はじめに
以前に以下の記事にてElasticsearchでRAGを構成するための手順を説明しました。
https://qiita.com/takeo-furukubo/items/e5d43fa734e4338b895f
この方法はPythonの知識を必要とするため、プログラミングに馴染みのない方にはあまりお役に立たなかったかもしれません。
Elasticは8.14というバージョンにてPlaygroundという機能をリリースしました。この機能を使えばプログラミングの知識なしにノーコードでRAGを試すことができます。
2024/08/19現在の最新バージョンである8.15.0ではまだPlayground機能はTech Previewです
2024/08/19現在、PlaygroundはEnterpriseライセンスが必要です
Playground
PlaygroundというのはKibana上で簡単にRAG(Rerieval Augmented Generation)を試せる機能です。
ドキュメントはこちらです。
https://www.elastic.co/guide/en/kibana/current/playground.html

以前の記事でも書きましたが、RAGの成否は検索(=Retrieval)にかかっています。PlaygroundではRAGの応答の元になったドキュメントも簡単に確認ができます。
この機能で本番運用できるわけではないですが、まずは社内のドキュメントでRAGがどのような応答になるのか、といった検証には十分利用できます。
準備
Elastic Cloud
以前の記事の「手順」の部分が全く同じなので、こちらの手順を参考にして「Elstic Cloudの作成」「機械学習ノードの作成」「形態素解析のためのExtension追加」を行ってください。
https://qiita.com/takeo-furukubo/items/e5d43fa734e4338b895f#%E6%89%8B%E9%A0%86
設定ファイル
こちらをgit cloneしてください。
https://github.com/legacyworld/playground
E5モデルの展開
以前の記事では東北大学のモデルを使用しましたが、今回はノーコードでやりたいのでKibanaのメニューから展開できるE5を使用します。
