本記事ではcubic splineを用いて、時系列データを補間する方法を紹介します。
スッと出来るようになりたいのですが、使いたいときには忘れている。。。
補間処理する前にデータの時間単位を細かくするところがポイントです。
はじめに
センサーデータ等で複数のデータを取り扱う際に データの時系列的に同期取れていない場合、補完処理が必要になる。例えば、こんなデータがあるとする。
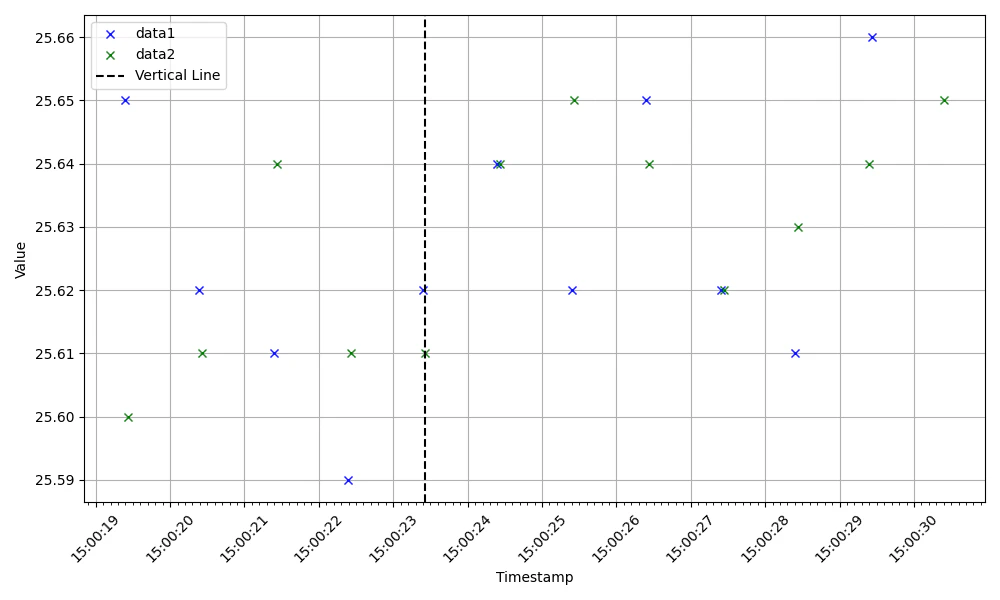
data1とdata2があって、時系列が一見あっているように見えるが、、、実は合っていない。
こんなデータを機械学習の学習データとして取り扱うには、補間処理が必要となる。
また、ミリ秒単位のデータとなっているため、データ量削減のために秒単位のデータにしたい。
結果のイメージ
結果のイメージはこちら↓

元データ(x)に対して、補間した新しいデータ(○)が1秒単位に整形され、かつ元のデータと同じ曲線上にあり、尤もらしい値を取っているように見えるようになりました。
(あくまで補間なので本当に、その時点でその値になったとは保証できません。)
補間処理の手法はいくつかありますが、今回はcubic補間法を適用しました。cubic補間は、スプライン曲線を使用してデータを滑らかに補間する方法です。スプライン曲線は、前後のデータ含めた3点から、滑らかな曲線を生成します。
そのため、最初のデータは前の時点のデータがないため、次点のデータをそのまま採用しています。ご注意ください。
手順の詳細
以下の手順にそって詳細です。
データの時系列を丸める(四捨五入する)
まずは、データを細かくした上で補間するため、処理しやすいようにデータを丸めます。
df1['Timestamp'] = df1['Timestamp'].dt.round("0.1S") # 100ミリ秒以下を丸める
df2['Timestamp'] = df2['Timestamp'].dt.round("0.1S") # 100ミリ秒以下を丸める
ここで100ミリ秒単位で四捨五入することで誤差が発生するため、丸める単位は各自で検討願います。
Timestamp Value1
0 2023-08-24 15:00:19.292372 25.65
1 2023-08-24 15:00:20.392646 25.62
2 2023-08-24 15:00:21.394758 25.61
3 2023-08-24 15:00:22.395541 25.59
4 2023-08-24 15:00:23.396453 25.62
5 2023-08-24 15:00:24.397867 25.64
6 2023-08-24 15:00:25.401104 25.62
7 2023-08-24 15:00:26.400618 25.65
8 2023-08-24 15:00:27.401027 25.62
9 2023-08-24 15:00:28.402504 25.61
↑こういったデータが↓こうなります。
Timestamp Value1
0 2023-08-24 15:00:19.300 25.65
1 2023-08-24 15:00:20.400 25.62
2 2023-08-24 15:00:21.400 25.61
3 2023-08-24 15:00:22.400 25.59
4 2023-08-24 15:00:23.400 25.62
5 2023-08-24 15:00:24.400 25.64
6 2023-08-24 15:00:25.400 25.62
7 2023-08-24 15:00:26.400 25.65
8 2023-08-24 15:00:27.400 25.62
9 2023-08-24 15:00:28.400 25.61
扱うデータを外部結合する
次に今回扱うデータは2系統なので2つのデータを外部結合し、歯抜けデータを作ります。
data_list = pd.merge(df1,df2,on = "Timestamp", how='outer') # 外部結合 該当するTimestampがない場合はNaNで行追加
この時点ではデータは以下のようになります。
Timestamp Value1 Value2
2023-08-24 15:00:19.300 25.65 NaN
2023-08-24 15:00:19.400 NaN 25.60
2023-08-24 15:00:20.400 25.62 25.61
2023-08-24 15:00:21.400 25.61 25.64
2023-08-24 15:00:22.400 25.59 25.61
2023-08-24 15:00:23.400 25.62 25.61
2023-08-24 15:00:24.400 25.64 25.64
2023-08-24 15:00:25.300 NaN 25.65
2023-08-24 15:00:25.400 25.62 NaN
2023-08-24 15:00:26.400 25.65 25.64
NaNになっているところが歯抜け(同期がとれていない箇所)です。
resampleしてデータを時系列として細分化
次にresampleして、100ミリ秒間隔になるようにデータを追加していきます。
Value1 Value2
Timestamp
2023-08-24 15:00:19.300 25.65 NaN
