Markdown Preview Enhancedを使いこなす
以前書いたCode Runnerを使いこなすがそこそこ需要あったので、お気に入りの拡張機能を深堀する記事第二弾として執筆しました。
Abstract
VScodeの拡張機能は様々なものが日夜開発されています。マークダウンのプレビューをする拡張機能もかなりの数存在していますが、圧倒的(主観)ダウンロード数を誇るのがMarkdown Preview Enhancedです。
解説記事も世の中には多く存在していますが、例えばコードチャンクのオプションやcrossnote(旧mume)のparser.jsの細かなカスタマイズなどに触れている記事はあまり見つけられませんでした。そこで本記事ではMarkdown Preview Enhancedの機能(特にコードチャンク)を紹介しながら、主にそのカスタマイズに言及し、応用編ではマークダウンに挿入してあるPythonを仮想環境で実行させたり、生成されたグラフ画像を自動で保存させたりします。(v0.7以降後者は難しくなりました。)
注意:リンク先はVScode版のgitです。Atom版のgitはhttps://github.com/shd101wyy/markdown-preview-enhancedです。またここで語るのはVScodeの拡張機能としてであるため、atom版での動作は保証しません。(推測ですが、カスタマイズの中心は共通処理の部分mumeなので、流用は可能だと思われます。) Atom版は開発終了しています。
Markdown Preview Enhanced とは
略してMPEとも。
Markdown Preview Enhanced is a SUPER POWERFUL markdown extension for Atom and Visual Studio Code. The goal of this project is to bring you a wonderful markdown writing experience.
公式ドキュメントより
つまり最強に快適で拡張性の高いマークダウンのプレビュー拡張機能です。書かれている通り、Atomにも提供しているようですね。
他にも多数のマークダウンプレビュー拡張機能がありますが、単純にできることの多さ、ひいては拡張性の高さが良いと考えています。例えばマークダウンはHTMLにパースされて表示されているのですが、そのパース前・後に処理を独自に加えることができます。またJupyter Notebookのようにコードチャンク機能があり、ノートブックと同じ感覚で実行できます。他には画像をドラックアンドドロップで読み込んだりするImage Helper機能もあり、様々な便利機能の詰め合わせだと考えれば良いかと思います。
環境
本格的に機能の紹介に入っていく前に環境を明示しておきます。あまり関係ないと思いますが念のため。Pythonはコードチャンクの例などの際に用いています。3系であれば問題なく動くコードで示すつもりです。
- Windows 10
- VScode 1.60.1
- Markdown Preview Enhanced 0.6.0
- v0.7.2以降、parser.jsについてbreaking changeがあるため注意してください。(2023/09/09加筆)
- Python 3.7.9, 3.8.10
- pipenv version 2021.5.29
上記の通りWindowsなのでパス等はC:\hogeで、ショートカットキーはctrlで表記します。Macの方は適宜読み替えてください。
Markdown preview enhancedは、Web対応するためにparser.jsの形式をv0.7以降で変更したようです。
また、mumeという名前はcrossnoteという名前に変更された模様。適宜修正をしていますが、漏れていた場合は読み替えてください。
インストール
普通に拡張機能マーケットからインストールできます。
markdown previewで検索すると1番上に来ました(記事執筆時点)。
基本機能
勿論基本的な機能はプレビューです。
ctrl+K Vあるいは右クリックのコンテキストメニューからOpen preview to sideで隣のパネルにプレビューを表示します。
また応用編以降がメインのため、ここではコードチャンクを主役に据えて紹介をします。その他機能の多くは公式ドキュメント(日本語版)を読んでください。
ダイアグラム
この機能を普段使用していない筆者は、よくわかっていないことが多いので、公式ドキュメント読んでください。
網羅的な記事はVisual Studio Code+Markdownでチャート/グラフ/図を描画するには?がよさそう。
