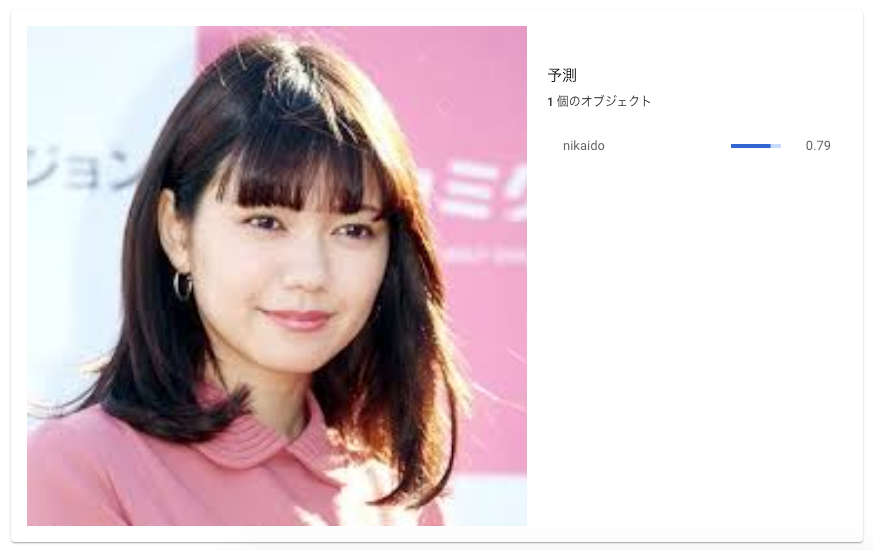
以下の写真は誰でしょうか。

二階堂ふみさんです!
では、以下の写真は誰でしょうか。

山本舞香さんです!
髪型、表情、照明によっては、非常に似ていますね。
どちらも綺麗です。
(以下比較画像。)

今回は、Googleの機械学習を元にしたGCPのプロダクト「AutoMLVision」を
使って、二人の画像識別を行いました。
Cloud AutoML
機械学習の専門知識、プログラミング知識がなくても、簡単に機械学習の
トレーニング、評価、改善、デプロイが可能。ビジネスニーズに合わせて作成することも可能。
AutoMLの中には、いくつかのプロダクトがある。
| プロダクト名 | 用途 |
|---|---|
| AutoML Vision | 画像分類 |
| AutoML Video Inteligence | 動画コンテンツ検出 |
| AutoML Natural Language | 自然言語処理 |
