はじめに
生成AIの使い方の一つであるRAG(Retrieval Augmented Generation)について以下の記事を先日書きました。
https://qiita.com/takeo-furukubo/items/e5d43fa734e4338b895f
この利用方法では実はまずファイルにあるテキストデータを抽出してElasticsearchにインデックスする必要があります。
本記事では実際にWindowsにあるファイルからテキストを抽出してElasticsearchにインデックスを行います。
Connector
Connectorというのはユーザが検索したい元データ(PDF,Text File,Office系ドキュメントなど)からテキストを抽出して、Elasticsearchで全文検索できるようにするものです。
生成AIの使い方の一つであるRAG(Retrieval Augmented Generation)の初手になる部分です。
Elasticsearchにはテキストを入れますので、様々なファイルからテキストを抽出してから、属性情報を追加してインデックス化します。

ここでConnectorには2種類あります。
- Native Connector
- Elastic側で管理していて、設定だけ入力するとそのまま利用可能
- Connector clients
- ユーザ側で運用・管理するもの
SharepointやGoogle Driveなどクラウド上にあるデータであればNative Connectorが便利ですが、オンプレミスにあるデータの場合は外部からのアクセスは難しいので、Connector clientsを使います。
今回はオンプレミスのWindowsからConnector clientsを使ってテキスト抽出する方法の解説です。
環境
Windows 10 Pro / 21H2 / 19044.2130
Docker Desktop for windows: v24.0.6
Elasticsearch: 8.11.1 (Elastic Cloud)
データを集めるConnectorをコンテナ上で動かします。WindowsにDocker Desktopをインストールしておいてください。
Elastic Cloud
(既にある場合は必要ありません)
こちらのブログをベースにElastic Cloudにクラスタを展開します。
https://qiita.com/tomo_s_el/items/3584d0b1fabb0bafa4fa
Connector clients設定
KibanaメニューからSearch -> Contentと選び、右上のCreatea new indexをクリック

次にUse a connectorをクリックします。因みにデータの抽出ツールは今回ご紹介するConnectorも入れて3種類用意しています。他の2つはこちらです。
- Crawler
- Web Siteからデータを引っ張ってくる
- API
- APIでデータを持ってくる

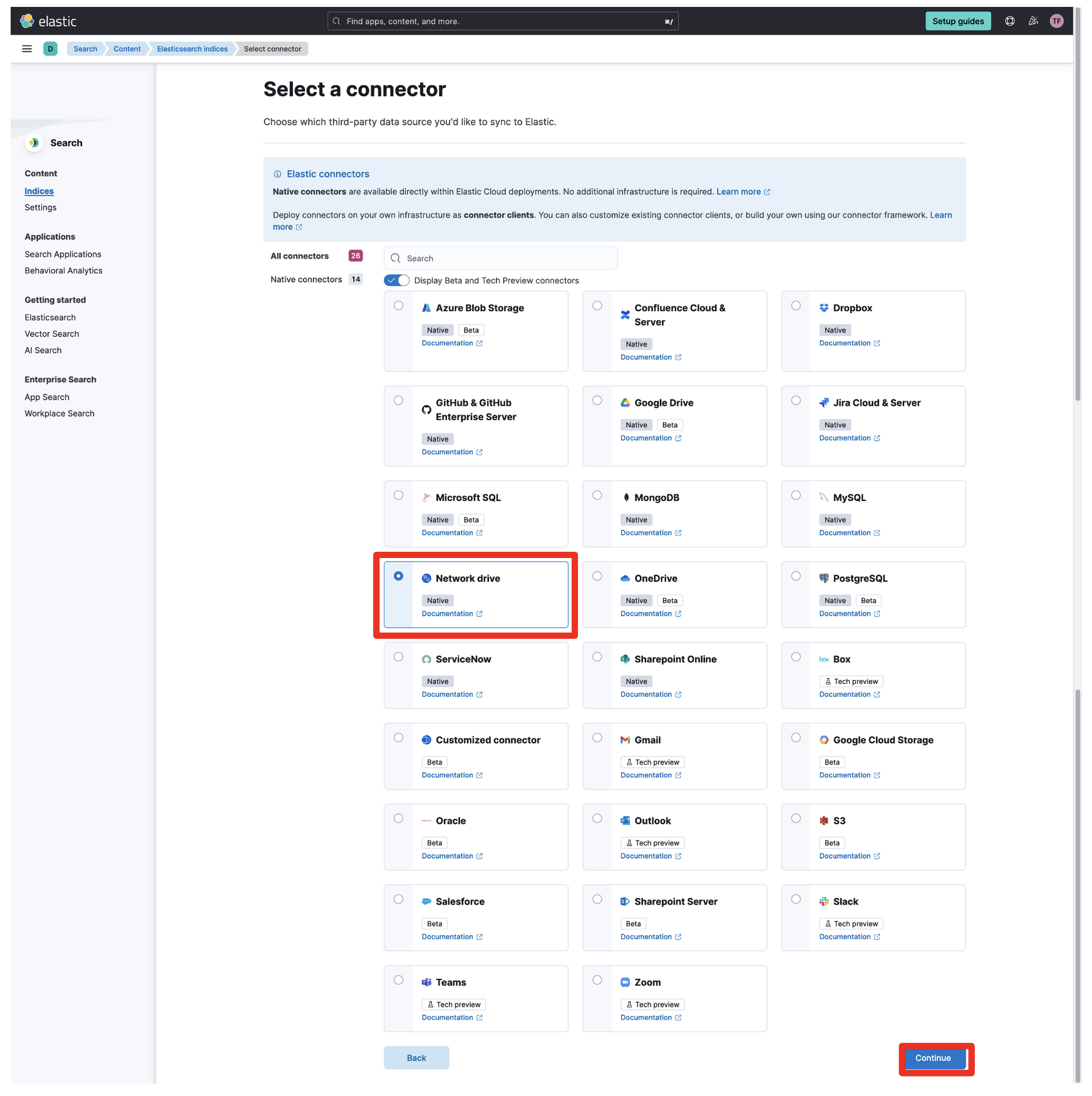