外部 File の Import
@ import "path/to/file" {options}
することで、様々なファイルを貼り付けることができる。超有能機能。

(公式ドキュメントより)
またコードブロックとして表示されるものについては、オプションでline_begin=2等指定することで特定の行以降や特定の行までを表示することが可能になります。
外部 File の Import読みましょう。
コードチャンクと組み合わせるものについては以下でも触れます。
コードチャンク
個人的にMPEが最強たる所以かもしれない機能。
なんとマークダウンに埋め込んだコードブロックを実行します。
速度面ではおそらく最適化はされていないので、流石にJuptyer NoteBookの上位互換とまではいかないかも。とはいえ気軽に言語を問わずコードと実行と数式がすべてかけるのは非常に魅力的ですよね。残念な点は出力されたグラフの画像などを保存できないこと。しかしこれは応用編で解決策を提示します。
コードチャンクはデフォルトでは無効になっています!これはセキュリティ上の問題です。
自己責任において、setting.jsonで"markdown-preview-enhanced.enableScriptExecution": trueにしてください。
おすすめはワークスペースごとの設定にすることです。
コードブロックに言語後にオプションcmdを指定することで、その場で実行することが可能になります。

コードブロックの右上にallと▷ボタンがあります。allはすべてのコードブロックを実行するもので、▷はそのブロックのみ実行します。
デフォルトでは以下のように実行結果がすぐ下に生成されます。

Pythonの場合、もちろんpythonのパスが通っていないと実行されません。他言語でも同様です。
またcmdは任意のコマンドをとることができます。単に{cmd}とした場合は言語名がコマンドとして使われます。そのため言語名と実行コマンドが異なるような言語ではcmdを指定することが必須になります。
例:JavaScriptはnodeで実行する

また、コマンドライン引数を指定することも可能です。

$input_fileはマクロで、実行時に入力ファイル名に置換されます。
※内部的には、コードブロックをファイルにまとめて、それを渡すという形をとっています。そのファイル名のことです。これは一時的なファイルなので処理が終了すると消えます。
また@ importでも対応します。例として適当に作ったhello.pyを同ディレクトリに保存しました。
print("Hello")
そしてマークダウンで@ importすると・・・

もう最強感ありますね。
行を表示したいときも簡単に実現します。適当なファイルtemp.pyを用意しました。
"""
@importされるファイル。
"""
import sys
import platform
def main():
print(sys.version)
print(platform.platform())
if __name__ == '__main__':
main()
そして・・・
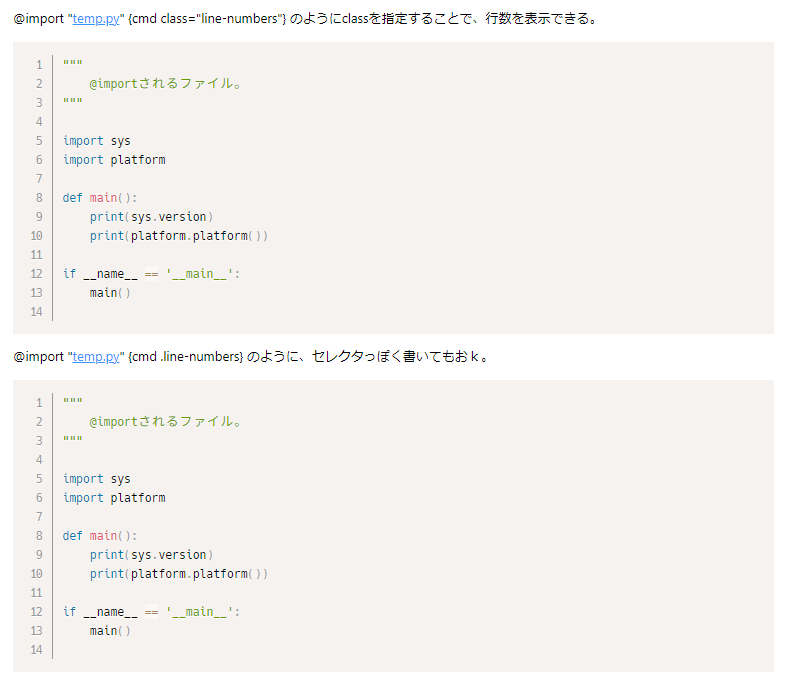
この行数を表示するクラスは他の通常のコードブロックでも通用します。またこのクラスはhtmlにおけるクラスでもあるので、cssで指定することが可能になります。しゅごい・・・
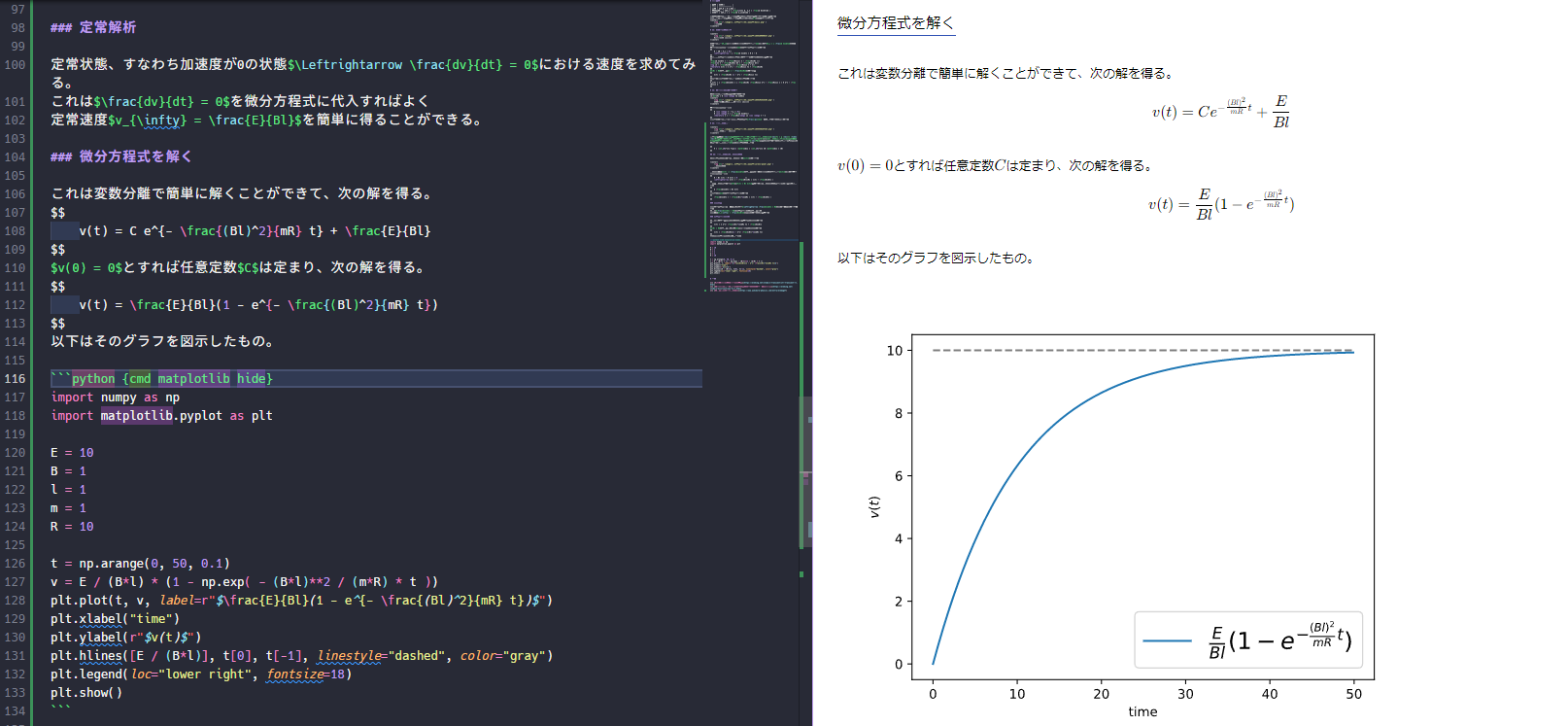
よし、きっとmatplotlibもプレビュー上に!!
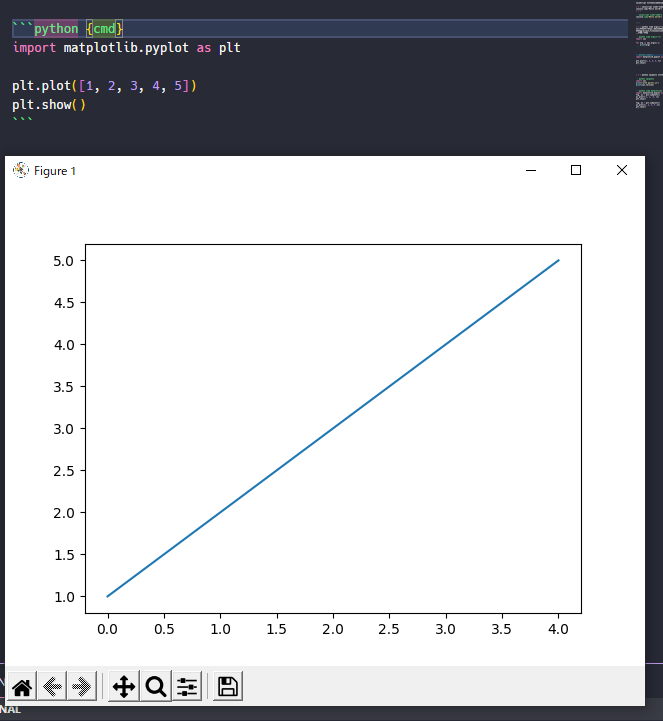
残念でした!別窓です!!!・・・・・これを回避するには、オプションにmatplotlibを指定します。
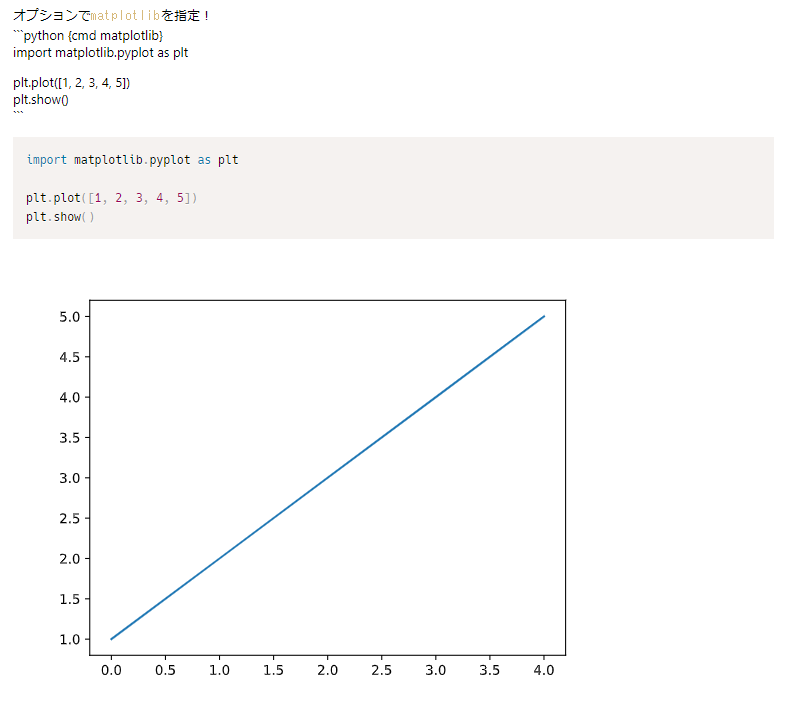
(プレビューのスクリーンショット)
なるほど、これなら問題ない。しかしながら保存ができない・・・出力形式を指定するオプションでoutput="png"とかしても、強制的に埋め込みのsvgになっています。ソースコードを見ると、matplotlibで指定した瞬間に出力はmarkdownになってしまうみたい。この問題の解決のヒントになりそうなことは後半に。
また、hideオプションを使うとコードを隠して実行結果のみ表示できます。
何に使えるのかというと、基本文章はマークダウンで書きたいけど、グラフを追加したいという時です。次の図のように、簡単なグラフの作成であればマークダウン上で編集して実行することができます。やばくね???????
