Advent Calendarに乗じて初投稿です。お手柔らかにお願いします。
本記事には、以下のような技術情報を記載しています
- Pythonを使って、Wiktionary(wikipedia)の記事情報をダンプデータから取得する
- Next.jsで開発したアプリをserwistでPWA化し、Github Pages上に公開する
経緯
勉強がてらちょっとした個人開発をやってみたい、と思いつつ過ごしていたある日、ドライブ中に「黒姫野尻湖」というパーキングエリアが目に留まり閃きます。
「黒姫野尻湖」を直訳(というか一字毎に英訳)すると「 ブラック プリンセス フィールド ヒップ レイク 」、これちょっと面白くないか?と。
この名前は「黒姫山」と「野尻湖」から来ており、それぞれ立派な由来があることは承知しています。が、これを直訳した結果が「ブラック プリンセス」(高貴)、「フィールド」(広大)ときてからの「ヒップ レイク」(臭そう)…地元の方には申し訳ないですが ギャップが面白い 名前に変貌します。
"変な翻訳"というのはしばしば面白さを生みます。例えばGoogle翻訳といった翻訳アプリも、今でこそいい感じに翻訳してくれますが、かつてはガバガバ翻訳がネタにされてきました。あとは「ルー語」も、"変な翻訳"による面白さに近いかもしれません。
…といった経緯から、 わざと変な翻訳するアプリ というコンセプトを思い立ちます。冒頭の「黒姫野尻湖」のように、漢字を一字ごとに英語へ翻訳するような単純なやり方でも面白い結果になりそうですし、個人開発第一弾としての難易度も丁度いいのではと考えました。
前置きが長くなりましたが、今回は「入力された漢字を1字ごとに英語へ翻訳」するアホな翻訳アプリ、"あほんやく"を個人開発した記録となります。
アプリ開発記
どうやって実現するか
パッと思いつくのは、Google翻訳などの翻訳APIに漢字を1字ずつ投げる方法です。Google翻訳に漢字1字を投げてみるとわかるのですが、結構いい感じに翻訳してくれます。
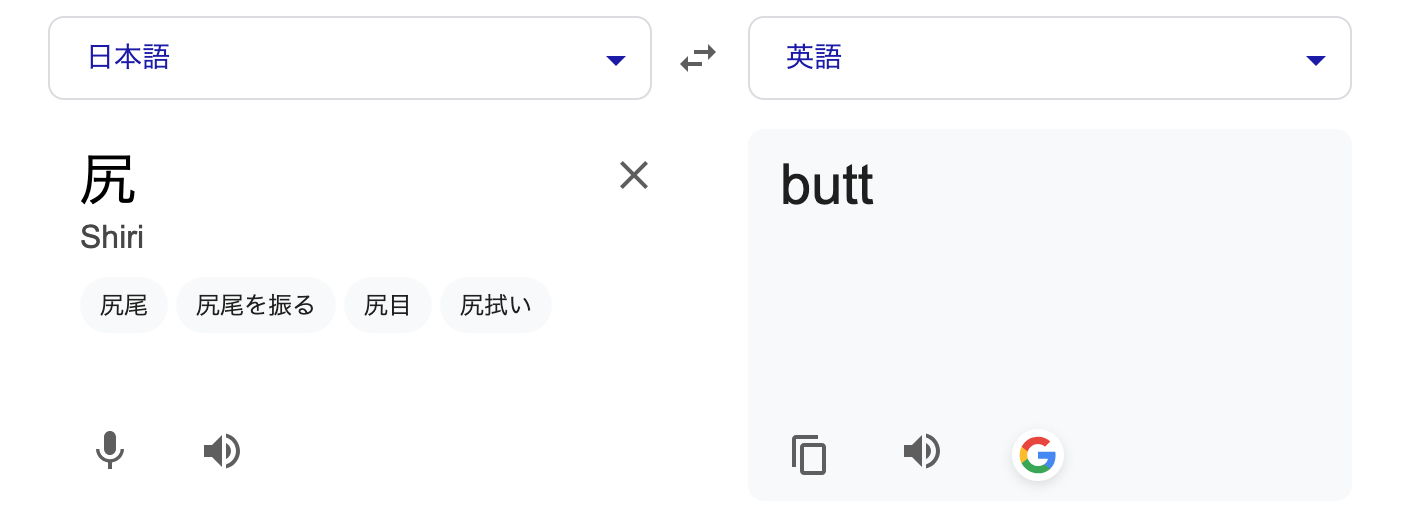
…あれ、 「尻」って「ヒップ」じゃないんですか…?