次の画面でNetwork Driveを選択して、右下のContinueをクリック
因みにNetwork DriveはSMB v2/v3のみです。
次の画面ではインデックスの名前を入力します。search-が必ず頭に付きます。以下の例だとsearch-windows-driveという名前のインデックスが作成されます。入力したら右下のCreate Indexをクリック。
Language Analyzerは日本語を選んでも形態素解析は行われないので、後ほど設定します。

次の画面では右側にあるConvert connectorをクリックします。デフォルトではNative Connectorとして扱われるためです。
このような脅しが出てきますが、インデックス毎に変更できるので気にせずYesを押しましょう。

最後に設定を入れていきます。
まずはGenerate API KeyをクリックするとAPI Keyが表示されるので、コピーして何処かに保存しておきましょう。この画面から移ると表示されなくなるので、保存していなかった場合は再作成する必要があります。
次にWindowsの認証情報を入れます。
Username,password,IP address,Pathを入力します。Portは必要に応じて変更してください。
最後にEnable document level securityをチェックしてSave configurationをクリックします。
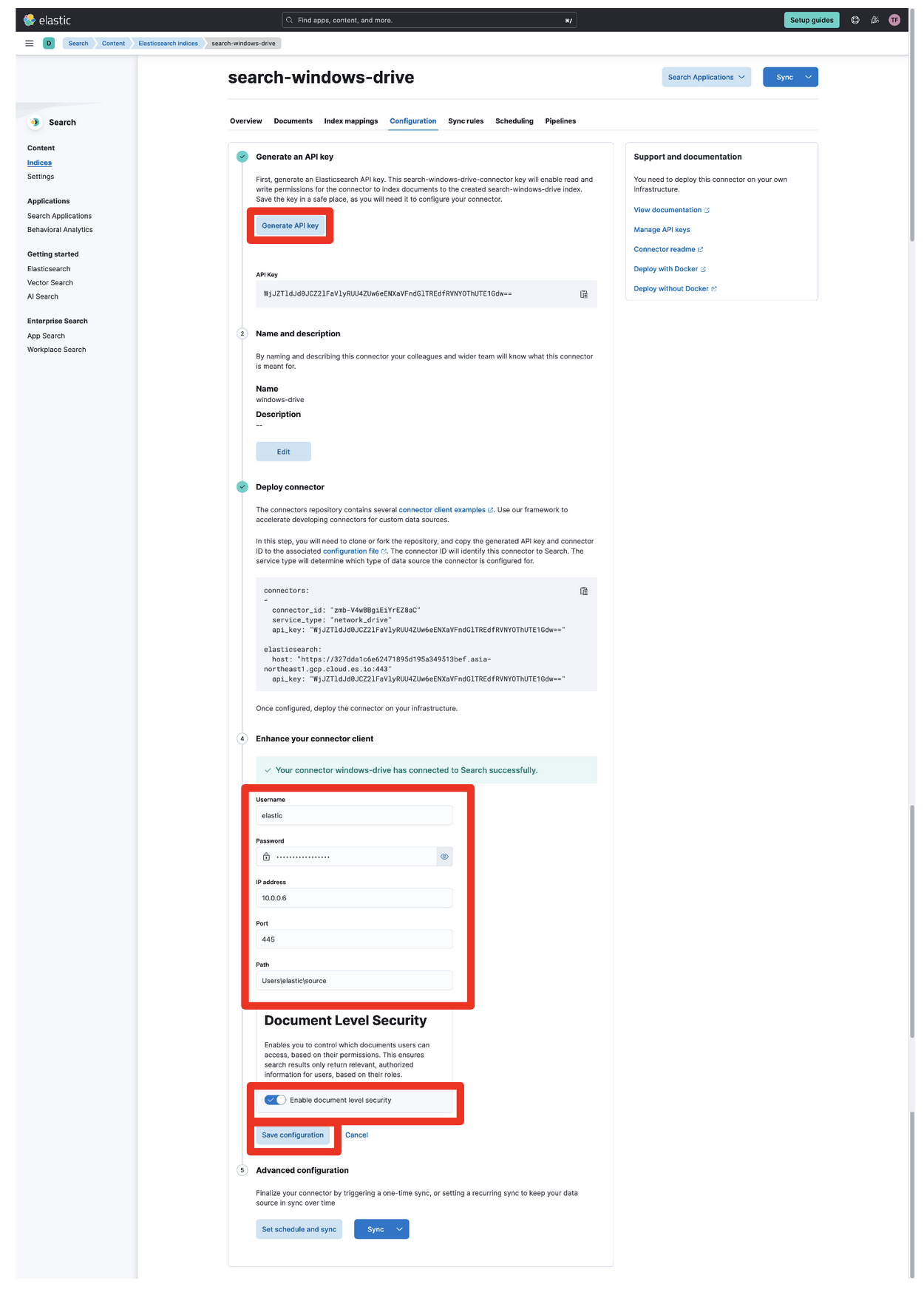
次にWindows上で動くConnector clientsを設定していきます。Deploy connectorの下にあるconnectors:から始まる部分をコピーしておきます。
ですが、その前に日本語対応の設定を行います。
日本語(形態素解析)設定
インデックスclose
日本語の全文検索には特別な処理が必要です。詳細は下記リンクを参照して下さい。
https://www.elastic.co/jp/blog/how-to-implement-japanese-full-text-search-in-elasticsearch
settingとmappingを変更する必要がありますが、インデックスを開いた状態では変更できませんので、まず一旦インデックスをcloseします。
Management->Dev Toolsと開いて、以下を入力して実行します。
POST search-windows-drive/_close
赤枠で囲った三角をクリックすると実行できます。右側に以下のように表示されると無事close出来ています。

settings/mappings変更
まず形態素解析を指定しているsettingsを変更します。この設定を入れることで形態素解析としてkuromojiを使う設定になります。
右側の画面にerrorが出ていないことを確認してください。
PUT search-windows-drive/_settings
{
"settings": {
"index": {
"analysis": {
"char_filter": {