さて、最も基本的な機能を上記では紹介しましたが、もちろん他には多くの機能が搭載されています。
公式ドキュメントのコードチャンクのページを読むのがよいでしょう。本記事はどちらかと言えば拡張編以降に力を入れている記事なのでここで基本的な機能の紹介は終わることにします。めんどくさいわけではないよ。
拡張編
MPEは様々な拡張が可能です。MPE側が想定しているであろう拡張の紹介を行います。
主に~/.mumeのフォルダ、つまりWindowsではC:\Users\takeMe1010\.mume以下のファイルを変更すること可能になります。 (2023/09/09時点で.crossnoteに変更されています。いつからなのかは分かりませんが...)
このフォルダの指定は拡張機能の設定で変更可能で、markdown-preview-enhanced.configPathで指定可能です。
style.less
lessを用いて、表示されるプレビューに装飾を加えることができます。
編集するファイルstyle.lessの場所は ~/.mume~/.crossnoteです。
ちなみにデフォルトだとmarkdown-preview-enhanced.previewThemeで設定されたcssが使われます。setting.jsonから選ぶか、プレビュー画面で右クリックして、Preview Themeから選択することで変更できる。すべて自分で指定したいときは、none.cssを指定しよう。
さて、デフォルトでは以下のようになっています。
/* Please visit the URL below for more information: */
/* https://shd101wyy.github.io/markdown-preview-enhanced/#/customize-css */
.markdown-preview.markdown-preview {
// modify your style here
// eg: background-color: blue;
}
プレビューで主に表示される部分が.markdown-preview.markdown-previewとなっているので、基本的にはこの部分を編集することになります。
以下は自分用のstyle.lessファイルです。参考にしてもらえれば。
私はたまにmarkdown-pdfを使うので、そちらでも使う都合上、bodyに対して同じcssをつけたいという希望から.markdown-preview.markdown-previewの外側にも.main()を展開しています。
ちなみにこの記事のプレビューのスクリーンショットはnone.cssを指定して、以下のstyle.lessを用いています。
// 線などの色
@line-color: #2f51b4;
// 表のヘッダーの色
@table-header-color: rgb(121, 190, 255);
/* 色装飾関係のCSS */
.colors() {
.red {
color: red;
}
.blue {
color: blue;
}
.green {
color: green;
}
.yellow {
color: yellow;
}
}
.hackgen {
font-family: 'HackGen', -apple-system, BlinkMacSystemFont, 'Segoe UI', Roboto, Oxygen, Ubuntu, Cantarell, 'Open Sans', 'Helvetica Neue', sans-serif;
}
.hackgenNerd {
font-family: 'HackGenNerd', -apple-system, BlinkMacSystemFont, 'Segoe UI', Roboto, Oxygen, Ubuntu, Cantarell, 'Open Sans', 'Helvetica Neue', sans-serif;
}
.applyCodeBlockFont(@font: "HackGenNerd") {
pre[data-role=codeBlock] {
font-family: @font, -apple-system, BlinkMacSystemFont, 'Segoe UI', Roboto, Oxygen, Ubuntu, Cantarell, 'Open Sans', 'Helvetica Neue', sans-serif;
}
}
.basic() {
background-color: white;
color : black;
}
/**
* メイン部分
*/
.main() {
body {
.basic();
}