メニューからAnalytics -> Machine Learning -> Trained Modelsと選択して、下記の画面で右上の”Add trained model”をクリックします。
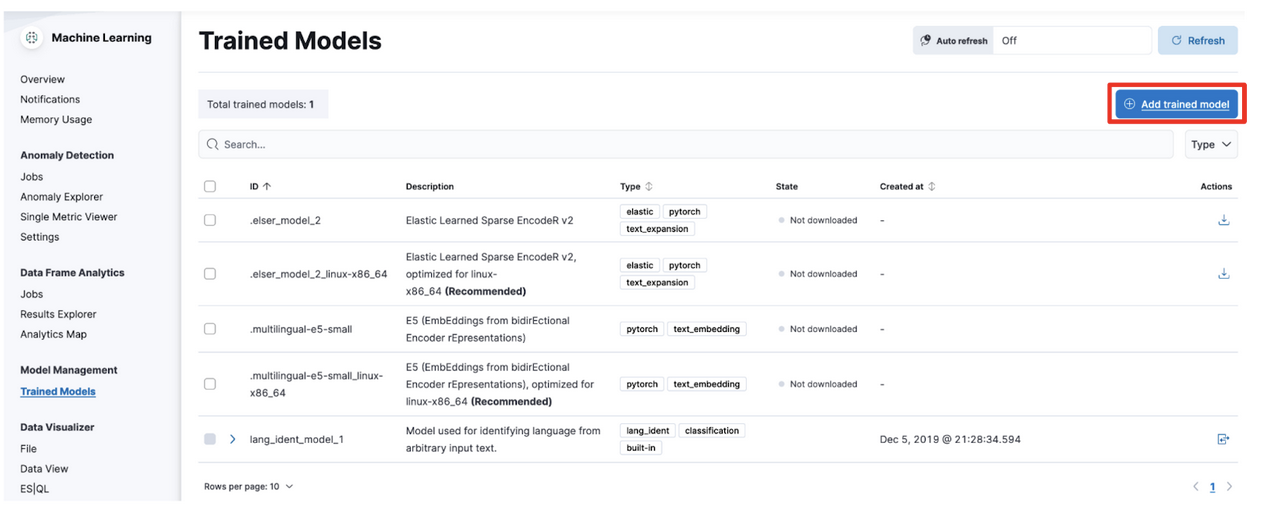
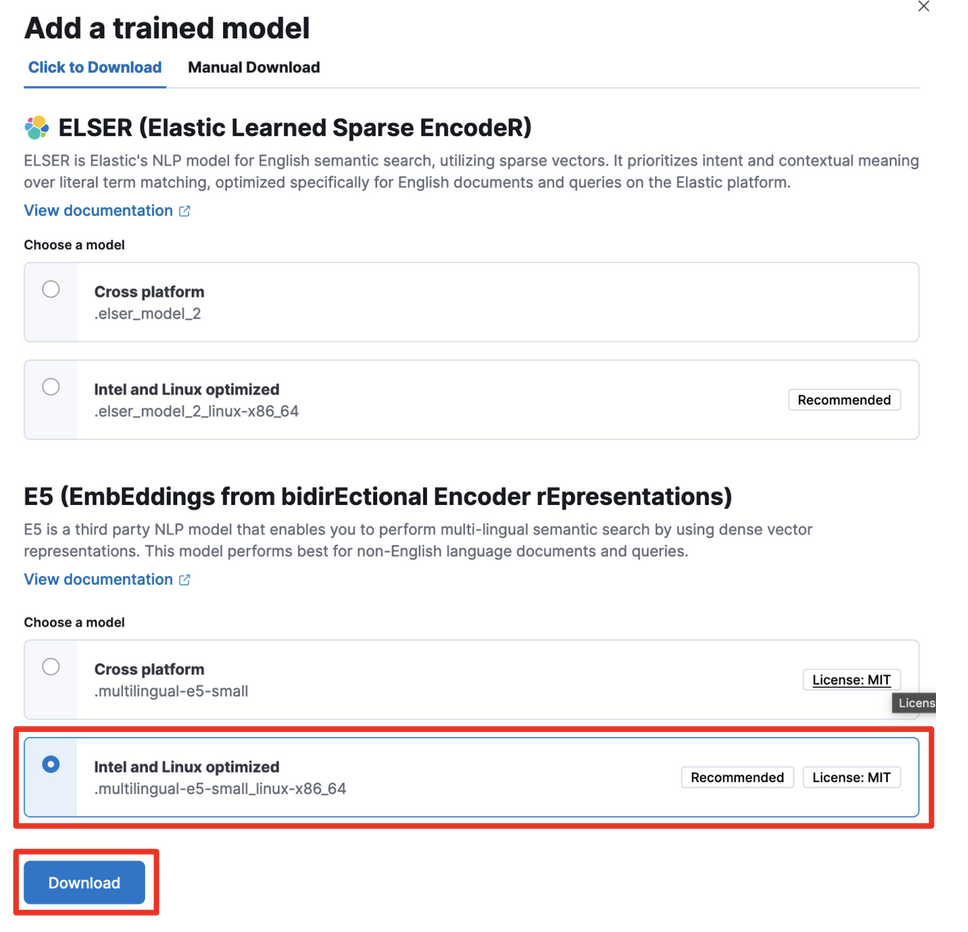
下記の画面にて一番下にあるE5 (EmbEddings from bidirEctional Encoder rEpresentations)の”Intel and Linux optimized”を選び、Downloadをクリック。
すると以下のように”Downloading”が表示されます。

ダウンロードが終わると”Ready to deploy”と表示されるので、そのあたりにマウスをホバーさせると右側に▷が表示されるので、それをクリックします。

ウィンドウが立ち上がるのでそのまま”Start”をクリックします

暫く待つと”Deployed”と表示されます

ドキュメントアップロード
以前の記事ではPythonプログラムでアップロードしていますが、今回はノーコードを条件にしているのでKibanaの機能を使います。
