はじめに
今後はストリーム処理の時代がくるはずです。たぶん。そんな気がします。
というわけで、適当なデータ発生を発生させて、Kinesis Streams+Spark streamingでストリーム処理を体験してみました。
Spark 2.0.0 (EMRを利用)
Kinesis Streamsとは
昔は単にKinesisと呼ばれていましたが、後からKinesis FirehoseとKinesis Analyticsが追加されたため、Kinesis3兄弟のうちの1人と呼ばれています。
大規模でスケール可能で、メッセージが一定時間保存されるPubSub型キューのことを指します。
つまり、データを発生させるProducer相当と、後段の処理であるConsumer相当を作成する必要があります。
Spark Streamingとは
大規模データ分散処理フレームワークのApache sparkのライブラリの一つで、少しのコード変更でストリーミング処理が記述できます。
今回Spark環境はAmazon EMR(マネージドHadoop、Hadoopエコシステムも使える)で用意します。
https://aws.amazon.com/jp/emr/
準備
Kinesis streamsの準備
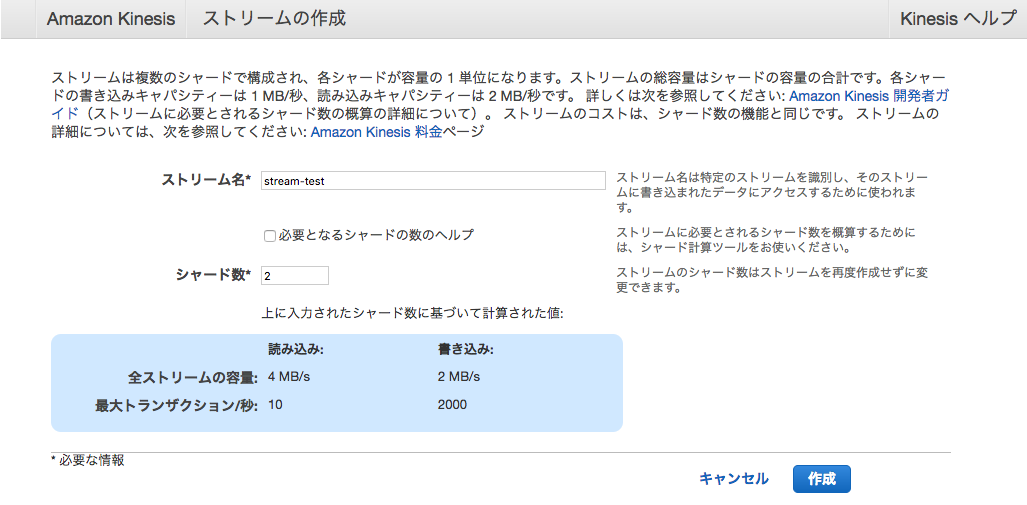
AWSコンソールからKinesis streamsのページに行きます。
- ストリーム名
- シャード数
を決めるだけです。スループット要件等に応じて決定してください。ここでは適当に2にします。
EMRの準備
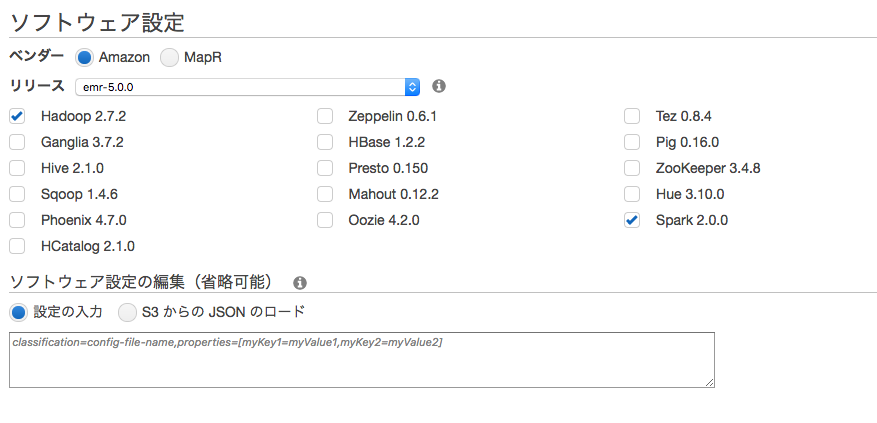
AWSコンソールからEMRのページに行きます。
サブネットを指定する場合はクラスター作成から詳細オプションに移動します。
Sparkに必ずチェックをつけてください。
あとはデフォルトで問題ありませんが、マスターのセキュリティグループはデフォルトではSSHポートが空いていないので他のセキュリティグループをつける必要があります。
EC2
データの作成用にEC2も1台準備しておきます。botoが使えればなんでもよいです。
データ作成(producer)
データを発生させるスクリプトです。色々な言語で記述できるのですが、ここではPythonを使います。
# !/usr/bin/python
# -*- coding: utf-8 -*-
import boto.kinesis,datetime,time,random
connection = boto.kinesis.connect_to_region('ap-northeast-1')
stream_name = 'stream-test'
partition_key = str(time.time()) + str(random.random())
source_str = 'abcdefghijklmnopqrstuvwxyz'
for loop in range(10):
for i in range(10):
sampledata=str(i)+","+random.choice(source_str)
put_data = connection.put_record(stream_name,sampledata,partition_key)
time.sleep(10)
やっていることとしては、
- Kinesis接続の準備
- 数値およびアルファベットのランダム文字列を10回発生させる
- Kinesis streamsにPutする
- 10秒間隔で2-4を10回やる
です。
partition_keyで設定した値をハッシュ化したものをもちいてシャードの振り分けが行われるみたいです。
なのである程度ランダムになるようにしています。
データ処理(Consumer)
