株式会社ブレインパッドプロダクトユニットでRtoaster GenAIの開発をしている依田です。
今回はプログラムの性能を予測する際によく使われる計算量オーダーとビッグ・オー記法について記します。
はじめに
『リーダブルコード』という、たいへん素晴らしい書籍があります。私はこの書籍を新人・若手エンジニアへ積極的に勧めているのですが、この本を読み進めると205ページに突然以下の記述が現れます。
処理時間は$O(n)$である
この謎のおまじないが、特に説明もなく現れるのはけしからんと思った次第なので、果たしてこの記法が何なのかを解説します。
「謎のおまじない」の名前
謎のおまじない $O(n)$ は、ビッグ・オー記法と呼ばれるものです。「ビッグオー記法」、「O記法」と書くこともありますが、この記事では一律「ビッグ・オー記法」と表現します。プログラミングの世界では、処理時間やメモリ使用量を表現するために広く使われています。
しかし、多くの技術書や記事では、「読者は当然知っているもの」として説明なしに使われることが多く、初学者にとっては大きな壁となっています。特に、指数や対数といった数学的な知識を前提とした解説が多く、初学者にとっては理解のハードルが高いものでした。
この記事の目的
この記事では、数学の深い知識がなくても、プログラミング初心者でも、ビッグ・オー記法と計算量オーダーを直感的に理解できることを目指します。数学的な用語、専門的な用語は可能な限り避けて、より平易な表現で説明します。専門用語も併せて学びたい方は脚注に記載しますので、そちらもぜひご覧ください。
対象読者は以下の方々です。
- プログラミング初学者
- 技術書で突然出てきたビッグ・オー記法に戸惑った方
- アルゴリズムの効率性を理解したい方
本記事を読むことで、以下のことが身につきます。
- ビッグ・オー記法が何を表しているのか理解できる
- グラフを見て、どの計算量オーダーが効率的かを判断できる
- 技術書で計算量オーダーの話題が出てきてもなんとなく理解できるようになる
読み進めるために覚えておくおまじない
この記事を読み進めるにあたって、以下のおまじないが登場します。意味の理解は不要です。字面と読み方だけ覚えておきましょう。
- 指数(しすう)
- 対数(たいすう)
- $log$(ろぐ)
- 階乗(かいじょう)
それでは、計算量オーダーとビッグ・オー記法の世界へ一緒に踏み出しましょう。
本記事は初学者向けのため一部表現を平易にしています。数学的な厳密性を省略していたり、アルゴリズム解析の厳密な定義とは異なる部分があります。
計算量オーダーの基本的な考え方
計算量オーダーとは、プログラムがデータを処理するのに必要な「手間」や「時間」の増加の度合いを表す指標です。
単に処理時間の具体的な値(例:0.5秒)ではなく、「データ量が増えたとき、処理時間がどのように増えるか」という増加の割合・増加する傾向に注目します。
例えば、10件のデータを処理するプログラムがあったとします。このプログラムは、100件、1,000件とデータが増えたとき、処理時間がどのように変化するでしょうか。
- データ量が10倍になったら処理時間も10倍
- それとも100倍
- あるいはほとんど変わらない
この「データ量が増えたとき、処理時間がどう変化するか」を表現するのが計算量オーダーです。
そして、計算量オーダーを表すときにビッグ・オー記法が広く使われています。以後の説明で詳しく触れますが、一例として以下のような表現が用いられます。
- $O(n)$
- $O(log\ n)$
- $O(n^2)$
これらはいずれも「データ量 $n$ が増えたとき、処理時間の増加の度合い」を表しています。
ビッグ・オー記法の $n$ は「入力サイズ」を表します。具体的には配列の要素数や文字列の長さ、グラフの頂点数または辺数などが該当します。
