通常のGPUによる並列化はData Parallel(データ並列)であり、データバッチを複数のGPUで並列で処理するものです。
PyTorchだとnn.DataParallelを使う方法です。(参考:https://qiita.com/arutema47/items/2b92f94c734b0a11609d )
これで学習速度を速くできます。しかし、データ並列では1つGPU容量を超えたネットワークを学習することが出来ません。
そこで、もう一つの並列化の方法として、1つのネットワークを複数のGPUに部分分割して学習するという手法が考えられます。
これを**Model Parallel(モデル並列)**というそうです。
特に3次元データのDeep Learningなどではネットワークが巨大になって、GPUでのメモリが足りなくなる事態が発生します。
そういった場面ではこのModel Parallelは役に立つと思われます。
実装する
やり方はPyTorchのチュートリアルを参考にしました。
https://pytorch.org/tutorials/intermediate/model_parallel_tutorial.html
ResNet50の並列化を行います。
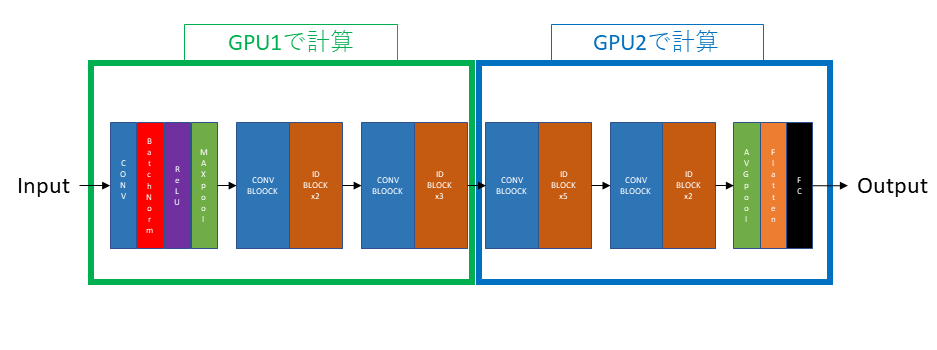
モデル並列のイメージとしては、下図のような感じです。
ネットワークの前半をGPU1で、後半をGPU2で学習させます。
環境
GPUはTesla P100(16GB)のGPUを2台使いました。(NVLINKにより接続されている)
OSはLinux(Red Hat Enterprise)
CUDA 9.0
Anaconda
Python 3.6
PyTorch 1.1.0
コード
ResNetのネットワークを二つに分割してそれぞれをGPU('cuda:0'と'cuda:1')を指定して割り当てます。
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.models as models
from torchvision.models.resnet import ResNet, Bottleneck
num_classes = 1000
class ModelParallelResNet50(ResNet):
def __init__(self, *args, **kwargs):
super(ModelParallelResNet50, self).__init__(Bottleneck, [3, 4, 6, 3], num_classes=num_classes, *args, **kwargs)
self.seq1 = nn.Sequential(
self.conv1,
self.bn1,
self.relu,
self.maxpool,
self.layer1,
self.layer2
).to('cuda:0')
self.seq2 = nn.Sequential(
self.layer3,
self.layer4,
self.avgpool,
).to('cuda:1')
self.fc.to('cuda:1')
def forward(self, x):
x = self.seq2(self.seq1(x).to('cuda:1'))
return self.fc(x.view(x.size(0), -1))
入力はランダムな値で埋めた(3,1024,1024)の画像にして、batch size=10で学習してみます。
batch_size = 10
image_w = 1024
image_h = 1024
model = ModelParallelResNet50()
# 通常のResNet50で学習するときは model = models.resnet50(num_classes=num_classes).to('cuda:0')
model.train()
loss_fn = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.001)
one_hot_indices = torch.LongTensor(batch_size).random_(0, num_classes).view(batch_size, 1)
for _ in range(1000):
inputs = torch.randn(batch_size, 3, image_w, image_h)
labels = torch.zeros(batch_size, num_classes).scatter_(1, one_hot_indices, 1)
optimizer.zero_grad()
outputs = model(inputs.to('cuda:0'))
labels = labels.to(outputs.device)
loss_fn(outputs, labels).backward()
optimizer.step()
実行している間に、シェルでnvidia-smiコマンドしてGPUの使用状況を確認します。
$ nvidia-smi
...
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla P100-SXM2... On | 00000000:61:00.0 Off | 0 |
| N/A 31C P0 46W / 300W | 14637MiB / 16276MiB | 48% Default |
+-------------------------------+----------------------+----------------------+
| 1 Tesla P100-SXM2... On | 00000000:62:00.0 Off | 0 |
| N/A 35C P0 241W / 300W | 6657MiB / 16276MiB | 80% Default |
+-------------------------------+----------------------+----------------------+
...
2つのGPUでメモリが使われていることが確認できました。
最後に
nn.Sequentialで層をまとめてGPUを指定するだけなので、簡単にできました。
ちなみに巨大なネットワークを学習する他の方法としてUnified Memoryなどがあります。
参考:https://qiita.com/koreyou/items/4494442eb71bea0bb5b2
また他の手法としては、元々のGPUメモリ容量が大きいTPUを使うというのも考えられます。
*追記(2020/04/30)
3D U-NetのModel Parallelを実装したものをgithubに公開しました。
https://github.com/atakehiro/3D-U-Net-pytorch-model-parallel