スタートアップで働くRailsエンジニアです。
今回、Adjustローデータをユーザーの行動分析や広告効果の検証に活用しようということで、たまたまAdjust、S3、Redshiftを触る機会があったため作業メモとして残します。
Redshift、クエリの実行が早くて助かりますよね。Adjustローデータような大きなデータに対してクエリを実行して分析結果を得たいような場合、かなり良い選択肢ではないかと思います。
個人的にAdjust関連のドキュメントがとっつきにくかったため、アドテク分野そんなによくわからないけど急遽触ってみることになった、など私と同じ境遇の方の参考になれば幸いです。
やりたいこと
Adjustローデータ
↓ csv形式で毎時自動アップロード
S3
↓ csvファイルのデータを1日1回コピー
Redshift(サービス分析基盤)
前提
- Redshift側は既存環境を利用(クラスタ、DBは作成済み)
- AdjustはBasicプランを契約(ローデータエクスポート機能が利用できること)
作業内容
- S3バケットを新規作成
- Adjustローデータをcsv形式でS3に自動アップロードするための設定
- Redshiftに新規テーブル作成する
- S3からRedshiftにcsvファイルの中身をコピーする
- 4.の自動化(バッチで1日1回、スクリプトを実行する)
1. S3バケットを新規作成
AWSマネジメントコンソールに接続して、サービスからS3を選択します。
今回のcsvアップロード先のバケットを1つ作成していきます。
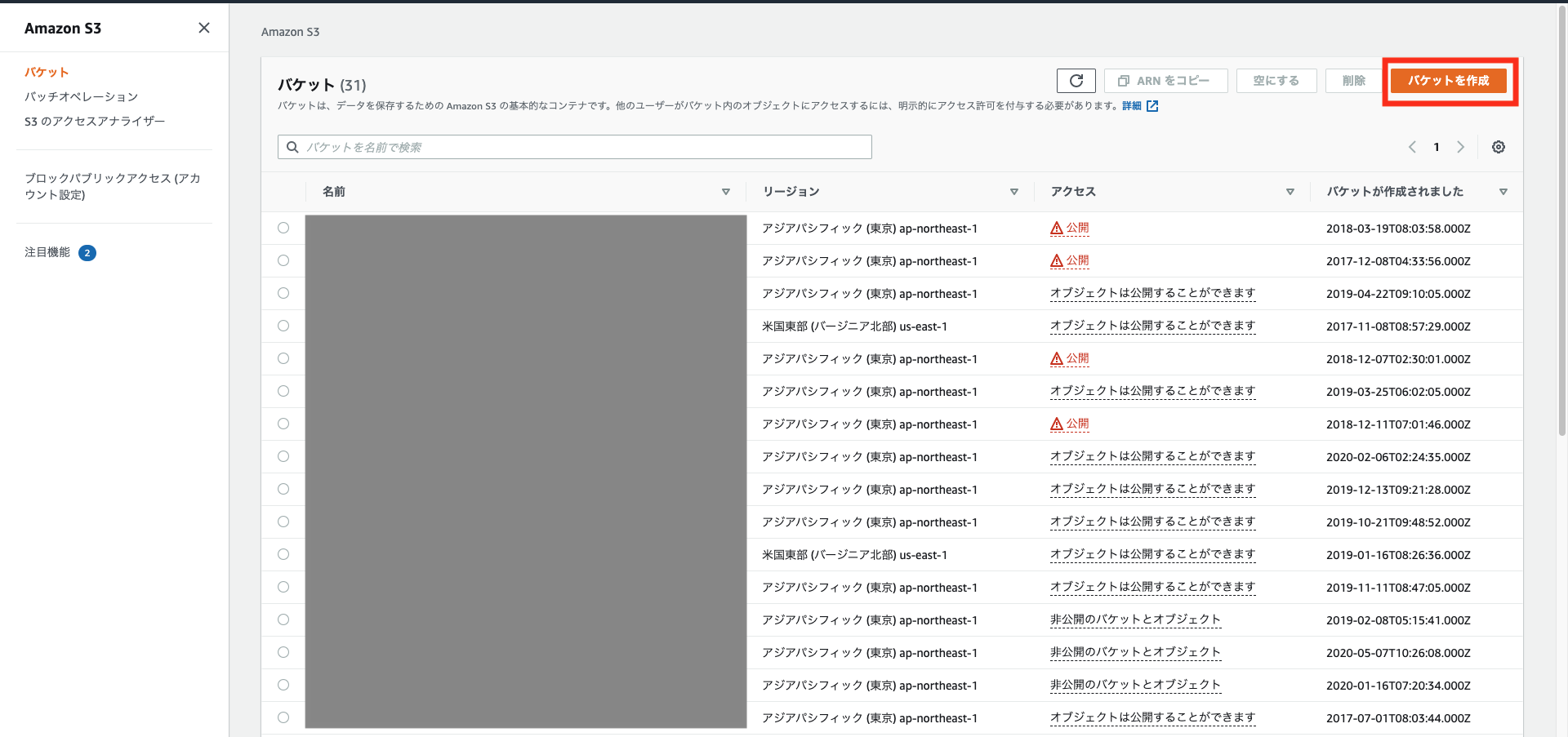
バケットを作成をクリックします。
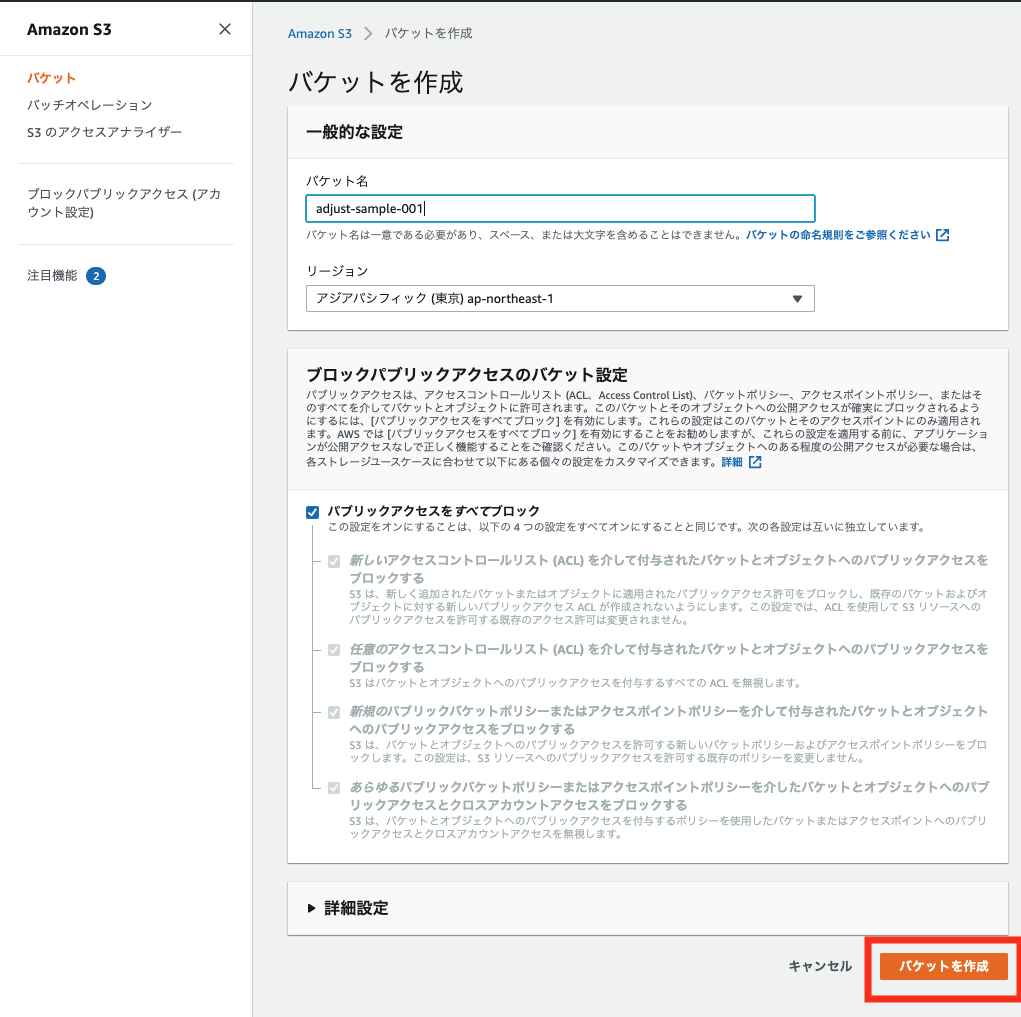
今回はバケット名を adjust-sample-001 とします。
リージョンは東京リージョンを選択します。
ブロックパブリックアクセスの設定や詳細設定はデフォルトで問題ありません。
入力したら「バケットを作成」を実行します。
これでバケットの新規作成は完了です。
2. Adjustローデータをcsv形式でS3に自動アップロードするための設定