ドキュメントは相変わらずNewsAPIです。
https://newsapi.org/
用意しているドキュメント(seminar.ndjson)はNewsAPIで「東京大学」を検索したものです。
このドキュメントではなく新しくNewsAPIで取得する場合には、NewsAPIではJSONで出力されるのでjq -c '.[]' hoge.json > hoge.ndjsonなどでNDJSONに変換をしておきます。
Kibanaからアップロード
メニューからAnalytics -> Machine Learning -> Data Visualizer -> Fileと選択すると下記の画面が表示されます。
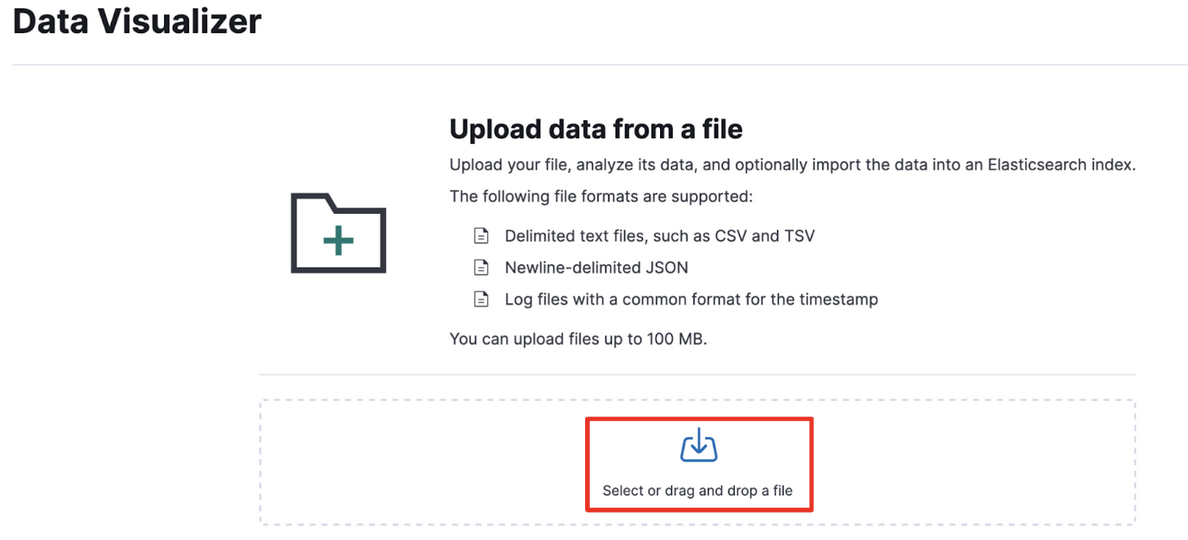
ここでseminar.ndjsonをアップロードします。(自分でNDJSONをNewsAPIから作った場合はそちらをアップロードします)
以下のように処理がされるのでImportをクリック

下記の画面で“Advanced”をクリックして、index nameに名前をいれる(ここではseminarと入れている)