例えば、100件のデータを処理する場合、$n = 100$ となります。
では、なぜビッグ・オー記法を使うのでしょうか。それは、プログラムの実行速度は環境によって変わるからです。具体的には、プログラムを実行するコンピュータの性能が良ければ、その分早く処理は終わりますし、全く同じロジックの実装でもプログラミング言語によって性能の差が出てきます。これらの要因を全て考慮すると、正確な処理時間を予測するのは困難です。しかし、ビッグ・オー記法を使えば、環境に依存しない、アルゴリズムの本質的な効率性を表現できます。
ビッグ・オー記法は「最悪ケース」を表す
ビッグ・オー記法について、重要なポイントがあります。それは、ビッグ・オー記法は「最悪の場合」の計算量1を表しているということです。
例えば、$n$ 件のリストから特定の値を先頭から順番に探していく方法2を考えてみましょう。
def find_value(arr, target):
for i, value in enumerate(arr):
if value == target:
return i
return -1
このアルゴリズムの処理時間は、以下のように変わります。
- 最良の場合:探している値が最初にある → $1$ 回の比較で終了
- 平均的な場合:探している値が中間にある → $\frac{n}{2}$ 回の比較
- 最悪の場合:探している値が最後、または存在しない → $n$ 回の比較
ビッグ・オー記法では、最悪の場合を想定して $n$ 回比較することを明言する手法で、それを $O(n)$ と表現します。これは、「どんなに運が悪くても、この程度の処理時間で済む」という保証を与えてくれます。$O$ は「最悪の場合」であることを示し、カッコの中の $n$ に計算の回数を記述します。
最悪ケースを基準とすることで、システムの安全性を担保できます。「最良の場合は速い」と期待するよりも、「最悪でもこの程度」と分かっている方が、信頼性の高いシステム設計ができます。
ビッグ・オー記法と似た、親戚のような表現もあります。一例としては以下の通りです。
- ビッグ・シータ記法(Θ記法):「だいたいこの範囲」に収まることを表す
- ビッグ・オメガ記法(Ω記法):最良の場合の計算量を表す
ただ、これらはビッグ・オー記法ほど使用頻度は高くありません。
時間計算量オーダーと空間計算量オーダー
計算量オーダーには、大きく分けて「時間計算量オーダー」と「空間計算量オーダー」の2種類あります。
時間計算量オーダーは、処理にかかる時間の増加の度合いを表します。この記事で主に扱うのは時間計算量オーダーです。
時間計算量オーダーにおけるビッグ・オー記法は、以下のように解釈します。
- $O(n)$:データ量 $n$ に比例した時間がかかる
- $O(n^2)$:データ量の二乗に比例した時間がかかる
一方、空間計算量オーダーは使用するメモリ量の増加の度合いを表します。
一般的に「計算量オーダー」や単に「計算量」と言った場合、時間計算量オーダーを指します。空間計算量オーダーを指す場合は明示的に「空間計算量オーダー」と呼びます。
時間計算量オーダーの種類
この章では、代表的な7つの時間計算量オーダーを順番に解説します。それぞれについて、以下の構成で説明します。
- グラフ:データ量と処理時間の関係を視覚化
- 説明:どういう動きをするアルゴリズムか
- コード例:Pythonでの具体例
- ロジック例:どのようなロジックを実装する際に使われるか
グラフは縦軸に計算回数、横軸にデータ量 $n$ を取ります。グラフ毎に、縦軸と横軸の最大値は異なることがある点に留意して下さい。
O(1) - 定数時間
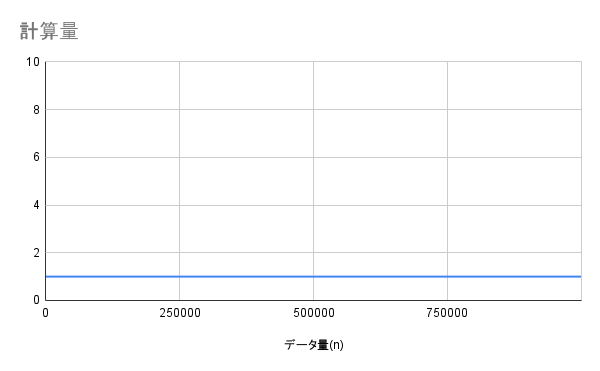
説明
データ量に関係なく、常に一定時間で処理が完了する計算量です。
データが10個でも、1,000個でも、100万個でも、処理時間は変わりません。これは最も理想的な計算量です。