次にAdjustからS3にローデータをエクスポートするための設定を行います。
2-1. AWS側の設定(IAMユーザーの作成)
まずはAdjustからS3にアクセスする用のIAMユーザーを1つ作成します。
AWSマネジメントコンソール サービスからIAMを選択してIAMのコンソール画面に飛びます。
IAMポリシー作成
はじめにS3からのアクセスを許可するポリシーを作成します。
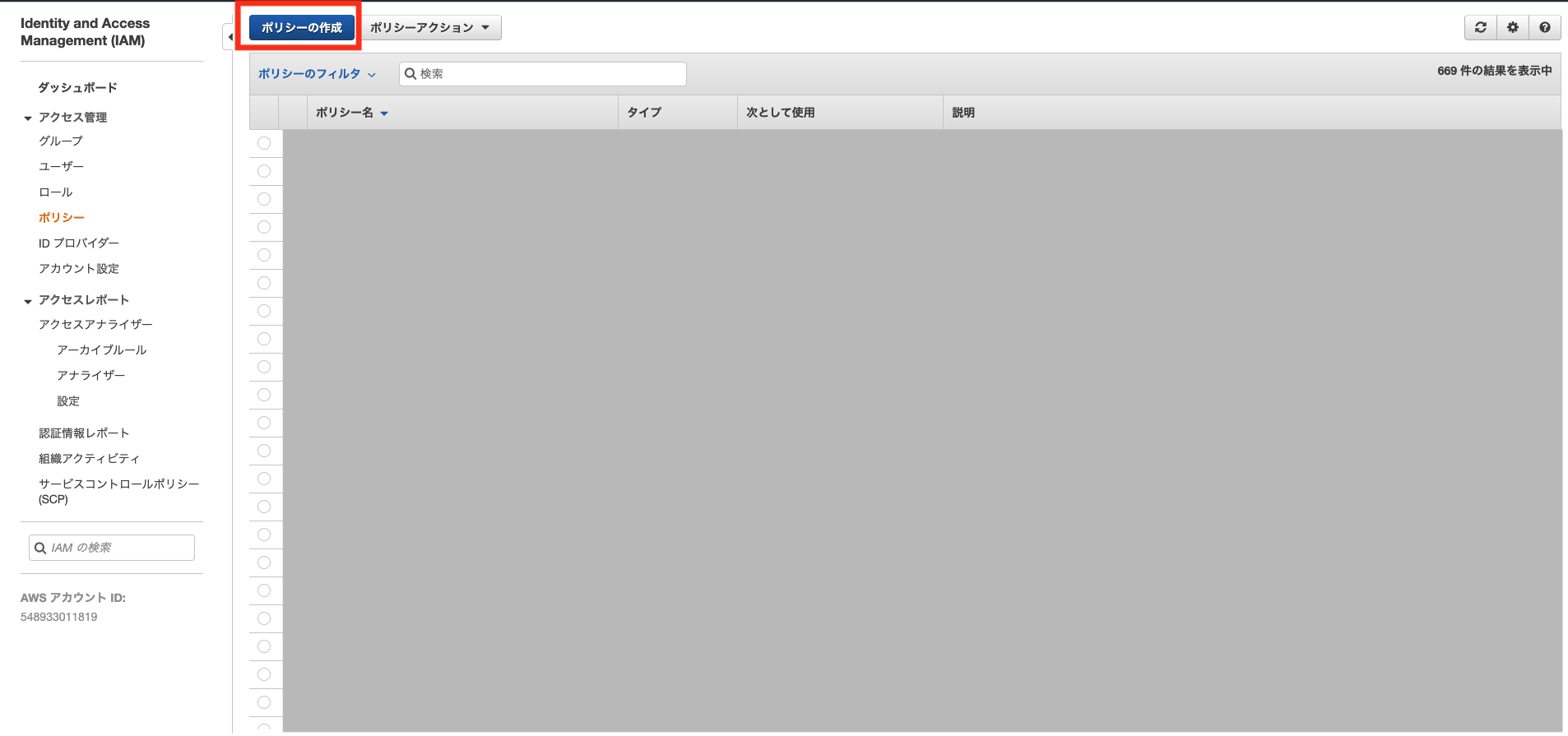
ポリシータブから「ポリシーの作成」をクリックします。
ポリシーの作成画面ではJSONタブを選択して、ポリシーを記述します。
下記は作成したS3バケットadjust-sample-001への読み書き権限を付与する記述です。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetBucketLocation",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::adjust-sample-001"
]
},
{
"Effect": "Allow",
"Action": [
"s3:PutObject"
],
"Resource": [
"arn:aws:s3:::adjust-sample-001/*"
]
}
]
}
ポリシーの作成にあたってはこちらの記事を参考にしました。
https://024minion.hatenablog.jp/entry/2018/05/02/233652
バケット名が作成したものと一致していることを確認して「ポリシーの確認」に進みます。
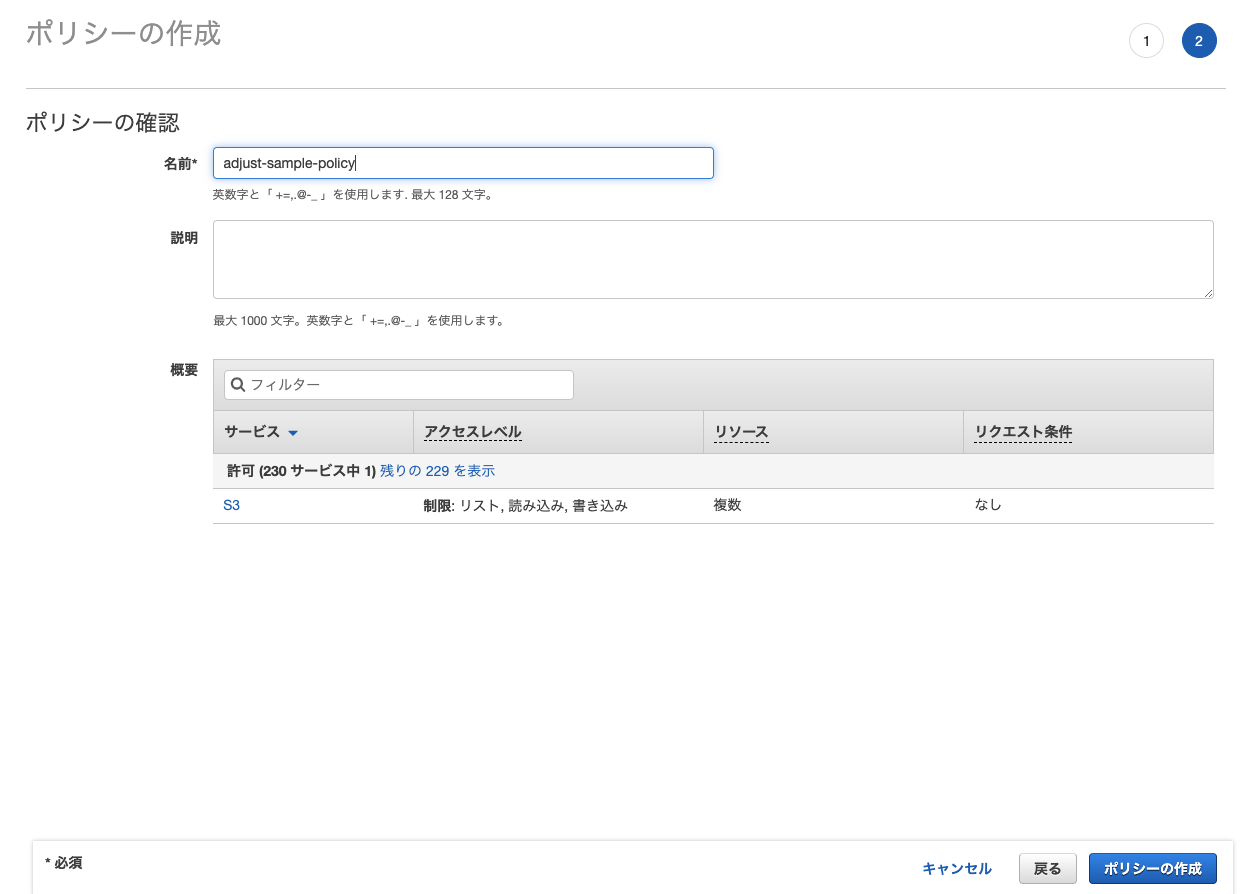
作成したポリシーに名前をつけます。今回は adjust-sample-policy とします。
入力後、「ポリシーの作成」を実行します。
ポリシーが作成されました。
続いて、先程のポリシーを設定するIAMユーザーを作成します。
IAMユーザー作成
ユーザータブから「ユーザーを作成」をクリックします。
 IAMユーザー名を入力します。今回は **adjust-sample-server** とします。