ここではまだ”Import”をクリックしない
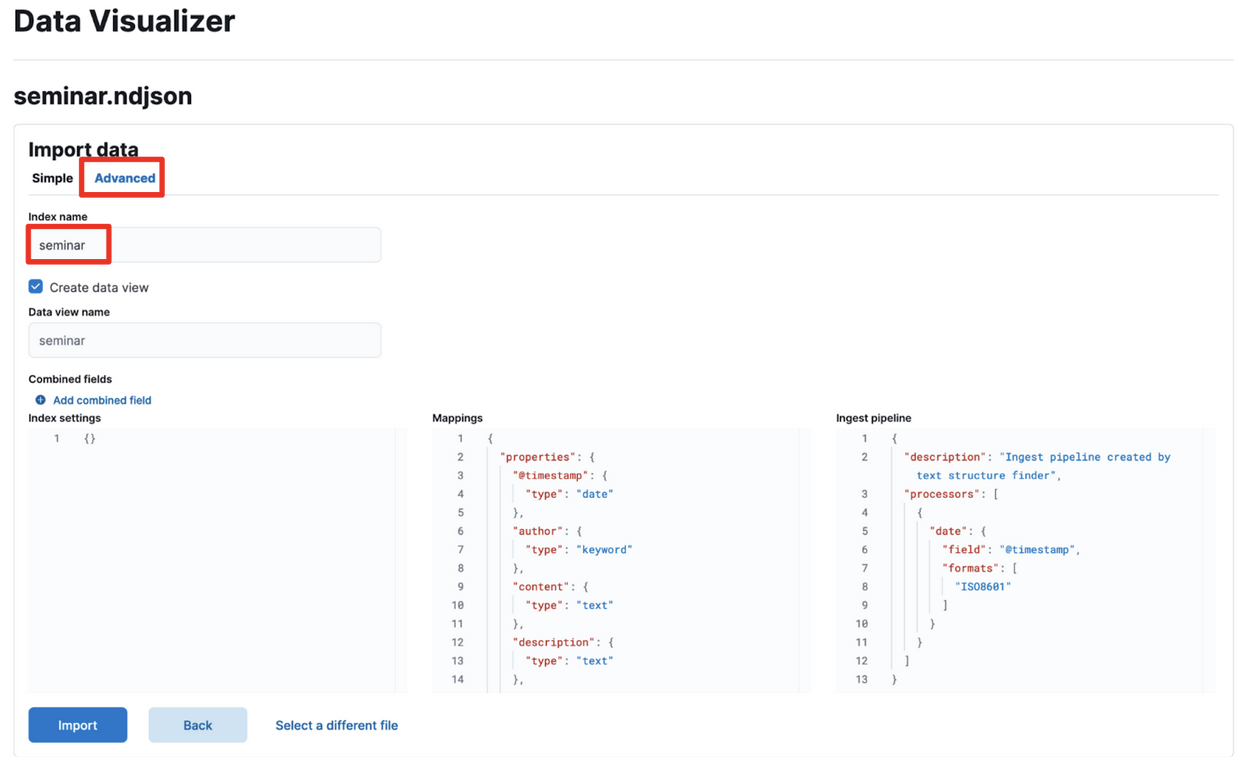
Importを押してインデックスを作ってしまった方は、気にせずに同じ手順で別の名前のインデックスを作ってください
インデックス設定
左端の"Index Settings"にある文字をすべて消して、index.txtの内容を全てコピ&ペーストします。
形態素解析を行う基本的な設定が行われています。
Mapping設定
真ん中の"Mappings"にある文字をすべて消して、mapping.txtの内容を全てコピ&ペーストします。
Inget Pipeline設定
右端の"Ingest Pipeline"にある文字をすべて消して、ingestpipeline.txtの内容を全てコピ&ペーストします。
ここではテキストデータの投入と同時にベクトル化をE5モデルで行っています。
全て変更し終わったら"Import"をクリックします。

問題がなければ以下のような画面になります。”View Index in Discover”をクリックするとDiscoverでデータを見ることができます。