Kinesis streamsからデータを取得し、何らかの処理をするスクリプトです。
from __future__ import print_function
import sys
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
from pyspark.streaming.kinesis import KinesisUtils, InitialPositionInStream
if __name__ == "__main__":
sc = SparkContext()
ssc = StreamingContext(sc, 5)
appName="stream-app"
streamName="stream-test"
endpointUrl="https://kinesis.ap-northeast-1.amazonaws.com"
regionName="ap-northeast-1"
lines = KinesisUtils.createStream(
ssc, appName, streamName, endpointUrl, regionName, InitialPositionInStream.LATEST, 1)
lines.pprint()
ssc.start()
ssc.awaitTermination()
Sparkの中にKinesis stramsを利用するためのモジュールが用意されているのでそれを使います。
まずSparkを利用するための入り口ともいえるSparkContextとStreamingでつかうためのStreamingContextを用意します。
StreamingContextはWindows単位で処理をするので、ここでは5秒おきとしています。
sc = SparkContext()
ssc = StreamingContext(sc, 5)
Streamsを作ります。appnameはなんでもよいのでstream-appとしています。
appName="stream-app"
streamName="stream-test"
endpointUrl="https://kinesis.ap-northeast-1.amazonaws.com"
regionName="ap-northeast-1"
lines = KinesisUtils.createStream(
ssc, appName, streamName, endpointUrl, regionName, InitialPositionInStream.LATEST, 1)
表示します。
lines.pprint()
Stream処理を起動します。
ssc.start()
ssc.awaitTermination()
実行
EMRでSparkのジョブを実行します。この時JARファイルを指定します。
spark-submit --jars /usr/lib/spark/external/lib/spark-streaming-kinesis-asl-assembly_*.jar ./get.py
EC2でデータを発生させます。
python put.py
少し待つとConsumer側で表示されます。
-------------------------------------------
Time: 2016-11-03 01:38:00
-------------------------------------------
0,c
1,e
2,x
3,w
4,g
5,h
6,t
7,q
8,c
9,o
行数をカウントしたい場合は例えば以下のようにします。
counts=lines.count()
counts.pprint()
これでストリーム処理を実装する際のイメージがつかめたかな、と思います。
性能等については何も考えていないので、要検討です。