アクセスの種類は **プログラムによるアクセス** を選択して、次のステップに進みます。
IAMユーザー名を入力します。今回は **adjust-sample-server** とします。
アクセスの種類は **プログラムによるアクセス** を選択して、次のステップに進みます。

アクセス許可の設定は 既存のポリシーを直接アタッチ を選択します。
読み込まれたポリシー一覧の中から、先ほど作成したポリシーadjust-sample-policyにチェックを入れて、次のステップに進みます。
(今回、タグの追加は今回は行いませんのでさらに次のステップへ進みます)
これまで作成してきたIAMユーザーの確認画面が表示されますので、「ユーザーの作成」を実行します。
 これでS3バケットにプロブラム(今回はAdjsut)から接続するためのIAMユーザーが作成できました。
この画面で表示されているIAMユーザーの**アクセスキーIDとシークレットアクセスキーはAdjust側の設定で必要となるため控えておく**必要があります。
※ もし控え忘れてしまった場合はIAMコンソール > ユーザーから作成したIAMユーザー`adjust-sample-server`を選択します。認証情報タブから「アクセスキーの作成」を実行することで新しいキーペアを作成することができます。
これでS3バケットにプロブラム(今回はAdjsut)から接続するためのIAMユーザーが作成できました。
この画面で表示されているIAMユーザーの**アクセスキーIDとシークレットアクセスキーはAdjust側の設定で必要となるため控えておく**必要があります。
※ もし控え忘れてしまった場合はIAMコンソール > ユーザーから作成したIAMユーザー`adjust-sample-server`を選択します。認証情報タブから「アクセスキーの作成」を実行することで新しいキーペアを作成することができます。
2-2. Adjust側の設定
Adjust管理画面 ローデータエクスポート設定
次に、Adjust管理画面からアプリ>その他の設定>ローデータエクスポートと進みます。

csvアップロードを選択します。
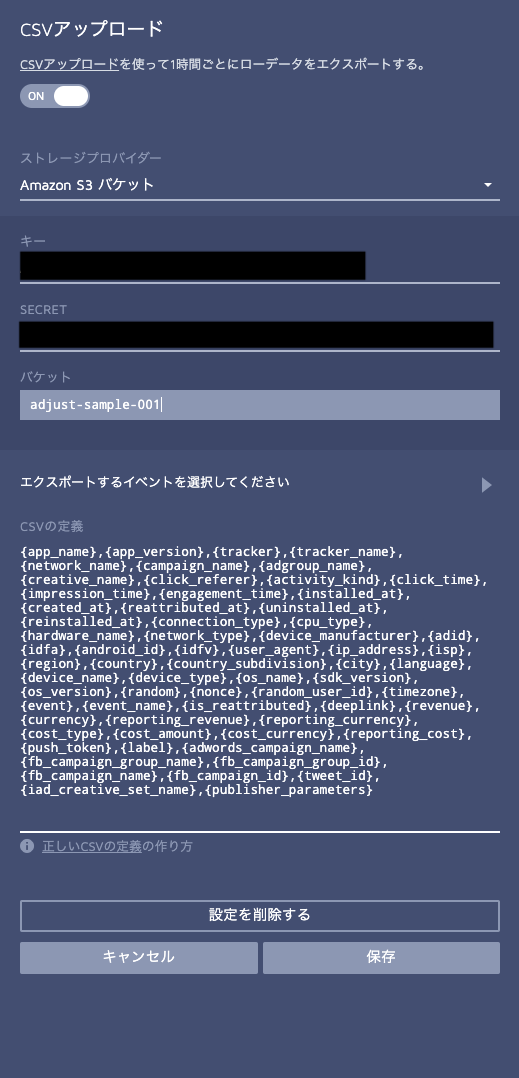