目指した結果がこんな形で打ち砕かれると思いませんでしたが、一つ賢くなりました。
さておき、このやり方でも悪くはなさそうですが、1字ごとにリクエストが必要となるため非効率です。
そもそも「漢字を一字ごとに英語へ翻訳する」だけですので、Google翻訳のような高度な翻訳機能を使わずとも、「黒」=「ブラック」、「姫」=「プリンセス」のような、漢字ごとの翻訳結果をあらかじめ辞書として作っておくだけで十分そうです。
この辞書の作成手法として、今回は Wiktionary を利用します。
Wiktionaryについて
ウィクショナリー (Wiktionary) は wiki と dictionary の合成語です。ウィキを使った参加型プロジェクトで、辞書を作成することを目的としています。 (Wiktionary日本語版トップページより)
wikipediaに似ていますが、目的が辞書の作成であることが大きな違いです。また、言語ごとに辞書が分かれています。
そこで英語版Wiktionaryを見てみると、以下のように漢字ごとのページが用意されており、英語でその漢字の意味が説明されています。
ここから漢字ごとに英語の意味を抽出すれば、翻訳結果をまとめた辞書データが作れるのではと考えました。
辞書を作成する
Wiktionaryダンプデータの解析
Wiktionaryには全ページの情報を格納したダンプデータが用意されていますので、これを利用します。
解析方法はwikipediaと同じですので、以下の記事を参考にPythonを用いて解析を実施しました。
ダンプデータのダウンロード
以下から最新の日付をクリックし、ダウンロードページに移動します。
必要なのは以下の2ファイルになります。
- enwiktionary-[日付(yyyymmdd)]-pages-articles-multistream-index.txt.bz2
- 各ページのindexが記載されているファイル
- 展開してtxtファイルにして利用する
- このindexファイルから、ダンプデータにアクセスするための情報を抜き出す
- enwiktionary-[日付(yyyymmdd)]-pages-articles-multistream.xml.bz2
- ダンプデータの本体、 展開せずそのまま利用する
indexファイルから必要な情報を抜き出す
まずindexファイルには、1行ごとに以下のような形で情報が記載されています。
ブロック:id:ページタイトル
一方で、ダンプファイルからページを取得するのに必要な情報は次の3つです。
- id
- ブロック
- 次のブロック
この内、「id」と「ブロック」はそのままindexファイルの値を使えばいいです。
厄介なのが「次のブロック」で、indexファイルを順番に見ていき、ブロック値が変わったらその変わった値を「次のブロック」とします。
例えば、"犬"という漢字であれば以下のようになります。
828429:598:犬
828429:599:馬
〜中略〜
828429:670:servant
1004241:671:马
| id | ブロック | 次のブロック |
|---|---|---|
| 598 | 828429 | 1004241 |
また、今回はページタイトルが漢字1文字のみのページを抽出すればよいので、正規表現で「漢字」にマッチするUnicodeスクリプト\p{Script=Han}を用い、漢字1文字のみの行を抜き出せば良さそうです。
以上をまとめたpythonプログラムが以下になります。indexファイルから漢字1文字だけの行を対象に、id、ブロック、次のブロックを読み、jsonファイルに一次データとして書き出します。
コードを展開
import regex
import json
# indexファイルの、漢字1字のみが記載されている行にマッチする正規表現
p = regex.compile(r'^[0-9]+:[0-9]+:\p{Script=Han}\n')
out_text = [] # 最終的に結果を書き出すテキスト配列
buf_list = [] # 一時リスト
buf_block = 0 # 「次のブロック」のために「今のブロック」を覚えておく
# indexファイルをオープン
with open("enwiktionary-yyyymmdd-pages-articles-multistream-index.txt", mode='r') as f:
lines = f.readlines()
# indexファイルの行ごとにループ
for line in lines:
# コロンで区切ってoffset、id、titleに分解
data = line.split(":")
# 冒頭の正規表現にマッチさせ、漢字行かを判定
is_kanji = p.fullmatch(line)
# ブロック値が変わった = "次のブロック"になったので書き出す
if buf_block != int(data[0]):
if len(buf_list) > 0:
for x in buf_list:
# out_textに、id、ブロック、次のブロック、及び漢字を追加する
out_text.append({"id":int(x[1]),"block":int(x[0]),"next_block":int(data[0]),"kanji":x[2].rstrip('\n')})
# 一時リストはクリアする
buf_list.clear()
# 「今のブロック」を覚え直す
buf_block = int(data[0])
# 漢字行だったら、一時リストに追加する
# (この一時リストは、上の「ブロック値が変わった」時の処理で正式に書き出し)
if is_kanji is not None:
buf_list.append(data)
# 最後に結果をjsonに書き出す
with open("kanji_index_list.json",mode="w") as w:
json.dump({"data":out_text},w,ensure_ascii=False,indent=4, sort_keys=True)
実行すると以下のようなjsonファイルが作られます。
{
"data": [
{
"block": 828429,
"id": 598,
"kanji": "犬",
"next_block": 1004241
},
{
"block": 828429,
"id": 599,
"kanji": "馬",
"next_block": 1004241
},
...
]
}
ダンプデータにアクセスする
ここは参考記事のコードをそのまま利用します。
コードを展開
import bz2
import xml.etree.ElementTree as ET
import json
# id、ブロック、次のブロックから、ページ内容を取得する
def get_text(id,block,next_block):
with open("enwiktionary-yyyymmdd-pages-articles-multistream.xml.bz2", "rb") as f:
f.seek(block)
block = f.read(next_block - block)
data = bz2.decompress(block)
xml = data.decode(encoding="utf-8")
root = ET.fromstring("<root>" + xml + "</root>")
page = root.find("page/[id='"+str(id)+"']")
return page.findtext("revision/text")
with open("kanji_index_list.json","r") as json_open:
json_load = json.load(json_open)
d = json_load["data"][0] # 犬
id = d["id"]
block = d["block"]
next_block = d["next_block"]
text = get_text(id,block,next_block)
# とりあえず結果をprintしてみる
print(text)
実行すると以下のようにWiktionaryのページが出力されます。
{{also|大|太}}
{{character info}}
{{character info|⽝}}
==Translingual==
{{stroke order|type=animate}}
===Alternative forms===
* {{l|mul|犭}} (when used as a left Chinese radical)
Although the alternative form clearly shows only three strokes, it is still counted as four strokes when using a Chinese dictionary. Compare [[氵]] from {{m|mul|水||water|sc=Hani}}, [[扌]] from {{m|mul|手||hand|sc=Hani}}, and [[忄]] from {{m|mul|心||heart|sc=Hani}}, all of which are 3-stroke forms from 4-stroke characters.
