tl; dr
- Chainerにおいて、以下の関数をGPUメモリを使う前に挿入することで、GPUメモリの大きさ以上の深層学習モデルを扱える。
- ただし、パフォーマンス改善につながらないので、ミニバッチの大きさを大きくする目的では使わないこと。
import cupy as cp
pool = cp.cuda.MemoryPool(cp.cuda.malloc_managed)
cp.cuda.set_allocator(pool.malloc)
はじめに
...
cupy.cuda.memory.OutOfMemoryError: out of memory to allocate 8589934592 bytes (total 17179869184 bytes)
などとエラーを吐かれて泣いた記憶はないでしょうか。
最近は様々な分野で深層学習のモデルの巨大化が激しいです。学習時間が長くなるのは致し方ないとして、モデルによってはGPUメモリにのらず、そもそもまともに動かすことができないという問題に直面することがあります。特に、Graph Convolution系のアルゴリズムでは、ミニバッチ学習方法が確立されていない1ため、GPUメモリの大きさの制約を受けやすいです。
本記事では、Pascal以降のNVidia GPUから機能が拡張された2Unified Memoryを使って、GPUメモリよりも大きなモデルをChainerで扱う方法を紹介します。
注記
CPUメモリとGPUメモリのやり取りが増えるので、もちろん効率が悪くなります。最低限モデル+1データがGPUに乗るのであれば普通にマルチGPUをしたほうが良いと思います3。
以下のケースが該当する場合はここに記載のアプローチが有効だと考えられます。
- Graph Convolution Network (GCN)など、ミニバッチ学習方法が確立されておらず、モデル全体をGPUに上げる必要がある場合。
- どうしてもGPUメモリに乗らないサイズのモデルを扱うとき。
- マルチGPUが手元になく、ミニバッチサイズを1で学習すると学習が安定しないとき。
なお、本アプローチの代案としてGoogleのTPU (64GBのメモリがある)を使ったり、半精度(FP16)を使う(代替メモリ消費が80%程度に抑えられる)ことが考えられます。あと、モデルがうまくわけられるのであればマルチGPUでモデル並列化なども可能です4。
方法
ChainerからGPUを使う前に以下の関数を実行(ソースコードに記載)しておきます。
import cupy as cp
pool = cp.cuda.MemoryPool(cp.cuda.malloc_managed)
cp.cuda.set_allocator(pool.malloc)
以上です。
本当にGPUメモリ以上が扱えるかを確認するためには以下のようなコードを実行してみます。
import cupy as cp
size = 32768 # 32GBのV100ならば、以下が1つあたり16GBになるよう46341にする
a = cp.ones((size, size)) # 8GB (16GB)
b = cp.ones((size, size)) # 8GB (16GB)
c = cp.ones((size, size)) # 8GB (16GB)
Chainerの裏ではCuPyが動いているので、CuPyで問題なければChainerも問題ないことは自明でしょう。
解説みたいなもの
(この分野の専門家ではなく、この記事のために軽く調べただけなので話半分くらいに聞いてください)
Unified Memoryとは、要はCPUとGPUで共通のメモリ空間(=GPUメモリ+CPUメモリ)を使う方法です。
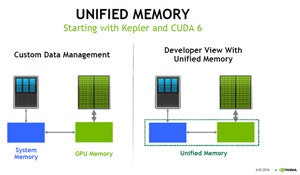
(from https://news.mynavi.jp/article/unified_memory-1/)
Pascal以前にもUnified Memory自体はあったものの、使用するデータをGPUのメモリに移動しないとデータを活用できないため今回のような用途には使えませんでした。それに対して、Pascal以降は必要なデータだけを逐次アクセスUnified Memoryから取得できるようになったため、今回のようなことができるようになったそうです。
プロによる詳しい解説はこちら。
参考文献
- 根岸ら. 2017. Unified Memoryを用いた大規模ディープラーニングモデルの性能に関する考察. 日本ソフトウェア科学会第34回大会.
- 奥田遼介. 2018. CuPy -NumPy互換GPUライブラリによるPythonでの高速計算-. GTC Japan.
- Hisa Ando. 2016. GTC Japan 2016 - Pascalのユニファイドメモリ. マイナビニュース.