コード例
def get_first_element(arr):
"""リストの最初の要素を取得"""
return arr[0]
# データ量に関係なく、常に1回のアクセスで完了
data = [1, 2, 3, 4, 5]
first = get_first_element(data) # O(1)
配列の特定位置へのアクセスは、データ量に関係なく常に一定時間で完了します。
ロジック例
- キーで高速検索できるデータ構造3でのデータ取得:ユーザーIDをキーにして、ユーザー情報を即座に取得
- データベースの主キー検索:IDを指定して1件のレコードを取得
- 配列の要素アクセス:リストの5番目の要素を取得
O(log n) - 対数時間
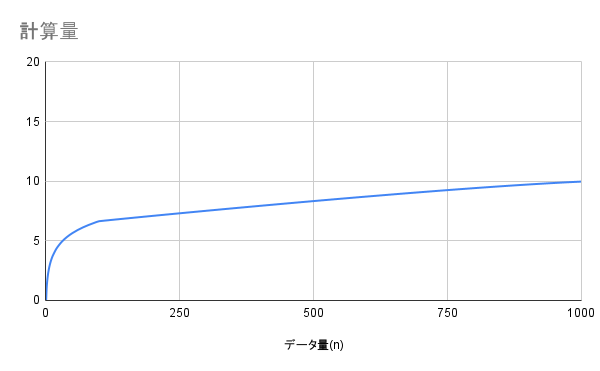
説明
データを半分ずつ絞り込んでいく4アルゴリズムの計算量5です。
「対数」という言葉に身構える必要はありません。イメージとしては、辞書で言葉を探すときの動きです。
例えば、1,000ページの辞書で「プログラム」という言葉を探すとき、以下のように探します。
- 真ん中(500ページ目)を開く → 「た」行だった
- 後半の真ん中(750ページ目)を開く → 「ま」行だった
- その前の真ん中(625ページ目)を開く → 「な」行だった
- 625ページと750ページの間(687ページ目)を開く → 「は」行だった
- ...
このように、毎回範囲を半分に絞り込むことで、1,000ページあっても10回程度で目的の言葉にたどり着けます。
データ量が2倍になっても、処理回数は1回しか増えません。非常に効率的な計算量です。
コード例
def binary_search(sorted_list, target):
"""ソート済みのリストから半分ずつ絞り込んで目的の値を探す"""
left = 0
right = len(sorted_list) - 1
while left <= right:
mid = (left + right) // 2
if sorted_list[mid] == target:
return mid # 見つかった
elif sorted_list[mid] < target:
left = mid + 1 # 後半を探索
else:
right = mid - 1 # 前半を探索
return -1 # 見つからなかった
# 使用例
data = [1, 3, 5, 7, 9, 11, 13, 15, 17, 19]
index = binary_search(data, 13) # O(log n)
ロジック例
- データベースの索引検索:検索用の索引構造を使った高速検索
- 大規模データの検索:ソート済みの100万件のデータから特定レコードを探す
数値例
| データ量 | 最大処理回数 |
|---|---|
| 10 | 4 |
| 100 | 7 |
| 1,000 | 10 |
| 10,000 | 14 |
| 100,000 | 17 |
| 1,000,000 | 20 |
| 1,000,000,000,000 | 40 |
データ量が10倍になっても、処理回数は3〜4回しか増えないことがわかります。1兆という大きな数でも、わずか40回で処理できます。
O(n) - データ量に比例する時間
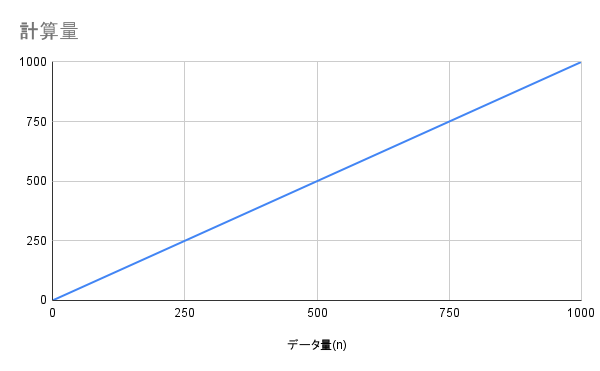
説明
データ量に比例して処理時間が増える計算量です。
データが2倍になれば処理時間も2倍、10倍になれば処理時間も10倍になります。直線的に増加するため、わかりやすい計算量です。
コード例
def find_max(numbers):
"""リストの最大値を見つける"""
max_value = numbers[0]
