順を解説いたします。
因みにIntegrationsというのは、BeatsのModuleのようなもので、ApacheやNGINXなどログフォーマットが予めわかっているログをパースするIngest Pipelineが事前に用意されていて、Dashboard等も自動で作成する機能です。
以下の内容になっていますので、OpenLDAPのログがすでにある場合にはOpenLDAPの設定などは飛ばしてください。
- OpenLDAPとログイン用アプリ設定
- Elastic Agent設定・インストール
- Ingest Pipeline設定
Elastic Cloudにクラスタを作成
(既にある場合は必要ありません)
こちらのブログをベースにElastic Cloudにクラスタを展開します。
https://qiita.com/tomo_s_el/items/3584d0b1fabb0bafa4fa
動作環境
Dockerが動けば特に環境は問いません。
OS: Linux (ubuntu 20.04)
VM: Azure Standard DS1 v2
Docker: 24.0.5
Docker Compose: v2.20.2
Elasticsearch (Elastic Cloud): 8.11.1
OpenLDAPとログイン用アプリ設定
まずOpenLDAPのログを作るためにOpenLDAPを立てて、認証を行う簡単なアプリを立ち上げます。
docker composeで立ち上げます。
こちらのリポジトリにソースコードがあります。
https://github.com/legacyworld/customlogs_ldap
基本的に何も設定は必要ありません。
OpenLDAP
OpenLDAPのDocker Imageはこちらを利用しています。
https://github.com/osixia/docker-openldap
以下のDockerfileでbuildします。
FROM osixia/openldap
RUN apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 0E98404D386FA1D9
RUN apt-get update && apt-get install -y rsyslog
COPY user.ldif /container/service/slapd/assets/config/bootstrap/ldif/custom
COPY logging.ldif /container/service/slapd/assets/config/bootstrap/ldif/custom
COPY rsyslog.conf /etc
- Ubuntuの
apt-key- こちらを参考にしました
- https://zenn.dev/takc923/articles/391ea8a4e03f43
- ldifファイル
- ldifファイルを指定されたフォルダにおいておくと起動時に設定してくれます
-
user.ldif- testuser{1..4}を追加しています
-
logging.ldif- syslogにログを出力する設定
- rsyslog.conf
- 時間のフォーマットを変更(usまで表示)
OpenLDAPのadminアカウントはdocker-compose.ymlで設定します。
environment:
- LDAP_LOG_LEVEL=128
- LDAP_DOMAIN=example.com
- LDAP_ADMIN_PASSWORD=password
ログインアプリ
こちらを参考にしました。
https://www.osstech.co.jp/~hamano/posts/flask-login-ldap/
元記事のソースコードからは少し変更しています。
- importの変更
-
FromからFlaskFormに変更 -
TextFieldからStringFieldに変更 -
logging追加
-
- LDAPの設定
- LDAP URLをコンテナ名に変更
- DNを
user.ldifの設定に合わせて変更
- logging
-
/log/flask.logに出力するように変更
-
起動
customlogs_ldapディレクトリでdocker compose up -d
立ち上がったらOpenLDAPのコンテナ上でrsyslogを起動します。
docker exec -it openldap service rsyslog start
UIからの認証
http://localhost:5000
で以下の画面が開きます。