Playgroundの設定
では本題のPlaygroundを使っていきます。まずは以下の2点の設定が必要です。
- LLM
- インデックスと検索するフィールド
Search -> Playgroundとクリックすると以下の画面になります。まずはLLMの設定を行います。

すでに設定されている方はスキップしてください。
LLM
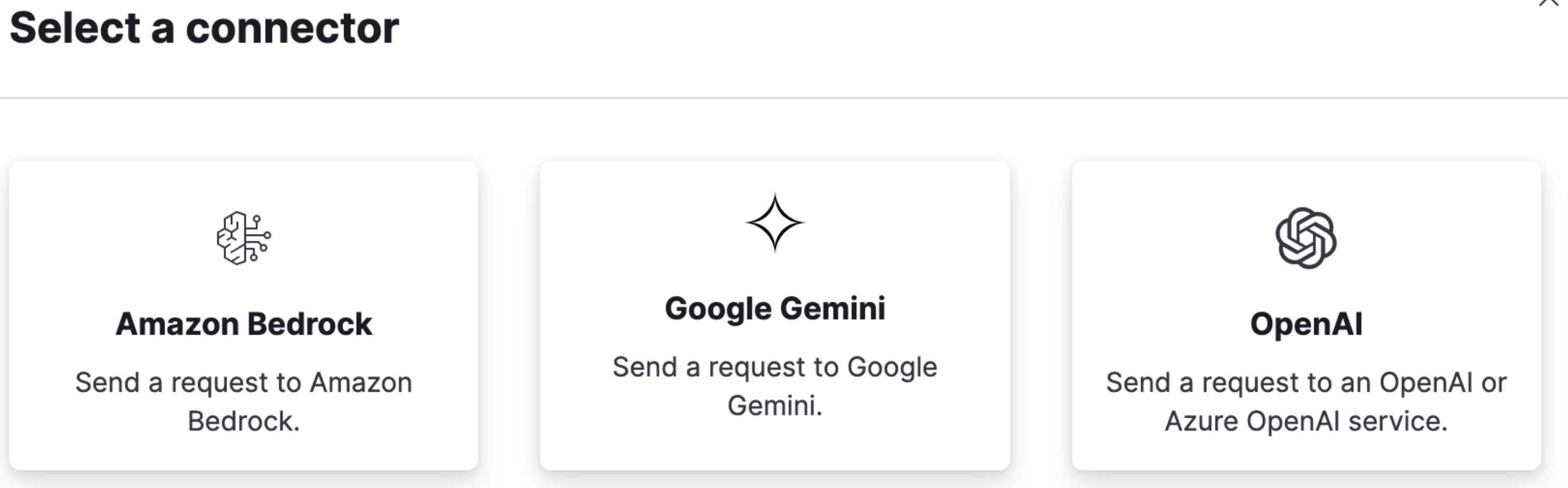
下記の画面のようにAWS Bedrock, Google Gemini, OpenAIが使用できます。APIキーなどは各LLMにてご準備ください。
インデックス
LLMの設定に問題なければ以下のように自動的に”LLM Connected”となるので、”Add data sources”をクリックします。ここで設定するのはどのデータを使ってRAGを行うかを選択しています。

先ほど入力したインデックス名を選択(ここでは”seminar”)。Available Indicesの下に表示されているので、それをクリックして、最後に"Save and Continue"をクリックします。