| AutoML Translation | 翻訳 |
| AutoML Tables | 構造化データ |
今回使用するプロダクトは、「AutoMLVision」。
AutoML Vision
独自の画像識別の機械学習モデルを作成できる。
自分で識別したい画像をアップロードすることで、プログラムを書くことなく、
自動でアップロード画像に合わせてモデル作成される。
(例: 猫の種類の識別、カレイの種類識別、不良品の識別)
注意
- GoogleCloudアカウント登録が必要。(無料枠あり)
1.準備
GCPコンソール上でCloud AutoML API
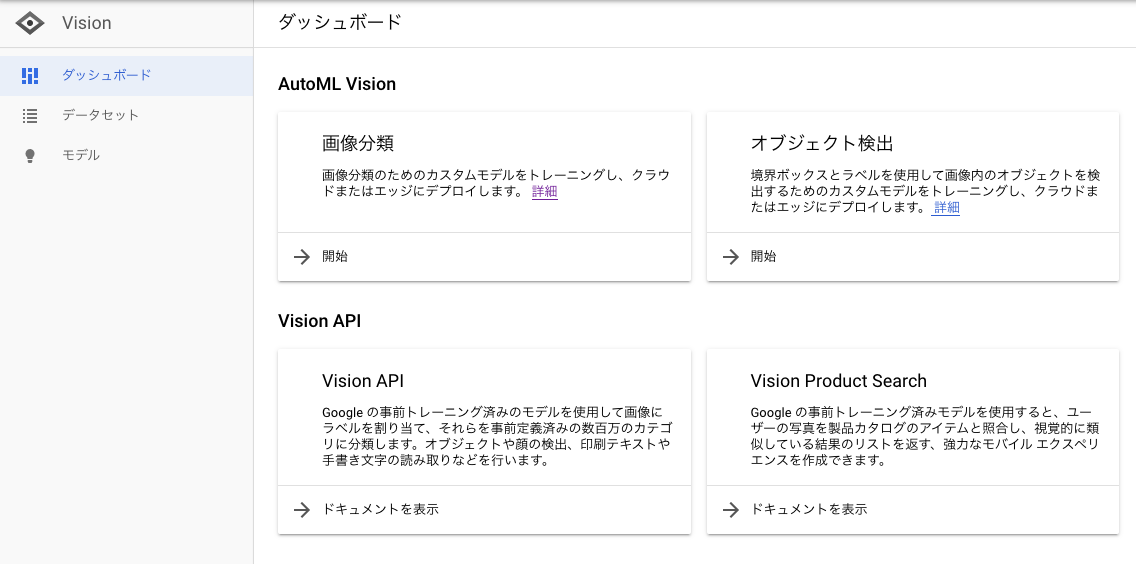
GCPメニュー Vision > ダッシュボード > AutoML Vision > 画像分類
データセット>新しいデータセット
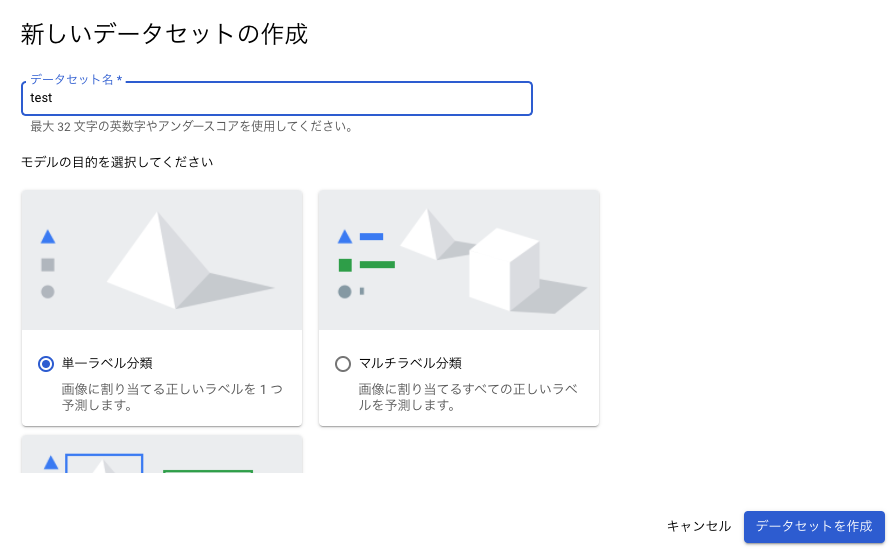
データセット名を適当に記述。
モデルの目的を「単一ラベル分類」を選択。