testuser1/passwordと入力すると以下のように表示されます。

パスワードを間違えるとページは遷移しません。
log/syslogには以下のように表示されています。
2023-11-30T02:58:06.927861+00:00 1fb5472bef24 slapd[441]: conn=1000 fd=12 ACCEPT from IP=192.168.48.3:54620 (IP=0.0.0.0:389)
2023-11-30T02:58:06.928033+00:00 1fb5472bef24 slapd[441]: conn=1000 op=0 BIND dn="uid=testuser1,ou=people,dc=example,dc=com" method=128
2023-11-30T02:58:06.928162+00:00 1fb5472bef24 slapd[441]: conn=1000 op=0 BIND dn="uid=testuser1,ou=people,dc=example,dc=com" mech=SIMPLE ssf=0
2023-11-30T02:58:06.928283+00:00 1fb5472bef24 slapd[441]: conn=1000 op=0 RESULT tag=97 err=0 text=
2023-11-30T02:58:06.929043+00:00 1fb5472bef24 slapd[441]: conn=1000 op=1 UNBIND
2023-11-30T02:58:06.929547+00:00 1fb5472bef24 slapd[441]: conn=1000 fd=12 closed
本記事ではこのログをパースしていきます。
スクリプトでログ生成
docker exec -it app python test.pyを実行するとランダムにLogin IDを選び、10%ほどでパスワードを間違えます。
Elastic Agentの設定
Integrationの設定
ここではログの絶対パスを設定するだけです。
KibanaメニューのManagement -> Integrationsとクリックします。
検索バーにcustom logsと入力し、赤枠で囲った部分をクリックします。
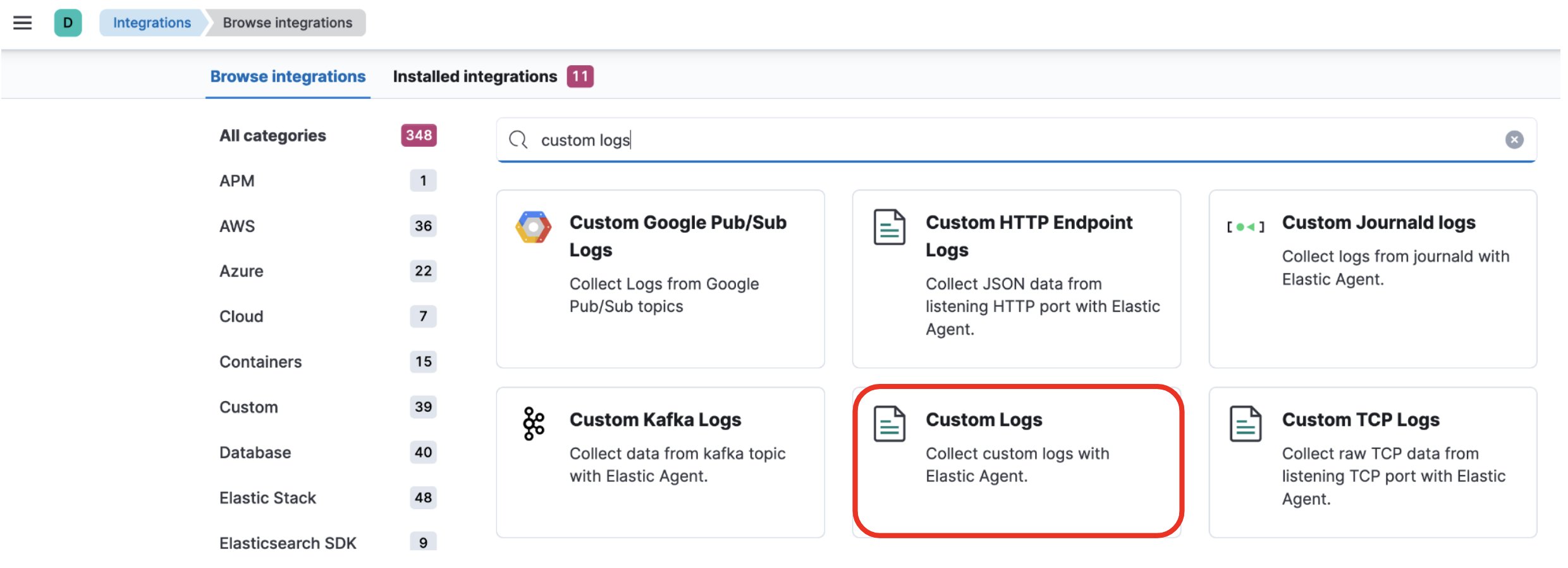
右上のAdd Custom Logsをクリック

初回のみこの画面が開くこともあります。Add Integration only(skip agent installation)をクリックします。

次の画面では2箇所入力が必須です。
- Log file path
- customlogs_ldap/log/syslogの絶対パスを記入
- Dataset name
- インデックスの名前に使用します。ここではldapと入力
最後に右下のSave and Continueをクリック

- インデックスの名前に使用します。ここではldapと入力
暫くすると以下のダイアログが出てきますので、Add Elastic Agent to your hostsをクリック