for num in numbers: # 全要素を1回ずつ確認
if num > max_value:
max_value = num
return max_value
# 使用例
data = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3]
max_num = find_max(data) # O(n)
全ての要素を1回ずつ確認する必要があるため、データ量に比例して処理時間が増えます。
ロジック例
- 全ユーザーへのメール送信:10,000人のユーザーに通知メールを送る
- CSVファイルの全行読み込み:100万行のCSVファイルを処理
- リストの合計値計算:売上データの総額を計算
- データの検索(先頭から順番に探す方法2):未整列のリストから特定の値を探す
O(n log n) - 効率的なソート
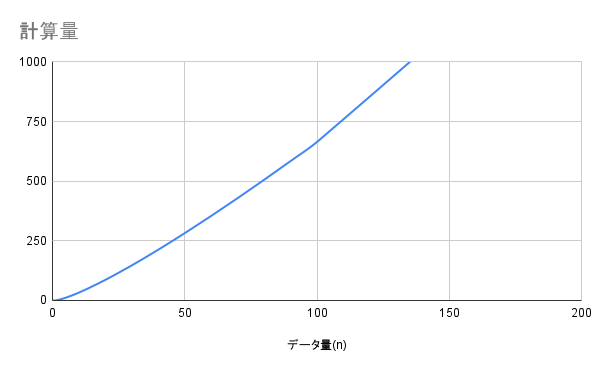
説明
効率的なソートアルゴリズムの計算量です。
$O(n)$ よりは遅いですが、後述の $O(n^2)$ よりははるかに速く、実用的な計算量です。データ量が大きくなっても、比較的効率よく処理できます。
コード例
def merge_sort(arr):
if len(arr) <= 1:
return arr
# 配列を半分に分割
mid = len(arr) // 2
left = merge_sort(arr[:mid])
right = merge_sort(arr[mid:])
# マージ(統合)
return merge(left, right)
def merge(left, right):
"""2つのソート済み配列を統合"""
result = []
i = j = 0
while i < len(left) and j < len(right):
if left[i] <= right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
result.extend(left[i:])
result.extend(right[j:])
return result
# 使用例
data = [64, 34, 25, 12, 22, 11, 90]
sorted_data = merge_sort(data) # O(n log n)
ロジック例
- 大量データのソート:10万件の売上データを金額順に並べ替え
- ログファイルの時系列ソート:数十万行のログを時刻順に整理
数値例
| データ量 | $O(n\ log\ n)$ の処理回数(概算) |
|---|---|
| 10 | 33 |
| 100 | 664 |
| 1,000 | 9,966 |
| 10,000 | 132,877 |
$O(n)$ の約10〜13倍の処理回数になりますが、次に説明する $O(n^2)$ と比べるとはるかに効率的です。
O(n^2) - 二乗時間
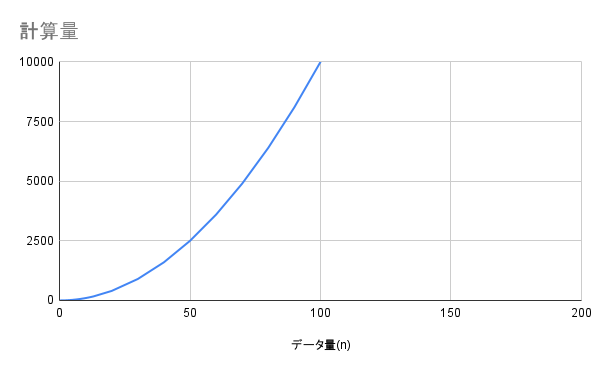
説明
データ量が2倍になると処理時間が4倍になる計算量です。
データ量が小さいうちは問題ありませんが、データが増えると急激に処理時間が増加します。
コード例
def find_duplicates(numbers):
"""重複している数値のペアを見つける(非効率な方法)"""
duplicates = []
for i in range(len(numbers)):
for j in range(i + 1, len(numbers)): # 二重ループ
if numbers[i] == numbers[j]:
duplicates.append((numbers[i], i, j))
return duplicates