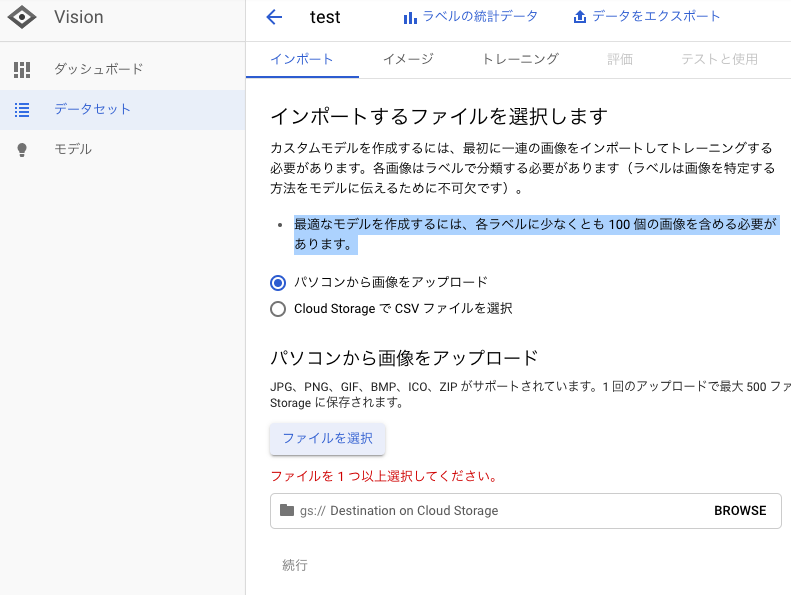
2.モデル作成に必要な画像アップロード
最初に使用する画像をアップロードして、ラベリングする必要がある。
アップロード方法は、
・localから直接アップロード
・GCSからCSVファイルをアップロード
→ 今回は、直接PCからアップロード。
<ポイント>
最適なモデルを作成するには、各ラベルに少なくとも 100 個の画像を含める必要があります。
より、精度を求めるには、最低1000枚必要という人もいる、、、
今回は、1000枚頑張って用意した、、、
画像の取得は、スクレイピング等を使うとある程度が取得可能。(末尾Apendixに追記)
3 ラベリング
ローカルから画像アップロードした場合、別途ラベリングする必要がある。
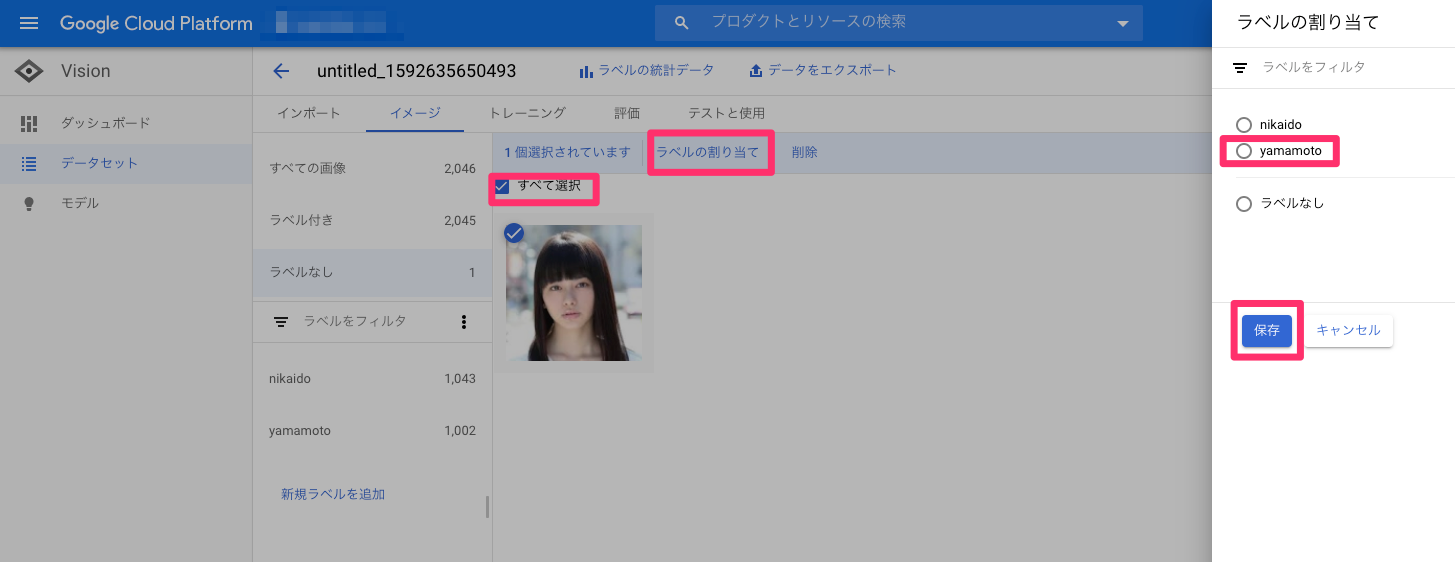
200枚ずつラベリング可能。
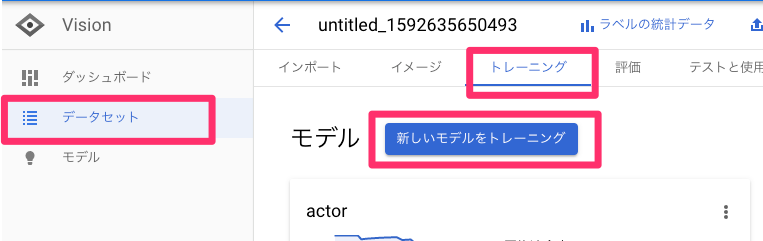
4 トレーニング