Elastic Agentのインストール
以下のような画面が表示されるので、Install Elastic Agent on your hostの部分でOpenLDAPをインストールした環境を選択する(下記のキャプチャではLinuxへのインストール例)
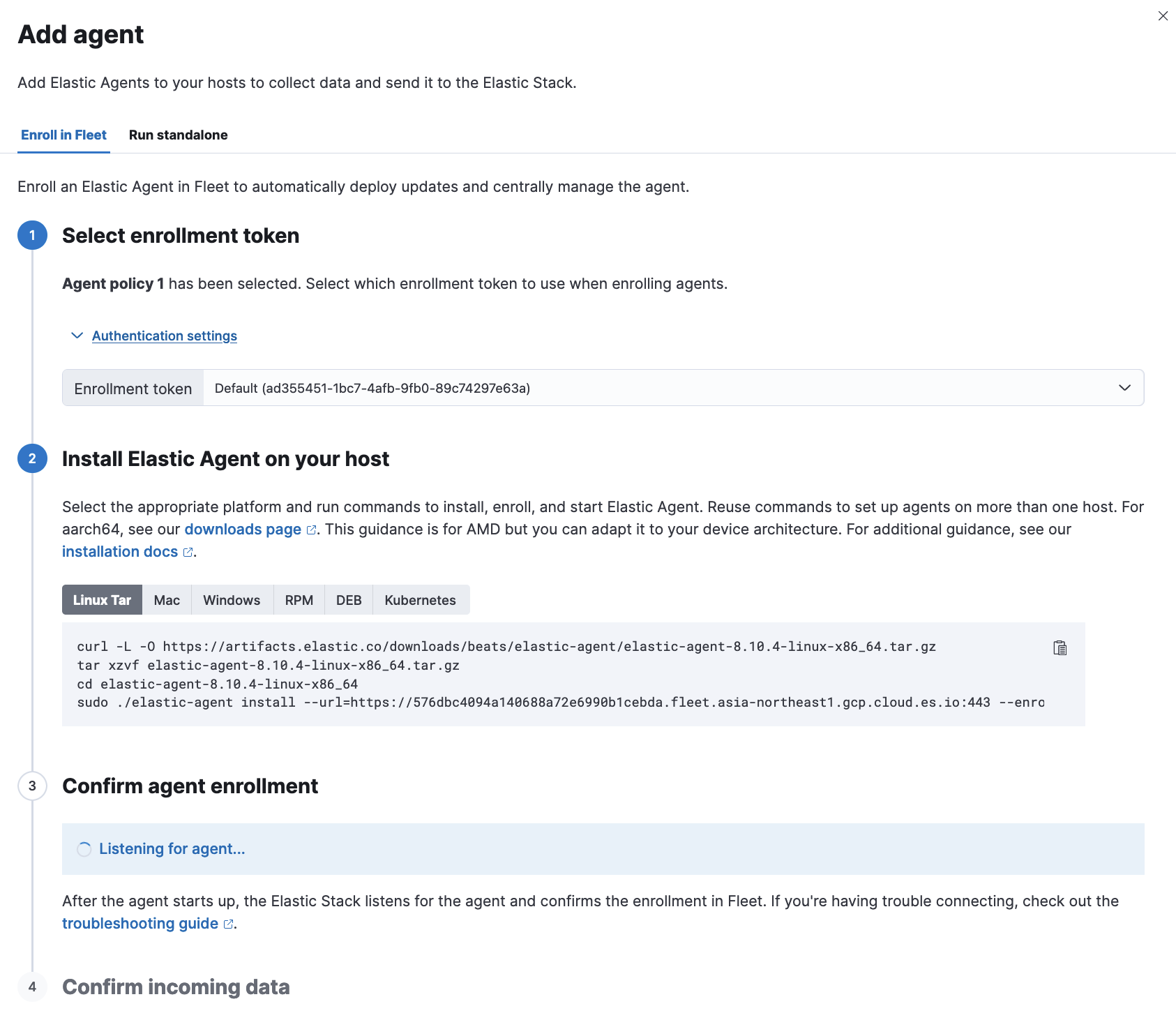
問題なければConfirm agent enrollmentのところが以下のようになります。

Management -> Fleetとクリックすると、以下のように登録されていることがわかります(Hostのところの名前は各自環境で変わります)
もう一つ表示されていると思いますが(下記だとd714a2d93a83)、これは気にしなくても良いです。