# 使用例
data = [1, 2, 3, 2, 4, 3, 5]
dupes = find_duplicates(data) # O(n²)
二重ループ(ループの中にループ)がある場合、$O(n^2)$ になることが多いです。
ロジック例
- 重複データの検出:リスト内の全ペアを比較して重複を探す
- 総当たりマッチング:100人の参加者全員の組み合わせを評価
数値例
| データ量 | 処理回数($n^2$) |
|---|---|
| 10 | 100 |
| 100 | 10,000 |
| 1,000 | 1,000,000 |
| 10,000 | 100,000,000 |
データ量が1,000を超えると、処理回数が100万回を超えてしまいます。
O(2^n) - 2倍ずつ増える
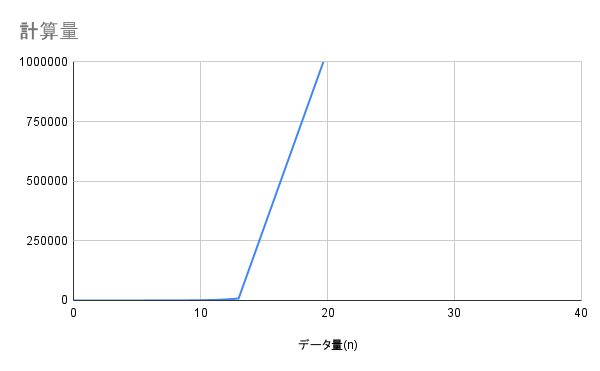
説明
データが1つ増えると処理時間が2倍になる計算量です。
データ量が少し増えるだけで、処理時間が爆発的に増加します。実用的ではありません。
コード例
def fibonacci_naive(n):
"""フィボナッチ数列(非効率な自分自身を呼び出す実装)"""
if n <= 1:
return n
return fibonacci_naive(n - 1) + fibonacci_naive(n - 2)
# 使用例
result = fibonacci_naive(10) # O(2^n)
# fibonacci_naive(40) は数秒〜十数秒かかる
自分自身を呼び出す処理6が2分岐する場合、$O(2^n)$ になることがあります。
ロジック例
- 全パターンの探索:パスワードの総当たり攻撃(ブルートフォース)
- 組み合わせの全列挙:10個の選択肢から全ての組み合わせを試す(1,024通り)
$O(2^n)$ のアルゴリズムは、データ量が$30$ 〜 $40$ を超えると実用的ではなくなります。計算結果を記憶して再利用する手法7などの最適化手法を検討しましょう。
O(n!) - 階乗時間
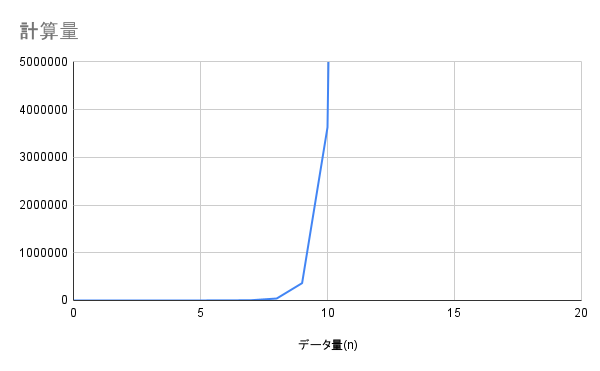
説明
現実的に解けない問題の計算量です。全ての並び方を試すアルゴリズムがこれに該当します。
コード例
import itertools
def calculate_distance(route, cities):
"""経路の総距離を計算(モック実装)"""
# 注: 本来はなんらかのアルゴリズムで各都市間の距離を計算するが、
# ここでは計算量オーダーの説明が目的のため、簡易値を返す
return sum(route) # デモ用の簡易実装
def traveling_salesman_naive(cities):
"""巡回セールスマン問題(全探索)"""
n = len(cities)
all_routes = itertools.permutations(range(n))
min_distance = float('inf')
best_route = None
for route in all_routes: # n! 通りの経路を全て試す
distance = calculate_distance(route, cities)
if distance < min_distance:
min_distance = distance
best_route = route
return best_route, min_distance
# 使用例
cities = [(0, 0), (1, 2), (3, 1), (5, 4)]
result_route, result_distance = traveling_salesman_naive(cities)
print(f"最適経路: {result_route}, 距離: {result_distance}")