アップロード先の設定画面が表示されます。
「ストレージプロバイダー」は Amazon S3 バケット を選択します。
「キー」、「SECRET」に 先ほど作成したIAMユーザーのアクセスキーID 、シークレットアクセスキー を入力します。
「バケット」に今回作成したアップロード先のバケット名を入力します。
「エクスポートするイベント」を選択して、保存を実行します。
これでAdjust側の設定は完了です。
たったこれだけの設定でAdjustからS3への自動アップロードが行われるようになります。スゴイ。
毎時0分にAdjustからローデータのcsvがS3のバケットにアップロードされます。
S3にアップロードされたcsvファイル一覧
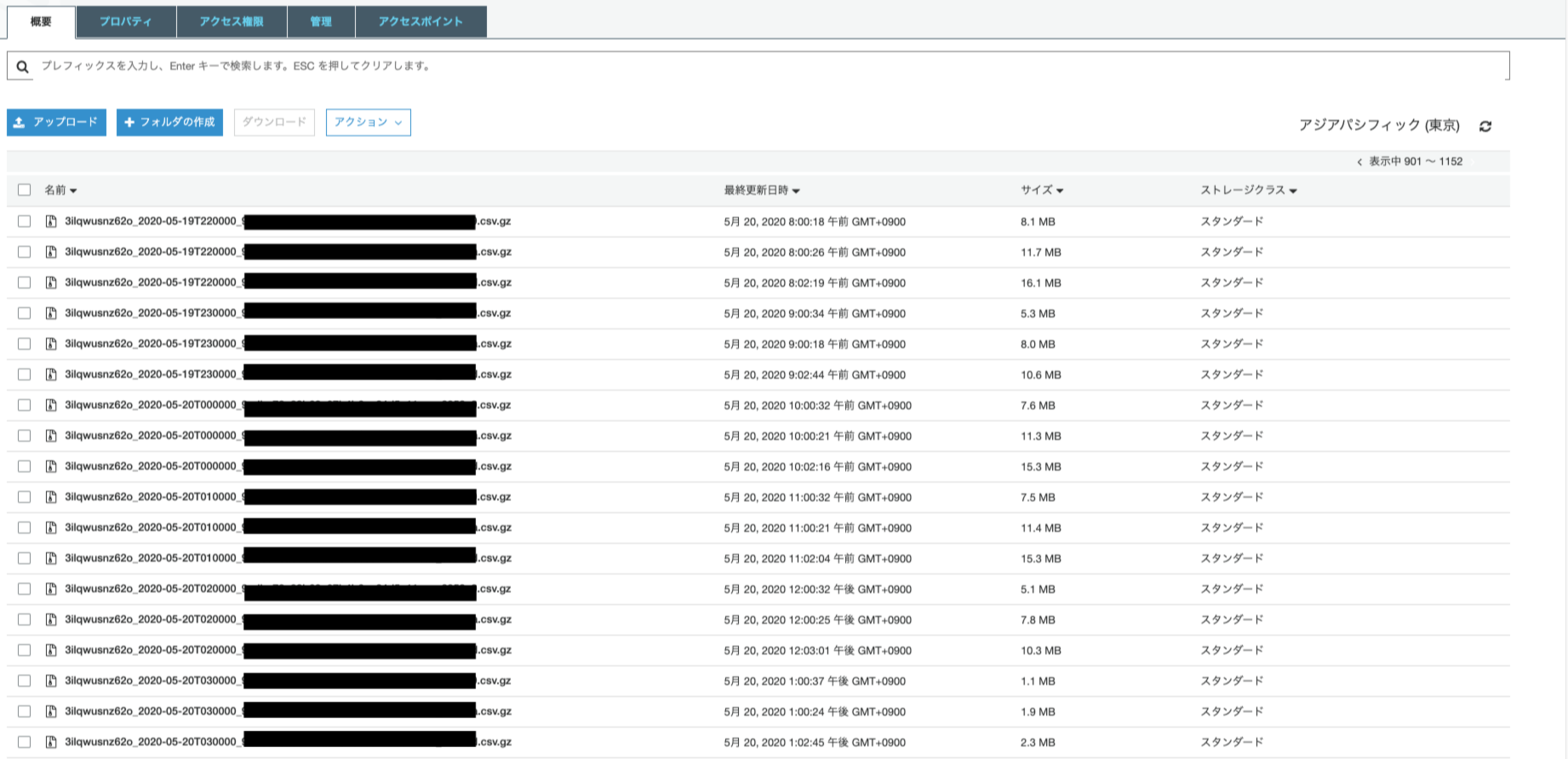
こんな感じで、gzip形式で圧縮されたcsvファイルが定時アップロードされます。
お次はこのcsvファイルをRedshiftにコピーして、クエリで扱えるようにしていきます。
3. Redshiftに新規テーブル作成する
Redshiftにcsvをインポートするためのテーブルを新規作成します。
私はDBeaverというSQLクライアントツールをつかってRedshiftに接続して作業しました。
最近、Redshift側にクエリエディタというAWSコンソールから直接クエリを実行できる機能が追加されたようなので、クライアントツールをインストールしていないような場合はそちらを使っても良いかもしれません。
DBeaverからテーブル作成のためのコマンドを実行
create table コマンドを実行します。
ローデータに対応するカラムを用意します。
データ型は適当ですので調整する必要がありそうです。
create TABLE *table_name* (
app_name VARCHAR
, app_version VARCHAR
, tracker VARCHAR
, tracker_name VARCHAR(512)
, network_name VARCHAR
, campaign_name VARCHAR
, adgroup_name VARCHAR
, creative_name VARCHAR