データの確認
データが取り込まれているので確認してみます。
Management -> Stack Management -> Kibana -> Dataviewをクリックします。
Dataviewはどのインデックスを処理するか、という単位です。
いろんなログファイルを一括で処理したい場合、logsというDataviewで*logs*にマッチするインデックスを纏めて処理する、ということが出来ます。
今回はlogs-ldap-defaultという名前で自動的にインデックスが作成されています。
Elastic Agentで取得したログの命名規則は下記のページの参照してください。
https://www.elastic.co/guide/en/fleet/8.11/data-streams.html#data-streams-naming-scheme
下記のページで右上のCreate data viewをクリックします。
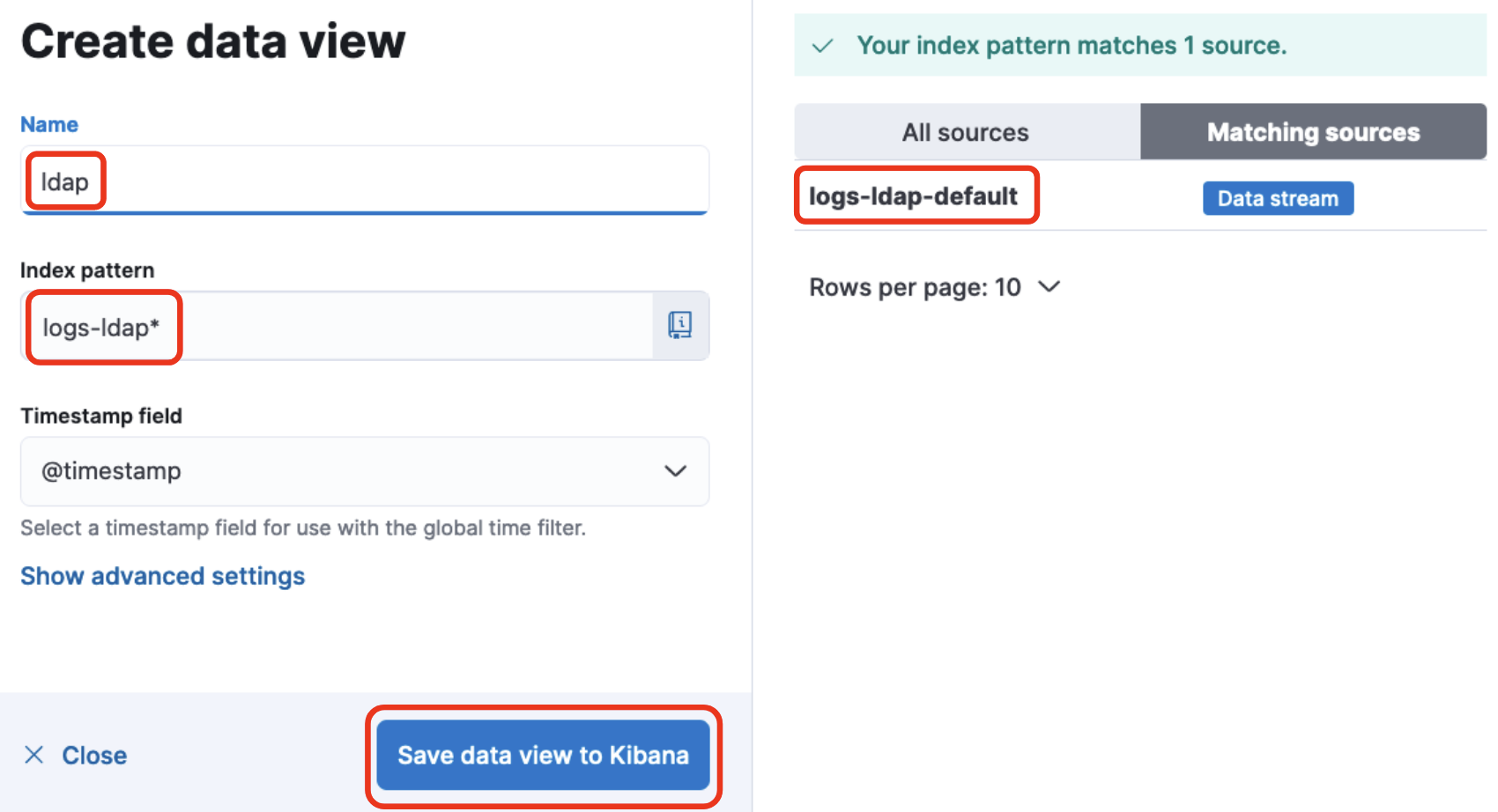
以下のように入力します。
- Name
- ldap (これは任意です)
- Index pattern
- logs-ldap*
- logs-ldapから始まるインデックス全て表示するという設定
- logs-ldap*
右側にlogs-ldap-defaultと表示されていることを確認して、Save data view to Kibanaをクリックして保存します。
では実際にデータを見てみましょう。
Analytics -> Discoverをクリックします。先程作成したDataviewの名前(ここではldap)を選ぶと右側にログが表示されます。

更に右側の赤枠で囲っている矢印をクリックするとログの詳細を見ることが出来ます。

これを見ると既にパースされているように見えますね?
でも残念ながら違います。ここにあるIPアドレスやホスト名などはElastic Agentが自動的に収集するデータで、OpenLDAPのログは含まれていません。
OpenLDAPのログはmessageというフィールドに入っています(右下の2をクリックすると表示されます)

