クラスタリングアルゴリズムの一つであるDBSCANの概要や簡単なパラメータチューニングについて,
日本語記事でまとまっているものがないようでしたのでメモしました。
DBSCANの概要は,wikipediaの(雑な)和訳ですのでご容赦ください。
DBSCANとは
-
Density-based spatial clustering of applications with noiseの略 - クラスタリングアルゴリズムの一つ
アルゴリズムの概要
- 1.点を3つに分類する
- Core点 : 半径ε以内に少なくともminPts個の隣接点を持つ点
- Reachable点(border点):半径ε以内にminPts個ほどは隣接点がないが,半径ε以内にCore pointsを持つ点
- Outlier : 半径ε以内に隣接点がない点
- 2.Core点の集まりからクラスタを作成し,Reachable点を各クラスタに割り当てる.
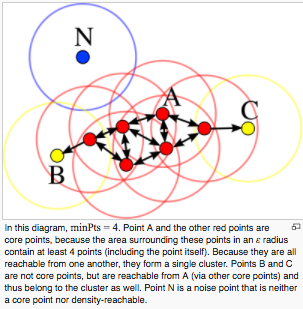
[図wikipediaより]
長所
- k-meansと違って,最初にクラスタ数を決めなくてよい
- とがったクラスタでも分類できる。クラスタが球状であることを前提としない
- outlierに対してrobustである。
- パラメータがεとminPtsという二つでよい。また,パラメータの範囲も判断しやすい。
短所
- border点の概念が微妙で,データによりどのクラスタに属するか変わる可能性がある。
- 距離の計算方法により,精度が変わる。
- データが密集していると適切にεとminPtsを決めるのが難しい。ほとんどの点を一つのクラスタに分類してしまう場合も
- データがわからないとεを決めるのが難しい。
- (DBSCANに限った問題ではないが)次元が大きくなると次元の呪いの影響を受ける
他のアルゴリズムとの違い
scikit-learnのデモページにある各手法の比較した図なのですが,右から2番目がDBSCAN。densityに基づいてクラスタリングされていることが直感的にわかる。

εとminPtsのチューニング
二次元だと可視化させてうまく分類できているか判別できるのだが,3次元以上になると可視化して判断するのは難しい。
以下のようにしてoutlierやクラスタ数をデバッグして調節した。
(scikit-learnを利用)
from sklearn.cluster import DBSCAN
for eps in range(0.1,3,0.1):
for minPts in range(1,20):
dbscan = DBSCAN(eps=eps,min_samples=minPts).fit(X)
y_dbscan = dbscan.labels_
print("eps:",eps,",minPts:", minPts)
# outlier数
print(len(np.where(y_dbscan ==-1)[0]))
# クラスタ数
print(np.max(y_dbscan)))
# クラスタ1に含まれる点の数
print(len(np.where(y_dbscan ==0)[0]))
# クラスタ2に含まれる点の数
print(len(np.where(y_dbscan ==1)[0]))
DBSCAN関連のリンク
- wikipedia
- 公式ドキュメント
- 公式デモページ
- Qiita
追記
日本語版Wikipediaが更新され、記述が追加されていました。わかりやすいです。