// この辺はmarkdown-pdfのstylesフォルダから抜粋。
h1,
h2,
h3 {
font-weight: normal;
}
h1 {
padding-bottom : 0.3em;
line-height : 1.2;
border-color : black;
border-bottom-width: 1px;
border-bottom-style: solid;
}
h2 {
position : relative;
padding-left : 18px;
padding-bottom: 0.3em;
line-height : 1.2;
&::before {
background: @line-color;
content : "";
height : 20px;
width : 5px;
left : 0px;
position : absolute;
top : 3px;
}
}
h3 {
display : inline-block;
border-bottom: solid 1px @line-color;
}
img {
max-width : 100%;
max-height: 100%;
}
hr {
border : 0;
height : 2px;
border-bottom: 2px solid;
}
.bold {
font-weight: bold;
}
.italic {
font-style: italic;
}
table {
width: 95%;
margin: auto;
border-collapse: collapse;
tr {
th {
background-color: @table-header-color;
}
th, td {
border: solid 1px black;
text-align: center
}
}
}
.applyCodeBlockFont();
.colors;
.right {
text-align: right
}
.center {
text-align: center
}
.left {
text-align: left
}
}
/* bodyとmarkdown-preview.markdown-previewに適用して、previewとpdfのCSSを共通にする */
.main;
.markdown-preview.markdown-preview {
.main;
.basic();
@media print {
p {
font-size: 12px;
}
}
}
表示はこんな感じ。
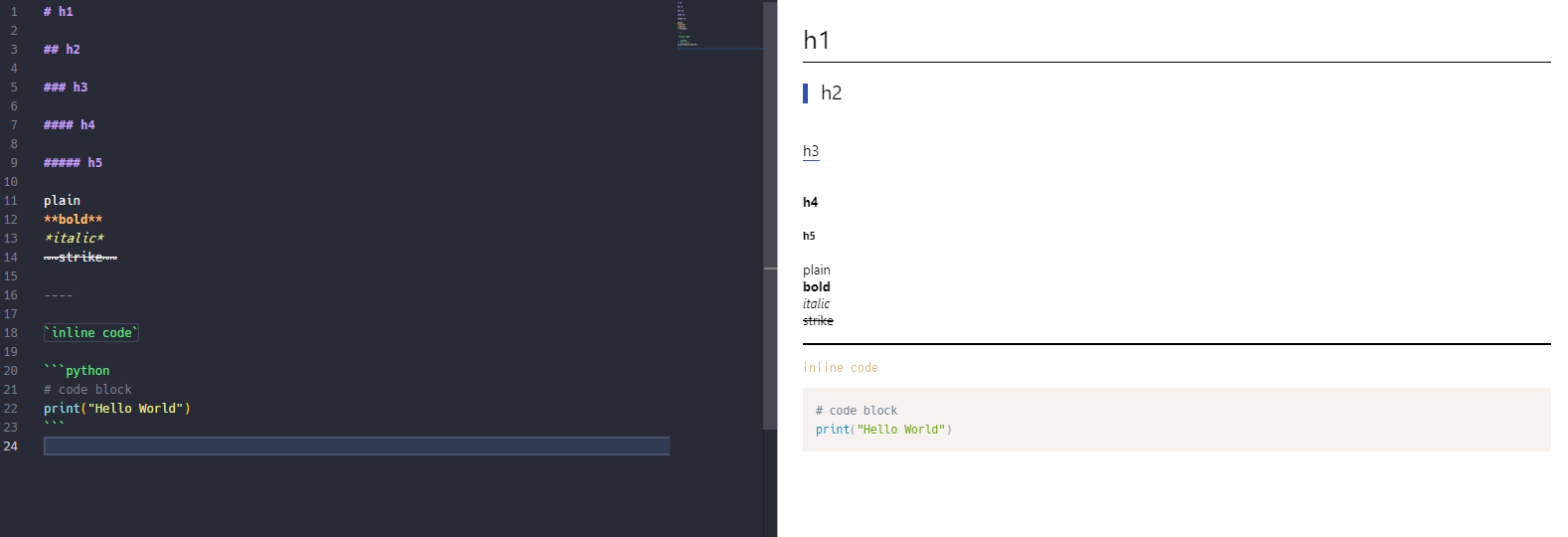
※lessの文法は解説しません。
私はHackGenを愛用しているため、フォントファミリーをそのように設定しています。インストールしていなければ反映されないので注意。
katex_config.js
v0.7.2以降(?)では、katex_config,js及びmathjax_config.js, mermaid_config.jsはconfig.jsに統合されています。
parser.jsと同様、設定を表す単一オブジェクトのみを返す形式のみ有効です。
({
katexConfig: {
"macros": {}
},
mathjaxConfig: {
"tex": {},
"options": {},
"loader": {}
},
mermaidConfig: {
"startOnLoad": false
},
})
オブジェクトのプロパティ等は同じなので、下記で紹介している設定はconfig.jsの対応したセクションに書き加えるようにしてください。
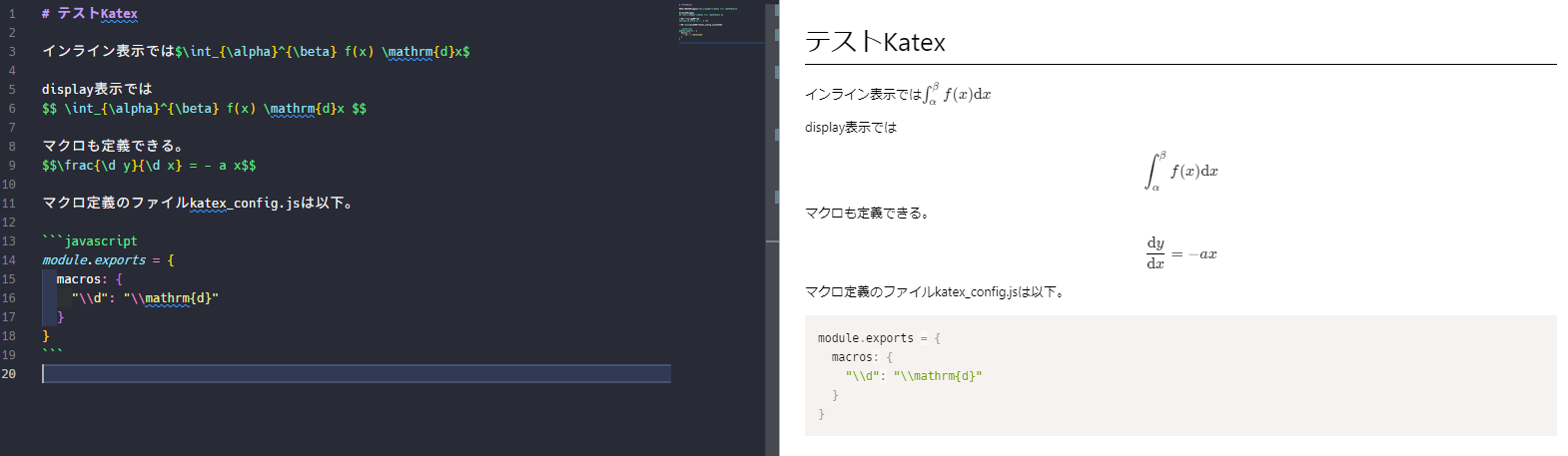
Katexでは、マクロを定義して使うことができます。
ソースコードを見るとマクロ以外にもオプションを指定できそうであるけれどあまり使わなさそうだし割愛。使用できるオプションはおそらく公式ドキュメントにあるもの。
例えば以下のように書きます。\dを\mathrm{d}に置き換えるマクロです。例によって\はエスケープが必要。
module.exports = {
macros: {
"\\d": "\\mathrm{d}"
}
}
← markdown preview →
MathJaxの方(mathjax_config.js)はよくわかりませんでした・・・
mermaid_config.js
mermaid.jsで図を描く時の設定ファイル。
ソースコードを見ると、生成されるhtmlのmermaidを読み込むscriptの冒頭に直接埋め込まれるみたいです。
設定できる値は公式ドキュメントのExample 2の形で使える値かな?