===Han character===
{{Han char|rn=94|rad=犬|as=00|sn=4|four=43030|canj=IK|ids=⿺大丶}}
...
翻訳結果の抽出
こうして漢字のページ情報を取得できるようになりましたが、取得できるのはwiki記法で書かれたページそのものであり、ここから「漢字の意味」として説明文を探して抽出する必要があります。
これのやり方ですが、いい方法が浮かばなかったので 正規表現でごり押し しました。漢字の意味を抽出するだけでなく、wiki記法の除去も併せて行う必要があります(ソースはあまりに汚いので割愛…)。
大まかな抽出方針は以下です。ただ、Wiktionaryは参加形式の辞書ということもあってか、フォーマットがそこまで統一されておらず、ここに書ききれないくらいの細かい調整を入れています。
- 日本語の意味を取得したいので、まずは見出し:
Japaneseを探す -
Japaneseの直下、またはNoun(名詞)のところにある説明文を取得する - いくつかの意味が記載されている漢字は、一番最初に出てきたものを取得する
- 旧字などは、元の漢字の結果をそのまま用いて同一の意味とする(例:国⇔國は同一の意味とする)
最終的には、以下のように漢字をキーにしたjsonファイルが出来上がりました。
{
"㐂": {
"yaku_eng": "rejoice"
},
"㐌": {
"yaku_eng": "south china"
},
...
}
手動での微調整
ザッと結果を眺めてみて、あまりにも翻訳結果が長いものや、キチンと意味が説明されていないものについては手動で調整を加えました。
場合によっては、対象外として辞書から削除する対応もしています。
// 「こがらし」:あまりに元が長すぎるので簡略化
"凩": {
- "yaku_eng": "kind of strong wind in japan between late autumn and early winter"
+ "yaku_eng": "wintry wind"
}
// 調べてみると愛知の方で使われている方言字とのこと
// まともな翻訳は難しそうなので、今回は対象外として除外する
- "杁": {
- "yaku_eng": "only used for place names in aichi prefecture"
- }
尚、ここで「尻」は「hip」に調整します。 正確には違うのでしょうけど、やっぱ「尻」といえば「hip」の印象が強いので(個人の感想)。
英語→カタカナ読みへの変換
日本人から見ると英語はそれだけで少しかっこよく、変な翻訳感が薄れてしまう印象を受けました。
そこで、「カタカナ読み」への変換を行います。
調べてみたところ、「e2k」というPythonのライブラリが良さそうだったのでこちらを用います。実装は以下の記事を参考に行いました。
コードを展開
from e2k import C2K
from e2k import NGram
import json
ngram = NGram()
# characters directly to katakana
c2k = C2K()
# 英単語一つをカタカナ表記にコンバートする
def convert(english: str) -> str:
if ngram(english):
return c2k(english)
else:
return ngram.as_is(english.lower()) # 小文字で入力必要
# 作成した辞書jsonを開く
with open("translate_table.json","r") as json_open:
json_load = json.load(json_open)
result_json_arr = {}
for data in json_load.items():
result_json_arr[data[0]]={
# 英訳結果はそのまんま
"yaku_eng": data[1]["yaku_eng"],
# 新たにカナ変換結果を作成する
"yaku_kana": "".join(map(lambda x:convert(x),data[1]["yaku_eng"].split()))
}
# カナ付き辞書を新たに保存する
with open("translate_table_with_kana.json","w") as result_json:
json.dump(result_json_arr,result_json,ensure_ascii=False,indent=4, sort_keys=True)
実行すると以下のように、先のjsonファイルにカナ読みが付与されます。
{
"㐂": {
"yaku_eng": "rejoice",
"yaku_kana": "リジョイス"
},
"㐌": {
"yaku_eng": "south china",
"yaku_kana": "サウスチャイナ"
},
...