, click_referer VARCHAR(4096)
, activity_kind VARCHAR
, click_time BIGINT
, impression_time BIGINT
, engagement_time BIGINT
, installed_at BIGINT
, created_at BIGINT
, reattributed_at BIGINT
, uninstalled_at BIGINT
, reinstalled_at BIGINT
, connection_type VARCHAR
, cpu_type VARCHAR
, hardware_name VARCHAR
, network_type VARCHAR
, device_manufacturer VARCHAR
, adid VARCHAR
, idfa VARCHAR
, android_id VARCHAR
, idfv VARCHAR
, user_agent VARCHAR(512)
, ip_address VARCHAR
, isp VARCHAR
, region VARCHAR
, country VARCHAR
, country_subdivision VARCHAR
, city VARCHAR
, language VARCHAR
, device_name VARCHAR
, device_type VARCHAR
, os_name VARCHAR
, sdk_version VARCHAR
, os_version VARCHAR
, random BIGINT
, nonce VARCHAR
, random_user_id VARCHAR
, timezone VARCHAR
, event VARCHAR
, event_name VARCHAR
, is_reattributed BOOLEAN
, deeplink VARCHAR(4096)
, revenue VARCHAR
, currency VARCHAR
, reporting_revenue VARCHAR
, reporting_currency VARCHAR
, cost_type VARCHAR
, cost_amount FLOAT