普段mermaidを使用しないので、これ以上は触れないでおきます。自分で使う時が来たら追記するかも。
head.html
(v0.7.10以降)
~/.crossnote/hrad.htmlは、プレビューに表示されるhtmlの<head>タグの末尾に追加される要素を書くことができます。
<!-- The content below will be included at the end of the <head> element. -->
<script type="text/javascript">
document.addEventListener("DOMContentLoaded", () => {
// 典型的にはここにjsを書けばよさげ。
});
</script>
v0.7以降、requireがparser.jsで使えなくなったので、その代替として提供された気がします。
parser.js
同様に ~/.mumeに存在するはず。~/.crossnoteに変更されています(2023/09/09加筆)。
このファイルに追加をすることで機能を勝手に追加したりすることが可能になります。
デフォルト設定は以下。コメントはこちらで加筆したものです。
v0.7.2以前のお話
こちらはv0.7.2以前のみ有効なテンプレートです。
module.exports = {
// 書いているmarkdownの文字列を受け取る。HTMLに変換される前にマークダウン文書に変換をかますことができる。
onWillParseMarkdown: function(markdown) {
return new Promise((resolve, reject)=> {
// ココでmarkdownの文字列を加工する
return resolve(markdown)
})
},
// マークダウンがHTMLに変換された後に、プレビューとして表示するHTMLへ渡される前に変換をかますことができる。
onDidParseMarkdown: function(html, {cheerio}) {
return new Promise((resolve, reject)=> {
// ココでHTMLの文字列を加工する
return resolve(html)
})
},
// ソースコードをみると、以下二つはtransformする前と後に呼ばれるものみたい。軽く見た感じでは上記二つで十分足りそうな感じ。
// pandocで出力する際には、`onWillParseMarkdown`が呼ばれた後に`onWillTransformMarkdown`及び`onDidTransformMarkdown`が呼び出される?(要検証)
onWillTransformMarkdown: function (markdown) {
return new Promise((resolve, reject) => {
return resolve(markdown);
});
},
onDidTransformMarkdown: function (markdown) {
return new Promise((resolve, reject) => {
return resolve(markdown);
});
}
}
公式ドキュメントの例では、全てのheader要素つまり#の前に😀を加える仕様でparser.jsを改変しています。
module.exports = {
onWillParseMarkdown: function(markdown) {
return new Promise((resolve, reject) => {
markdown = markdown.replace(/#+\s+/gm, ($0) => $0 + "😀 ");
return resolve(markdown);
});
},
};
つまり各行に対して、先頭が#或いは##...と#が続く形の時に(正規表現の#+に対応)、その部分を取り出して後ろに顔文字を加えることで、実装していることになります。(replaceについてはJavaScriptのリファレンスのString.prototype.replace()を参照)
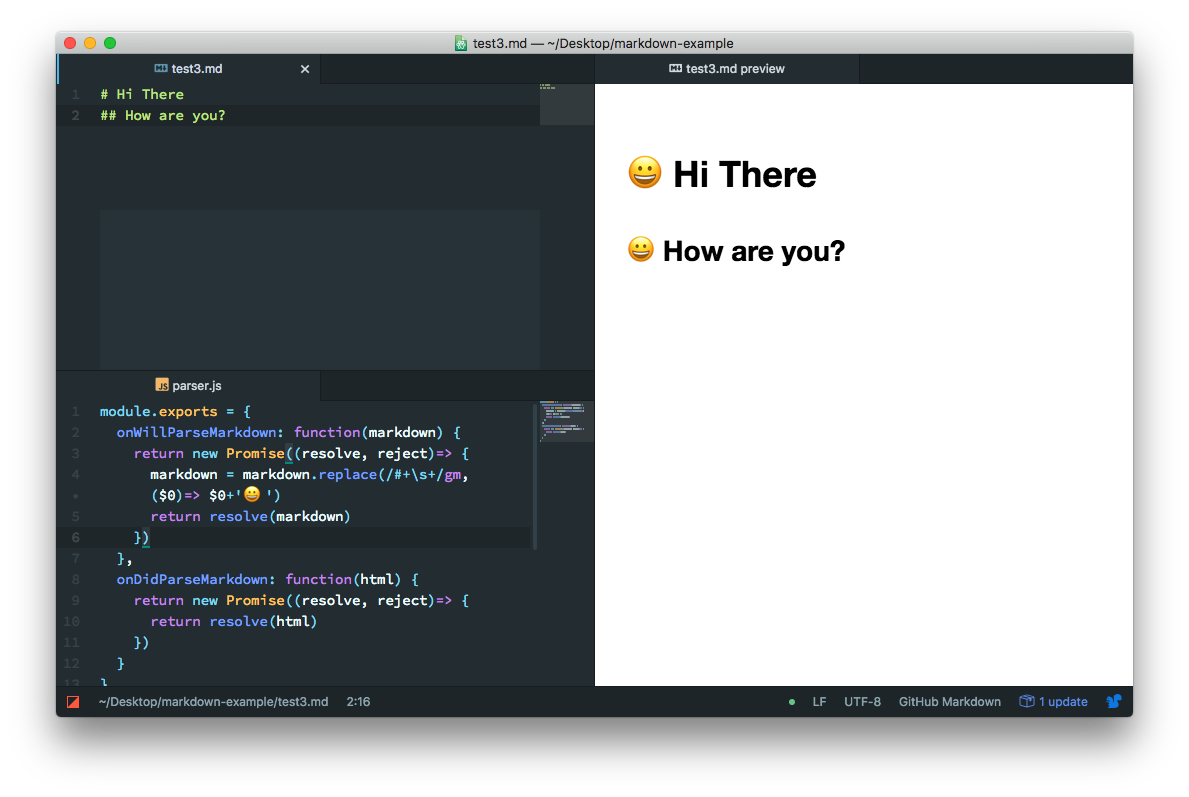
(公式より)
v0.9.4以降、onWillTransformMarkdown, onDidTransformMarkdownが削除されました。
({
// 書いているmarkdownの文字列を受け取る。HTMLに変換される前にマークダウン文書に変換をかますことができる。
onWillParseMarkdown: async function(markdown) {
return markdown;
},
// マークダウンがHTMLに変換された後に、プレビューとして表示するHTMLへ渡される前に変換をかますことができる。
onDidParseMarkdown: async function(html) {
return html;
},
// なんか増えてた。詳細は未調査。
processWikiLink: function({text, link}) {
return {
text,
link: link ? link : text.endsWith('.md') ? text : `\${text}.md`,
};
}
})
このように、parser.jsは単一のオブジェクトを返す形で書く必要がありそうです。
どうやら、vmというnodeのモジュールでサンドボックス環境を作成して、その環境でparser.jsを実行しているようです。
この変更によって、require()がparser.js内で使用できなくなりました (致命傷)。
下記で紹介している、npm moduleを利用して色々するのはv0.7.2以前でのみ使用できますので注意してください。
参考:
https://github.com/shd101wyy/crossnote/blob/master/src/notebook/config-helper.ts#L150
https://github.com/shd101wyy/crossnote/blob/master/src/utility.ts#L298
例えば、公式ドキュメントでは次のような例を紹介しています。
({
onWillParseMarkdown: async function(markdown) {
return markdown.replace(/#+\s+/gm, ($0) => $0 + "😀 ");
},
onDidParseMarkdown: async function(html) {
return html;
}
})
全てのheader要素つまり#の前に😀を加える仕様です。
各行に対して、先頭が#或いは##...と#が続く形の時に(正規表現の#+に対応)、その部分を取り出して後ろに顔文字を加えることで、実装していることになります。
(公式より)
このparser.jsには可能性を感じますね!