"normalize": {
"type": "icu_normalizer",
"name": "nfkc",
"mode": "compose"
}
},
"tokenizer": {
"ja_kuromoji_tokenizer": {
"mode": "search",
"type": "kuromoji_tokenizer"
}
},
"analyzer": {
"kuromoji_analyzer": {
"tokenizer": "ja_kuromoji_tokenizer",
"char_filter": ["normalize"],
"filter": [
"kuromoji_baseform",
"kuromoji_part_of_speech",
"cjk_width",
"ja_stop",
"kuromoji_stemmer",
"lowercase"
]
}
}
}
}
}
}
次にどのフィールドに対して適用するかをmappingで決めます。長いですが、以下をDev Toolsで実行します。
PUT search-windows-drive/_mapping
{
"dynamic": "true",
"dynamic_templates": [
{
"data": {
"match_mapping_type": "string",
"mapping": {
"analyzer": "iq_text_base",
"fields": {
"prefix": {
"search_analyzer": "q_prefix",
"analyzer": "i_prefix",
"type": "text",
"index_options": "docs"
},
"delimiter": {
"analyzer": "iq_text_delimiter",
"type": "text",
"index_options": "freqs"
},
"joined": {
"search_analyzer": "q_text_bigram",
"analyzer": "i_text_bigram",
"type": "text",
"index_options": "freqs"
},
"enum": {
"ignore_above": 2048,
"type": "keyword"
},
"stem": {
"analyzer": "iq_text_stem",
"type": "text"
}
},
"index_options": "freqs",
"type": "text"
}
}
}
],
"properties": {
"_allow_access_control": {
"type": "text",
"fields": {
"delimiter": {
"type": "text",
"index_options": "freqs",
"analyzer": "iq_text_delimiter"
},
"enum": {
"type": "keyword",
"ignore_above": 2048
},