}
機械学習をベースとしているようで、どんな単語もカタカナ読みに変換できる反面、例えば「of」→「オーエフ」(「オブ」ではない)といったように、思ったのと違う読まれ方をするケースも見られました。
今回はこれも"変な翻訳"の一部と考えて許容し、修正せずそのまま利用することとします。
これで、辞書が形になりました。
アプリを作成する
ユーザー入力をもとに、辞書を用いた翻訳を行うアプリを開発します。
アプリは何で作っても良かったのですが、後述のPWAがよさそうだったのでWebアプリとして開発します。
また、ライブラリとしては個人的な好みでReactを用います。
環境構築
React公式を参考に、今回はNext.js(+TypeScript)を用いました。
公式通りにやればよいので説明は割愛。
AIに大枠を作ってもらう
恥ずかしながら今まで生成AIを使った開発をしたことがなかったので、この機会にUI部分の作成をAIに任せてみます。
何でも良かったのですが、Next.jsと親和性が高そうだった v0 を利用しました。
「ヘンテコな翻訳アプリを作ります。」「Google翻訳のような翻訳アプリと同様のUI構成とします。」みたいなプロンプトを投げたところ、 「ヘンテコ」=不思議系世界観 とみなされてしまったようで、ピンクを中心としたトンデモデザインが降ってきました。以下のような謎アイコンまで作られる始末。

流石にアカンので、きちんと「青と白を基調とした落ち着いたデザイン」と指示し直し。その他細かい手直しも行っています。プロンプトの下手くそさを痛感する結果となりました…。
翻訳処理を作る
TypeScriptで翻訳処理を作成します。
まずは入力された文字を、スプレッド構文で1字ごとの配列にします。
こうすると、「𠮷」などのサロゲートペア文字もキチンと1字ごとに分割してくれます。
// 変数strに入力された文字が入っている
const splited_str = [...str]
この分割した漢字をもとに辞書を探索します。この時、以下のように辞書jsonから漢字型を作ると型安全になってよいです。
// カナ読み付き辞書jsonをimport
import dict from "translate_table_with_kana.json"
// 辞書jsonのキーにある漢字を「漢字」型として定義する
type kanji = keyof (typeof dict)
// 漢字型の型ガード関数
const is_kanji = (key:string):key is kanji=>{
return Object.keys(dict).includes(key)
}
これらをまとめ、ベースとなる翻訳処理を以下のように作成しました。
コードを展開
// カナ読み付き辞書jsonをimport
import dict from "translate_table_with_kana.json"
// 辞書jsonのキーにある漢字を「漢字」型として定義する
type kanji = keyof (typeof dict)
// 漢字型の型ガード関数
const is_kanji = (key:string):key is kanji=>{
return Object.keys(dict).includes(key)
}
// 翻訳関数
const trans = (str:string):string[]= => {
const splited_str = [...str]
// 配列として翻訳結果を作って返す
return splited_str.map(s=>{
// 漢字だったら:辞書の翻訳結果
if(is_kanji(s)){
return dict[s].yaku_kana
}
// それ以外:そのまま
else{
return s
}
})
}
翻訳処理に調整をかける
このままでも最低限の動きはしますが、いくつか調整したほうが面白そうな部分に手を加えます。
踊り字
「々」「ゝ」など、繰り返しで用いる字です。
踊り字は \p{Script=Han} の正規表現にマッチしないため、作った辞書に登録されていません。翻訳の対象外として、例えば「時々」→「タイム 々」とかにしても良いのですが、少々カッコ悪い。
そこで、「時々」→「タイム タイム」といったように、踊り字が出てきたら前の翻訳を繰り返す対応を取ります。
上記Wikipediaを見るに、厳密に対応すると色々考慮するところが多そうですが、そこまで頑張るポイントでもないと考え以下のように簡易的な対応とします。
- 対象は「々」「ゝ」「ヽ」「ゞ」「ヾ」「〻」とします
- 本来は踊り字によって対応する文字種が決まっていますが、今回はすべて同様に「前の翻訳を繰り返す」扱いとします
- 「時々」「時ゝ」はどちらも「タイム タイム」とします