全てラベリングしたら、トレーニングを行う。
学習は、自動的に画像を3つのセットに分割されて、それぞれ
トレーニング:80%
ハイパーパラーメータ調整等:10%
モデルの評価:10%
に使用される。
トレーニングタブから「新しいモデルをトレーニング」。
モデルを選択。
「Cloud hosted」を選択。
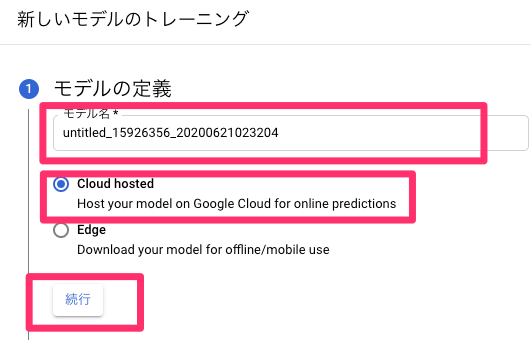
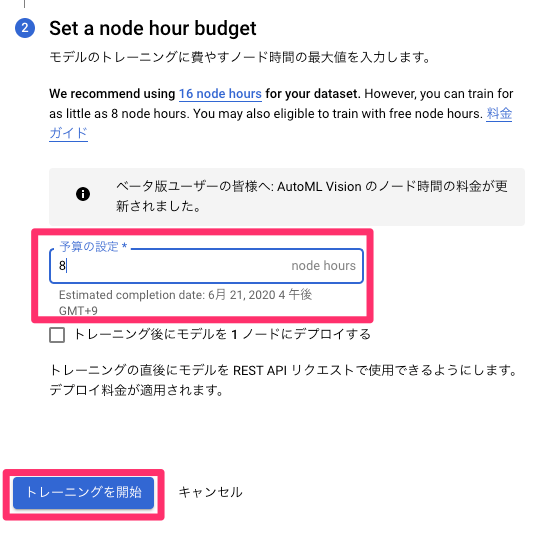
トレーニングのノード時間を設定。
今回は8時間に設定。
初回無料枠あり。
請求先アカウント 1 つにつき、トレーニングとオンライン予測それぞれに 40 時間の無料ノード時間を、さらにバッチ?>予測に 1 時間の無料ノード時間を使用できます。
トレーニングを開始。(約1時間)
5 評価
以下評価結果。
適合率:84.83%
再現率:84.83%
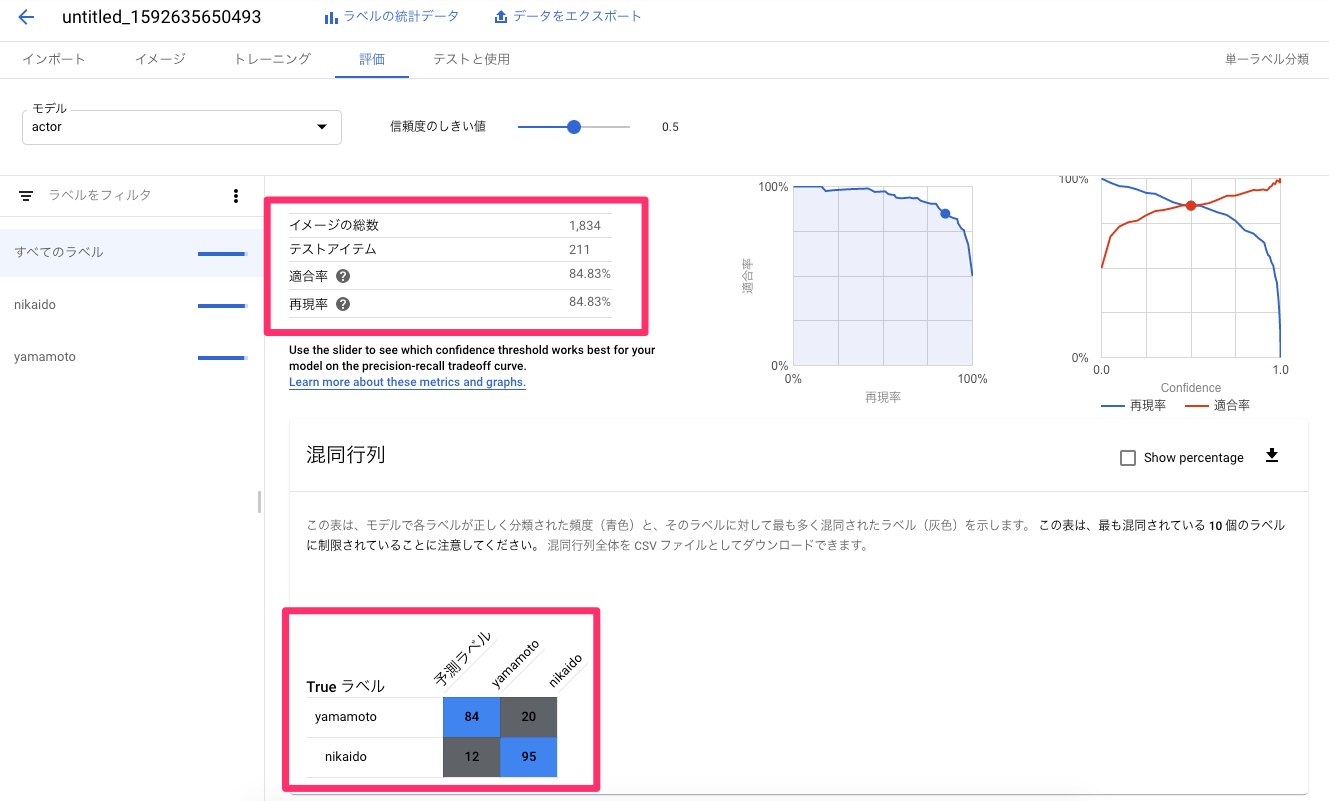
最初にしては、いい数値かと!