"joined": {
"type": "text",
"index_options": "freqs",
"analyzer": "i_text_bigram",
"search_analyzer": "q_text_bigram"
},
"prefix": {
"type": "text",
"index_options": "docs",
"analyzer": "i_prefix",
"search_analyzer": "q_prefix"
},
"stem": {
"type": "text",
"analyzer": "iq_text_stem"
}
},
"index_options": "freqs",
"analyzer": "iq_text_base"
},
"_subextracted_as_of": {
"type": "date"
},
"_subextracted_version": {
"type": "keyword"
},
"_timestamp": {
"type": "date"
},
"body": {
"type": "text",
"fields": {
"delimiter": {
"type": "text",
"index_options": "freqs",
"analyzer": "iq_text_delimiter"
},
"enum": {
"type": "keyword",
"ignore_above": 2048
},
"joined": {
"type": "text",
"index_options": "freqs",
"analyzer": "i_text_bigram",
"search_analyzer": "q_text_bigram"
},
"prefix": {
"type": "text",
"index_options": "docs",
"analyzer": "i_prefix",
"search_analyzer": "q_prefix"
},
"stem": {
"type": "text",
"analyzer": "iq_text_stem"
},
"japanese": {
"type": "text",
"analyzer": "kuromoji_analyzer"
}
},
"index_options": "freqs",
"analyzer": "iq_text_base"
},
"created_at": {
"type": "date"
},
"id": {
"type": "keyword"
},
"path": {
"type": "text",
"fields": {
"delimiter": {
"type": "text",
"index_options": "freqs",
"analyzer": "iq_text_delimiter"
},
"enum": {
"type": "keyword",
"ignore_above": 2048
},
"joined": {
"type": "text",