続く応用編では色々試していきます。
応用編
以下では上記の仕様を利用したり、拡張機能のソースコードを書き換えたりして更に利便性を高めます。
とくに後者は間違えたりすると正常な動作をしなくなったりするので、自己責任で。まぁ失敗したら再インストールすればいいんですけど。
v0.7.2以降は、parser.jsを下記のように書くとよいかもしれません。 (2023/09/09加筆)
((() => {
// 共通処理や関数・変数を定義する
// 続く例だと、ここにmodule.exportの外側を書いていく感じになります。
return {
onWillParseMarkdown: async function (markdown) {
return markdown;
},
onDidParseMarkdown: async function (html) {
return html;
},
// deprecated. See https://github.com/shd101wyy/vscode-markdown-preview-enhanced/releases/tag/0.8.1
// 代わりのオプションが生えているみたいですが、一旦解説を保留します。(更新が激しいため。)
processWikiLink: function ({ text, link }) {
return {
text,
link: link ? link : text.endsWith('.md') ? text : `${text}.md`,
};
}
}
})());
@import みたいなのを自作する
割と何でもできるので、画像を横並びにするコマンドを自作してみます。
こんな感じで、画像のパスとタイトルを key: value にした引数から、横並びの画像を生成してくれるものを作ってみました。
@stack-import { "hoge.png": "title 1", "fuga": "title 2" }
preview:

画像は https://www.irasutoya.com/2026/04/blog-post_28.html より。
実装は、とりあえず素直に @stack-import から始まる行を特定して、その行の内容を HTML / CSS で書き直して展開して上書きするということをしました。
(() => {
return {
/**
* @param {string} markdown
* @returns {string}
*/
onWillParseMarkdown: async function (markdown) {
const lines = markdown.split("\n");
for (let i = 0; i < lines.length; i++) {
const line = lines[i];
if (line.startsWith("@stack-import")) {
const rawArgs = line
.substring(13) // length of `@stack-import`
.trim()
.replaceAll("\\", "\\\\"); // for json parse
/**@type {Object} */
const args = JSON.parse(rawArgs);
const images = Object.entries(args).map((value) => {
const [path, title] = value;
return `<div class="v-stack"><img src="${path}" class="contain"><span>${title}</span></div>`
});
lines[i] = `<div class="h-stack">${images.join("")}</div>` // 強引に内容を上書き
}
}
return lines.join("\n");
},
};
})();
class 名などは less ファイル側で定義しました:
.stack {
display: flex;
}
.h-stack {
.stack();
}
.v-stack {
.stack();
flex-direction: column;
align-items: center;
}
img.contain {
object-fit: contain;
}
今回は結構雑にやったのですが、引数の受け取り方などは改善の余地がありそう。
gap とかも受け取れるように改善した版:
(() => {
const stackImport = {
/** @param {string} line */
match: (line) => {
return line.match(/^@stack-import(\s+)(\{[^\}]+\})(\s+)(\{[^\}]+\})?/);
},
/**
* @param {string} line
* @param {RegExpMatchArray} match
*/
transform: (line, match) => {
const rawImagesArgs = match[2].trim().replaceAll("\\", "\\\\"); // for json parse
/**@type {Object} */
const images = JSON.parse(rawImagesArgs);
/**@type {Object} */
const configs = match[4] ? JSON.parse(match[4]) : {};
const gap = configs.gap ?? "0rem";
const imgHtmls = Object.entries(images).map((value) => {
const [path, title] = value;
return `<div class="v-stack"><img src="${path}" class="contain"><span>${title}</span></div>`;
});
return `<div class="h-stack" style="gap: ${gap}">${imgHtmls.join("")}</div>`;
},
};
return {
/**
* @param {string} markdown
* @returns {string}
*/
onWillParseMarkdown: async function (markdown) {
const lines = markdown.split("\n");
return lines
.map((line) => {
const stackImportMatch = stackImport.match(line);
if (stackImportMatch) {
try {
return stackImport.transform(line, stackImportMatch);
} catch (e) {
return `[ERROR] ${e}`;
}
}
return line;
})
.join("\n");
}
};
})();
こんな感じで指定できます。
@stack-import { "hoge.png": "title 1", "fuga": "title 2" } {"gap": "0.5rem"}
Pipenvと組み合わせる
私は仮想環境にPipenvを現在愛用しています。
解説記事はこちらがおススメ→Pipenvを使ったPython開発まとめ
今回仮想環境は3.8の環境でやってみます。
C:\hoge>pipenv --python 3.8
// グラフの動作確認に使用するので
C:\hoge>pipenv install matplotlib
仮想環境を作ったのち、適当に同ディレクトリに以下のようなtest_pipenv.mdを作成します。
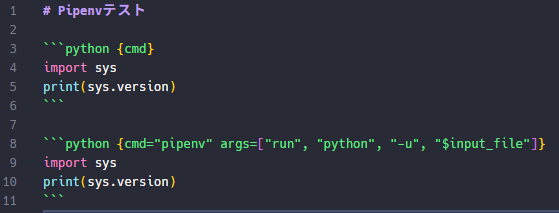
Pipenvでは仮想環境で走らせるときにはpipenv run python -u hoge.pyとするからですね。
ctrl+shift+Enterで全コードを実行すると
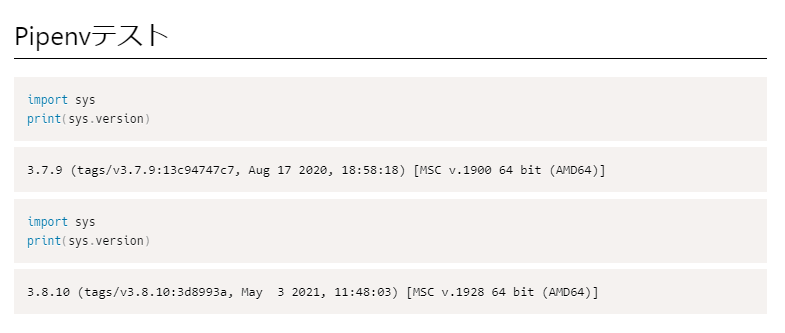
私はグローバルではpython 3.7なので、一つ目は3.7と出ています。二つ目は今回作成した仮想環境になっています!
とはいえ、毎回argsを指定するのも骨が折れます。
parser.jsに、前処理をさせて変換させましょう。
((() => {
/**
* コードチャンクの{pipenv}を実行用のpipenv run python -u $input_file に変換して返す
* @param {string} markdown
* @returns {string}
*/
function convertPipenv(markdown) {
const lines = markdown.split("\n");
for (let i = 0; i < lines.length; i++) {
lines[i] = lines[i].replace(
/```python\s+{pipenv([\W\w\s]*)}/g,
"```python {cmd=\"pipenv\" args=[\"run\", \"python\", \"-u\", \"\$input_file\"]$1}"
).replace(
/@import\s+("[\W\w]+")\s+{pipenv([\W\w\s]*)}\s*/g,
"@import $1 {cmd=\"pipenv\" args=[\"run\", \"python\", \"-u\", \"\$input_file\"]$2}"
);
}
return lines.join('\n');
}
return {
onWillParseMarkdown: async function (markdown) {
markdown = convertPipenv(markdown);
return markdown;
},
// 省略...
};
})());
v0.7以前
/**
* コードチャンクの{pipenv}を実行用のpipenv run python -u $input_file に変換して返す
* @param {string} markdown
* @returns {string}
*/
function convertPipenv(markdown) {
const lines = markdown.split("\n");
for (let i = 0; i < lines.length; i++) {
lines[i] = lines[i].replace(
/```python\s+{pipenv([\W\w\s]*)}/g,
"```python {cmd=\"pipenv\" args=[\"run\", \"python\", \"-u\", \"\$input_file\"]$1}"
).replace(
/@import\s+("[\W\w]+")\s+{pipenv([\W\w\s]*)}\s*/g,
"@import $1 {cmd=\"pipenv\" args=[\"run\", \"python\", \"-u\", \"\$input_file\"]$2}"
);
}
return lines.join("\n");
}
module.exports = {
/**
* markdown-itに放り込まれる前の文字列を扱う部分
* @param {string} markdown マークダウンの文字列
* @returns resolve(マークダウンの文字列)
*/
onWillParseMarkdown: function(markdown) {
return new Promise((resolve, reject) => {
// この段階ではマークダウンの文字列。この返却値をmarkdown-itに放り込む。
markdown = convertPipenv(markdown);
return resolve(markdown);
});
}
}
(なお上記の実装は1行ずつ見ていく仕様になっています。正直大きなマークダウンファイルでは遅いと思われるので、何らかの改良が必須…)
これにより、オプションの先頭にpipenvとつけるだけで、pipenvで実行するコードチャンクができるようになりました!