, cost_currency VARCHAR
, reporting_cost FLOAT
, push_token VARCHAR(512)
, label VARCHAR
, adwords_campaign_name VARCHAR
, fb_campaign_group_name VARCHAR
, fb_campaign_group_id BIGINT
, fb_campaign_name VARCHAR(512)
, fb_campaign_id BIGINT
, tweet_id VARCHAR
, iad_creative_set_name VARCHAR
, publisher_parameters VARCHAR
);
これでRedshiftのテーブル作成は完了です。
4. S3からRedshiftにcsvファイルの中身をコピーする
先ほど作成したテーブルにS3のcsvファイルの中身をコピーしてみます。
SQLクライアントツールまたはRedshiftクエリエディタからCOPYコマンドを実行してみます。
copy *table_name*
FROM 's3://adjust-sample-001/3ilqwusnz62o_2020-05-19'
credentials 'aws_iam_role=*Redhsiftに設定済みのS3へアクセスするためのIAMロール(既存設定)*'
gzip
delimiter ','
csv
ignoreheader 1
region 'ap-northeast-1';
S3バケット内のファイル指定ですが、前方一致で自動的にワイルドカード指定してくれるので便利です。
1日に24ファイル作られるcsvファイルを、上記の指定でまとめてコピーできます。
また、AdjustからS3にアップロードされるcsvファイルはgzip形式で圧縮されているため、gzipオプションを付ける必要があります。
また、csvファイルの1行目はヘッダ(カラム名)なので、1行目を除いてコピーするためignoreheader 1オプションをつけます。
実行してみてエラーがなければ、ローデータをクエリで扱えるようになっているはずです。