"index_options": "freqs",
"analyzer": "i_text_bigram",
"search_analyzer": "q_text_bigram"
},
"prefix": {
"type": "text",
"index_options": "docs",
"analyzer": "i_prefix",
"search_analyzer": "q_prefix"
},
"stem": {
"type": "text",
"analyzer": "iq_text_stem"
}
},
"index_options": "freqs",
"analyzer": "iq_text_base"
},
"size": {
"type": "long"
},
"title": {
"type": "text",
"fields": {
"delimiter": {
"type": "text",
"index_options": "freqs",
"analyzer": "iq_text_delimiter"
},
"enum": {
"type": "keyword",
"ignore_above": 2048
},
"joined": {
"type": "text",
"index_options": "freqs",
"analyzer": "i_text_bigram",
"search_analyzer": "q_text_bigram"
},
"prefix": {
"type": "text",
"index_options": "docs",
"analyzer": "i_prefix",
"search_analyzer": "q_prefix"
},
"stem": {
"type": "text",
"analyzer": "iq_text_stem"
},
"japanese": {
"type": "text",
"analyzer": "kuromoji_analyzer"
}
},
"index_options": "freqs",
"analyzer": "iq_text_base"
},
"type": {
"type": "text",
"fields": {
"delimiter": {
"type": "text",
"index_options": "freqs",
"analyzer": "iq_text_delimiter"
},
"enum": {
"type": "keyword",
"ignore_above": 2048
},
"joined": {
"type": "text",
"index_options": "freqs",
"analyzer": "i_text_bigram",
"search_analyzer": "q_text_bigram"
},
"prefix": {
"type": "text",
"index_options": "docs",
"analyzer": "i_prefix",
"search_analyzer": "q_prefix"
},
"stem": {