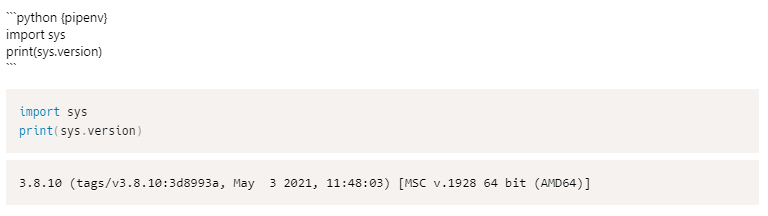
ちなみに@ importでも動作します。偉い。めでたしめでたし、と思っていたらmatplotlibがプレビューにうまく出力されない・・・ v0.9.2 (release, issue) 以降、matplotlibオプションをつけるだけで良くなりました。
v0.9.2以前
どうやら原因は~/.vscode/extensions/shd101wyy.markdown-preview-enhanced-0.6.0\\node_modules\\@shd101wyy\\mume\\out\\src\\code-chunk.jsみたい。
この81行目を変更しました。
// 81行目 before
if (cmd.match(/python/) &&
(normalizedAttributes["matplotlib"] || normalizedAttributes["mpl"])) {
// 色々
}
// after
if ((cmd.match(/python/) || cmd.match(/pipenv/)) &&
(normalizedAttributes["matplotlib"] || normalizedAttributes["mpl"])) {
// 色々
}
同様に~/.vscode/extensions/shd101wyy.markdown-preview-enhanced-0.6.0\\node_modules\\@shd101wyy\\mume\\out\\src\\render-enhancers\fenced-code-chunks.jsの169行目も変更します。この変更は次のセクションの話の自動で保存のために必要みたいです。※ここも変更したらうまくいったレベルです。このソースがどこから呼ばれるのかすらわからなかったので・・・
//before
else if (cmd.match(/python/) &&
(normalizedAttributes["matplotlib"] || normalizedAttributes["mpl"])) {
outputFormat = "markdown";
}
// after
else if ((cmd.match(/python/) || cmd.match(/pipenv/)) &&
(normalizedAttributes["matplotlib"] || normalizedAttributes["mpl"])) {
outputFormat = "markdown";
}
これによってコマンドがpipenvでもオプション{matplotlib}が有効になり、グラフがプレビューに出力されるようになりました。めでたしめでたし。
matplotlibで出力したグラフを自動で保存する
Q. そもそも拡張機能はどうやってグラフをマークダウンに取り込んでるのだろうか?
A. plt.showを書き換えて、出力先を標準出力にsvgで書き出すようにして取得している。
その処理の部分は~\.vscode\extensions\shd101wyy.markdown-preview-enhanced-0.6.0\node_modules\@shd101wyy\mume\out\src\code-chunk.jsに記述されています(92行目以降から抜粋)。
def new_plt_show():
plt.savefig(sys.stdout, format="svg")
plt.show = new_plt_show
これをプログラムの実行時に、先に実行することでplt.showを上書きしているみたい。(v0.7以降、minifiedされたのでjsのコードは確認できませんが、恐らく変更されていません。)
出力されたsvgがどこに出力されているか??
実はpreviewのhtmlにはsvgが含まれています。確認は簡単です。
- 適当にmatplotlibのグラフを描画して表示させたhtmlをブラウザで開き(プレビューで右クリック:Opne in browser)、デベロッパーツール(Chromeだとctrl+shift+I)で見る
- コマンドパレットから
Developer: Open Webview Developer Toolを実行
この方法で表示されているプレビューのhtmlを見ることができるので、覚えておくとよいでしょう。
ちなみに出力されているHTMLは以下のようになっています。
例えば以下のようなマークダウンを書いたときは
概ね以下のようになっています。(...は省略の意味)
<html>
<head>
...
</head>
<body>
<div class="mume markdown-preview">
<h1 class="mume-header" id="matplotlib%E3%81%AE%E3%83%86%E3%82%B9%E3%83%88">matplotlibのテスト</h1>
<div class="code-chunk" data-id="cube" data-cmd="python">
<div class="input-div">
<pre data-role="codeBlock" data-info="python {code_chunk_offset=0, cmd matplotlib id="cube"}" class="language-python">...</pre>
</div>
<div class="output-div">
<svg ...>
...
</svg>
</div>
</div><!--div.code-chunk-->
</div>
</body>
</html>
したがって、目的のsvgは<div class="output-div">の子孫に存在していることがわかりますね。またオプションで指定したidは<div class="code-chunk">のデータ属性が保持していることが確認できます。またその他code-chunkのオプションは<div class="input-div">の子孫の<pre>のデータ属性が保持していることも確認できます。
ただし、v0.7以降、parser.jsではrequireが使えないため、下記の折り畳みの内容は使えません。
v0.7以前
// もしnpm initをしていないならしてから。
C:\Users\takeMe\.mume>npm install cheerio
parser.jsを以下のようにしてみます。
const path = require("path");
const fs = require("fs");
const cheerio = require("cheerio");
/**
* 出力されたSVGを全て保存する。
* @param {cheerio.CheerioAPI} $
* @param {string} saveDir 保存フォルダ
*/
function saveAllSvg($, saveDir) {
$(".output-div").children("svg").each((i, elem) => {
const svg_str = $.html(elem);
/**@type {string} */
const code_chunk_id = $(elem.parent.parent).data("id");
let stem;
// デフォルトの名前の時
if (code_chunk_id.match(/code-chunk-id-\d+/)) {
stem = code_chunk_id + "-" + i.toString();
} else {
stem = code_chunk_id;
}
const filepath = path.resolve(saveDir, stem + ".svg");
fs.writeFileSync(filepath, svg_str);
});
}
module.exports = {
/**
* HTMLに変換された後の文字列を扱う部分。
* @param {string} html HTMLの文字列
* @param {string} projectDir プロジェクトのルートフォルダ
* @returns resolve(HTMLの文字列)
*/
onDidParseMarkdown: function(html, projectDir) {
// ここはHTMLの文字列。
return new Promise((resolve, reject) => {
const $ = cheerio.load(html);
// projectディレクトリのcode-outputというフォルダに保存するという意味。tempフォルダにしたかったらここを変更。
const saveDir = path.join(projectDir, "code-output");
saveAllSvg($, saveDir);
return resolve(html);
});
}
}
! 本来projectDirという引数は存在しません。なので拡張機能のソースコードをいじって情報を持ってきます(力技)。…プルリクとかしたら喜ばれるのかな?