このままだとuidやouでグラフ化したり出来ません。
ではこれをパースするingest pipelineを作成していきます。
Ingest Pipeline作成
messageフィールドに入っているデータからconnection id,uid,ouといった値を個別に取り出すのはIngest Pipelineの役割です。
https://www.elastic.co/guide/en/elasticsearch/reference/current/ingest.html
このPipelineのGrokを使います。
https://www.elastic.co/guide/en/elasticsearch/reference/current/grok-processor.html
Logstash等で慣れている方も多いと思いますが、空白や文字などで区切っていくものです。
では早速以下のログを全てパースできるようにしていきます。
2023-11-30T02:58:06.927861+00:00 1fb5472bef24 slapd[441]: conn=1000 fd=12 ACCEPT from IP=192.168.48.3:54620 (IP=0.0.0.0:389)
2023-11-30T02:58:06.928033+00:00 1fb5472bef24 slapd[441]: conn=1000 op=0 BIND dn="uid=testuser1,ou=people,dc=example,dc=com" method=128
2023-11-30T02:58:06.928162+00:00 1fb5472bef24 slapd[441]: conn=1000 op=0 BIND dn="uid=testuser1,ou=people,dc=example,dc=com" mech=SIMPLE ssf=0
2023-11-30T02:58:06.928283+00:00 1fb5472bef24 slapd[441]: conn=1000 op=0 RESULT tag=97 err=0 text=
2023-11-30T02:58:06.929043+00:00 1fb5472bef24 slapd[441]: conn=1000 op=1 UNBIND
2023-11-30T02:58:06.929547+00:00 1fb5472bef24 slapd[441]: conn=1000 fd=12 closed
Grokでは前から順に区切っていくのが楽です。全てに共通している2023-11-30T02:58:06.927861+00:00 1fb5472bef24 slapd[441]: conn=1000をまず切ります。
Management -> Stack Management -> Ingest Pipelineを選び、右上のCreate pipelineからNew pipelineをクリックします。
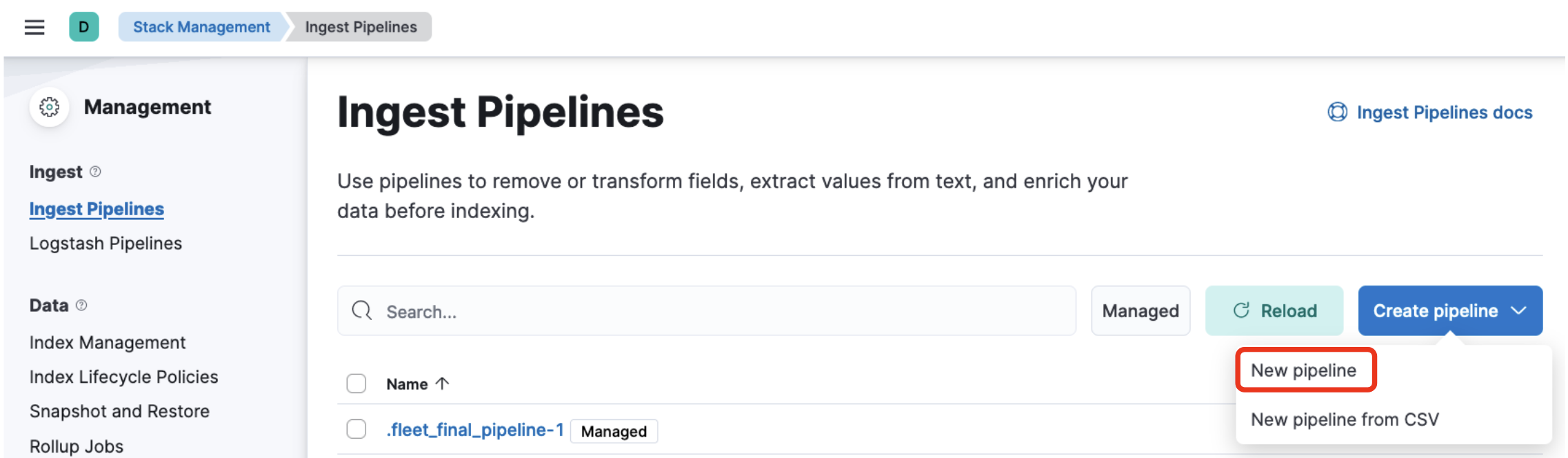
以下の画面が開きます。
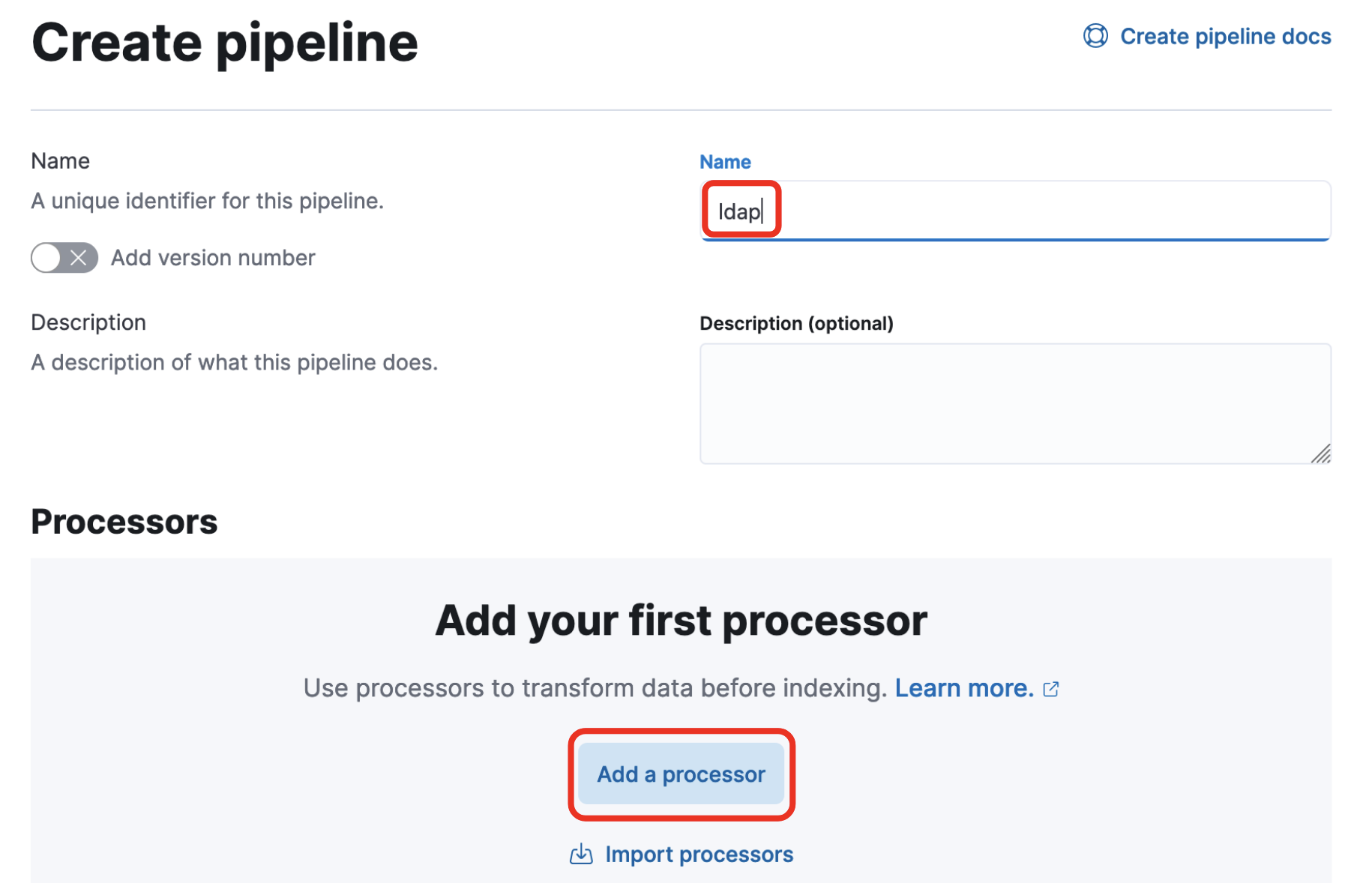
- Name
- ldapと入力(任意です)
1つ目のGrok
真ん中にあるAdd a processorをクリックすると右側に以下の画面が出てくるので設定をしていきます。