# 4都市なら 4! = 24 通りで済むが...
# 10都市なら 10! = 3,628,800 通り
# 下記は12都市で、479,001,600 通り、処理に1分前後かかる
cities = [(0, 0), (1, 2), (3, 1), (5, 4), (9, 8), (14, 12), (23, 20), (37, 32), (60, 52), (97, 84), (157, 136), (254, 220)]
result_route, result_distance = traveling_salesman_naive(cities)
print(f"最適経路: {result_route}, 距離: {result_distance}")
# 15都市なら 15! = 1,307,674,368,000 通り(1兆超)
ロジック例
- 配送ルートの最適化:10箇所の配送先を最短経路で回る順番を決める
- データベースのテーブル読み取り順序:複数テーブルを結合する際に、読み取りの順序を決定する
データ量が10で約360万通り、15を超えると1兆通りを超え、現実的な時間では計算できなくなります。
計算量オーダーにおける係数の扱い
ビッグ・オー記法では、定数や係数を無視します。具体的には、以下の例のように記載を簡略化します。
- $O(2n)$ → $O(n)$
- $O(n + 100)$ → $O(n)$
- $O(5n^2)$ → $O(n^2)$
これは、データ量が大きくなると、定数や係数の影響が相対的に小さくなるためです。
例えば、$2n$ と $n$ の違いは常に2倍ですが、$n^2$ と $n$ の違いは $n$ が大きくなると無限大に広がります。
時間計算量オーダーの比較
ここまで7つの時間計算量オーダーを見てきました。それぞれがデータ量の増加に対してどう振る舞うか、比較してみましょう。
全オーダーを1つのグラフで比較
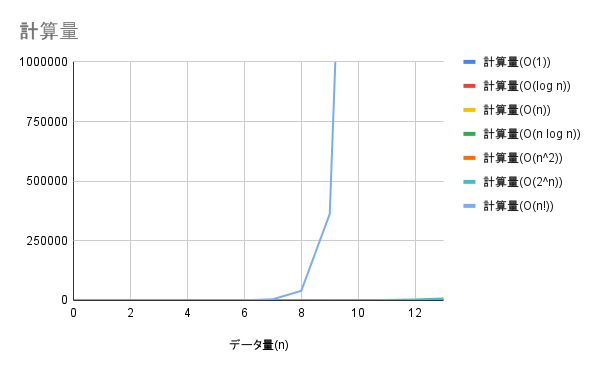
$O(n!)$ が突出していて、その他の計算量オーダーが比較できません。
O(1)、O(log n)、O(n)の比較
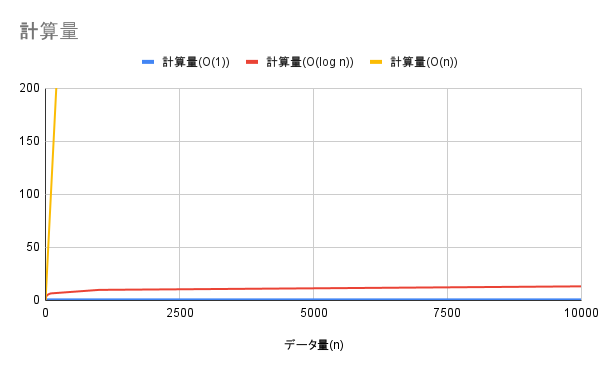
$O(1)$ と $O(log\ n)$ は、データ量が増えても $O(n)$ より圧倒的に少ない計算量で済むことがわかります。
O(n)、O(n log n)、O(n^2)の比較
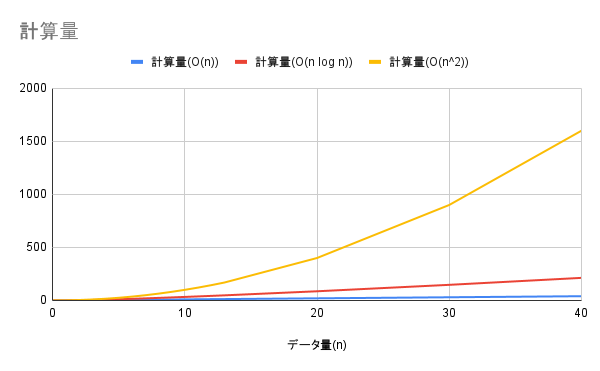
$O(n\ log\ n)$ は、$O(n^2)$ に比べ、計算量を少なく抑えられることがわかります。
O(n^2)、O(2^n)、O(n!)の比較