画面右下に“Context fields”という部分があります。ここにある”description”を選択します。これは検索して取ってきたドキュメントのどのフィールドをコンテキストとしてLLMに渡すか、という設定です。この設定については”Save”などをクリックしなくても適用されていますので、このまま次のステップに進みます。

クエリ
ページ上部にある”Query”を選択します。ここでクエリ文(どのように検索するか)を決めます。

デフォルトでは”text_embedding”のみ選ばれています。これはベクトル検索のみ行う設定です。”description”をEnableするとキーワード検索部分が追加されてハイブリッド検索(RRF: Reciprocal Rank Fusion)となっています。

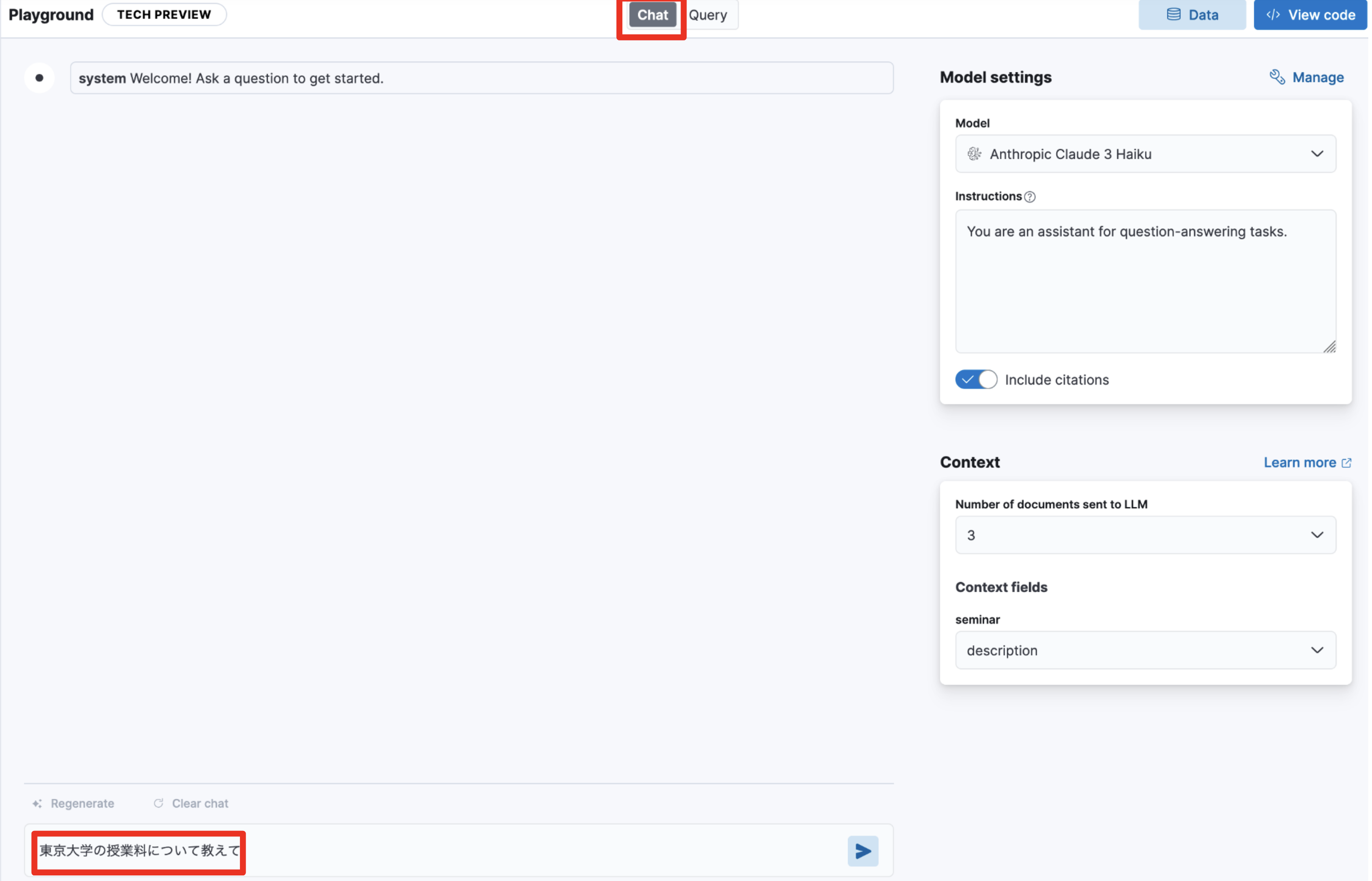
ページ上部にある”Chat”をクリックしてチャットを行う画面に戻り、ページ下部にある”Ask a quesion”に”東京大学の授業料について教えて”と入力します
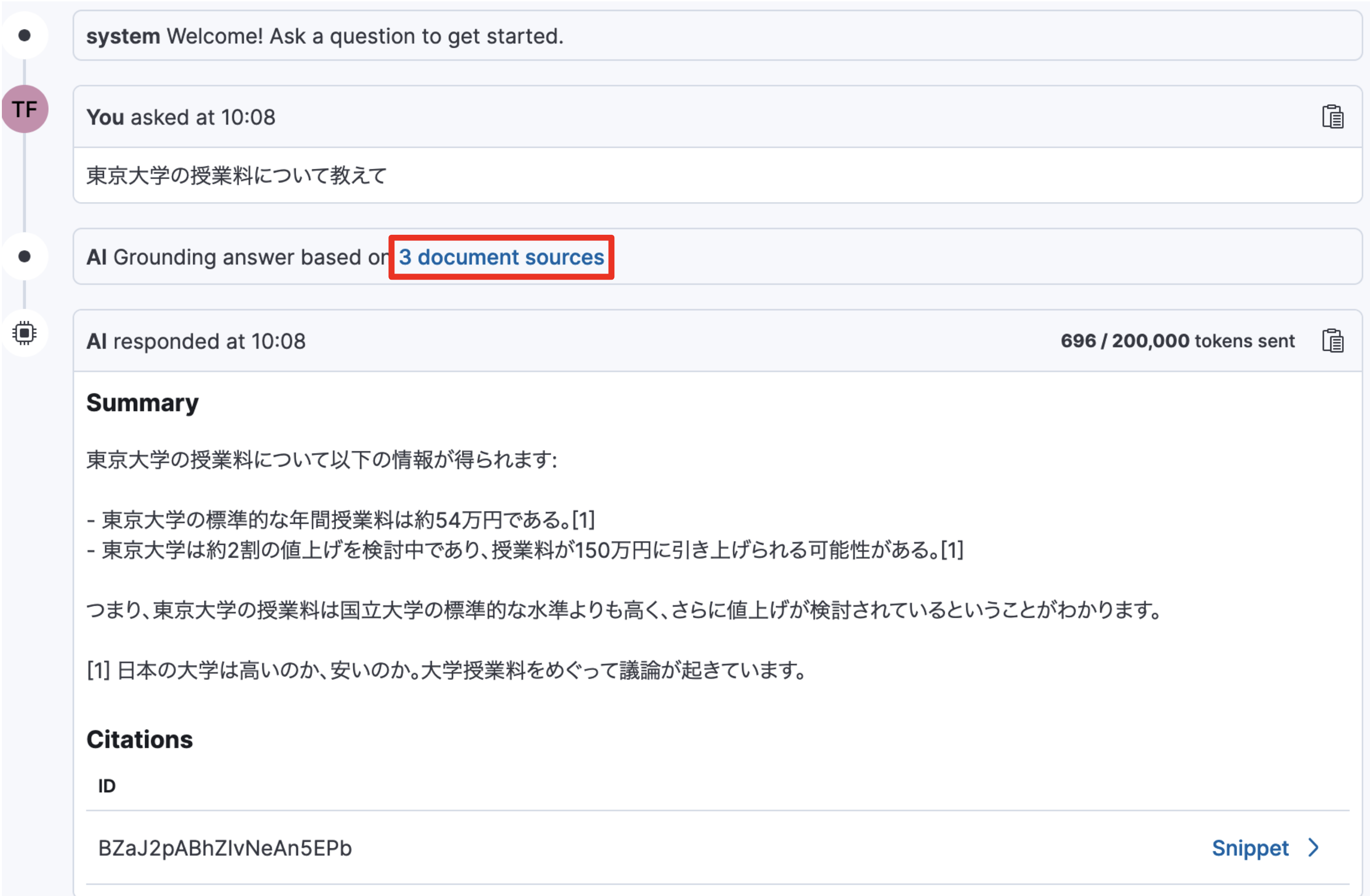