- ProcessorにGrokを選択
- Fieldにmessageと入力
- Patternsに以下を入力
%{TIMESTAMP_ISO8601:@timestamp} %{HOSTNAME:host.name} %{WORD:process.name}\[%{NUMBER:process.pid:int}\]: conn=%{NUMBER:connection_id:int} %{GREEDYDATA:rest}-
%{}の中身で右側(@timestampとか)がElasticsearchでのフィールド名になり、@timestampに時間が格納される - 共通項以外は一旦
restというフィールドに収める

2つ目のGrok
ここからAdd a processorをクリックして直列に処理を繋いでいきます。
次はfdかopで分かれますので、複数処理を書いていきます。

- 処理するフィールドには
restを入力します - 先程最後に残した
restに対して処理を行います。-
fd=%{NUMBER:fd:int} %{WORD:action} from IP=%{IP:source.ip}:%{NUMBER:source.port:int} \(IP=%{IP:destination.ip}:%{NUMBER:destination.port:int}\)- 最初は
fd=12 ACCEPT from IP=192.168.48.3:54620 (IP=0.0.0.0:389)にマッチするように記述 - これにマッチしなかったら次のパターンが処理される
- 最初は
-
op=%{WORD:operation} %{WORD:action} %{GREEDYDATA:rest}- opから始まるものは4種類あるので一旦
restに格納
- opから始まるものは4種類あるので一旦
-
fd=%{NUMBER:fd:int} %{WORD:action}-
fd=12 closedにマッチ
-
-
op=%{WORD:operation} %{WORD:action}- 上のGREEDYDATAの部分には
op=1 UNBINDがマッチしないのでこれを追加
- 上のGREEDYDATAの部分には
-
3つ目のGrok
次にopから始まるものを切っていきます。

- 更に
restに対して処理を行いますdn="uid=%{DATA:uid},ou=%{DATA:organizational_unit},dc=%{DATA:domain_component},dc=%{DATA:top_level_domain}" %{GREEDYDATA:rest}tag=%{NUMBER:tag:int} err=%{NUMBER:err:int} text=%{DATA:result_text}
- このプロセスからここでは全くマッチしないパターンが出てきますので(fdが入っているもの)、エラーで止まらないように一番下にあるIgnore failures for this processorをチェックしておきます