"type": "text",
"analyzer": "iq_text_stem"
}
},
"index_options": "freqs",
"analyzer": "iq_text_base"
}
}
}
titleとbodyに以下の部分が追加されています。これにより、title.japaneseとbody.japaneseに対して検索をかけると形態素解析されたものになります。
"japanese": {
"type": "text",
"analyzer": "kuromoji_analyzer"
}
設定が正しく入っているかどうかは以下をDev Toolsで実行すると確認できます。
GET search-windows-drive/_settings
GET search-windows-drive/_mapping
問題なければ以下をDev Toolsで実行してインデックスを再度開きます。
POST search-windows-drive/_open
Connector clientを立ち上げる
config fileの作成
Windowsマシン上でどこか適当な作業ディレクトリを作ります。
mkdir connectors-config
curl https://raw.githubusercontent.com/elastic/connectors/main/config.yml --output ./connectors-config/config.yml
と実行します。config.ymlが保存されるので、notepadか何かで開きます。
先程保存した内容をconfig.ymlに貼り付けます。

Docker(Connector client)起動
Windows上で以下のコマンドを実行
C:/Users/elastic/source/connectors/connectors-configの部分は環境に合わせて変更してください。
2024/08/02更新
imageは公式のリポジトリから確認してください
https://www.docker.elastic.co/r/enterprise-search/elastic-connectors
docker network create elastic
docker run -v C:/Users/elastic/source/connectors/connectors-config:/config --network "elastic" --tty --rm docker.elastic.co/enterprise-search/elastic-connectors:<version> /app/bin/elastic-ingest -c /config/config.yml
エラーなどが出ていないことを確認してください。
同期
connector clientが待機状態になっているので、同期を開始します。
Search->Contentから先程作ったインデックス(search-windows-drive)を選択し、Configurationタブをクリックして設定画面に戻ります。