- 濁点用の踊り字(「ゞ」「ヾ」)についても、特に濁点をつけるような対応を行いません(「時ヾ」も「タイム タイム」)
- 踊り字が繰り返されたら、その数だけ前の翻訳にさかのぼって繰り返します
- 例:「一歩々々」 → 「ワン ウォーク ワン ウォーク」
- 踊り字の数が前の文字より多いときは、参照先無し=「ヌルポ」とします
- 例:「古々々米」→「オールド ヌルポ オールド ライス」
- 本当は「古」を2回繰り返して「オールド オールド オールド ライス」とするのが正解のようです
- 上記「一歩々々」のような、2字以上を繰り返す動作との区別が面倒だったので、妥協しています
- 例:「古々々米」→「オールド ヌルポ オールド ライス」
辞書に無い漢字
全ての漢字に翻訳結果を用意するのは難しく、いくつか対象外の漢字も出てきます。
例えば香水で有名な「瑛人」さんの"瑛"の字。Wiktionaryで見てみると(2025年12月現在)意味が説明されていません。
このような漢字は辞書から除外しているため、何も対応しないと「瑛人」→「瑛 パーソン」になります。これでも悪くはないのですが、せっかくの翻訳結果に漢字が残ってしまうのはもったいないなと。
そこで、アホなりに頑張ってる感を出すべく、「辞書に無い漢字用の翻訳結果」を表示するようにしてみました。
- 「辞書に無い漢字」の場合、特殊対応します
- ここでいう「辞書に無い漢字」は、 TypeScriptの正規表現
\p{sc=Han}(Pythonにおける\p{Script=Han}と同義)にマッチしたが、辞書上にはない(is_kanjiがfalse)ものとします
- ここでいう「辞書に無い漢字」は、 TypeScriptの正規表現
- 辞書に無い漢字全てで同じ結果にしても面白くないので、文字コードに応じていくつかパターンを用意します
コードを展開
// 辞書に無い漢字用の翻訳結果を作る
const trans_unknown_kanji = (str:string):string =>{
// 翻訳できなかったときに表示する文字一覧
const unknown_trans_table:string[] = ["ナニコレ","ヨメヘン","シラン","イミフ","ワカンネ"]
// 辞書には無い、けれども\p{sc=Han}にはマッチする場合、それ用の翻訳をする
if(!is_kanji(str) && /^\p{sc=Han}$/u.test(str) ){
// 対象文字の文字コード値に応じて↑のテーブルから文字を返す
return unknown_trans_table[str.charCodeAt(0) % unknown_trans_table.length]
}
// それ以外はそのまま
else{
return str
}
}
これにより、「瑛人」→「シラン パーソン」となります。誰その人知らない…みたいな大変申し訳ない結果に。
PWAとしてアプリを公開する
ここまでで概ねアプリが形になり、あとは公開するだけとなります。やり方ですが、前述の通り今回はPWAとして公開します
PWA(プログレッシブウェブアプリ) とは、インストール型のネイティブアプリっぽい動きが可能なWebアプリです。Qiitaも対応しており、PCであればアドレスバーのところからインストールが可能となっています。
アプリを公開するにあたり、例えば普通のスマホアプリであれば、ストア公開やらなんやらの手続きが必要となります。一方PWAであれば基本はWebアプリなので、どこかのサーバーに配置するだけでOKとなります。その「どこかのサーバー」も、ソースコードを管理するGithubが提供しているGitHub Pagesを用いることで、無料での公開が可能と考えました。
Next.jsのPWAライブラリの選定
ググると「next-pwa」というライブラリが最初にヒットしますが、2022年で開発が止まっているのが気がかり。
Next.jsの公式を見てみると、 serwist というライブラリが紹介されていたため、今回はこちらを用います。
serwist のインストールと設定
serwist公式ドキュメントの通りに進めていけば最低限動くようになります。
まずはインストール。
npm i @serwist/next && npm i -D serwist
続いてドキュメント記載の通りに以下のファイルを修正・作成。
- next.config.ts
- tsconfig.json
- .gitignore
- sw.ts
- manifest.json
manifest.jsonで指定したアイコンファイルも忘れずに作成し、 public フォルダに配置します。
最後にlayout.tsxあたりで、manifest.jsonをメタデータに追加すればOKです。