4つ目のGrok
最後にdn=から始まる2パターンについて区切ります。

method=%{NUMBER:method:int}mech=%{DATA:mech} ssf=%{NUMBER:ssf:int}
これで全パターンを区切ることが出来ます。
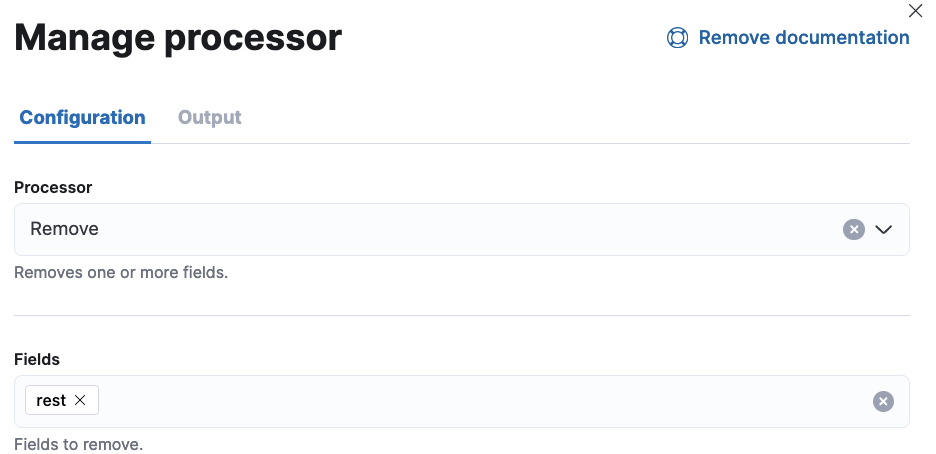
Remove
最後にrestフィールドは必要ないので消しておきます。
On Failure
一応失敗したときの処理も加えておきます。

Failure procesorsのAdd a processorをクリックして、以下のように入力します。
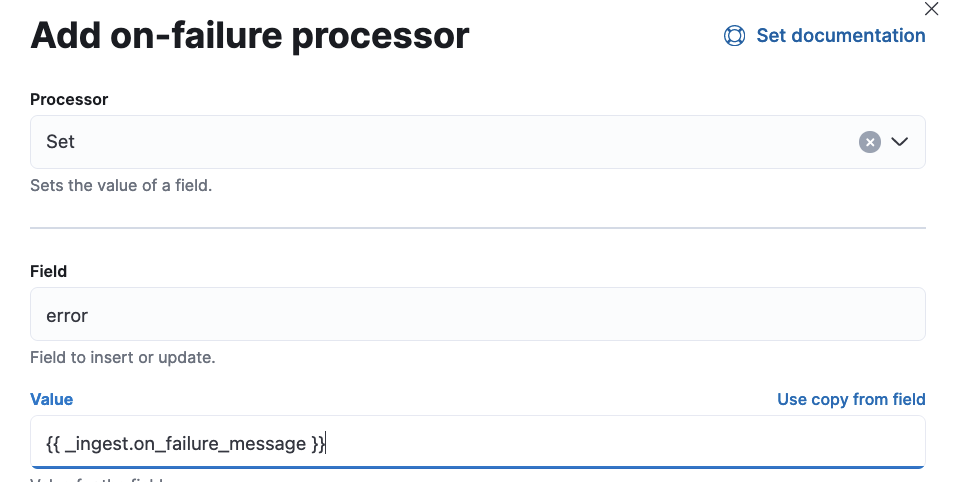
Valueに記載している{{ _ingest.on_failure_message }}はエラーの内容です。
最終形
最終的にこうなっていると思います。

Save pipelineを最後にクリックするのを忘れないようにしましょう。
いちいち入力が面倒くさい方へ
pipeline.jsonの中身をコピーして、Management -> Dev Toolsを開きます。
コピーした内容を左側に貼り付けて、右上の矢印をクリックすると上記の設定が全て行われます。

IntegrationsでIngest Pipelineの使用を設定
先ほど作成したIngest Pipelineは作っただけでは勝手には使用されません。Elastic AgentのCustom Logs Integrationsで設定します。
Management -> FleetでElastic Agentをインストールしたホストの横にあるAgent Policyを選びます。(ここではAgent Policy 1)

以下の画面に移るので、Custom LogsのName(ここではlog-1)をクリックします。

先程設定したCustom Logsの設定画面が開きますので、Change defaults、Advanced optionsとクリックして、設定画面を開いていきます。
下記のCustom configurationにpipeline: ldapと入力し、右下のSave integrationsをクリックして保存します。

これでingest pipelineで行われる処理が反映されているはずです。
この手順は以下に記載されています。
https://www.elastic.co/guide/en/elasticsearch/reference/master/ingest.html#pipeline-custom-logs-configuration
Discoverで確認
ではDiscoverでパースされているかどうか確認してみましょう。
uidが入っているログを選んでみてみましょう。