一番下のSyncをクリックしてFull Contentを選んでしばらく待ちます。
Dockerを実行した画面に以下のような出力があればデータの同期ができています。
[FMWK][15:18:52][INFO] [Connector id: kGe9Y4wBBgiEiYrEOH-5, index name: search-windows-drive, Sync job id: w2fCY4wBBgiEiYrEKX_i] Sync progress -- created: 400 | updated: 0 | deleted: 0
[FMWK][15:18:57][INFO] [Connector id: kGe9Y4wBBgiEiYrEOH-5, index name: search-windows-drive, Sync job id: w2fCY4wBBgiEiYrEKX_i] Sync ended with status completed -- created: 409 | updated: 0 | deleted: 0 (took 17 seconds)
同期スケジュール
今回は手動で同期をしていますが、通常は一定間隔で自動的に行うと思います。
こちらの画面でその設定を行うことが出来ます。

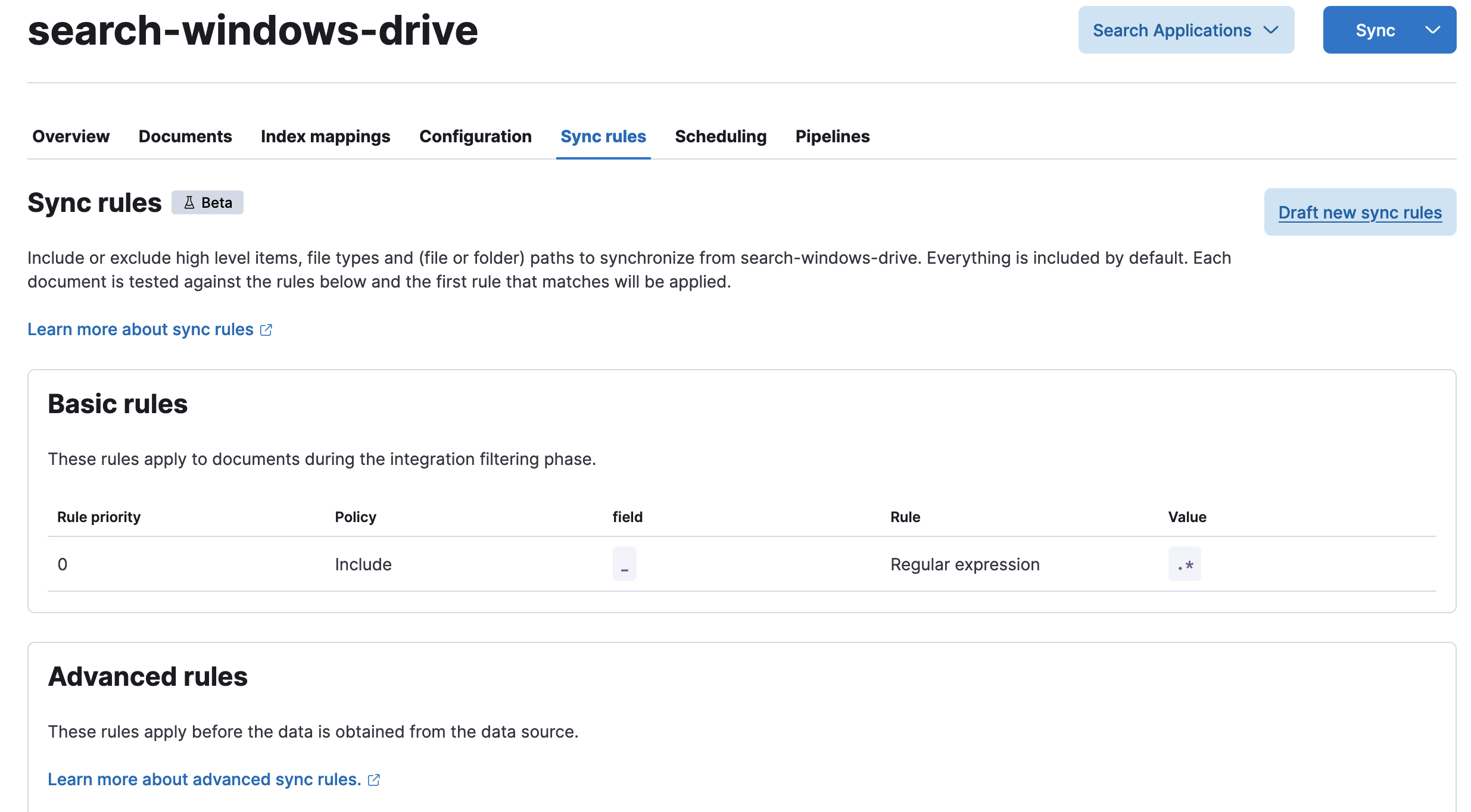
同期ルール
フォルダを除外したり、拡張子で取り込むファイルの種類を決めたりすることができます。
ドキュメントはこちらです。
https://www.elastic.co/guide/en/enterprise-search/current/sync-rules.html
制限
10MB以上のファイルはそのままではインデックス出来ません。
テキスト抽出を行うコンテナを別途立てる必要があります。
ドキュメントはこちらです。
https://www.elastic.co/guide/en/enterprise-search/current/connectors-content-extraction.html
ドキュメントの確認
先程の画面でDocumentsタブをクリックするとインデックスされたドキュメントが表示されます。

アクセス権限情報
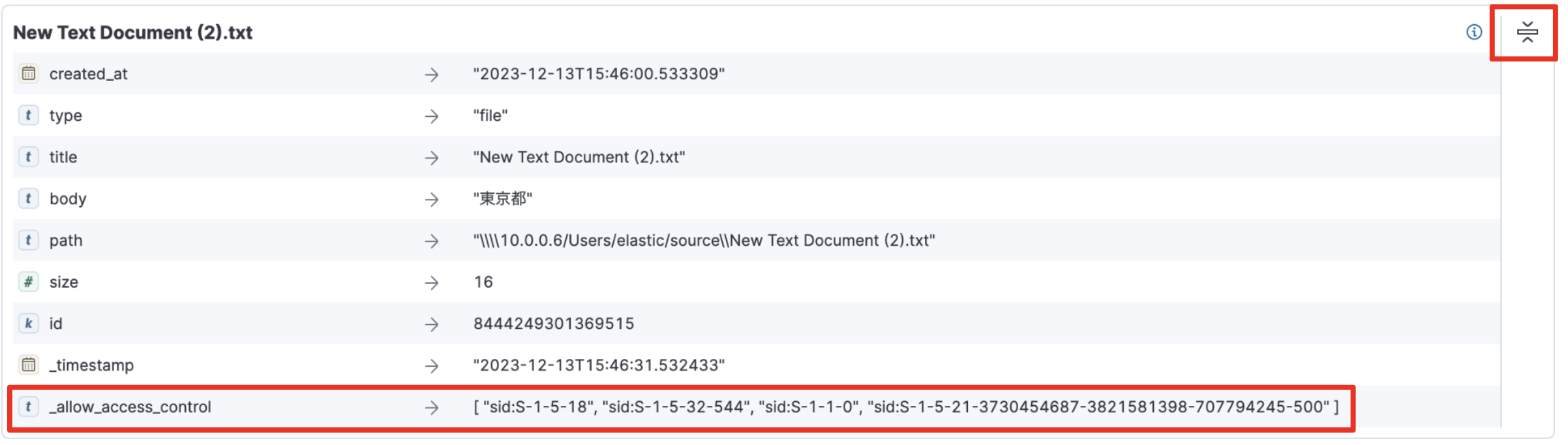
ドキュメントの右上にあるところ(赤枠で囲ったところ)をクリックすると全てのフィールドが表示されます。
_allow_access_controlというフィールドがそれです。WindowsのSIDが入っているのがわかるかと思います。
Document Level Security
Windowsサーバの場合、権限情報を別のインデックスに保存することで簡単にドキュメントレベルでアクセス制限をかけることが出来ます。
ConfigurationタブのSyncをクリックして、今度はAccess Controlをクリックします。
無事に同期が終わったら情報を確認してみます。
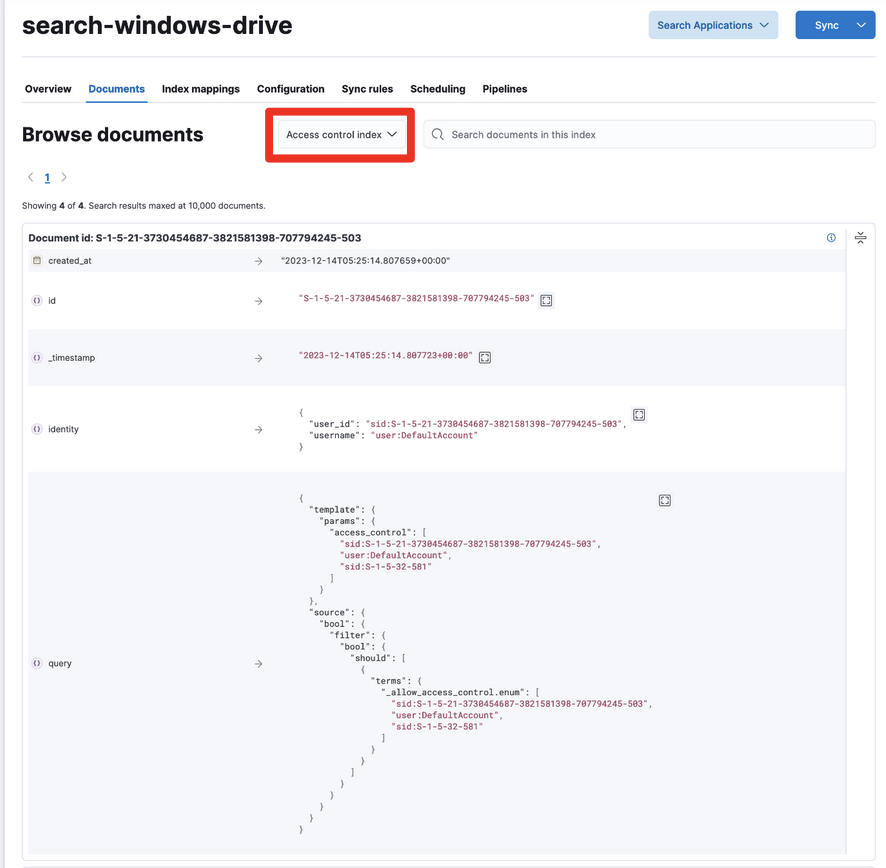