6 デプロイ・テスト
モデルで実際に予測できるように、デプロイする。
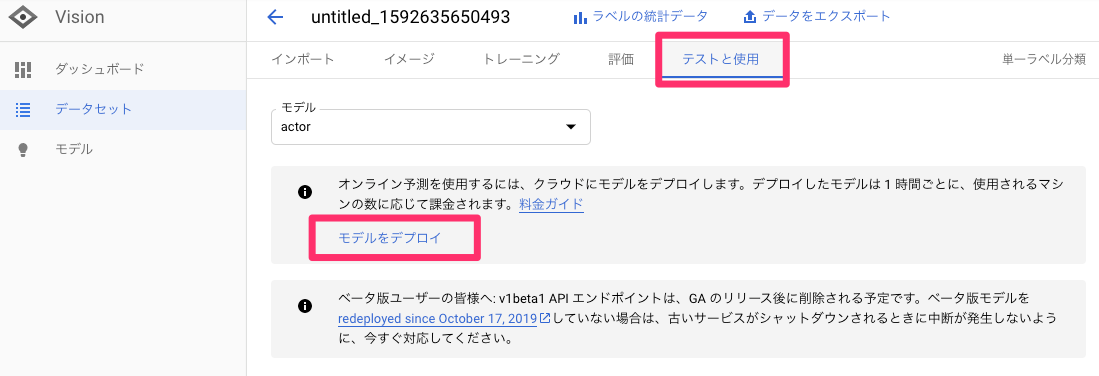
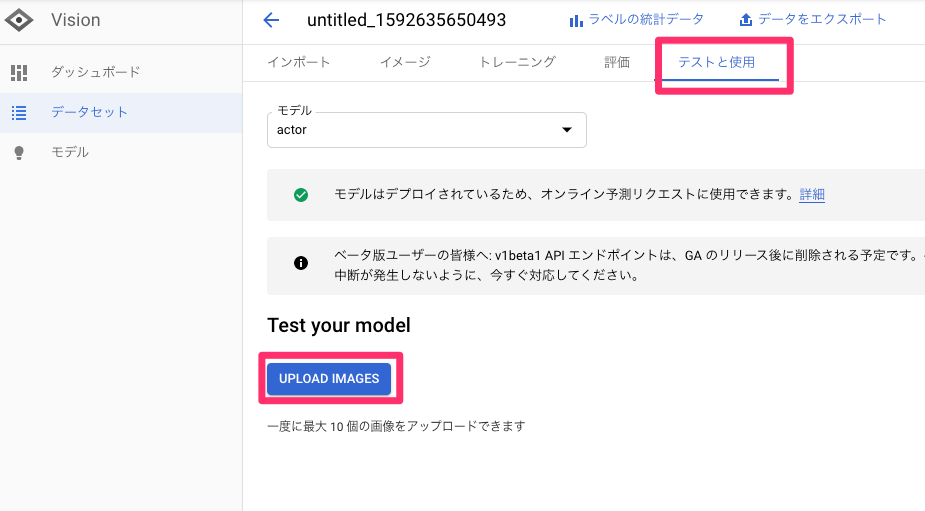
APIでオンライン予測も可能。サービスに組み込むこともできる。
実際の画像をアップロードして、予測を行う。

Appendix
1000枚の画像収集が大変。以下の記事を参考に取得。
その他、Youtube動画のスクリーンショットをする。
https://qiita.com/kumakuma324/items/9e026c11838b4e94ad2d
おまけ
宮崎あおいはどちらに似ているのでしょうか。