コードを展開
import type React from "react"
import type { Metadata, Viewport } from "next"
import "./globals.css"
// これを追加
export const metadata: Metadata = {
title: "あほんやく",
manifest: "manifest.json",
}
// 以下略
これだけで最低限のPWA化が完了します。
npm run dev でデバッグ実行して、アドレスバーに「インストール」ボタンが出ていれば成功です。
Github Pagesへのデプロイ
かなりハマったポイントです。
まず、Next.jsのアプリを普通にGitHub Pagesに公開する手順は以下になります。
- GitHub Pages用にプロジェクトへ手を加える
- 静的エクスポートするように変更
- manifest.json等のパスに、GitHubのリポジトリ名を追加
-
npm run buildでビルド結果を確認
→outディレクトリが作られ、jsファイルなどが吐き出されることを確認
- GitHub Actionsを設定
- GitHubへのプッシュをトリガーに、上記
npm run buildがGitHub側で実行されるようになる
→ビルド結果がGitHub Pagesに公開され、アクセス可能になる
- GitHubへのプッシュをトリガーに、上記
これで進めてみると、1.は問題なく進み、試しにローカルで仮サーバー立てて out ディレクトリの中身を配置したらキチンと動くようになりました。
2.もGitHub Pagesに公開されるところまでは良かったのですが…サービスワーカー(sw.tsをビルドしたsw.js)がブラウザへ登録されない事態に。
ローカルサーバーで試したときは動いていたので、多分GitHub Actionsの設定が足りてないのでしょうが…
試行錯誤の末、上記手順の2.以降を妥協することで今回は解決しました。
- GitHub Pages用にプロジェクトへ手を加える
- 静的エクスポートするように変更
- manifest.json等のパスに、GitHubのリポジトリ名を追加
-
npm run buildでビルド結果を確認
→outディレクトリが作られ、jsファイルなどが吐き出されることを確認
- GitHub Pages公開用のリポジトリを作る
- Github Pagesを静的htmlサイトとして設定
- 1.でビルドした
outディレクトリを、上記公開用リポジトリにプッシュ
ビルド結果の out ディレクトリは本来Git管理しないため、正直微妙な対応ではあります
GitHub Pages公開用のリポジトリを作る
GitHubにユーザー登録→ログインの上、公開用にリポジトリを作成します。
私はここまでのプロジェクトをGitHubでソース管理していたため、 ahonnyaku_out という公開用のリポジトリを追加で作成しました。
GitHub Pages用にプロジェクトに手を加える
GitHub PagesにNext.jsのアプリを公開するためには、アプリを静的エクスポートするように設定を見直す必要があります。また、GitHub PagesのURLはリポジトリ名になるため、これに伴う修正も必要となります。
next.config.ts
「output:"export"」を追加し、静的エクスポートするようにするのと、 basePath を公開リポジトリの名称とします。
また、 register:false とし、サービスワーカーの登録も手動としています(これは試行錯誤の残骸なので不要かもしれません…)。
コードを展開
import type { NextConfig } from "next";
import withSerwistInit from "@serwist/next";
const withSerwist = withSerwistInit({
cacheOnNavigation: true,
swSrc: "src/app/sw.ts",
swDest: "public/sw.js",
reloadOnOnline: false,
+ register:false
});
const nextConfig: NextConfig = {
+ basePath:"/ahonnyaku_out",
reactStrictMode: true,
+ output:"export",
};
export default withSerwist(nextConfig);
npm run build を実行するとビルドが走り、 out ディレクトリにhtmlやjsファイルなどが吐き出されるようになります。