Documentsタブに移動して、Browse Documentsの横にあるPull DownをクリックしてAccess control indexを選びます。
下図のように情報が入っていて、queryが入っているのは実際に検索する際にこのqueryを使ってアクセス権限を確認するためです。このあたりはまた別のブログで紹介します。
Document Level Securityのドキュメントはこちらです。
https://www.elastic.co/guide/en/enterprise-search/current/dls-e2e-guide.html
Discoverでデータを確認する
おなじみのDiscoverでもデータを見てみます。
Stack Management->Index Managementから先ほど作成したsearch-windows-driveをクリックします。

次の画面でDiscover indexをクリックするとDiscoverのページに飛びます。

Discoverのページでbodyかtitleをクリックしてみましょう。
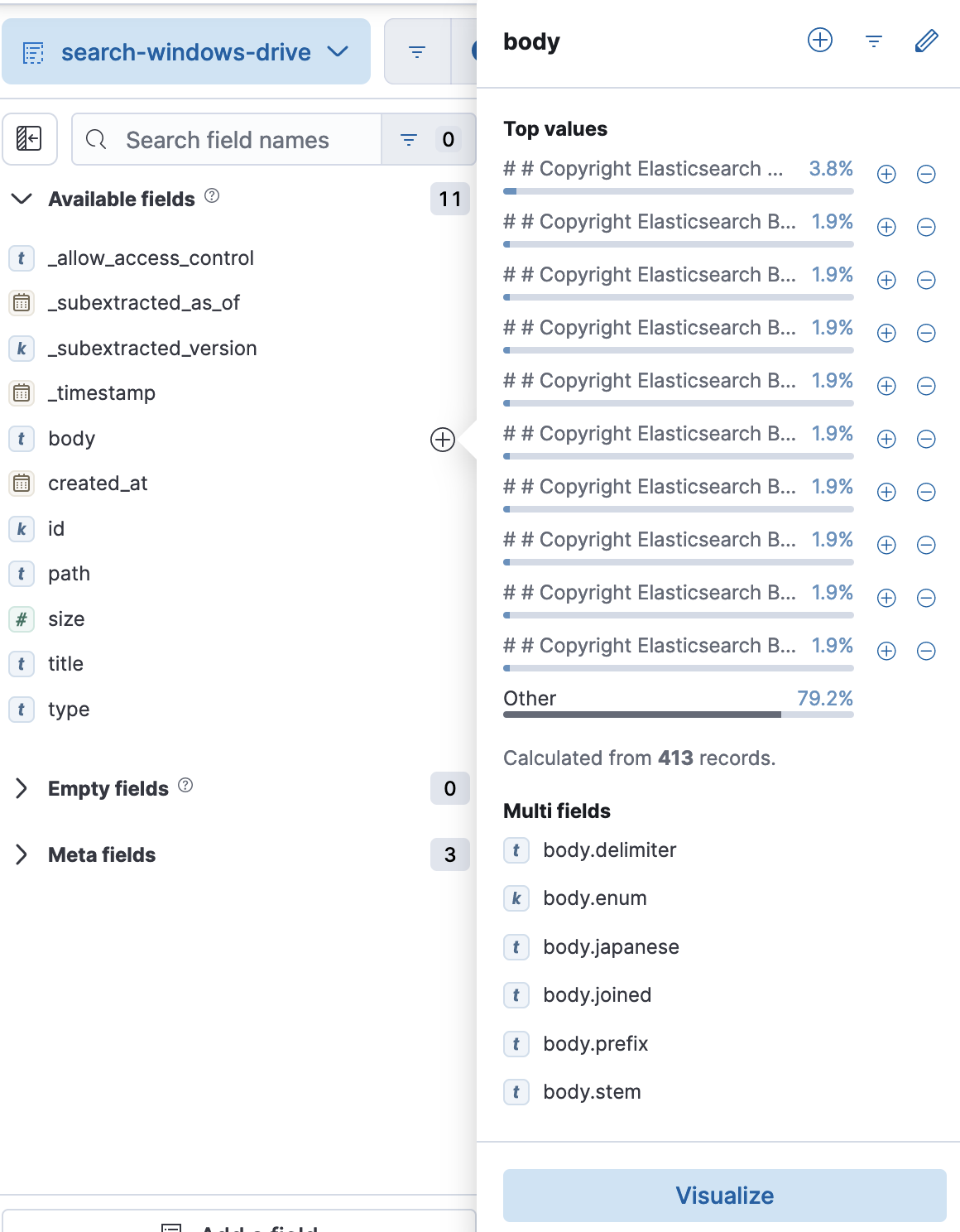
kuromoji.analyzer用に追加したbody.japanese,title.japaneseがあるのが確認できます。
形態素解析
ファイルの用意
ではごく簡単に形態素解析の効果を確認してみます。
まずは東京都とだけ書いたテキストファイルをWindowsの同期できる場所に置きます。そしてSearch->Content->search-windows-drive->Configurationで設定画面を開いて一番下にあるSyncをクリックしてFull Contentを選んで同期待ちにしておきます。
コンテナが立ち上がったままであれば、自動的に同期されてDiscoverに表示されるはずです。
検索してみる
Discoverの検索ボックスに東京と入れてみると先程の文章が表示されますね。当然です。
では次に京都と入れてみてください。表示されてしまいましたね。
理由は東京都の後ろの「京都」に引っかかっているからです。
これは望んだ結果ではないはずです。
では次にbody.japanese:京都と入力してみてください。表示されませんね。
body.japaneseでは「東京都」は「東京|都」と分割されているので検索ではヒットしません。

ただ辞書ベースの分割のみに頼ると新しい言葉に対応できなくなります。
このあたりは様々な知見が必要となりますので、是非弊社コンサルティングサービスをご利用ください。
まとめ
Connectorを使うと非常に簡単に色んな場所に散らばっている文書類をElasticsearchに取り込むことが出来ます。
ドキュメントの権限も設定することが出来るので、人事の書類を一般社員が見るなどの事故も起こりません。
全ての資料を一箇所に綺麗にまとめられているケースは少ないと思います。是非ElasticsearchのConnectorを使って社内文書の横断検索システムを構築して、従業員の生産性向上に役立ててみてください。