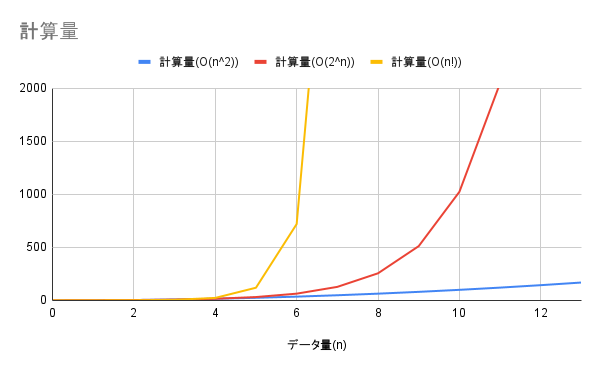
$O(2^n)$ は、 $O(n!)$ と比べると幾分マシですが、 $O(n^2)$ より急勾配で計算量が増加します。
データ量と処理時間の対応表
以下の表は、データ量が増えたときの各計算量の処理回数を示しています。
| データ量 | $O(1)$ | $O(\log n)$ | $O(n)$ | $O(n \log n)$ | $O(n^2)$ | $O(2^n)$ | $O(n!)$ |
|---|---|---|---|---|---|---|---|
| $1$ | $1$ | $1$ | $1$ | $1$ | $1$ | $2$ | $1$ |
| $10$ | $1$ | $3$ | $10$ | $33$ | $100$ | $1,024$ | $3,628,800$ |
| $100$ | $1$ | $7$ | $100$ | $664$ | $10,000$ | $1.27×10^{30}$ | $9.33×10^{157}$ |
| $1,000$ | $1$ | $10$ | $1,000$ | $9,966$ | $1,000,000$ | $1.07×10^{301}$ | - |
$O(2^n)$と$O(n!)$は、データ量が100を超えると天文学的な数値になります。
実用的な計算量はどれか
実務では、以下の計算量が実用的です。
| 実用度 | 計算量オーダー | 処理時間 | 評価 |
|---|---|---|---|
| 理想的、データ量が増えても安心 | $O(1)$ | 常に一定時間 | 最高 |
| $O(log\ n)$ | 非常に効率的 | 素晴らしい |
|
| 実用的、十分に効率的 | $O(n)$ | データ量に比例 | 良し! |
| $O(n \log n)$ | 大量データでも実用的 | そこそこ良い |
|
| 注意が必要、データ量次第 | $O(n^2)$ | データ量が1,000を超えると暗雲漂う | 大丈夫か...? |
| 避けるべき、実用的でない | $O(2^n)$ | データ量が40を超えると危うい | つらい |
| $O(n!)$ | データ量が16を超えると不可能 | アカン |
最後に
計算量オーダーは、プログラミングの基礎となる重要な概念です。最初は難しく感じることもありますが、グラフのイメージとコード例を思い出しながら、少しずつ慣れていきましょう。
コードを書く際は「このループは何回実行されるか?」「データが増えたら処理時間はどう変わるか?」と考える癖をつけることで、より効率的で美しいコードが書けるようになります。
この記事が、計算量オーダーを理解する第一歩になれば幸いです。