サービスワーカーの手動登録設定
まず、手動でサービスワーカーを登録するためのコンポーネントを作ります。
コードを展開
'use client'
import { useEffect } from 'react'
export function RegisterSW() {
useEffect(() => {
if ("serviceWorker" in navigator && window.serwist !== undefined) {
window.serwist.register();
}
},[])
return null
}
これをlayout.tsxあたりで参照するようにします。
コードを展開
import type React from "react"
import type { Metadata, Viewport } from "next"
+import { RegisterSW } from "./components/register-sw"
// 略
export default function RootLayout({
children,
}: Readonly<{
children: React.ReactNode
}>) {
return (
<html lang="ja">
<body className={`font-sans antialiased`}>
+ <RegisterSW />
{children}
</body>
</html>
)
}
manifest.json
アイコンファイルなどのパスに、GitHubのリポジトリ名を追加します
コードを展開
{
"name": "あほんやく",
"short_name": "あほんやく",
"description": "アホな翻訳アプリ",
- "start_url": "/",
+ "start_url": "/ahonnyaku_out/",
"display": "standalone",
"background_color": "#ffffff",
"theme_color": "#ffffff",
"icons": [
{
- "src": "/icon-192.png",
+ "src": "/ahonnyaku_out/icon-192.png",
"sizes": "192x192",
"type": "image/png"
},
{
- "src": "/icon-512.png",
+ "src": "/ahonnyaku_out/icon-512.png",
"sizes": "512x512",
"type": "image/png"
}
],
"orientation": "portrait"
}
layout.tsx
manifest.jsonのパスに、同様にGitHubのリポジトリ名を追加します
コードを展開
import type React from "react"
import type { Metadata, Viewport } from "next"
import "./globals.css"
export const metadata: Metadata = {
title: "あほんやく",
- manifest: "manifest.json",
+ manifest: "/ahonnyaku_out/manifest.json",
}
// 以下略
ここまででプロジェクトの修正は完了です。 npm run build を実行し、 out ディレクトリにビルド結果を出力しておきます。
尚、 npm run dev でデバッグする際のlocalhostのURLも、http://localhost:3000/ahonnyaku_out/ といったようにリポジトリ名付きに変わります。
Github Pagesを静的htmlサイトとして設定
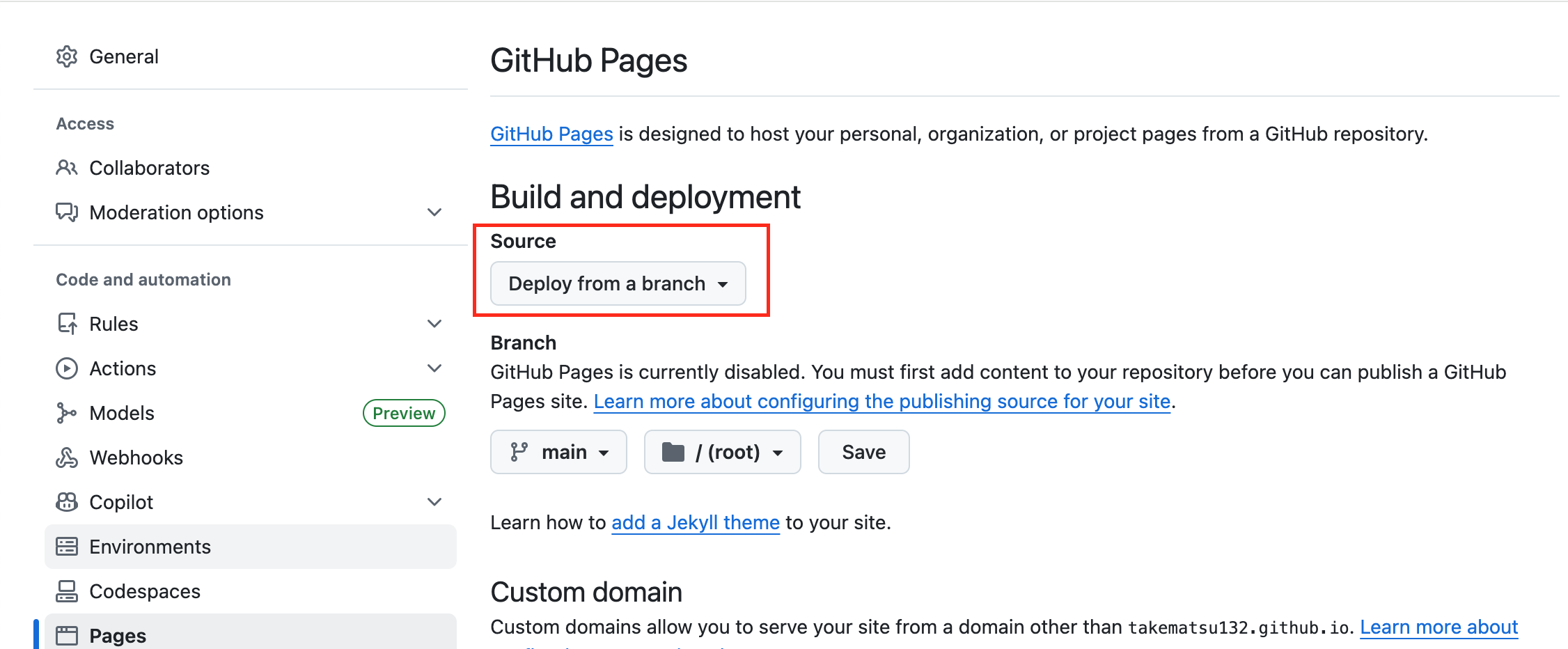
GitHub Pagesの設定をします。
リポジトリの「Settings」から「Pages」に移動します。下図赤枠の「Deploy from a branch」のところを「GitHub Actions」に変更します。
以下のように色々出てくると思うので、「Static HTML」のConfigureを選択します。
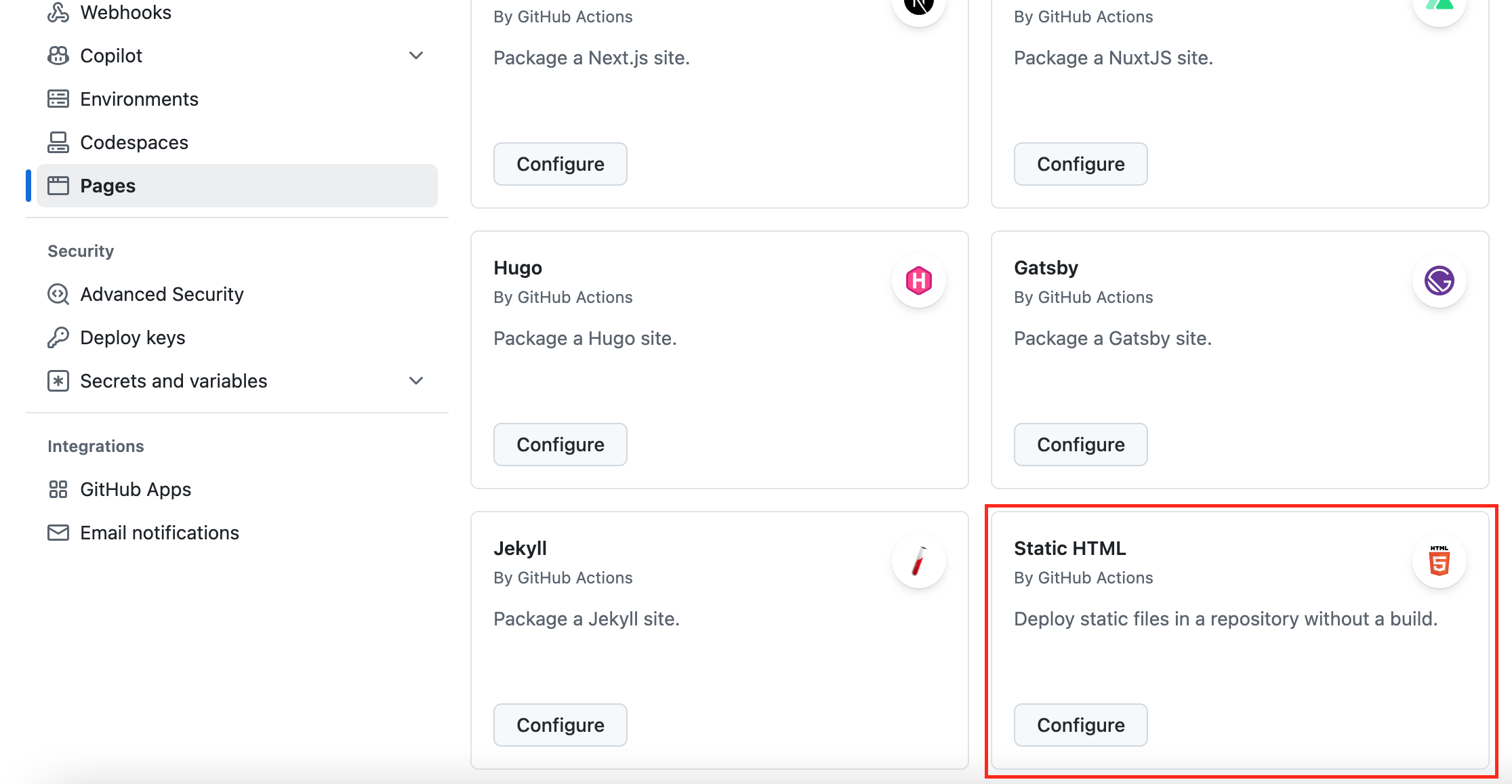
すると「static.yml」というyamlファイルの編集画面になります。特に編集無しでコミットすればOKかと思います。
1.でビルドした out ディレクトリをプッシュ
ここまで設定すれば、リポジトリにhtmlをプッシュすることで、アプリが公開されるようになります。