確かにuidがちゃんとフィールドとして入っています。
では、左側のフィールド一覧を一番下までスクロールしてuidをクリックしてみます。
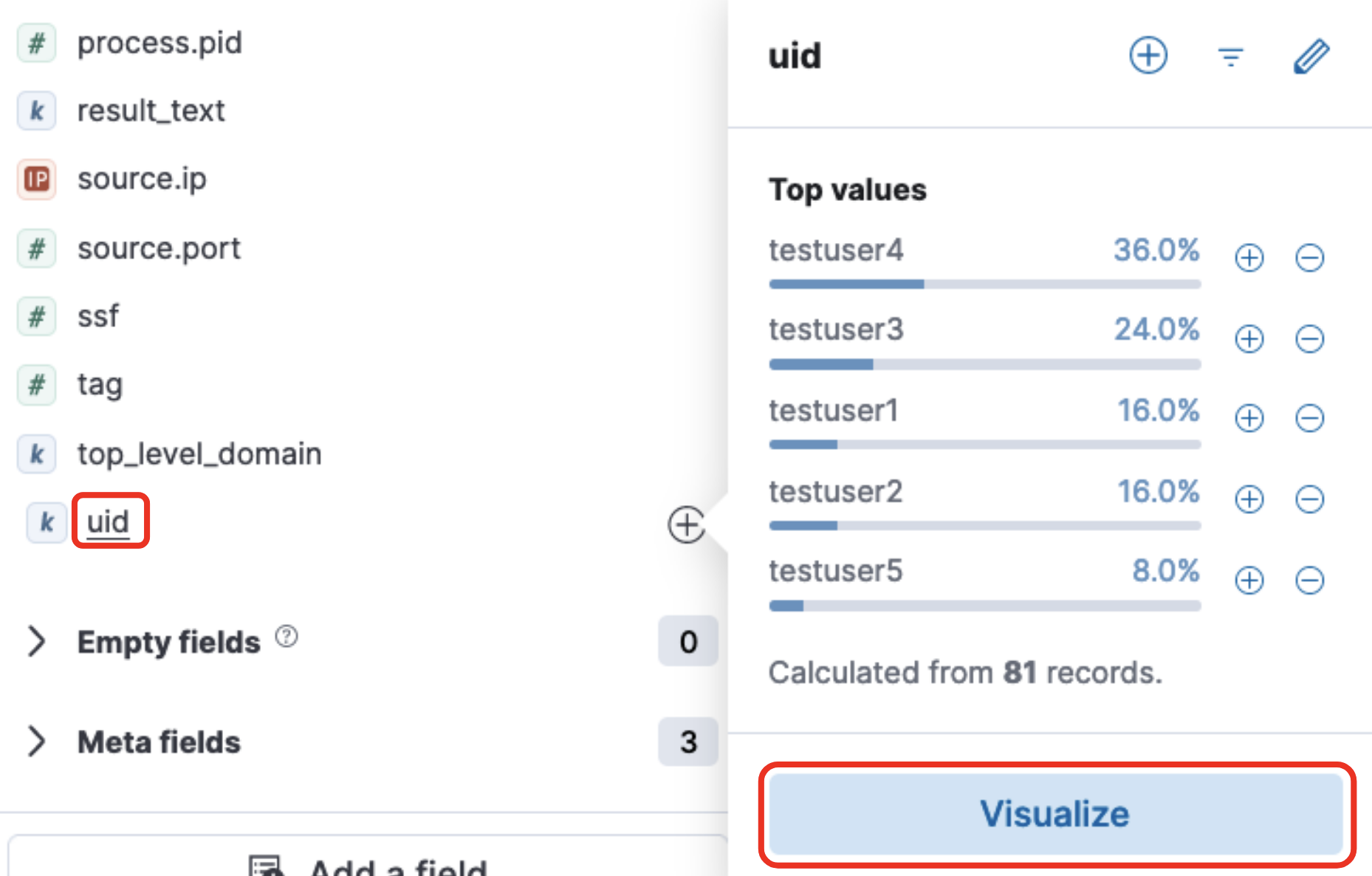
右側にuidの値の分布が表示されます。下のVisualizeをクリックしてみましょう。

これがLensというKibanaの可視化ツールです。ここで先程パースしたいろいろなデータを可視化してみてください。
まとめ
よく使われるソフトやFirewall機器等は元々Integrationsが用意されているため、このような手順は必要ありません。
ただ独自のアプリケーションなどのログを取り込む場合はどうしてもこのような作業が必要となりますが、一度パースしてしまえば、Kibanaの強力な可視化ツールでデータを分析することが可能となります。
是非とも挑戦してみてください。
おまけ:Grokについて
Grokパターンはあっているかどうか確かめながら行うことになると思います。KibanaにはGrokデバッガというそのためのツールを用意してあります。
Management -> Dev Tools -> Grok Debuggerで以下の画面が開きます。

Sample Dataにログを入れて、Grok Patternに試してみたいパターンを入れて、Simulateをクリックすると、Elasticsearchでどのように区切られるかが表示されます。
今回のリポジトリを使用してもらうと、Flaskのログも同じlogフォルダにflask.logとして出力されています。
127.0.0.1 - - [02/Dec/2023 06:02:04] "GET /login?next=/ HTTP/1.1" 200 -
127.0.0.1 - - [02/Dec/2023 06:02:04] "POST /login HTTP/1.1" 200 -
これのパースにも是非チャレンジしてみてください。