このparser.jsを呼び出している部分はmumeのmarkdown-engine.jsです。よって~\.vscode\extensions\shd101wyy.markdown-preview-enhanced-0.6.0\node_modules\@shd101wyy\mume\out\src\markdown-engine.js の2053行目を変更します。markdown-engine.jsを頑張って開いてcrlt+Gで2053行目にジャンプするのがよいかと。
// before
html = yield utility.configs.parserConfig["onDidParseMarkdown"](html, {
cheerio,
});
// after
html = yield utility.configs.parserConfig["onDidParseMarkdown"](html, this.projectDirectoryPath, {
cheerio,
});
これで実行結果にsvgがあれば、そのコードチャンクのidを名前にして保存することができます。ただし上記の仕様だと、二個以上のグラフで上書きが発生することがあることに気が付きました。これは直したいですね。。。
現状svgになっていますが、png形式に変更するコードをnpm installしてなんとかすれば変換は容易なはず。
またhtmlにはコードチャンクのオプション等が保持されているので、色々頑張れば独自のオプションを設定して、保存ディレクトリをコード側で指定するみたいなこともできそうです。
そこで、v0.8以降の 解決策として、head.htmlを利用した、クリップボードにコピーする方法を提案します。
head.htmlを下記の内容にしてみます。
<!-- The content below will be included at the end of the <head> element. -->
<script type="text/javascript">
function createSaveButton(title = 'Save') {
const saveButton = document.createElement("input");
saveButton.type = 'button';
saveButton.value = title;
return saveButton;
}
/**
* @param {HTMLElement} svg
* ref: https://eniel.blog.fc2.com/blog-entry-611.html
*/
function createSvgCanvas(svg) {
const svgData = new XMLSerializer().serializeToString(svg);
const canvas = document.createElement('canvas');
canvas.width = svg.width.baseVal.value;
canvas.height = svg.height.baseVal.value;
const ctx = canvas.getContext('2d');
const image = new Image;
image.onload = function () {
ctx.drawImage(image, 0, 0);
}
image.src = "data:image/svg+xml;charset=utf-8;base64," + btoa(unescape(encodeURIComponent(svgData)));
return canvas
}
class Watcher {
constructor() {
}
update() {
const divs = document.getElementsByClassName("output-div");
for (const div of divs) {
// `div.output-div`は`matplotlib`オプションを指定していると`svg`タグが子孫として追加される。
const svg = div.getElementsByTagName('svg')[0];
if (svg == null) { continue; }
const canvas = createSvgCanvas(svg);
const saveButton = createSaveButton();
saveButton.onclick = () => {
canvas.toBlob(blob => navigator.clipboard.write([new ClipboardItem({ 'image/png': blob })]));
const prevValue = saveButton.value;
saveButton.value = 'Copied!';
setTimeout(() => {
saveButton.value = prevValue;
}, 5000);
}
// 前の更新で追加したボタンを削除する
if (div.childElementCount > 1) {
div.children[1].remove();
}
div.appendChild(saveButton);
}
}
}
function main() {
const watcher = new Watcher();
setInterval(() => {
watcher.update();
}, 5000);
}
function executeMainWithDelay() {
// NOTE: 遅延して実行させないと、DOM取得が正常にできないっぽい。
setTimeout(() => {
main();
}, 1000);
}
// ref: https://stackoverflow.com/questions/39993676/code-inside-domcontentloaded-event-not-working
if (document.readyState !== 'loading') {
executeMainWithDelay();
} else {
document.addEventListener("DOMContentLoaded", executeMainWithDelay);
}
</script>
matplotlibの画像を出力したのちに、それを発見するとクリップボードにコピーするボタンをはやします。
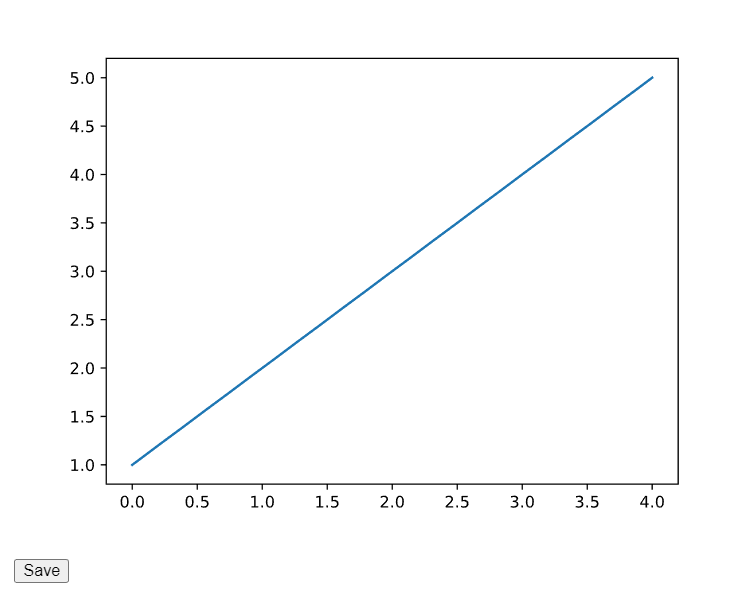
なお、このボタンはpdf出力したものには表れません。
ポイントは特に次の2点です。
- webview本体がReactで作成されているようなので、
DOMContentLoadedがheadに書いても動作しないことがあった - なぜか遅延して実行しないとDOMのlnegthが0になるので、1000ms程度適当に遅延して実行する
svgをクリップボードにコピーする処理はこちらのブログを参考にしました。
v0.9.4にて、beta機能としてpng画像をクリップボードにコピーする機能が追加されました。
Supported to export the selected element in preview to .png file and copy the blob to the clipboard
将来的には、ここで述べたような努力は必要なくなるかもしれませんね。
トラブルシューティング
自分が直面したトラブルについてメモしておく場所でもあります。
parser.jsやkatex_config.jsなどが無視される, 動作しない
v0.7.2以降、parser.jsの形式が制限され、破壊的変更が行われました。
また、katex_config.jsなどはconfig.jsに統合されました。
拡張機能がv0.7.1以前で、parser.jsなどをカスタマイズしていた場合は、下記のいずれかの対応が必要です。
- v0.7.1にバージョンを落として、そのバージョンで固定する
-
応用編などで述べたように、
parser.jsなどの構成を書き換える
chromeでPDF出力を選ぶと数式がレンダリングされない問題
レンダリングを行う部分の処理が、エクスポートを行う処理よりも遅いことで引き起こされる問題っぽい。
issueだと#638, #375がこの問題に対応しているっぽい。
対処はsettings.jsonで下記の設定を追加することになります。
{
...
"markdown-preview-enhanced.puppeteerWaitForTimeout": 3000, // 最大3000msまでレンダリングの処理を待つ
...
}
まとめ
本記事ではコードチャンクを中心に、parser.jsのカスタマイズについて紹介してきました。
Markdown-Preview-Enhancedは他にも素晴らしい機能を数多く搭載しているため、ぜひ公式ドキュメント(日本語版)を読んでみてください。
きっとあなたがしたいと思ったことは既に存在しているか、あるいはカスタマイズ可能なことでしょう。
皆様の快適なMPE生活の参考になれば幸いです。
take_me
Log
- 2021/09/21 投稿
- 同日 pipenvだと画像が自動保存できない問題を解決(?)
- (2022/12/01) トラブルシューティングを追加. 数式のレンダリングができないissueに言及
- (2023/09/09) v0.7.2以降のparser.js周りの変更を反映。
- (2023/10/15) 応用編をparser.jsの形式変更に対応した状態に更新完了
- (2026/04/29)
@stack-importを定義する例の追加