まず、ビルド結果の out ディレクトリだけを、ローカルでGit管理するところから始めます。
やり方は何でもいいのですが、私は愚直に out ディレクトリを別の場所にコピー→ git init しました。
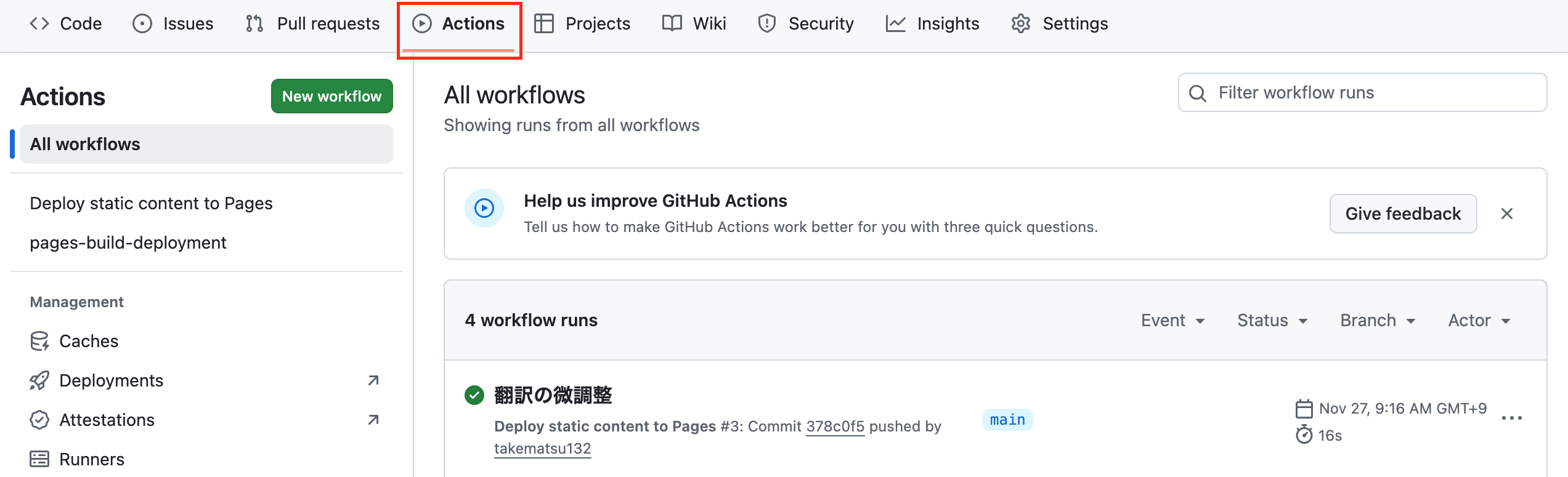
そのうえで、上で作った公開用リポジトリをリモートに設定してプッシュします。
プッシュすることで、GitHub Actionsで設定したスクリプト(static.yml)が動作し、htmlが公開されるようになります。リポジトリの「Actions」を開き、以下のように緑のレになっていればOKだと思います。
完成
完成品がこちらです。
感想
きっかけとなった「黒姫野尻湖」については、「 ブラック プリンセス エリア ヒップ レイク 」と翻訳する結果となりました。
「フィールド」が「エリア」になりましたが、他は想定通り翻訳できており、個人的には満足しています。
一つ心残りとしては、オフライン対応が期待通りにできなかったところ。
PWAはサービスワーカーに設定を入れることで、キャッシュを用いたオフライン動作が可能です。この話を聞いたとき、以下のような動きができるのでは?と期待していました。
- ブラウザから見てるときは普通のWebアプリとして動作
- 「インストール」されたら、ネイティブアプリ風の動作に切り替え
- ソース類をすべてキャッシュし、オフラインでも動作
こんな感じでインストールの有無で動作が変えられて、完全にオフラインでも動作するアプリを作れるのかと思っていたのですが、イマイチ情報が見つからず。
一応、現状でもserwistのデフォルトキャッシュ期限(多分1日)はオフラインでも動きます。ただし期限を過ぎるとオフラインでは動作しません。
ここまで目指すならPWAで頑張るよりも、ネイティブアプリとして作った方が早いのかもしれません。
おまけ
遊び方の例
ドライブ中の話題のネタ
冒頭の「黒姫野尻湖」に限らず、地名は比較的おかしくなりがちです。
サービスエリアや看板の地名など、ドライブ中に見つけた地名を入れてみましょう。ちょっとした車内の会話ネタになります。
ネタばれ対策などで伏字を作る
ネタばれ防止、検索除け、下ネタ(残念ながら面白くなりがち)など、ちょっとした伏字を作りたいことも多い昨今。そんなときにも使えます。
オーガ デストロイ の ブレード ノージング リミット ライン カー コンパイル 観てきた!
最後の リファインメタルズ プリソン さんには涙が止まりませんでした
見事にネタバレを回避できてますね。その代わり何言ってんだこいつと白い目で見られそうですが。
ほかの翻訳アプリと合わせて逆翻訳
実はカタカナの翻訳結果とともに、英語の結果も表示しています。本旨から外れるので省略しましたが無駄に頑張ったポイント。
これをGoogle翻訳とかに入れるとアホな逆翻訳が楽しめます。以下、一例です。
-
「水樹奈々」
―(あほんやく)→「water tree what what」
―(Google翻訳)→「 水樹 何か 」
-
「三井住友銀行」
―(あほんやく)→「three well dwelling friend silver go」
―(Google翻訳)→「 3つの井戸に住む友人シルバーゴー 」
-
「ハム太郎」
―(あほんやく)→「hamu fatness son」
―(Google翻訳)→「 ハム太り息子 」
個人的に好きなアホ翻訳集
- 「天の川」→「スキー の ライバー」
何もかもが違う 。
普通は「天の川」といえば「milky way」なところを、英語のテストで無理やりひねり出したかのごとき「sky no river」という時点でおかしいのに、読み方も「そっちで読んじゃったか」という結果に。 雪山が大好きな配信者 みたいになっちゃってます。
「アホな翻訳」というコンセプトを体現していて好きです。
- 「未来」→「シープ カミング」
羊が来る!
何でシープ?と思ったら、干支のヒツジ(未)が翻訳結果になっていた模様。
本来"ミライ"という言葉が持つワクワク感と、 羊が向かってくる光景 とのギャップがジワジワきます。
- 「富士山」→「ウェルス サムライ マウンテン」
やはり日本の象徴といえばサムライなのか…?
サムライに目が行きがちですが「ウェルス(wealth)」もいいですね。地味に3・4・5調なのでリズム感もいいです。
… もしかしてMt.FUJIより良いのでは? (そんなことはない)
- 「性格」→「セックス ステータス」
「どんな性格(セックス ステータス)の人が好き?」
「やっぱ優しい性格(セックス ステータス)かな~」
これはひどい 。
とはいえ、「性」→「sex」は Google翻訳さんもそう訳す ので、何も間違っていません。