RedshiftはPostgreSQLをベースに、少し独自の仕様があるので、詳しくはAWSのドキュメントをご確認ください。
https://docs.aws.amazon.com/ja_jp/redshift/latest/dg/c_redshift-and-postgres-sql.html
ここまでで、AdjustローデータをRedshiftにコピーしてクエリで扱えるようにするという当初の目的は達成しました。
最後に1日1回、自動でこのコマンドが実行されるように簡単なスクリプトを作成します。
5. コピーコマンドの自動化
pythonスクリプトファイルを作成
以下のようなpythonスクリプトを用意してcrontabで1日1回実行するように設定しました。
# PostgreSQLへ接続するためにpsycopg2を利用する
import psycopg2
from datetime import datetime, timedelta
yesterday = (datetime.today() - timedelta(days=1)).strftime('%Y-%m-%d')
# ログファイル
log_file = '/home/ubuntu/project/project_analytics/copy_log/log_{}'.format(yesterday)
def create_log(string):
with open(log_file, 'w') as f:
f.write(string + '\n')
def add_log(string):
with open(log_file, 'a') as f:
f.write(string + '\n')
# Redshift接続情報
hostName = "Redshiftのホスト名"
databaseName = "RedshiftのDB名"
portNo = "5439"
userName = "Redshiftのユーザー名"
password = "Redshiftのパスワード"
# Connectionオブジェクト作成
conn = psycopg2.connect(
host=hostName,
database=databaseName,
port=portNo,