2023-08-24 15:00:19.400 NaN 25.6
2023-08-24 15:00:19.500 NaN NaN
2023-08-24 15:00:19.600 NaN NaN
2023-08-24 15:00:19.700 NaN NaN
2023-08-24 15:00:19.800 NaN NaN
2023-08-24 15:00:19.900 NaN NaN
2023-08-24 15:00:20.000 NaN NaN
2023-08-24 15:00:20.100 NaN NaN
2023-08-24 15:00:20.200 NaN NaN
こんな感じに大量の時間情報だけの空行をつくります。
ようやく補間
pandasのinterpolate関数をつかって補間します。methodパラメータを指定することで様々な補間方法を試せます。
data_list["Value1"].interpolate(method="cubic",inplace = True)
data_list["Value2"].interpolate(method="cubic",inplace = True)
結果は↓
Value1 Value2
Timestamp
2023-08-24 15:00:19.300 25.650000 NaN
2023-08-24 15:00:19.400 25.644600 25.600000
2023-08-24 15:00:19.500 25.639902 25.596373
2023-08-24 15:00:19.600 25.635849 25.594123
2023-08-24 15:00:19.700 25.632385 25.593119
2023-08-24 15:00:19.800 25.629457 25.593230
2023-08-24 15:00:19.900 25.627007 25.594326
2023-08-24 15:00:20.000 25.624980 25.596276
2023-08-24 15:00:20.100 25.623322 25.598949
2023-08-24 15:00:20.200 25.621976 25.602215
先頭データ以外は補間することができました。
1秒単位に切り出し
補間自体は既にできましたが、100ミリ秒単位だとデータが膨大になってしまうため、1秒単位に切り出します。
data_list_re = data_list.resample('1S').first() # resamplingにより1秒単位の先頭を採用
2つのデータのおなじタイミングでの値を得ることができましたね。
Value1 Value2
Timestamp
2023-08-24 15:00:19 25.650000 25.600000
2023-08-24 15:00:20 25.624980 25.596276
2023-08-24 15:00:21 25.615800 25.633970
2023-08-24 15:00:22 25.594596 25.624164
2023-08-24 15:00:23 25.603977 25.604015
2023-08-24 15:00:24 25.638535 25.628176
2023-08-24 15:00:25 25.624601 25.648887
2023-08-24 15:00:26 25.639300 25.646490
2023-08-24 15:00:27 25.636437 25.625883
2023-08-24 15:00:28 25.607431 25.623818

ソースコード
import matplotlib.pyplot as plt
from matplotlib.dates import MicrosecondLocator, SecondLocator
from datetime import datetime
import pandas as pd
data1 = [
[25.65,"2023-08-24 15:00:19.292372"],
[25.62,"2023-08-24 15:00:20.392646"],
[25.61,"2023-08-24 15:00:21.394758"],
[25.59,"2023-08-24 15:00:22.395541"],
[25.62,"2023-08-24 15:00:23.396453"],
[25.64,"2023-08-24 15:00:24.397867"],
[25.62,"2023-08-24 15:00:25.401104"],
[25.65,"2023-08-24 15:00:26.400618"],
[25.62,"2023-08-24 15:00:27.401027"],
[25.61,"2023-08-24 15:00:28.402504"],
[25.66,"2023-08-24 15:00:29.435129"],
]
data2 = [
[25.60,"2023-08-24 15:00:19.432731"],
[25.61,"2023-08-24 15:00:20.430275"],
[25.64,"2023-08-24 15:00:21.438256"],
[25.61,"2023-08-24 15:00:22.427294"],