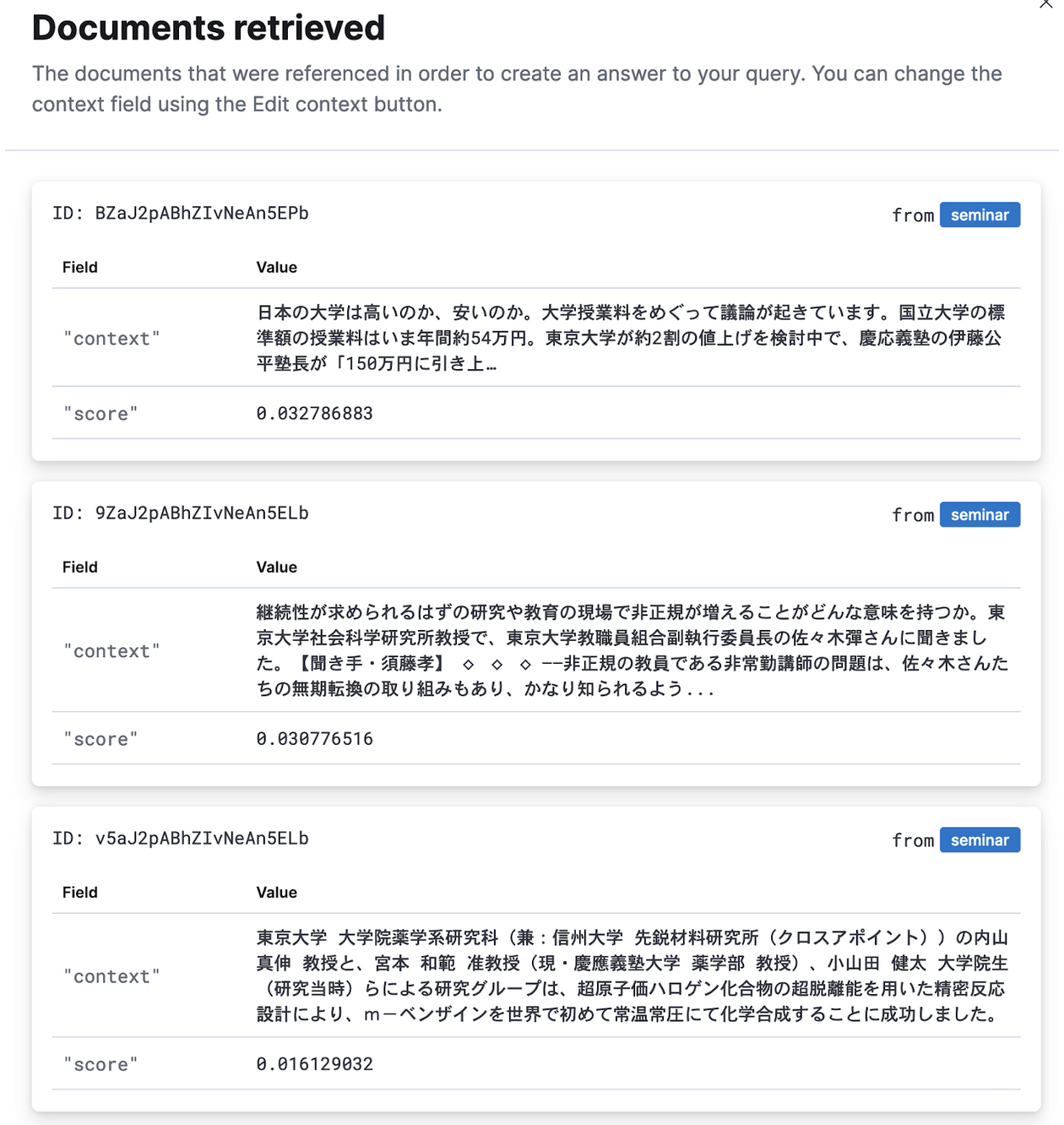
例えばAWS Bedrock Claude3 Haikuだとこのように要約されています。”3 document sources”をクリックするとこの要約を作成した根拠の文書が示されます。選択したLLMによってこの要約部分は結構変わります。
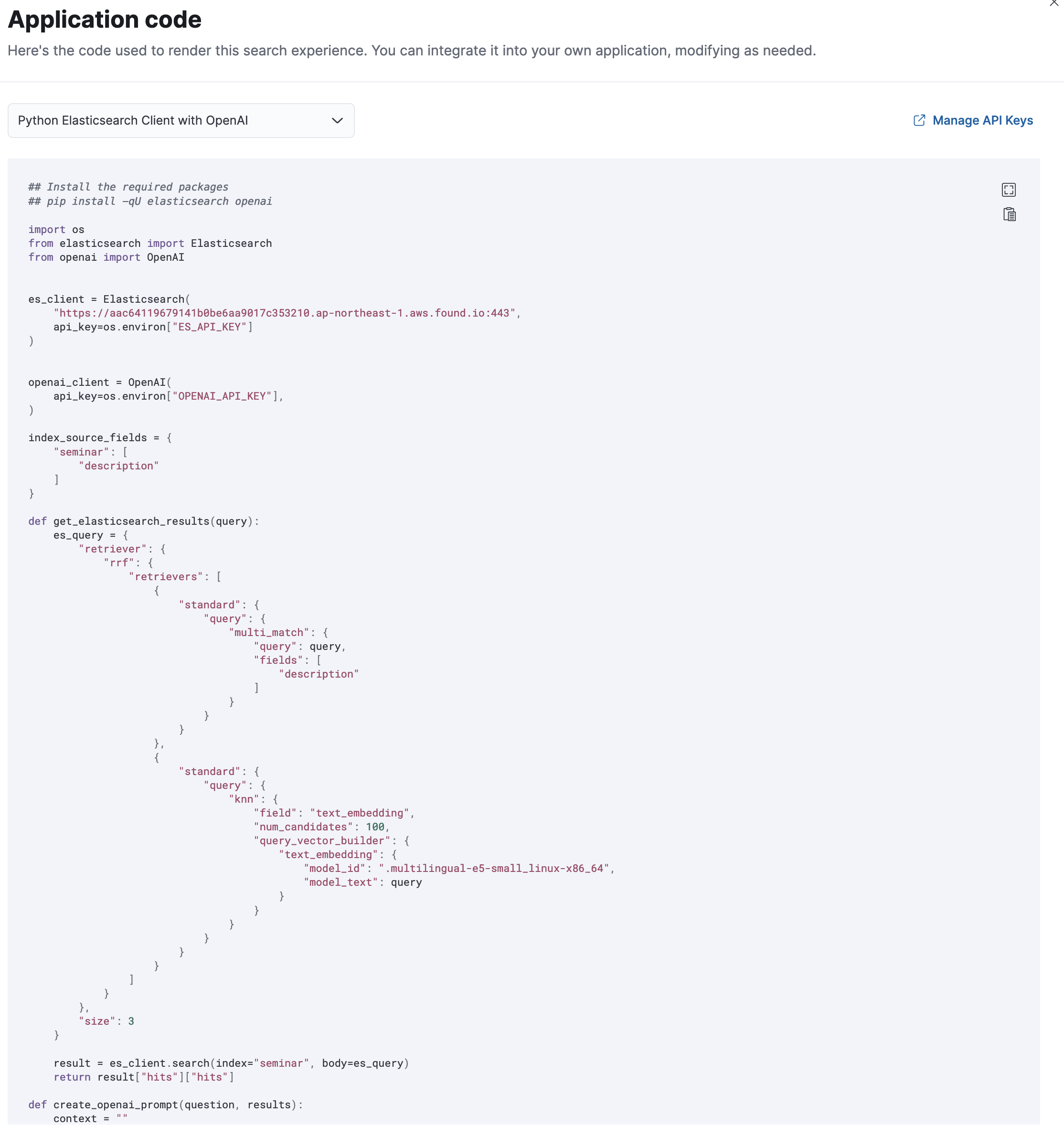
アプリケーションコード
右上の"View Code"をクリックすると、これと同じことを行うソースコードが表示されます。現状ではOpenAIのみです。
まとめ
いかがでしたでしょうか。非常に簡単にRAGを試せることを実感いただけかと思います。
似たようなサービスはあるとは思いますが、クエリ文を変更してRRFまで自動的に設定できるものはほとんど無いと思います。
またインデックスと同時にベクトル化も行えるため、ベクトル化のためのプログラムも必要ありません。
更に形態素解析の設定を簡単なので、高度な日本語処理も行えます。
是非Playgroundを利用してRAGに取り組んでみてください。