user=userName,
password=password
)
create_log('psycopg2 connected')
# SQL文を実行するためにはConnectionオブジェクトからさらにCursorオブジェクトを作成
cur = conn.cursor()
add_log('psycopg2 cursor opened.')
# ファイル名が昨日の日付のcsvファイルをまとめて抽出対象とする
file = 's3://adjust-sample-001/3ilqwusnz62o_{}'.format(yesterday)
# copy文
copy_statement = """
COPY *table_name*
FROM '{}'
credentials 'aws_iam_role=*Redhsiftに設定済みのS3へアクセスするためのIAMロール(既存設定)*'
gzip
delimiter ','
csv
ignoreheader 1
region 'ap-northeast-1'
""".format(file)
add_log(copy_statement)
# Cursorオブジェクトのexecute()メソッドでSQL文を実行
add_log('COPY start.')
cur.execute(copy_statement)
add_log('COPY end.')
# 変更をDBに保存
conn.commit()
# コネクションのクローズ
cur.close()
add_log('psycopg2 cursor closed')
conn.close()
add_log('psycopg2 connection closed.')
crontabで1日1回バッチを実行するように設定
cron.confファイルに毎日10:00にスクリプト実行するように設定します。
0 10 * * * python3 /home/ubuntu/project/project_analytics/copy_script_from_adjust.py
crontabで設定ファイルを読み込んで、cronを設定します。
$ crontab cron.conf
これで、今回の作業は完了です。お疲れさまでした。