[25.61,"2023-08-24 15:00:23.431058"],
[25.64,"2023-08-24 15:00:24.434484"],
[25.65,"2023-08-24 15:00:25.336280"],
[25.64,"2023-08-24 15:00:26.434633"],
[25.62,"2023-08-24 15:00:27.448013"],
[25.63,"2023-08-24 15:00:28.439745"],
[25.64,"2023-08-24 15:00:29.401826"],
[25.65,"2023-08-24 15:00:30.404341"],
]
df1 = pd.DataFrame(data1, columns=['Value1', 'Timestamp'])
df2 = pd.DataFrame(data2, columns=['Value2', 'Timestamp'])
# Timestamp列をdatetime型に変換
df1['Timestamp'] = pd.to_datetime(df1['Timestamp'])
df2['Timestamp'] = pd.to_datetime(df2['Timestamp'])
df1 = df1[['Timestamp', 'Value1']]# 列の順番を入れ替える
df1['Timestamp'] = df1['Timestamp'].dt.round("0.1S") # 100ミリ秒以下を丸める
df2['Timestamp'] = df2['Timestamp'].dt.round("0.1S") # 100ミリ秒以下を丸める
data_list = pd.merge(df1,df2,on = "Timestamp", how='outer') # 外部結合 該当するTimestampがない場合はNaNで行追加
data_list = data_list[['Timestamp', 'Value1', 'Value2']]# 列の順番を入れ替える
data_list = data_list.sort_values('Timestamp') # 日付順にSort
data_list.set_index("Timestamp", inplace = True) # 補完処理のためにindexにdateを指定
data_list = data_list.resample('0.1S').mean() #100ミリ秒単位にデータを追加
#補間処理を実施し、NaNになっている個所へ値をはめていく
data_list["Value1"].interpolate(method="cubic",inplace = True)
data_list["Value2"].interpolate(method="cubic",inplace = True)
data_list_re = data_list.resample('1S').first() # resamplingにより1秒単位の先頭を採用
fig, ax = plt.subplots(figsize=(10, 6)) # グラフのサイズを調整
# 元データをplot
ax.plot(df1['Timestamp'], df1['Value1'], marker='x', linestyle='', color='b', label='data1')
ax.plot(df2['Timestamp'], df2['Value2'], marker='x', linestyle='', color='g', label='data2')
# 補間したcubic spline曲線
ax.plot(data_list.index, data_list['Value1'], marker='', linestyle='-', color='b')
ax.plot(data_list.index, data_list['Value2'], marker='', linestyle='-', color='g')
# 補間したcubic spline曲線のうち1秒単位の時点
ax.plot(data_list_re.index, data_list_re['Value1'], marker='o', linestyle='', color='b', label='data1-new')
ax.plot(data_list_re.index, data_list_re['Value2'], marker='o', linestyle='', color='g', label='data2-new')
# 秒単位のグリッドを追加
ax.xaxis.set_major_locator(SecondLocator(interval=1)) # 秒単位のメジャーロケータ
ax.xaxis.set_minor_locator(MicrosecondLocator(interval=1000*100)) # 100m秒単位のメジャーロケータ
plt.xlabel('Timestamp')
plt.ylabel('Value')
plt.legend()
plt.xticks(rotation=45) # X軸のラベルを45度回転して表示
plt.grid()
plt.tight_layout() # レイアウト調整
plt.show() # グラフの表示
以上。